







3大核心技术
- 使用了3维高斯分布来做点云处理.使用协方差矩阵影响高斯大小形状跟旋转
- 使用了cuda可微渲染编码提高了渲染质量跟速度
- 使用了球谐函数处理RGB颜色
光栅化流程图
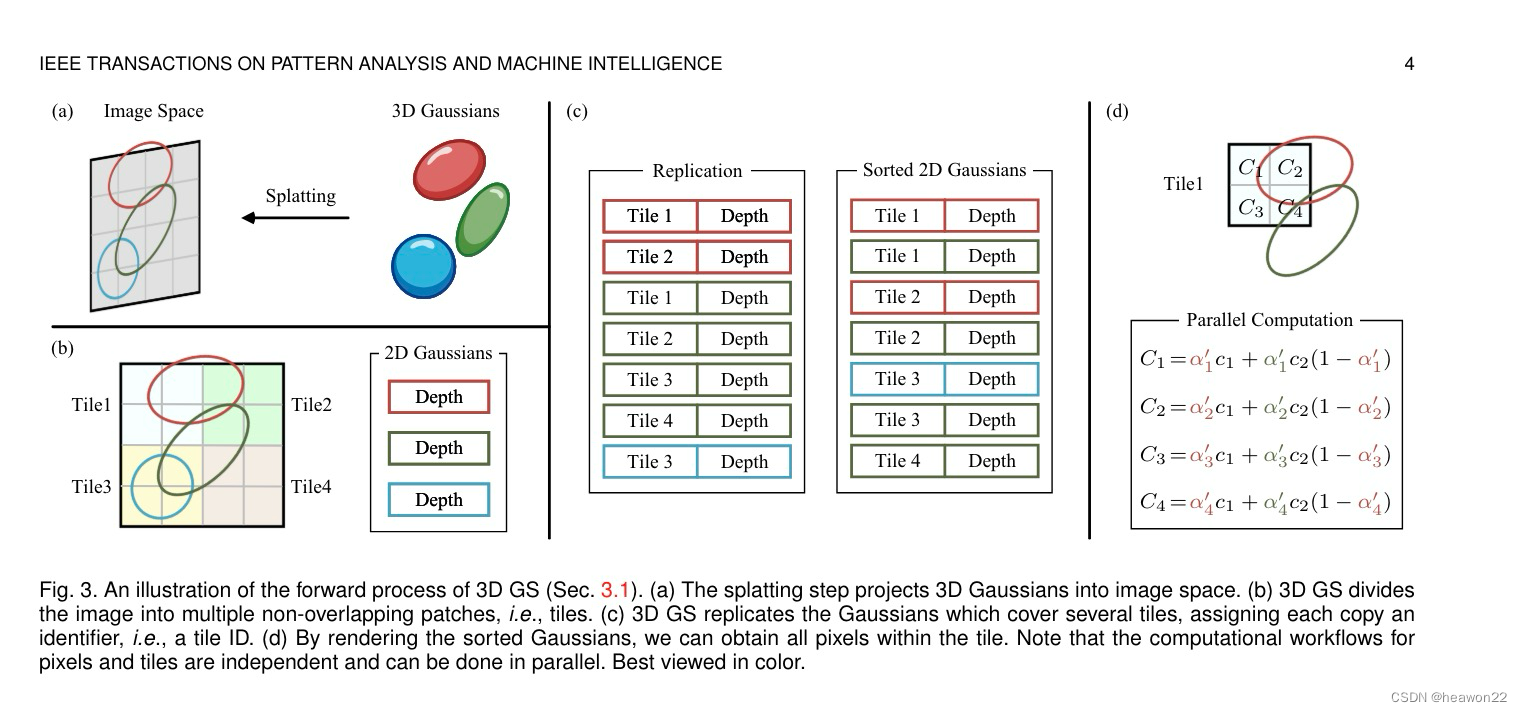 abc是预处理流程,d是光栅化过程
abc是预处理流程,d是光栅化过程
a) 3d-2d投影过程
3d gaussian是不同于传统模型,没有使用3角面来处理.而是使用了椭球.
椭球经过splatting溅射以后投影到2D图片
下面gaussian模型主要训练参数初始化.
def __init__(self, sh_degree : int):
self.active_sh_degree = 0 //球谐函数等级
self.max_sh_degree = sh_degree //球谐函数等级
self._xyz = torch.empty(0) //高斯球xyz坐标
self._features_dc = torch.empty(0) //球谐函数主要颜色
self._features_rest = torch.empty(0) //球谐函数其他颜色
self._scaling = torch.empty(0) //椭球xyz轴大小
self._rotation = torch.empty(0) //椭球旋转
self._opacity = torch.empty(0) //椭球透明度
self.max_radii2D = torch.empty(0) //椭圆2D半径
self.xyz_gradient_accum = torch.empty(0) //xyz梯度累计
self.denom = torch.empty(0) //分母
self.optimizer = None //优化器
self.percent_dense = 0 //密度参数
self.spatial_lr_scale = 0 //学习率
self.setup_functions() //初始化方法b) 2d 投影后tile每个块大小计算跟高斯椭球覆盖的关系
每个tile都是16*16像素组成,每个tile对应cuda的每个block,
每个tile都由多个高斯覆盖,每个高斯都有自己的深度,每个高斯对应cuda的一个block的一个线程
c) 计算2d投影后tile每个块列表List
用tile跟gaussian编号做排序处理
d) 最终光栅化流程
每个tile对应cuda的每个block,每个像素对应一个线程
通过覆盖这个像素的高斯点颜色跟透明度技术最终颜色
技术流程
python->c++->cuda
cuda:核函数-grid-block-thread做并行处理
python 核心代码文件
train.py
训练代码主入口
scene/__init_py
场景训练数据,相机数据,gaussian模型初始化
gaussian_model.py
gaussian模型核心代码
gaussian_renderer/init.py
render渲染核心代码
cuda核心代码文件
- gaussian_renderer/init.py 渲染的时候调用子模块的diff_gaussian_rasterization/init.py 文件
class GaussianRasterizer(nn.Module)类 - class GaussianRasterizer(nn.Module)调用继承了自动微分的类class _RasterizeGaussians(torch.autograd.Function).重写forward跟backward方法.
里面调用C++的rasterize_gaussians方法 - ext.cpp定义了python方法到rasterize_points文件的C++方法
- rasterize_points文件最终调用rasterizer_impl.cu的cuda代码
主要看CudaRasterizer::Rasterizer::forward跟CudaRasterizer::Rasterizer::backword2个方法
里面调用了forward跟backward的Cuda文件
这两个就是核心文件 - 渲染forward.cu 预处理核心代码备注
// Perform initial steps for each Gaussian prior to rasterization.
//预处理高斯球投影流程,计算高斯球投影的大小跟覆盖tile的范围,一个block处理一个tile,一个线程处理一个高斯球
template<int C>
__global__ void preprocessCUDA(int P, int D, int M,
const float* orig_points,
const glm::vec3* scales,
const float scale_modifier,
const glm::vec4* rotations,
const float* opacities,
const float* shs,
bool* clamped,
const float* cov3D_precomp,
const float* colors_precomp,
const float* viewmatrix,
const float* projmatrix,
const glm::vec3* cam_pos,
const int W, int H,
const float tan_fovx, float tan_fovy,
const float focal_x, float focal_y,
int* radii,
float2* points_xy_image,
float* depths,
float* cov3Ds,
float* rgb,
float4* conic_opacity,
const dim3 grid,
uint32_t* tiles_touched,
bool prefiltered)
{
auto idx = cg::this_grid().thread_rank();
if (idx >= P)
return;
// Initialize radius and touched tiles to 0. If this isn't changed,
// this Gaussian will not be processed further.
//半径跟tiles数量
radii[idx] = 0;
tiles_touched[idx] = 0;
// Perform near culling, quit if outside.
float3 p_view;
if (!in_frustum(idx, orig_points, viewmatrix, projmatrix, prefiltered, p_view))
return;
// Transform point by projecting
//经过3d point跟投影矩阵获取高斯的中心点
float3 p_orig = { orig_points[3 * idx], orig_points[3 * idx + 1], orig_points[3 * idx + 2] };
float4 p_hom = transformPoint4x4(p_orig, projmatrix);
float p_w = 1.0f / (p_hom.w + 0.0000001f);
float3 p_proj = { p_hom.x * p_w, p_hom.y * p_w, p_hom.z * p_w };
// If 3D covariance matrix is precomputed, use it, otherwise compute
// from scaling and rotation parameters.
//计算3D协方差矩阵
const float* cov3D;
if (cov3D_precomp != nullptr)
{
cov3D = cov3D_precomp + idx * 6;
}
else
{
computeCov3D(scales[idx], scale_modifier, rotations[idx], cov3Ds + idx * 6);
cov3D = cov3Ds + idx * 6;
}
// Compute 2D screen-space covariance matrix
//计算2d的协方差矩阵
float3 cov = computeCov2D(p_orig, focal_x, focal_y, tan_fovx, tan_fovy, cov3D, viewmatrix);
// Invert covariance (EWA algorithm)
//计算行列式值
float det = (cov.x * cov.z - cov.y * cov.y);
if (det == 0.0f)
return;
float det_inv = 1.f / det;
float3 conic = { cov.z * det_inv, -cov.y * det_inv, cov.x * det_inv };
// Compute extent in screen space (by finding eigenvalues of
// 2D covariance matrix). Use extent to compute a bounding rectangle
// of screen-space tiles that this Gaussian overlaps with. Quit if
// rectangle covers 0 tiles.
//计算2X2矩阵的最大特征值来近似椭圆的长轴半径
float mid = 0.5f * (cov.x + cov.z);
float lambda1 = mid + sqrt(max(0.1f, mid * mid - det));
float lambda2 = mid - sqrt(max(0.1f, mid * mid - det));
float my_radius = ceil(3.f * sqrt(max(lambda1, lambda2)));
float2 point_image = { ndc2Pix(p_proj.x, W), ndc2Pix(p_proj.y, H) };
uint2 rect_min, rect_max;
//计算覆盖的tile
getRect(point_image, my_radius, rect_min, rect_max, grid);
if ((rect_max.x - rect_min.x) * (rect_max.y - rect_min.y) == 0)
return;
// If colors have been precomputed, use them, otherwise convert
// spherical harmonics coefficients to RGB color.
//使用球鞋函数计算RGB颜色
if (colors_precomp == nullptr)
{
glm::vec3 result = computeColorFromSH(idx, D, M, (glm::vec3*)orig_points, *cam_pos, shs, clamped);
rgb[idx * C + 0] = result.x;
rgb[idx * C + 1] = result.y;
rgb[idx * C + 2] = result.z;
}
// Store some useful helper data for the next steps.
//存储一些有用的参数后续使用,深度跟半径
depths[idx] = p_view.z;
radii[idx] = my_radius;
points_xy_image[idx] = point_image;
// Inverse 2D covariance and opacity neatly pack into one float4
//2D协方差矩阵的逆跟tiles数量
conic_opacity[idx] = { conic.x, conic.y, conic.z, opacities[idx] };
tiles_touched[idx] = (rect_max.y - rect_min.y) * (rect_max.x - rect_min.x);
}6. 渲染forward.cu 光栅化核心代码备注
// Main rasterization method. Collaboratively works on one tile per
// block, each thread treats one pixel. Alternates between fetching
// and rasterizing data.
//最终像素渲染,一个block处理一个tile,一个线程处理一个像素
template <uint32_t CHANNELS>
__global__ void __launch_bounds__(BLOCK_X * BLOCK_Y)
renderCUDA(
const uint2* __restrict__ ranges,
const uint32_t* __restrict__ point_list,
int W, int H,
const float2* __restrict__ points_xy_image,
const float* __restrict__ features,
const float4* __restrict__ conic_opacity,
float* __restrict__ final_T,
uint32_t* __restrict__ n_contrib,
const float* __restrict__ bg_color,
float* __restrict__ out_color)
{
// Identify current tile and associated min/max pixel range.
//计算block的像素最小最大值
auto block = cg::this_thread_block();
uint32_t horizontal_blocks = (W + BLOCK_X - 1) / BLOCK_X;
uint2 pix_min = { block.group_index().x * BLOCK_X, block.group_index().y * BLOCK_Y };
uint2 pix_max = { min(pix_min.x + BLOCK_X, W), min(pix_min.y + BLOCK_Y , H) };
//计算thread的像素坐标
uint2 pix = { pix_min.x + block.thread_index().x, pix_min.y + block.thread_index().y };
uint32_t pix_id = W * pix.y + pix.x;
float2 pixf = { (float)pix.x, (float)pix.y };
// Check if this thread is associated with a valid pixel or outside.
//计算像素是否在图片
bool inside = pix.x < W&& pix.y < H;
// Done threads can help with fetching, but don't rasterize
//是否处理像素
bool done = !inside;
// Load start/end range of IDs to process in bit sorted list.
//处理block覆盖范围跟数量
uint2 range = ranges[block.group_index().y * horizontal_blocks + block.group_index().x];
const int rounds = ((range.y - range.x + BLOCK_SIZE - 1) / BLOCK_SIZE);
int toDo = range.y - range.x;
// Allocate storage for batches of collectively fetched data.
//高斯球编号,坐标,透明度
__shared__ int collected_id[BLOCK_SIZE];
__shared__ float2 collected_xy[BLOCK_SIZE];
__shared__ float4 collected_conic_opacity[BLOCK_SIZE];
// Initialize helper variables
//穿透率,高斯贡献数量,最后高斯数量,颜色
float T = 1.0f;
uint32_t contributor = 0;
uint32_t last_contributor = 0;
float C[CHANNELS] = { 0 };
// Iterate over batches until all done or range is complete
//开始循环计算
for (int i = 0; i < rounds; i++, toDo -= BLOCK_SIZE)
{
// End if entire block votes that it is done rasterizing
int num_done = __syncthreads_count(done);
if (num_done == BLOCK_SIZE)
break;
// Collectively fetch per-Gaussian data from global to shared
//计算高斯球编号,坐标,透明度
int progress = i * BLOCK_SIZE + block.thread_rank();
if (range.x + progress < range.y)
{
int coll_id = point_list[range.x + progress];
collected_id[block.thread_rank()] = coll_id;
collected_xy[block.thread_rank()] = points_xy_image[coll_id];
collected_conic_opacity[block.thread_rank()] = conic_opacity[coll_id];
}
block.sync();
// Iterate over current batch
//开始循环出来需要计算的高斯球
for (int j = 0; !done && j < min(BLOCK_SIZE, toDo); j++)
{
// Keep track of current position in range
contributor++;
// Resample using conic matrix (cf. "Surface
// Splatting" by Zwicker et al., 2001)
float2 xy = collected_xy[j]; //高斯椭圆中心像素坐标
float2 d = { xy.x - pixf.x, xy.y - pixf.y };//像素跟高斯椭圆中心距离
float4 con_o = collected_conic_opacity[j];//2d协方差矩阵的逆和不透明度
// 计算高斯分布概率的指数部分
float power = -0.5f * (con_o.x * d.x * d.x + con_o.z * d.y * d.y) - con_o.y * d.x * d.y;
if (power > 0.0f)
continue;
// Eq. (2) from 3D Gaussian splatting paper.
// Obtain alpha by multiplying with Gaussian opacity
//获取通过透明度连乘后的alpha值
// and its exponential falloff from mean.
// Avoid numerical instabilities (see paper appendix).
//计算alpha值
float alpha = min(0.99f, con_o.w * exp(power));
if (alpha < 1.0f / 255.0f)
continue;
float test_T = T * (1 - alpha);
if (test_T < 0.0001f)
{
done = true;
continue;
}
// Eq. (3) from 3D Gaussian splatting paper.
//计算颜色
for (int ch = 0; ch < CHANNELS; ch++)
C[ch] += features[collected_id[j] * CHANNELS + ch] * alpha * T;
T = test_T;
// Keep track of last range entry to update this
// pixel.
last_contributor = contributor;
}
}
// All threads that treat valid pixel write out their final
// rendering data to the frame and auxiliary buffers.
//最终输出穿透率,贡献数量,颜色
if (inside)
{
final_T[pix_id] = T;
n_contrib[pix_id] = last_contributor;
for (int ch = 0; ch < CHANNELS; ch++)
out_color[ch * H * W + pix_id] = C[ch] + T * bg_color[ch];
}
}更详细的环境搭建,代码详解,实际应用可查看下面视频















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









