







| ←上一篇 | ↓↑ | 下一篇→ |
|---|---|---|
| 2.3 Logistic 回归损失函数 | 回到目录 | 2.5 导数 |
梯度下降法 (Gradient Descent)
梯度下降法可以做什么?
在你测试集上,通过最小化代价函数(成本函数) J ( w , b ) J(w,b) J(w,b) 来训练的参数 w w w 和 b b b ,

如图,在第二行给出和之前一样的逻辑回归算法的代价函数(成本函数)
梯度下降法的形象化说明

在这个图中,横轴表示你的空间参数
w
w
w 和
b
b
b ,在实践中,
w
w
w 可以是更高的维度,但是为了更好地绘图,我们定义
w
w
w 和
b
b
b ,都是单一实数,代价函数(成本函数)
J
(
w
,
b
)
J(w,b)
J(w,b) 是在水平轴
w
w
w 和
b
b
b 上的曲面,因此曲面的高度就是
J
(
w
,
b
)
J(w,b)
J(w,b) 在某一点的函数值。我们所做的就是找到使得代价函数(成本函数)
J
(
w
,
b
)
J(w,b)
J(w,b) 函数值是最小值,对应的参数
w
w
w 和
b
b
b 。

如图,代价函数(成本函数) J ( w , b ) J(w,b) J(w,b) 是一个凸函数(convex function),像一个大碗一样。

如图,这就与刚才的图有些相反,因为它是非凸的并且有很多不同的局部最小值。由于逻辑回归的代价函数(成本函数)
J
(
w
,
b
)
J(w,b)
J(w,b) 特性,我们必须定义代价函数(成本函数)
J
(
w
,
b
)
J(w,b)
J(w,b) 为凸函数。 初始化
w
w
w 和
b
b
b,

可以用如图那个小红点来初始化参数
w
w
w 和
b
b
b ,也可以采用随机初始化的方法,对于逻辑回归几乎所有的初始化方法都有效,因为函数是凸函数,无论在哪里初始化,应该达到同一点或大致相同的点。

我们以如图的小红点的坐标来初始化参数 w w w 和 b b b 。
2. 朝最陡的下坡方向走一步,不断地迭代

我们朝最陡的下坡方向走一步,如图,走到了如图中第二个小红点处。

我们可能停在这里也有可能继续朝最陡的下坡方向再走一步,如图,经过两次迭代走到第三个小红点处。
3.直到走到全局最优解或者接近全局最优解的地方
通过以上的三个步骤我们可以找到全局最优解,也就是代价函数(成本函数) J ( w , b ) J(w,b) J(w,b) 这个凸函数的最小值点。
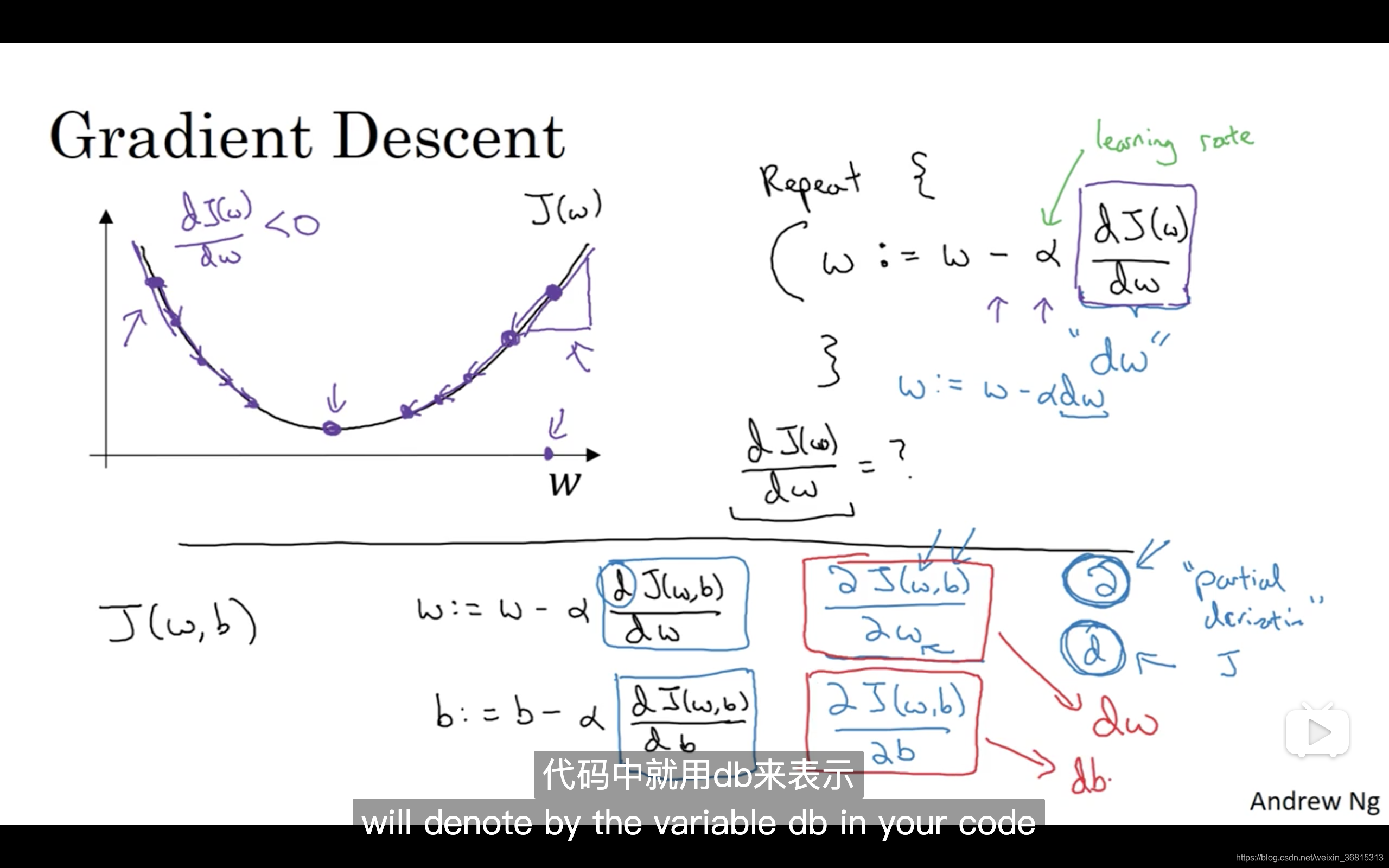
梯度下降法的细节化说明(仅有一个参数)

假定代价函数(成本函数) J ( w ) J(w) J(w) 只有一个参数 w w w ,即用一维曲线代替多维曲线,这样可以更好画出图像。

迭代就是不断重复做如图的公式:
: = := := 表示更新参数,
α \alpha α 表示学习率(learning rate),用来控制步长(step),即向下走一步的长度 d J ( w ) d w \frac{dJ(w)}{dw} dwdJ(w) 就是函数 J ( w ) J(w) J(w) 对 w w w 求导(derivative),在代码中我们会使用 d w dw dw 表示这个结果

对于导数更加形象化的理解就是斜率(slope),如图该点的导数就是这个点相切于 J ( w ) J(w) J(w) 的小三角形的高除宽。假设我们以如图点为初始化点,该点处的斜率的符号是正的,即 d J ( w ) d w > 0 \frac{dJ(w)}{dw}>0 dwdJ(w)>0 ,所以接下来会向左走一步。

整个梯度下降法的迭代过程就是不断地向左走,直至逼近最小值点。

假设我们以如图点为初始化点,该点处的斜率的符号是负的,即 d J ( w ) d w < 0 \frac{dJ(w)}{dw}<0 dwdJ(w)<0 ,所以接下来会向右走一步。

整个梯度下降法的迭代过程就是不断地向右走,即朝着最小值点方向走。
梯度下降法的细节化说明(两个参数)
逻辑回归的代价函数(成本函数) J ( w , b ) J(w,b) J(w,b) 是含有两个参数的。

∂ \partial ∂ 表示求偏导符号,可以读作round, ∂ J ( w , b ) ∂ w \frac{\partial J(w,b)}{\partial w} ∂w∂J(w,b) 就是函数 J ( w , b ) J(w,b) J(w,b) 对 w w w 求偏导,在代码中我们会使用 d w dw dw 表示这个结果, ∂ J ( w , b ) ∂ b \frac{\partial J(w,b)}{\partial b} ∂b∂J(w,b) 就是函数 J ( w , b ) J(w,b) J(w,b) 对 b b b 求偏导,在代码中我们会使用 d b db db 表示这个结果, 小写字母 d d d 用在求导数(derivative),即函数只有一个参数, 偏导数符号 ∂ \partial ∂ 用在求偏导(partial derivative),即函数含有两个以上的参数。
课程PPT


| ←上一篇 | ↓↑ | 下一篇→ |
|---|---|---|
| 2.3 Logistic 回归损失函数 | 回到目录 | 2.5 导数 |















 2373
2373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











