







数据集大全
- 数据集大全
- 介绍
- 目前接触到的数据集
- 1. [MNIST](http://yann.lecun.com/exdb/mnist/)
- 2. [CIFAR-10 / CIFAR-100](http://www.cs.toronto.edu/~kriz/cifar.html)
- 3. [ImageNet](http://www.image-net.org/)
- 4. [COCO](https://cocodataset.org/#home)
- 5. [PASCAL VOC](https://pjreddie.com/projects/pascal-voc-dataset-mirror/)
- 6. [Caltech101](http://www.vision.caltech.edu/Image_Datasets/Caltech101/)
- 7. [LFW](http://vis-www.cs.umass.edu/lfw/)
- 8. [fashion-mnist](https://www.kaggle.com/zalando-research/fashionmnist)
- 9. [DIV2K](https://data.vision.ee.ethz.ch/cvl/DIV2K/)
- 10. [Set5]()
- 收藏其他类数据集:
数据集大全
介绍
深度学习的关键是训练。无论是从图像处理到语音识别,每个问题都有其独特的细微差别和方法。
但是,你可以从哪里获得这些数据?现在你看到的很多研究论文都使用专有数据集,而这些数据集通常不会向公众发布。如果你想学习并应用你新掌握的技能,数据就成为一个问题。
在本文中,我们列出了一些高质量的数据集,每个深度学习爱好者都可以使用并改善改进他们模型的性能。拥有这些数据集将使你成为一名更好的数据科学家,并且你将从中获得无可估量的价值。我们还收录了具有最新技术(SOTA)结果的论文,供你浏览并改进你的模型。
如何使用这些数据集?
首先要做的事——下载这些数据集,这些数据集的规模很大!所以请确保你有一个快速的互联网连接。
数据集分为三类——图像处理、自然语言处理和音频/语音处理。
让我们开始我们的数据集之旅吧!
目前接触到的数据集
1. MNIST
MNIST数据集(Mixed National Institute of Standards and Technology database)是美国国家标准与技术研究院收集整理的大型手写数字数据库,包含60,000个示例的训练集以及10,000个示例的测试集.

你可以在 Yann LeCun的官网下载这套数据集,共四个文件包:
- train-images-idx3-ubyte.gz: 训练图片集 (9912422 bytes)
- train-labels-idx1-ubyte.gz: 训练图片集的正确标签 (28881 bytes)
- t10k-images-idx3-ubyte.gz: 测试图片 (1648877 bytes)
- t10k-labels-idx1-ubyte.gz: 测试图片的正确标签 (4542 bytes)
每张图片包含一个手写数字。

数据集包含6万张图片用于训练,1万张用于测试验证。
图像数据格式和图向量
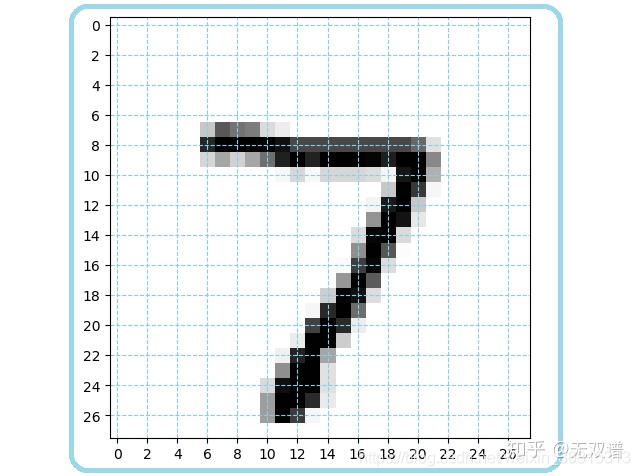
每张图片表达了[0,9]这是10个数字中的一个,有28X28=784个像素,每个像素根据灰度取整数值[0,255];把每张图片看作具有784个特征的图向量,问题就变成:根据D个特征维度,对图像做K分类的问题,这里D=784,K=10。
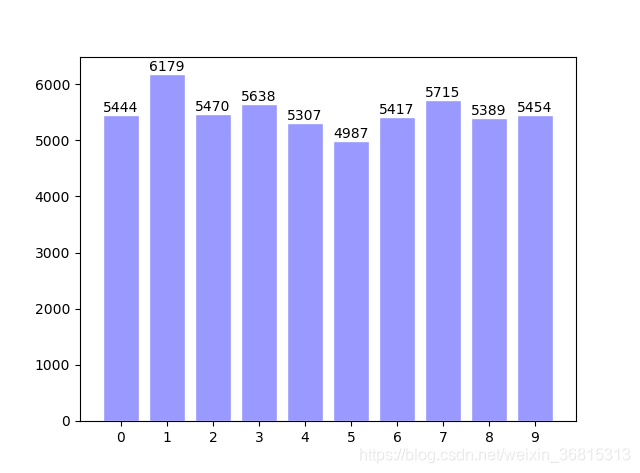
各个数字的数据量如下:
MNIST文件格式
图片images文件,前16个字节,是文件格式和图片数量、规格的描述;图片的像素信息从第17个字节开始。
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number 0004 32 bit integer 60000 number of images 0008 32 bit integer 28 number of rows 0012 32 bit integer 28 number of columns 0016 unsigned byte 0 pixel 0017 unsigned byte 0 pixel … xxxx unsigned byte ?? pixel
同样,标签labels文件里,前8个字节,是文件格式和标签数量的描述;而表述正确分类的标签信息,从第9个字节开始。
[offset] [type] [value] [description]
0000 32 bit integer 0x00000801(2049) magic number 0004 32 bit integer 60000 number of items 0008 unsigned byte 7 label 0009 unsigned byte 2 label … xxxx unsigned byte ?? label
理解了文件格式,就可以很容易地读取MNIST数据。
Ref:
2. CIFAR-10 / CIFAR-100
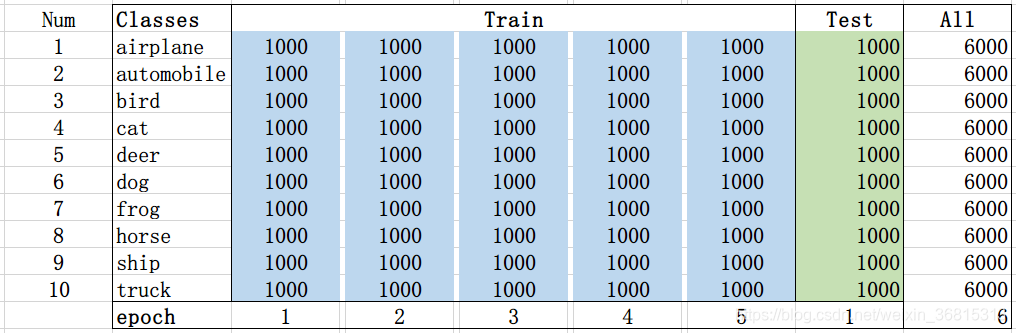
CIFAR-10 数据集由 10 个类的 60000 个 32x32 彩色图像组成,每个类有 6000 个图像。有 50000 个训练图像和 10000 个测试图像。
数据集分为 5 个训练批次和 1 个测试批次,每个批次有 10000 个图像。测试批次包含来自每个类别的恰好 1000 个随机选择的图像。训练批次以随机顺序包含剩余图像,但由于一些批次可能包含来自一个类别的图像比另一个更多,因此总体来说,5 个训练集之和包含来自每个类的正好 5000 张图像。

这 10 类都是彼此独立的,不会相互重叠,因此是多分类单标签问题。
3. ImageNet
miniImageNet和omniglot数据集在元学习和小样本学习领域应用广泛,但是网络上鲜有对miniImageNet数据集的介绍,因此在这里我对这个数据集做了一个简要的介绍。
ImageNet简介
miniImageNet数据集节选自ImageNet数据集。ImageNet是一个非常有名的大型视觉数据集,它的建立旨在促进视觉识别研究。训练ImageNet数据集需要消耗大量的计算资源。ImageNet为超过1400万张图像进行了注释,而且给至少100万张图像提供了边框。
ImageNet包含2万多个类别,比如:“气球”、“轮胎”和“狗”等类别,ImageNet的每个类别均有不少于500张图像。
训练这么多图像需要消耗大量的资源,因此在2016年google DeepMind团队Oriol Vinyals等人在ImageNet的基础上提取出了miniImageNet数据集。
来源
DeepMind团队首次将miniImageNet数据集用于小样本学习研究,从此miniImageNet成为了元学习和小样本领域的基准数据集。
DeepMind的那篇小样本学习的论文就是大名鼎鼎的Matching Network的来源: Matching Networks for One Shot Learning 。
miniImageNet包含100类共60000张彩色图片,其中每类有600个样本,每张图片的规格为84×84。通常而言,这个数据集的训练集和测试集的类别划分为:80:20。相比于CIFAR10数据集,miniImageNet数据集更加复杂,但更适合进行原型设计和实验研究。
数据集架构
mini-imagenet一共有2.86GB,文件架构如下:

数据集中图片示例:

Ref
4. COCO
5. PASCAL VOC
VOC:visual object classes
此数据集可以用于图像分类、目标检测、图像分割。
该挑战的主要目的是识别真实场景中一些类别的物体。在该挑战中,这是一个监督学习的问题,训练集以带标签的图片的形式给出。这些物体包括20类:
- Person: person;
- Animal: bird, cat, cow, dog, horse, sheep;
- Vehicle: aeroplane, bicycle, boat, bus,car, motorbike, train;
- Indoor: bottle, chair, dining table, pottedplant, sofa, tv/monitor;

- 训练集由一套图像组成:每个图像拥有一个对应的标注文件,给出了图像中出现的物体的bounding box和class label,该物体属于上述20类中的某一类。
- 同一张图像中,可能出现属于多个类别的多个物体。
- 所有的标注图片都有Detection需要的label,但只有部分数据有Segmentation Label。
- VOC2007中包含9963张标注过的图片, 由train/val/test三部分组成, 共标注出24,640个物体。
- VOC2007的test数据label已经公布, 之后的没有公布(只有图片,没有label)。
- 对于检测任务,VOC2012的trainval/test包含08-11年的所有对应图片。 train/val有11540张图片共27450个物体。
- 对于分割任务, VOC2012的trainval包含07-11年的所有对应图片, test只包含08-11。train/val有 2913张图片共6929个物体。
- 这些图像中的一部分图像还拥有像素级的标注,用于segmentation competition。
- 用于action classification的图片集与用于classification/detection/segmentation的图片集不相交。它们被部分地标注上了图像中人的bounding box,参考点和动作。
- 用于person layout taster的图像,被额外的标注上了人的身体部位(头、手、脚),其测试集与主任务(classification/detection)的测试集不相交。
- 数据集按1:1的比例被分为训练(验证)集和测试集。这两部分的图像中类别的分布也大致相等。
Ref
6. Caltech101
7. LFW
8. fashion-mnist
该数据集是 MNIST 数据集的一个替代品,因为 MNIST 手写数据过于简单,很多时候体现不出深度神经网络与传统机器学习算法之间的差距,所以才出现 fashion-mnist 数据集。
fashion-mnist 数据集也称潮流数据集,涵盖了来自 10 种类别的共 7 万个不同商品的正面图片,其中有T恤、卫衣、长裙、裤子、鞋子等各种物品,该数据集中的图像都是 28x28 的灰度图像,这些图像分别对应着 10 个类别标签,整个数据集被分为 6 万个训练数据与 1 万个测试数据。可以看出,除了数据内容不同,其他都与 MNIST 数据集相同,简单来讲,可以用于处理 MNIST 数据集的代码,通常也可以直接用在 fashion-mnist 数据集上。
下载地址:https://github.com/zalandoresearch/fashion-mnist
9. DIV2K
10. Set5
一个公开整理的 Set5 数据集的模型性能:Image Super-Resolution on Set5 - 4x upscaling
另一篇文章:Low-Complexity Single-Image Super-Resolution based on Nonnegative Neighbor Embedding


















 1616
1616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











