








 超级会员免费看
超级会员免费看

 本文深入解析huggingface Trainer的_data处理,包括_get_train_dataloader()函数,涉及dataset与dataloader的创建、采样方法。同时,文章详细解读了optimizer与scheduler的构建过程,包括create_optimizer_and_scheduler()、create_optimizer()和create_scheduler(),阐述了优化器的选择、参数获取及学习策略的设置。
本文深入解析huggingface Trainer的_data处理,包括_get_train_dataloader()函数,涉及dataset与dataloader的创建、采样方法。同时,文章详细解读了optimizer与scheduler的构建过程,包括create_optimizer_and_scheduler()、create_optimizer()和create_scheduler(),阐述了优化器的选择、参数获取及学习策略的设置。
文章目录
- 前言
- 一、self.get_train_dataloader()函数
- 二、创建优化器optimizer与学习策略scheduler
- 总结
前言
在huggingface中,有关trainer内容实在太多了,想完整给出trainer相关内容需要多篇文章来阐明。我想了想,我将布局6篇文章来构建有关内容。第一篇文章介绍TrainingArguments与trainner参数;第二篇文章给出一个完整Demo,并介绍trainner(train与_inner_training_loop)源码的整体结构,呈现一个整体框架;第三篇文章介绍(_inner_training_loop)给出数据构造、优化器构建方法源码解读;第四篇篇文章介绍(_inner_training_loop)中epoch外循环训练相关源码解读;第五篇文章介绍(_inner_training_loop)中step内循环训练相关源码解读;第六篇文章介绍Resume方法内容,包含继承数据、继承优化器、继承模型等实现完整断点续训功能。 而本篇为第三篇文章,主要解读数据与优化器相关等细化内容 。
第一篇文章链接
第二篇文章链接
第三篇文章链接
第四篇文章链接
第五篇文章链接
第六篇文章链接
一、self.get_train_dataloader()函数
这个是上一个节源码补充
这个函数十分重要,这个是对数据的处理,其调用代码如下:
# Data loader and number of training steps
train_dataloader = self.get_train_dataloader()
我继续查看get_train_dataloader函数内部源码,
1、self.get_train_dataloader()函数完整源码
get_train_dataloader(self) -> DataLoader 这段代码是一个函数定义,它的含义是定义了一个函数叫做 get_train_dataloader,这个函数接受一个参数 self,并且返回一个 DataLoader 对象。其官方源码如下:
def get_train_dataloader(self) -> DataLoader:
"""
Returns the training [`~torch.utils.data.DataLoader`].
Will use no sampler if `train_dataset` does not implement `__len__`, a random sampler (adapted to distributed
training if necessary) otherwise.
Subclass and override this method if you want to inject some custom behavior.
"""
if self.train_dataset is None:
raise ValueError("Trainer: training requires a train_dataset.")
train_dataset = self.train_dataset
data_collator = self.data_collator
if is_datasets_available() and isinstance(train_dataset, datasets.Dataset):
train_dataset = self._remove_unused_columns(train_dataset, description="training")
else:
data_collator = self._get_collator_with_removed_columns(data_collator, description="training")
dataloader_params = {
"batch_size": self._train_batch_size,
"collate_fn": data_collator,
"num_workers": self.args.dataloader_num_workers,
"pin_memory": self.args.dataloader_pin_memory,
} # 这个就是dataloader相关参数
if not isinstance(train_dataset, torch.utils.data.IterableDataset):
dataloader_params["sampler"] = self._get_train_sampler()
dataloader_params["drop_last"] = self.args.dataloader_drop_last
dataloader_params["worker_init_fn"] = seed_worker
return self.accelerator.prepare(DataLoader(train_dataset, **dataloader_params)) # 这里是
2、dataset与dataloader
a、dataset与dataloader来源
该值来源trainer类给定参数 train_dataset: Optional[Dataset] = None,也就是我们实例化trainer类传入参数,也是数据处理方法,非常类似torch的dataset方法。而data_loader也可传入,即采用自定义方式包装,也可使用tokenizer中的方法,一般可能是使用tokenizer中的方法,这个参数我在上一节有介绍,可自行参考。其中trainer类的初始化__init__函数处理源码如下:
default_collator = default_data_collator if tokenizer is None else DataCollatorWithPadding(tokenizer)
self.data_collator = data_collator if data_collator is not None else default_collator
self.train_dataset = train_dataset
self.eval_dataset = eval_dataset
self.tokenizer = tokenizer
注:一般dataset只给train_dataset而dataloader一般使用tokenizer的。这2个方法都是在__init__函数中完成了。
b、dataset与dataloader处理
以下代码为get_train_dataloader源码的数据处理内容,实际我们发现self.train_dataset与self.data_collator来源上面__init__获得。然后会走一个self._get_collator_with_removed_columns这个函数,最终得到dataloader_params的变量的字典。
if self.train_dataset is None:
raise ValueError("Trainer: training requires a train_dataset.")
train_dataset = self.train_dataset
data_collator = self.data_collator
if is_datasets_available() and isinstance(train_dataset, datasets.Dataset):
train_dataset = self._remove_unused_columns(train_dataset, description="training")
else:
data_collator = self._get_collator_with_removed_columns(data_collator, description="training")
dataloader_params = {
"batch_size": self._train_batch_size,
"collate_fn": data_collator,
"num_workers": self.args.dataloader_num_workers,
"pin_memory": self.args.dataloader_pin_memory,
} # 这个就是dataloader相关参数
在dataloader_params字典中,比较重要的是 data_collator方法,这个类似pytorch的dataloader中的collate_fn方法。
c、self._get_collator_with_removed_columns()函数获得collate_fn
该函数源码如下,我这里将不在解释细节了。这里理解是collate_fn的方法就可以了。
def _get_collator_with_removed_columns(
self, data_collator: Callable, description: Optional[str] = None
) -> Callable:
"""Wrap the data collator in a callable removing unused columns."""
if not self.args.remove_unused_columns:
return data_collator
self._set_signature_columns_if_needed()
signature_columns = self._signature_columns
remove_columns_collator = RemoveColumnsCollator(
data_collator=data_collator,
signature_columns=signature_columns,
logger=logger,
description=description,
model_name=self.model.__class__.__name__,
)
return remove_columns_collator
3、self._get_train_sampler()采样方法
b中获得dataset与dataloader方式,特别是collate_fn的方法,紧接着获得如何采样方式。这个关系到中断程序,继承数据中断地方继续采样。可以说,也应该是后面我要说如何构建resume比较关键地方。
a、采样方法调用
代码会通过判断而进入如下采样方法,这里self._get_train_sampler()函数就是重点,当然这些函数都是trainer类中的子函数,我们后期可以进行继承方式构建采样策略。
if not isinstance(train_dataset, torch.utils.data.IterableDataset):
dataloader_params["sampler"] = self._get_train_sampler()
dataloader_params["drop_last"] = self.args.dataloader_drop_last
dataloader_params["worker_init_fn"] = seed_worker
b、self._get_train_sampler()源码解读
这段代码是一个私有方法 _get_train_sampler 的定义,它接受一个参数 self,并且声明返回一个类型为 Optional[torch.utils.data.Sampler] 的对象,即可能返回一个 Sampler 对象,也可能返回 None。这个方法的作用是根据一些条件来获取训练数据的采样器(sampler)。让我逐行解释并加上注释:
def _get_train_sampler(self) -> Optional[torch.utils.data.Sampler]:
# 如果训练数据集为None或者没有长度信息,返回None
if self.train_dataset is None or not has_length(self.train_dataset):
return None
# 构建采样器
if self.args.group_by_length:
# 如果启用了按长度分组,并且datasets可用且train_dataset是datasets.Dataset类型
if is_datasets_available() and isinstance(self.train_dataset, datasets.Dataset):
# 获取训练数据集中的长度信息
lengths = (
self.train_dataset[self.args.length_column_name]
if self.args.length_column_name in self.train_dataset.column_names
else None
)
else:
lengths = None
# 获取模型输入名称
model_input_name = self.tokenizer.model_input_names[0] if self.tokenizer is not None else None
# 返回一个LengthGroupedSampler对象,用于按长度分组采样
return LengthGroupedSampler(
self.args.train_batch_size * self.args.gradient_accumulation_steps,
dataset=self.train_dataset,
lengths=lengths,
model_input_name=model_input_name,
)
else:
# 如果不按长度分组,则返回一个随机采样器RandomSampler
return RandomSampler(self.train_dataset)
这个方法根据是否启用了按长度分组来选择不同的采样器。如果启用了按长度分组,会返回一个 LengthGroupedSampler 对象,用于按照数据长度分组采样;如果没有启用按长度分组,则返回一个 RandomSampler 对象,用于随机采样。
最后,不按长度直接调用RandomSampler(self.train_dataset)的方式。
c、RandomSampler(self.train_dataset)源码解读
class RandomSampler(Sampler[int]):
r"""随机抽样元素。如果不重复抽样,则从洗牌后的数据集中抽样。如果有重复抽样,则用户可以指定要抽取的样本数量。
参数:
data_source(数据集):要从中抽样的数据集
replacement(bool):如果为“True”,则按需进行有放回抽样,默认为“False”
num_samples(int):要抽取的样本数量,默认为len(dataset)。
generator(生成器):用于抽样的生成器。
"""
data_source: Sized
replacement: bool
def __init__(self, data_source: Sized, replacement: bool = False,
num_samples: Optional[int] = None, generator=None) -> None:
# 初始化方法,接受数据集、是否有放回抽样、抽样数量和生成器作为参数
self.data_source = data_source
self.replacement = replacement
self._num_samples = num_samples
self.generator = generator
# 检查参数类型
if not isinstance(self.replacement, bool):
raise TypeError("replacement should be a boolean value, but got "
"replacement={}".format(self.replacement))
if not isinstance(self.num_samples, int) or self.num_samples <= 0:
raise ValueError("num_samples should be a positive integer "
"value, but got num_samples={}".format(self.num_samples))
@property
def num_samples(self) -> int:
# 获取抽样数量,如果没有指定则返回数据集长度
if self._num_samples is None:
return len(self.data_source)
return self._num_samples
def __iter__(self) -> Iterator[int]:
# 生成迭代器的方法
n = len(self.data_source)
...
d、RandomSampler(self.train_dataset)的迭代器__iter__
上面最重要函数是迭代器函数__iter__,我将在代码中注释默认迭代器函数选择内容,其代码如下:
def __iter__(self) -> Iterator[int]:
n = len(self.data_source)
if self.generator is None: # 选择这个,默认为None,使用torch的Generator(),而该部分在文章上面有第二节有介绍
seed = int(torch.empty((), dtype=torch.int64).random_().item())
generator = torch.Generator()
generator.manual_seed(seed)
else:
generator = self.generator
if self.replacement: # 这个选项为False
for _ in range(self.num_samples // 32):
yield from torch.randint(high=n, size=(32,), dtype=torch.int64, generator=generator).tolist()
yield from torch.randint(high=n, size=(self.num_samples % 32,), dtype=torch.int64, generator=generator).tolist()
else: # 选择这里
for _ in range(self.num_samples // n):
yield from torch.randperm(n, generator=generator).tolist()
yield from torch.randperm(n, generator=generator).tolist()[:self.num_samples % n]
而以下代码表示选择哪个,第一个是个循环循环,表示self.num_samples // n能除尽的取值迭代,而不能除尽在后面迭代,这样我感觉最后被n除有余会取余下迭代,但这不影响模型。
for _ in range(self.num_samples // n):
yield from torch.randperm(n, generator=generator).tolist()
yield from torch.randperm(n, generator=generator).tolist()[:self.num_samples % n]
4、数据的dataloader与accelerator加速
trainer对数据处理也是调用torch的dataloader方法,因此需传dataset(这里是train_dataset)和与dataloader相关参数params(这里是dataloader_params),而该参数包含2个部分内容:
第一部分内容:
dataloader_params = {
"batch_size": self._train_batch_size,
"collate_fn": data_collator,
"num_workers": self.args.dataloader_num_workers,
"pin_memory": self.args.dataloader_pin_memory,
} # 这个就是dataloader相关参数
第二部分内容:
dataloader_params["sampler"] = self._get_train_sampler()
dataloader_params["drop_last"] = self.args.dataloader_drop_last
dataloader_params["worker_init_fn"] = seed_worker
我们可以发现dataloader_params参数中最重要的参数是给出了collate_fn方法和采样sampler方法,也就是我上面讲述内容。
最后加速与包装及调用dataloader源码如下:
return self.accelerator.prepare(DataLoader(train_dataset, **dataloader_params)) # 这里是
注:这里我们可以通过trainer方法集成该函数,自然就可以根据需求给出collate_fn与采样方法。
二、创建优化器optimizer与学习策略scheduler
这个很重要,在这里会用到以下代码创造优化器和学习策略,这个地方也是self.create_optimizer_and_scheduler该方法,而该方法函数会调用相关优化器与策略。为此,后期我们需要使用resume方法,可明确哪里继承和使用。
if not delay_optimizer_creation:
self.create_optimizer_and_scheduler(num_training_steps=max_steps)
1、self.create_optimizer_and_scheduler(num_training_steps=max_steps)源码解读
实际该函数已经说的很清楚了,就是设置优化器和学习率调度器。提供一个表现良好的合理默认值。如果您想使用其他内容,可以通过 Trainer 的 init 传递一个元组到 optimizers,或者在子类中重写这个方法(或 create_optimizer 和/或 create_scheduler)。
def create_optimizer_and_scheduler(self, num_training_steps: int):
"""
Setup the optimizer and the learning rate scheduler.
We provide a reasonable default that works well. If you want to use something else, you can pass a tuple in the
Trainer's init through `optimizers`, or subclass and override this method (or `create_optimizer` and/or
`create_scheduler`) in a subclass.
"""
self.create_optimizer()
if IS_SAGEMAKER_MP_POST_1_10 and smp.state.cfg.fp16:
# If smp >= 1.10 and fp16 is enabled, we unwrap the optimizer
optimizer = self.optimizer.optimizer
else:
optimizer = self.optimizer
self.create_scheduler(num_training_steps=num_training_steps, optimizer=optimizer)
2、self.create_optimizer()优化器源码解读
该函数就是设置优化器。提供一个表现良好的合理默认值。如果您想使用其他内容,可以通过在 Trainer 的初始化中通过 optimizers 传递一个元组,或者子类化并在子类中覆盖此方法。我也将源码给出,这样可方便后期继承trainer类中的create_optimizer函数。
def create_optimizer(self):
"""
Setup the optimizer.
We provide a reasonable default that works well. If you want to use something else, you can pass a tuple in the
Trainer's init through `optimizers`, or subclass and override this method in a subclass.
"""
opt_model = self.model_wrapped if is_sagemaker_mp_enabled() else self.model
if self.optimizer is None:
decay_parameters = get_parameter_names(opt_model, ALL_LAYERNORM_LAYERS)
decay_parameters = [name for name in decay_parameters if "bias" not in name]
optimizer_grouped_parameters = [
{
"params": [
p for n, p in opt_model.named_parameters() if (n in decay_parameters and p.requires_grad)
],
"weight_decay": self.args.weight_decay,
},
{
"params": [
p for n, p in opt_model.named_parameters() if (n not in decay_parameters and p.requires_grad)
],
"weight_decay": 0.0,
},
]
optimizer_cls, optimizer_kwargs = Trainer.get_optimizer_cls_and_kwargs(self.args)
if self.sharded_ddp == ShardedDDPOption.SIMPLE:
self.optimizer = OSS(
params=optimizer_grouped_parameters,
optim=optimizer_cls,
**optimizer_kwargs,
)
else:
self.optimizer = optimizer_cls(optimizer_grouped_parameters, **optimizer_kwargs)
if optimizer_cls.__name__ == "Adam8bit":
import bitsandbytes
manager = bitsandbytes.optim.GlobalOptimManager.get_instance()
skipped = 0
for module in opt_model.modules():
if isinstance(module, nn.Embedding):
skipped += sum({p.data_ptr(): p.numel() for p in module.parameters()}.values())
logger.info(f"skipped {module}: {skipped/2**20}M params")
manager.register_module_override(module, "weight", {"optim_bits": 32})
logger.debug(f"bitsandbytes: will optimize {module} in fp32")
logger.info(f"skipped: {skipped/2**20}M params")
if is_sagemaker_mp_enabled():
self.optimizer = smp.DistributedOptimizer(self.optimizer)
return self.optimizer
a、优化器模型参数获取(get_parameter_names)
在这个函数create_optimizer(self)中获取模型参数方法decay_parameters = get_parameter_names(opt_model, ALL_LAYERNORM_LAYERS),其代码如下:
def get_parameter_names(model, forbidden_layer_types):
"""
Returns the names of the model parameters that are not inside a forbidden layer.
"""
result = []
for name, child in model.named_children():
result += [
f"{name}.{n}"
for n in get_parameter_names(child, forbidden_layer_types)
if not isinstance(child, tuple(forbidden_layer_types))
]
# Add model specific parameters (defined with nn.Parameter) since they are not in any child.
result += list(model._parameters.keys())
return result
这个函数不再介绍了,优化器是需要通过模型获取参数,方便后续如何分配学习率等。
b、Trainer.get_optimizer_cls_and_kwargs(self.args)源码解读
在上面获得相关模型参数,之后该实现如何创建优化器。而该函数optimizer_cls, optimizer_kwargs = Trainer.get_optimizer_cls_and_kwargs(self.args)又是通过self.args参数配置,选择调用哪个优化器以及相关参数。而返回optimizer_cls, optimizer_kwargs变量分别表示选择优化器与优化器对应的参数。我先Trainer.get_optimizer_cls_and_kwargs(self.args)给出该函数完整代码,在详细介绍其源码内容。
one、完整源码
首先呈现完整源码,其代码如下:
@staticmethod
def get_optimizer_cls_and_kwargs(args: TrainingArguments) -> Tuple[Any, Any]:
"""
Returns the optimizer class and optimizer parameters based on the training arguments.
Args:
args (`transformers.training_args.TrainingArguments`):
The training arguments for the training session.
"""
# parse args.optim_args
optim_args = {}
if args.optim_args:
for mapping in args.optim_args.replace(" ", "").split(","):
key, value = mapping.split("=")
optim_args[key] = value
optimizer_kwargs = {"lr": args.learning_rate}
adam_kwargs = {
"betas": (args.adam_beta1, args.adam_beta2),
"eps": args.adam_epsilon,
}
if args.optim == OptimizerNames.ADAFACTOR:
optimizer_cls = Adafactor
optimizer_kwargs.update({"scale_parameter": False, "relative_step": False})
elif args.optim == OptimizerNames.ADAMW_HF:
from .optimization import AdamW
optimizer_cls = AdamW
optimizer_kwargs.update(adam_kwargs)
elif args.optim in [OptimizerNames.ADAMW_TORCH, OptimizerNames.ADAMW_TORCH_FUSED]:
from torch.optim import AdamW
optimizer_cls = AdamW
optimizer_kwargs.update(adam_kwargs)
if args.optim == OptimizerNames.ADAMW_TORCH_FUSED:
optimizer_kwargs.update({"fused": True})
elif args.optim == OptimizerNames.ADAMW_TORCH_XLA:
try:
from torch_xla.amp.syncfree import AdamW
optimizer_cls = AdamW
optimizer_kwargs.update(adam_kwargs)
except ImportError:
raise ValueError("Trainer failed to import syncfree AdamW from torch_xla.")
elif args.optim == OptimizerNames.ADAMW_APEX_FUSED:
try:
from apex.optimizers import FusedAdam
optimizer_cls = FusedAdam
optimizer_kwargs.update(adam_kwargs)
except ImportError:
raise ValueError("Trainer tried to instantiate apex FusedAdam but apex is not installed!")
elif args.optim in [
OptimizerNames.ADAMW_BNB,
OptimizerNames.ADAMW_8BIT,
OptimizerNames.PAGED_ADAMW,
OptimizerNames.PAGED_ADAMW_8BIT,
OptimizerNames.LION,
OptimizerNames.LION_8BIT,
OptimizerNames.PAGED_LION,
OptimizerNames.PAGED_LION_8BIT,
]:
try:
from bitsandbytes.optim import AdamW, Lion
is_paged = False
optim_bits = 32
optimizer_cls = None
additional_optim_kwargs = adam_kwargs
if "paged" in args.optim:
is_paged = True
if "8bit" in args.optim:
optim_bits = 8
if "adam" in args.optim:
optimizer_cls = AdamW
elif "lion" in args.optim:
optimizer_cls = Lion
additional_optim_kwargs = {"betas": (args.adam_beta1, args.adam_beta2)}
bnb_kwargs = {"is_paged": is_paged, "optim_bits": optim_bits}
optimizer_kwargs.update(additional_optim_kwargs)
optimizer_kwargs.update(bnb_kwargs)
except ImportError:
raise ValueError("Trainer tried to instantiate bnb optimizer but bnb is not installed!")
elif args.optim == OptimizerNames.ADAMW_BNB:
try:
from bitsandbytes.optim import Adam8bit
optimizer_cls = Adam8bit
optimizer_kwargs.update(adam_kwargs)
except ImportError:
raise ValueError("Trainer tried to instantiate bnb Adam8bit but bnb is not installed!")
elif args.optim == OptimizerNames.ADAMW_ANYPRECISION:
try:
from torchdistx.optimizers import AnyPrecisionAdamW
optimizer_cls = AnyPrecisionAdamW
optimizer_kwargs.update(adam_kwargs)
# TODO Change dtypes back to M=FP32, Var = BF16, Kahan = False once they can be cast together in torchdistx.
optimizer_kwargs.update(
{
"use_kahan_summation": strtobool(optim_args.get("use_kahan_summation", "False")),
"momentum_dtype": getattr(torch, optim_args.get("momentum_dtype", "float32")),
"variance_dtype": getattr(torch, optim_args.get("variance_dtype", "float32")),
"compensation_buffer_dtype": getattr(
torch, optim_args.get("compensation_buffer_dtype", "bfloat16")
),
}
)
except ImportError:
raise ValueError("Please install https://github.com/pytorch/torchdistx")
elif args.optim == OptimizerNames.SGD:
optimizer_cls = torch.optim.SGD
elif args.optim == OptimizerNames.ADAGRAD:
optimizer_cls = torch.optim.Adagrad
else:
raise ValueError(f"Trainer cannot instantiate unsupported optimizer: {args.optim}")
return optimizer_cls, optimizer_kwargs
two、trainer对优化器选择构建OptimizerNames类
该类是参数args.optim参数选择使用哪个优化器,右边是名字,有很多种优化器供选择,其源码码如下:
class OptimizerNames(ExplicitEnum):
"""
Stores the acceptable string identifiers for optimizers.
"""
ADAMW_HF = "adamw_hf"
ADAMW_TORCH = "adamw_torch"
ADAMW_TORCH_FUSED = "adamw_torch_fused"
ADAMW_TORCH_XLA = "adamw_torch_xla"
ADAMW_APEX_FUSED = "adamw_apex_fused"
ADAFACTOR = "adafactor"
ADAMW_ANYPRECISION = "adamw_anyprecision"
SGD = "sgd"
ADAGRAD = "adagrad"
ADAMW_BNB = "adamw_bnb_8bit"
ADAMW_8BIT = "adamw_8bit" # just an alias for adamw_bnb_8bit
LION_8BIT = "lion_8bit"
LION = "lion_32bit"
PAGED_ADAMW = "paged_adamw_32bit"
PAGED_ADAMW_8BIT = "paged_adamw_8bit"
PAGED_LION = "paged_lion_32bit"
PAGED_LION_8BIT = "paged_lion_8bit"
这里给出选择优化器源码示列,如下图:
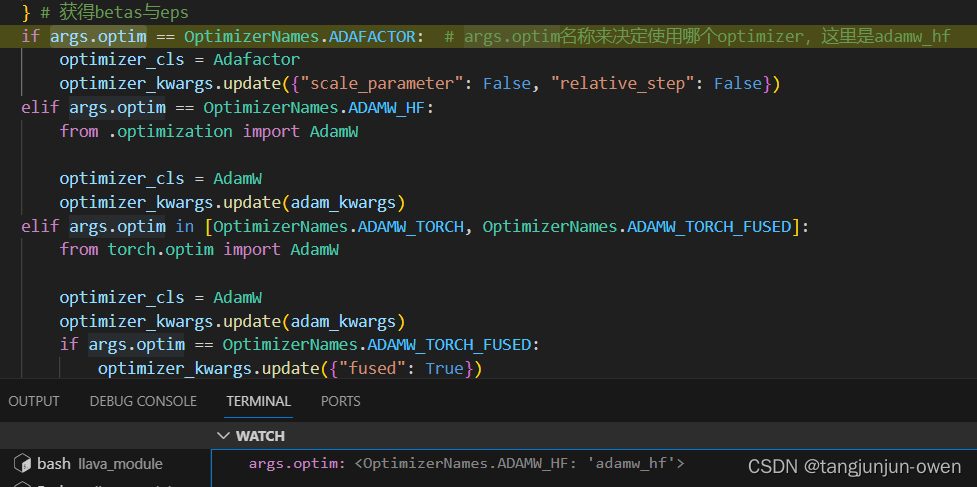
这个是对优化器选择额外介绍
three、优化器参数更新
这里,我们开始解读优化器相关内容,首先是优化器相关参数设置,如下代码:
optimizer_kwargs = {"lr": args.learning_rate} # 这个地方获得学习率,很重要
adam_kwargs = {
"betas": (args.adam_beta1, args.adam_beta2),
"eps": args.adam_epsilon,
} # 获得betas与eps
这里特别注意学习率和相关参数都是通过args给配置的,我们可以传参时候修改!
four、优化器选择与创建
本实例使用默认优化器,调用如下代码:
elif args.optim == OptimizerNames.ADAMW_HF:
from .optimization import AdamW
optimizer_cls = AdamW
optimizer_kwargs.update(adam_kwargs)
这里需要明确optimizer_kwargs参数与优化器optimizer_cls,其结果如下图:
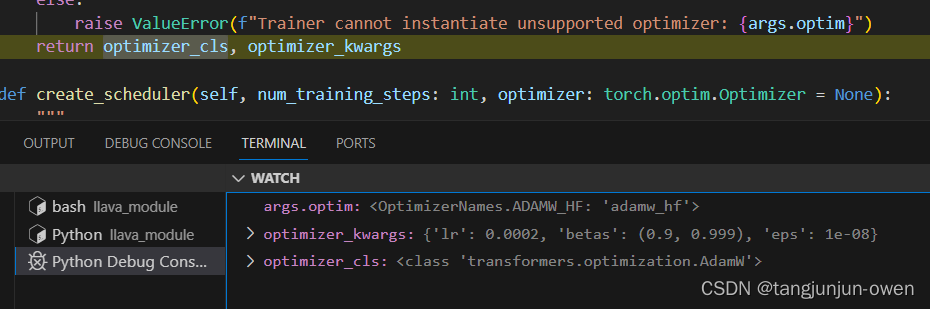
最终,直接跳到返回return optimizer_cls, optimizer_kwargs优化器与对应参数。在与返回之间代码也是优化器选择东西,不再介绍。
five、总结
1、返回2个值optimizer_cls, optimizer_kwargs,第一个值是优化器,第二个值是对应参数,特别重要是学习率。
2、这里知道返回也是调用torch相关优化器,那么在返回后我们或许可进行更改在self.create_optimizer()函数中。
3、在```optimizer_cls, optimizer_kwargs = Trainer.get_optimizer_cls_and_kwargs(self.args)`这个位置之后修改,比如学习率赋值等,这样后面就直接抄,可不用修改。
c、构建优化器
在上面选择了对应优化器与相关参数,紧接着是如何将优化器实例化了,如下代码就是通过不同选择将上面获得优化器与相关参数进行实例化。
if self.sharded_ddp == ShardedDDPOption.SIMPLE:
self.optimizer = OSS(
params=optimizer_grouped_parameters,
optim=optimizer_cls,
**optimizer_kwargs,
)
else:
self.optimizer = optimizer_cls(optimizer_grouped_parameters, **optimizer_kwargs)
if optimizer_cls.__name__ == "Adam8bit":
import bitsandbytes
manager = bitsandbytes.optim.GlobalOptimManager.get_instance()
skipped = 0
for module in opt_model.modules():
if isinstance(module, nn.Embedding):
skipped += sum({p.data_ptr(): p.numel() for p in module.parameters()}.values())
logger.info(f"skipped {module}: {skipped/2**20}M params")
manager.register_module_override(module, "weight", {"optim_bits": 32})
logger.debug(f"bitsandbytes: will optimize {module} in fp32")
logger.info(f"skipped: {skipped/2**20}M params")
重点说明:这里optimizer_grouped_parameters很重要!
而后面代码是相关配置,可忽略,本实列也没用到。
one、优化器参数说明
这里包含2个参数optimizer_grouped_parameters, optimizer_kwargs,我将给予说明。
optimizer_grouped_parameters:来源模型参数,这些参数才配置优化器,才能实现梯度更新学习;
optimizer_kwargs:来源对应优化器相关参数,使用args方式配置;
two、优化器构建
本实列使用以下方式将优化器实例化,以默认优化器为例,则将optimizer_cls看做来源from .optimization import AdamW的AdamW优化器类,其代码如下:
self.optimizer = optimizer_cls(optimizer_grouped_parameters, **optimizer_kwargs)
重点说明:创建优化器赋值给了self.optimizer,同时该self.optimizer也是给了trainer类的,谨记!
3、self.create_scheduler()优化器策略源码解读
该函数就是设置优化器的策略。self.create_scheduler(num_training_steps=num_training_steps, optimizer=optimizer)实现优化器策略,如果你也想更换策略,那就随我一起解读,到时候你可以继承trainer类在重构它的self.create_scheduler来实现。然而重构这个我们需要知道self.create_scheduler函数参数意义,其中num_training_steps表示迭代总数,若有30个数据循环2个epoch,该值等于30*2=60;optimizer是上面给的优化器。
self.create_scheduler(num_training_steps=num_training_steps, optimizer=optimizer)
a、self.create_scheduler()源码解读
该函数就是创建优化器策略,并将其传给self.lr_scheduler,也设置self._created_lr_scheduler = True。而返回self.lr_scheduler来源get_scheduler函数,我下面将介绍。
注释翻译:
设置scheduler程序。在调用此方法之前,训练器的优化器必须已经设置好,或者作为参数传递。
参数:
num_training_steps (int): 要执行的训练步数。
def create_scheduler(self, num_training_steps: int, optimizer: torch.optim.Optimizer = None):
"""
Setup the scheduler. The optimizer of the trainer must have been set up either before this method is called or
passed as an argument.
Args:
num_training_steps (int): The number of training steps to do.
"""
if self.lr_scheduler is None:
self.lr_scheduler = get_scheduler(
self.args.lr_scheduler_type,
optimizer=self.optimizer if optimizer is None else optimizer,
num_warmup_steps=self.args.get_warmup_steps(num_training_steps),
num_training_steps=num_training_steps,
)
self._created_lr_scheduler = True
return self.lr_scheduler
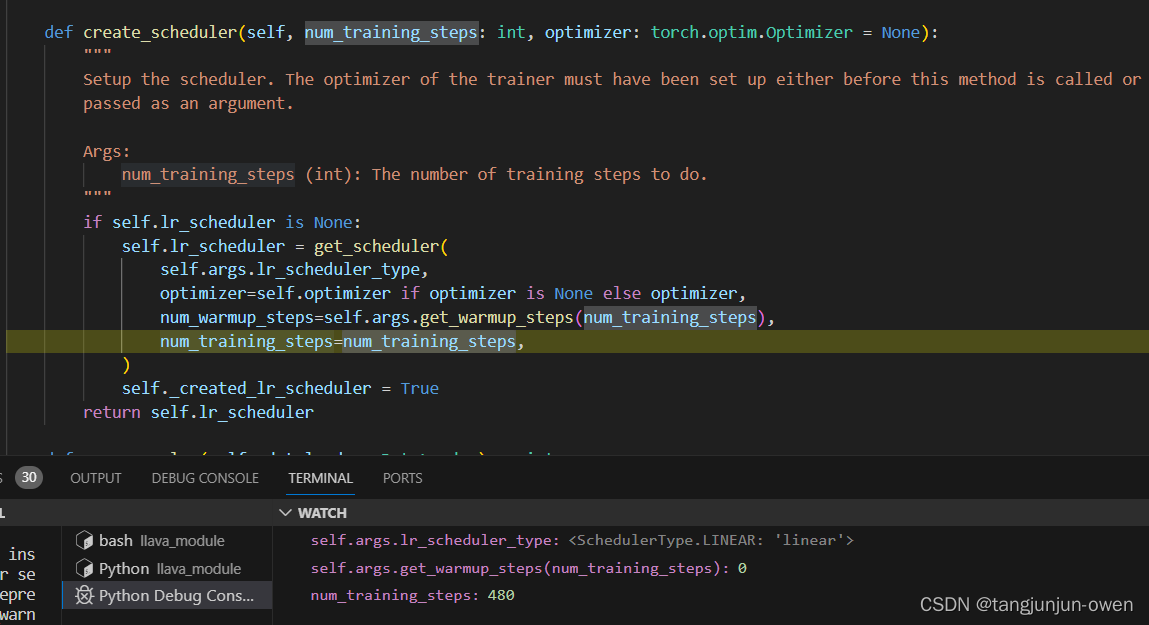
b、get_scheduler参数说明
self.args.lr_scheduler_type:选择使用什么方式
optimizer=self.optimizer if optimizer is None else optimizer:如果传递了优化器就用optimizer否则使用self.optimizer
num_warmup_steps=self.args.get_warmup_steps(num_training_steps):给出warmup步数
num_training_steps=num_training_steps:就是上面解释的若有30个数据循环2个epoch,该值等于30*2=60
其参数图示如下图:
而get_warmup_steps如下代码:
def get_warmup_steps(self, num_training_steps: int):
"""
Get number of steps used for a linear warmup.
"""
warmup_steps = (
self.warmup_steps if self.warmup_steps > 0 else math.ceil(num_training_steps * self.warmup_ratio)
)
return warmup_steps
我需要说明下,这个函数来源class TrainingArguments:类,这个里面参数在我上上节博客这里提到过,也就是个类的参数控制了warmup步数。这个参数self.warmup_steps设置且大于0那么步数直接使用它,否则使用else代码,该代码self.warmup_ratio参数需要设定,按照比率获取warmup的数字。
c、get_scheduler完整源码
该函数位于huggingface的transformers库中的optimization.py文件中,就是一个函数,其代码如下。
官方源码注释翻译:
统一的API,通过其名称获取任何调度器。
参数:
name(str或SchedulerType):要使用的调度器的名称。
optimizer(torch.optim.Optimizer):训练期间将使用的优化器。
num_warmup_steps(int,可选):要执行的热身步数。并非所有调度器都需要此参数(因此参数是可选的),如果未设置且调度器类型需要它,则函数将引发错误。
num_training_steps(int,可选):要执行的训练步数。并非所有调度器都需要此参数(因此参数是可选的),如果未设置且调度器类型需要它,则函数将引发错误。
def get_scheduler(
name: Union[str, SchedulerType],
optimizer: Optimizer,
num_warmup_steps: Optional[int] = None,
num_training_steps: Optional[int] = None,
):
"""
Unified API to get any scheduler from its name.
Args:
name (`str` or `SchedulerType`):
The name of the scheduler to use.
optimizer (`torch.optim.Optimizer`):
The optimizer that will be used during training.
num_warmup_steps (`int`, *optional*):
The number of warmup steps to do. This is not required by all schedulers (hence the argument being
optional), the function will raise an error if it's unset and the scheduler type requires it.
num_training_steps (`int``, *optional*):
The number of training steps to do. This is not required by all schedulers (hence the argument being
optional), the function will raise an error if it's unset and the scheduler type requires it.
"""
name = SchedulerType(name)
schedule_func = TYPE_TO_SCHEDULER_FUNCTION[name]
if name == SchedulerType.CONSTANT or name == SchedulerType.REDUCE_ON_PLATEAU:
return schedule_func(optimizer)
# All other schedulers require `num_warmup_steps`
if num_warmup_steps is None:
raise ValueError(f"{name} requires `num_warmup_steps`, please provide that argument.")
if name == SchedulerType.CONSTANT_WITH_WARMUP:
return schedule_func(optimizer, num_warmup_steps=num_warmup_steps)
if name == SchedulerType.INVERSE_SQRT:
return schedule_func(optimizer, num_warmup_steps=num_warmup_steps)
# All other schedulers require `num_training_steps`
if num_training_steps is None:
raise ValueError(f"{name} requires `num_training_steps`, please provide that argument.")
return schedule_func(optimizer, num_warmup_steps=num_warmup_steps, num_training_steps=num_training_steps)
这个写法和之前optimizer格式类似。
d、SchedulerType(name)
name = SchedulerType(name)根据第一个参数获取对应名称,其不同方法名称如下:
class SchedulerType(ExplicitEnum):
LINEAR = "linear"
COSINE = "cosine"
COSINE_WITH_RESTARTS = "cosine_with_restarts"
POLYNOMIAL = "polynomial"
CONSTANT = "constant"
CONSTANT_WITH_WARMUP = "constant_with_warmup"
INVERSE_SQRT = "inverse_sqrt"
REDUCE_ON_PLATEAU = "reduce_lr_on_plateau"
在使用schedule_func = TYPE_TO_SCHEDULER_FUNCTION[name]获得实际优化器策略方法,不同策略方法如下。需说明右边的value是不同方法名称。
TYPE_TO_SCHEDULER_FUNCTION = {
SchedulerType.LINEAR: get_linear_schedule_with_warmup,
SchedulerType.COSINE: get_cosine_schedule_with_warmup,
SchedulerType.COSINE_WITH_RESTARTS: get_cosine_with_hard_restarts_schedule_with_warmup,
SchedulerType.POLYNOMIAL: get_polynomial_decay_schedule_with_warmup,
SchedulerType.CONSTANT: get_constant_schedule,
SchedulerType.CONSTANT_WITH_WARMUP: get_constant_schedule_with_warmup,
SchedulerType.INVERSE_SQRT: get_inverse_sqrt_schedule,
SchedulerType.REDUCE_ON_PLATEAU: get_reduce_on_plateau_schedule,
}
注:上面的方法都是独立函数。
紧接着,我get_linear_schedule_with_warmup函数方法为列来展开介绍。
one、get_linear_schedule_with_warmup函数源码解读
创建一个学习率调度,其中学习率从优化器中设置的初始学习率线性减少到0,在此之前有一个热身阶段,在此阶段学习率从0线性增加到优化器中设置的初始学习率。
参数:
optimizer([~torch.optim.Optimizer]):要调整学习率的优化器。
num_warmup_steps(int):热身阶段的步数。
num_training_steps(int):总训练步数。
last_epoch(int,可选,默认为-1):恢复训练时的最后一个周期的索引。
返回:
具有适当调度的 torch.optim.lr_scheduler.LambdaLR。
def get_linear_schedule_with_warmup(optimizer, num_warmup_steps, num_training_steps, last_epoch=-1):
"""
Create a schedule with a learning rate that decreases linearly from the initial lr set in the optimizer to 0, after
a warmup period during which it increases linearly from 0 to the initial lr set in the optimizer.
Args:
optimizer ([`~torch.optim.Optimizer`]):
The optimizer for which to schedule the learning rate.
num_warmup_steps (`int`):
The number of steps for the warmup phase.
num_training_steps (`int`):
The total number of training steps.
last_epoch (`int`, *optional*, defaults to -1):
The index of the last epoch when resuming training.
Return:
`torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
"""
lr_lambda = partial(
_get_linear_schedule_with_warmup_lr_lambda,
num_warmup_steps=num_warmup_steps,
num_training_steps=num_training_steps,
)
return LambdaLR(optimizer, lr_lambda, last_epoch)
这里lr_lambda是_get_linear_schedule_with_warmup_lr_lambda函数,只是通过partial给其提前输入num_warmup_steps、 num_training_steps参数。
two、_get_linear_schedule_with_warmup_lr_lambda函数源码
上面只传了num_warmup_steps、 num_training_steps参数,若current_step大小于num_warmup_steps则使用current_steps/num_warmup_steps方式,否则(num_training_steps - current_step) / ( num_training_steps - num_warmup_steps)方式,可看出都是随着迭代次数增加,返回值都在减小。
def _get_linear_schedule_with_warmup_lr_lambda(current_step: int, *, num_warmup_steps: int, num_training_steps: int):
if current_step < num_warmup_steps:
return float(current_step) / float(max(1, num_warmup_steps))
return max(0.0, float(num_training_steps - current_step) / float(max(1, num_training_steps - num_warmup_steps)))
three、LambdaLR(optimizer, lr_lambda, last_epoch)实例化
紧接着,进行实例化,其方法如下,我想说这里包含了优化器策略加载等方式,我暂时不说,等我使用resume涉及到在给大家解读。
注释翻译:
将每个参数组的学习率设置为初始学习率乘以给定函数。当 last_epoch=-1 时,将初始学习率设置为 lr。
参数:
optimizer(Optimizer):封装的优化器。
lr_lambda(函数或列表):一个函数,根据整数参数 epoch 计算乘法因子,或者一个这样的函数列表,每个函数对应 optimizer.param_groups 中的一个组。
last_epoch(int):最后一个周期的索引。默认值:-1。
verbose(bool):如果为 True,则为每次更新在标准输出打印一条消息。默认值:False。
示例:
>>> # 假设优化器有两个组。
>>> lambda1 = lambda epoch: epoch // 30
>>> lambda2 = lambda epoch: 0.95 ** epoch
>>> scheduler = LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()
class LambdaLR(LRScheduler):
"""Sets the learning rate of each parameter group to the initial lr
times a given function. When last_epoch=-1, sets initial lr as lr.
Args:
optimizer (Optimizer): Wrapped optimizer.
lr_lambda (function or list): A function which computes a multiplicative
factor given an integer parameter epoch, or a list of such
functions, one for each group in optimizer.param_groups.
last_epoch (int): The index of last epoch. Default: -1.
verbose (bool): If ``True``, prints a message to stdout for
each update. Default: ``False``.
Example:
>>> # xdoctest: +SKIP
>>> # Assuming optimizer has two groups.
>>> lambda1 = lambda epoch: epoch // 30
>>> lambda2 = lambda epoch: 0.95 ** epoch
>>> scheduler = LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()
"""
def __init__(self, optimizer, lr_lambda, last_epoch=-1, verbose=False):
self.optimizer = optimizer
if not isinstance(lr_lambda, list) and not isinstance(lr_lambda, tuple):
self.lr_lambdas = [lr_lambda] * len(optimizer.param_groups)
else:
if len(lr_lambda) != len(optimizer.param_groups):
raise ValueError("Expected {} lr_lambdas, but got {}".format(
len(optimizer.param_groups), len(lr_lambda)))
self.lr_lambdas = list(lr_lambda)
super().__init__(optimizer, last_epoch, verbose)
def state_dict(self):
"""Returns the state of the scheduler as a :class:`dict`.
It contains an entry for every variable in self.__dict__ which
is not the optimizer.
The learning rate lambda functions will only be saved if they are callable objects
and not if they are functions or lambdas.
When saving or loading the scheduler, please make sure to also save or load the state of the optimizer.
"""
state_dict = {key: value for key, value in self.__dict__.items() if key not in ('optimizer', 'lr_lambdas')}
state_dict['lr_lambdas'] = [None] * len(self.lr_lambdas)
for idx, fn in enumerate(self.lr_lambdas):
if not isinstance(fn, types.FunctionType):
state_dict['lr_lambdas'][idx] = fn.__dict__.copy()
return state_dict
def load_state_dict(self, state_dict):
"""Loads the schedulers state.
When saving or loading the scheduler, please make sure to also save or load the state of the optimizer.
Args:
state_dict (dict): scheduler state. Should be an object returned
from a call to :meth:`state_dict`.
"""
lr_lambdas = state_dict.pop('lr_lambdas')
self.__dict__.update(state_dict)
# Restore state_dict keys in order to prevent side effects
# https://github.com/pytorch/pytorch/issues/32756
state_dict['lr_lambdas'] = lr_lambdas
for idx, fn in enumerate(lr_lambdas):
if fn is not None:
self.lr_lambdas[idx].__dict__.update(fn)
def get_lr(self):
if not self._get_lr_called_within_step:
warnings.warn("To get the last learning rate computed by the scheduler, "
"please use `get_last_lr()`.")
return [base_lr * lmbda(self.last_epoch)
for lmbda, base_lr in zip(self.lr_lambdas, self.base_lrs)]
e、策略选择与调用
随后根据参数选择对应优化器策略与相应的参数来调用其方法,如下代码:
if name == SchedulerType.CONSTANT or name == SchedulerType.REDUCE_ON_PLATEAU:
return schedule_func(optimizer)
# All other schedulers require `num_warmup_steps`
if num_warmup_steps is None:
raise ValueError(f"{name} requires `num_warmup_steps`, please provide that argument.")
if name == SchedulerType.CONSTANT_WITH_WARMUP:
return schedule_func(optimizer, num_warmup_steps=num_warmup_steps)
if name == SchedulerType.INVERSE_SQRT:
return schedule_func(optimizer, num_warmup_steps=num_warmup_steps)
# All other schedulers require `num_training_steps`
if num_training_steps is None:
raise ValueError(f"{name} requires `num_training_steps`, please provide that argument.")
return schedule_func(optimizer, num_warmup_steps=num_warmup_steps, num_training_steps=num_training_steps)
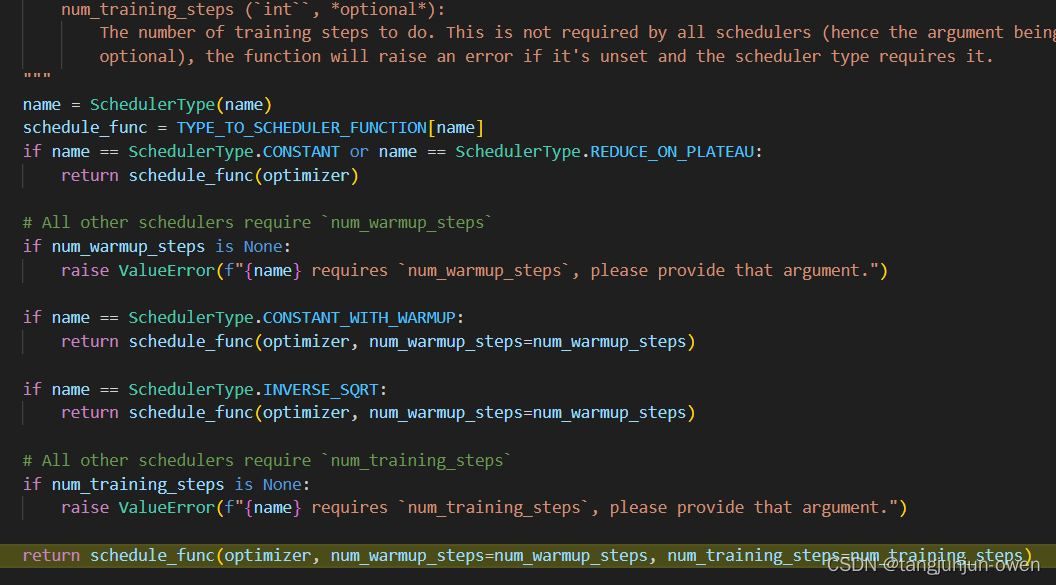
f、策略返回
自然而然, return LambdaLR(optimizer, lr_lambda, last_epoch)返回必然是一个类了,就是上面说的。
总结
本文是对上一章节这里内容的细节解读,特别是数据与优化器(我有说明)都是来源trainer类的函数方法实现,我们后期继承是可以改写的。


















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











