








背景:实现GCN,并且于resnet输出端的score level实现。
目录
相关内容
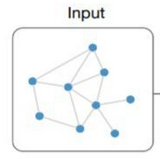
GCN (Graph Convolutional Network) 图卷积网络解析
一、GCN理论基础
GCN (Graph Convolutional Network) 图卷积网络解析
![]()
![]()

![]()
- 隐层的feature maps的数量为H,输入层数量为C,输出层为F
- 其中A为下面3.4中提到的symmetric adjacency matrix,


- 权重
 为输入层到隐层的权值矩阵
为输入层到隐层的权值矩阵 - 同理,权重
 为隐层到输出层的权值矩阵
为隐层到输出层的权值矩阵
这个公式跟BP有点像,只不过比BP多了一个稀疏的adj matrix A
二、邻接矩阵正则化
2.1 矩阵A的正则化
运行过程中,需要对邻接矩阵A进行正则化:
例如:
def normalize_adj(self, adj, threshold):
adj = (adj > threshold)*adj
# adj[adj>0.4]=1
D = np.power(np.sum(adj, axis=1), -0.5)
D = np.diag(D)
adj = np.matmul(np.matmul(D, adj), D)
return adj公式为symmetric adjacency matrix,![]()
![]()
或者
def gen_adj(A):
D = torch.pow(A.sum(1).float(), -0.5)
D = torch.diag(D)
adj = torch.matmul(torch.matmul(A, D).t(), D)
return adj如果A非对称的结构,经历此步可能并不能使A变成对称的。
2.2 运算与存储
直接嵌套入程序运算略显麻烦,不如直接运算好存起来再用。
import pickle
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import pandas as pd
import json
import os
from sklearn import datasets
from sklearn.cluster import SpectralClustering
from sklearn import metrics
class adj_matrix_gen():
def __init__(self):
self.load_dir='/Users/baidu/Desktop/code/ML_GAT-master/'
self.save_dir='/Users/baidu/Desktop/code/ML_GAT-master/'
self.load_corelation_filename='coco_correlations.pkl'
self.load_names_filename='coco_names.pkl'
self.save_filename='coco_normalized_adj.pkl'
self.load_correlation_file_path=self.load_dir+self.load_corelation_filename
self.load_names_file_path=self.load_dir+self.load_names_filename
self.save_file_path=self.save_dir+self.save_filename
self.un_normalized_fig_path=self.save_dir+'un_normalized_adj.jpg'
self.normalized_fig_path=self.save_dir+'normalized_adj.jpg'
def run_adj_matrix_gen(self):
# plot heatmap of matrix
def plot_cor(mat, names,save_fig_name):
fig, ax = plt.subplots()
# 二维的数组的热力图,横轴和数轴的ticklabels要加上去的话,既可以通过将array转换成有column
# 和index的DataFrame直接绘图生成,也可以后续再加上去。后面加上去的话,更灵活,包括可设置labels大小方向等。
sns.heatmap(
pd.DataFrame(mat * (mat >= 0), columns=names,
index=names),
xticklabels=True,
yticklabels=True,cmap="YlGnBu") # cmap="YlGnBu" 'RdYlBu'
# sns.heatmap(np.round(a,2), annot=True, vmax=1,vmin = 0, xticklabels= True, yticklabels= True,
# square=True, cmap="YlGnBu")
ax.set_title('Correlation', fontsize=18)
# ax.set_ylabel('Attribute', fontsize=18)
# ax.set_xlabel('Attribute', fontsize=18) # 横变成y轴,跟矩阵原始的布局情况是一样的
plt.savefig(save_fig_name)
plt.close('all')
def normalize_adj_gen(un_normalized_adj,threshold):
un_normalized_adj = (un_normalized_adj > threshold) * un_normalized_adj
# adj[adj>0.4]=1
D = np.power(np.sum(un_normalized_adj, axis=1), -0.5)
D = np.diag(D)
normalized_adj = np.matmul(np.matmul(D, un_normalized_adj), D)
return normalized_adj
# load correlation matrix and names
with open(self.load_correlation_file_path, 'rb') as f:
print("loading ",self.load_correlation_file_path," from local...")
correlations = pickle.load(f)
unnormalized_adj = correlations['pp']
with open(self.load_names_file_path,'rb') as f:
print("loading ",self.load_names_file_path," from local...")
names=pickle.load(f)
plot_cor(mat=unnormalized_adj,names=names,save_fig_name=self.un_normalized_fig_path)
normalized_adj=normalize_adj_gen(un_normalized_adj=unnormalized_adj,threshold=0.1)
plot_cor(mat=normalized_adj, names=names, save_fig_name=self.normalized_fig_path)
if __name__ == '__main__':
adj_matrix_gen().run_adj_matrix_gen()
print('finished....')
三、torch实现
3.1 init中的super
不加super会报错
class Graph_convolution_network(nn.Module):
def __init__(self, in_features,hidden_features, out_features):
# super(Graph_convolution_network, self).__init__() File "/Users/baidu/Desktop/code/ML_GAT-master/models/resnet_gcn.py", line 50, in __init__
self.graph_convolution_layer1=Graph_convolution_Layer(in_features=in_features, out_features=hidden_features)
File "/Users/baidu/anaconda3/envs/torch041/lib/python3.5/site-packages/torch/nn/modules/module.py", line 565, in __setattr__
"cannot assign module before Module.__init__() call")
AttributeError: cannot assign module before Module.__init__() call3.2 矩阵的读取与运算
这篇文章中有相关于 np变量与cuda变量的实现。Graph Attention Network 图注意力网络 (三) 更改邻接masked attention
# torch.floatTensor format
mask = torch.FloatTensor(np.where(unnormalized_adj > self.probability_filter_threshold, 1, 0))
unnormalized_adj=torch.FloatTensor(unnormalized_adj).mul(mask)
# numpy format
mask=np.where(unnormalized_adj > self.probability_filter_threshold, 1, 0)
unnormalized_adj=np.multiply(unnormalized_adj,mask)
D = np.power(np.sum(unnormalized_adj, axis=1), -0.5)
D = np.diag(D)
normalized_adj=np.matmul(np.matmul(D, unnormalized_adj), D)
print()
# def normalize_adj(adj, threshold):
# # adj=np.array(adj.data())
# adj = (adj > threshold) * adj
# # adj[adj>0.4]=1
# D = np.power(np.sum(adj, axis=1), -0.5)
# D = np.diag(D)
# adj = np.matmul(np.matmul(D, adj), D)
# return adj
self.normalized_adj=torch.FloatTensor(normalized_adj)注意torch与np格式的数据均可实现。
3.2 图卷积层的实现
class Graph_convolution_Layer(nn.Module):
def __init__(self, in_features, out_features, bias=False):
super(Graph_convolution_Layer, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.Tensor(in_features, out_features))
if bias:
self.bias = Parameter(torch.Tensor(1, 1, out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
stdv = 1. / math.sqrt(self.weight.size(1))
self.weight.data.uniform_(-stdv, stdv)
if self.bias is not None:
self.bias.data.uniform_(-stdv, stdv)
def forward(self, input, adj):
# adj=torch.FloatTensor(adj).cuda()
# adj = torch.FloatTensor(adj)
support = torch.matmul(input, self.weight)
output = torch.matmul(adj, support)
if self.bias is not None:
return output + self.bias
else:
return output
def __repr__(self):
return self.__class__.__name__ + ' (' \
+ str(self.in_features) + ' -> ' \
+ str(self.out_features) + ')'
3.3 GCN实现
class Graph_convolution_network(nn.Module):
def __init__(self, in_features,hidden_features, out_features):
super(Graph_convolution_network, self).__init__()
self.graph_convolution_layer1=Graph_convolution_Layer(in_features=in_features, out_features=hidden_features)
self.graph_convolution_layer2=Graph_convolution_Layer(in_features=hidden_features, out_features=out_features)
self.relu = nn.LeakyReLU(0.2)
with open('coco_correlations.pkl', 'rb') as f:
print("loading coco_correlations.pkl from local...")
correlations = pickle.load(f)
unnormalized_adj = correlations['pp']
self.probability_filter_threshold = 0.1
# torch.floatTensor format
mask = torch.FloatTensor(np.where(unnormalized_adj > self.probability_filter_threshold, 1, 0))
self.unnormalized_adj=torch.FloatTensor(unnormalized_adj).mul(mask)
def forward(self,input):
# normalized_adj=self.unnormalized_adj.cuda()
x=self.graph_convolution_layer1(input=input,adj=self.unnormalized_adj)
x=self.relu(x)
x=self.graph_convolution_layer2(input=x,adj=self.unnormalized_adj)
return x3.4 cuda的实现
adj矩阵读入为numpy,所以需要将其改为torch.FloatTensor.cuda
floatTensor可以直接转,cuda需要在forward中转换。否则会有报错:
File "/home/ssd1/slurm_submit/6submit_ML_GAT/torch/lib/python3.5/site-packages/torch/nn/modules/module.py", line 477, in __call__
result = self.forward(*input, **kwargs)
File "/home/ssd1/slurm_submit/6submit_ML_GAT/models/resnet_gcn.py", line 67, in forward
x=self.graph_convolution_layer1(input=input,adj=self.unnormalized_adj)
File "/home/ssd1/slurm_submit/6submit_ML_GAT/torch/lib/python3.5/site-packages/torch/nn/modules/module.py", line 477, in __call__
result = self.forward(*input, **kwargs)
File "/home/ssd1/slurm_submit/6submit_ML_GAT/models/resnet_gcn.py", line 38, in forward
output = torch.matmul(adj, support)
RuntimeError: Expected object of type torch.FloatTensor but found type torch.cuda.FloatTensor for argument #2 'mat2'读入转为FloatTensor,
with open('coco_correlations.pkl', 'rb') as f:
print("loading coco_correlations.pkl from local...")
correlations = pickle.load(f)
unnormalized_adj = correlations['pp']
self.probability_filter_threshold = 0.1
# torch.floatTensor format
mask = torch.FloatTensor(np.where(unnormalized_adj > self.probability_filter_threshold, 1, 0))
self.unnormalized_adj=torch.FloatTensor(unnormalized_adj).mul(mask)
def forward(self,input):
# normalized_adj=self.unnormalized_adj.cuda()
x=self.graph_convolution_layer1(input=input,adj=self.unnormalized_adj)
x=self.relu(x)
x=self.graph_convolution_layer2(input=x,adj=self.unnormalized_adj)
return xlayer之中转为cuda
def forward(self, input, adj):
# adj=torch.FloatTensor(adj).cuda()
# adj = torch.FloatTensor(adj)
adj=adj.cuda()
support = torch.matmul(input, self.weight)
output = torch.matmul(adj, support)
if self.bias is not None:
return output + self.bias
else:
return output

















 1171
1171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











