







 超级会员免费看
超级会员免费看
文章目录
前言
大模型基本使用huggingface来实现。对于不太理解其内容基本按照官网教程或相关博客等来实现。想进一步激发开源大模型在行业领域提升性能是棘手问题。该问题会涉及开源代码二次开发进行实验测试。基于此,本教程不同文字或理论介绍内容,而从源码解读其训练逻辑、权重保存、高效微调方法(LoRA)、断点续训方法、模型推理权重处理等方法。本教程所有内容完全依托huggingface源码与相关Demo验证来解读,助力大模型使用。
提示:huggingface训练知识!
一、Trainer和TrainingArguments训练与预测完整Demo
构建一个完整可训练和预测的模型,我将使用huggingface的Trainer方式来完成,并构建一些简单文本,以便于给出一个即插即用的模型Demo。这里,我将利用bert-base-uncased模型来完成一个完整的Demo。
1、数据构建
数据简单文本,我不在解释,直接给出继承torch.utils.data.Dataset方法实现自定义custom方式,其代码如下:
class SentimentDataset(torch.utils.data.Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)
# 创建数据集
train_dataset = SentimentDataset(train_encodings, train_labels)
val_dataset = SentimentDataset(val_encodings, val_labels)
而__getitem__功能实现最终结构如下图:
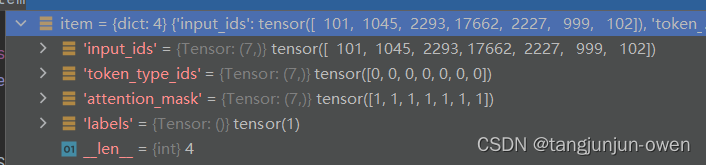
注:这里的train_dataset 与val_dataset 类似torch的dataset方法,而这个也是需要传给trainer模型的输入!
2、TrainingArguments构建
这些内容如同我上面介绍一样,需要什么直接添加即可。
# 定义训练参数
training_args = TrainingArguments(
output_dir='./out_dirs',
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
num_train_epochs=3,
logging_dir="./logs",
evaluation_strategy="epoch",
report_to="none"
)
我说明下,这个方法会加载默认参数,但这里有参数就会替换默认参数内容。
3、Trainer实例化
这里主角来了,我们需要初始化trainer类,一定记住这里train_dataset与val_dataset传入类似torch的dataset方法。
# 定义Trainer对象
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=lambda pred: {"accuracy": accuracy_score(pred.label_ids, pred.predictions.argmax(axis=1))}
)
4、模型训练
上面对了基本就可以训练了,直接给出代码,如下:
# 开始训练
trainer.train()
# 评估模型
eval_results = trainer.evaluate()
# print(f"Accuracy: {eval_results['eval_accuracy']:.4f}")
# 保存模型
model.save_pretrained("./sentiment_model")
5、模型推理
完成训练,直接使用保存的文件实现推理,如下代码:
# 加载模型
model = BertForSequenceClassification.from_pretrained("./sentiment_model")
# 预测一些示例文本
example_texts = ["I love this!", "I hate it."]
inputs = tokenizer(example_texts, padding=True, truncation=True, return_tensors="pt")
outputs = model(**inputs)
predicted_labels = torch.argmax(outputs.logits, dim=1).tolist()
# 打印预测结果
for text, label in zip(example_texts, predicted_labels):
print(f"Text: {text} -- Predicted Label: {'positive' if label == 1 else 'negative'}")
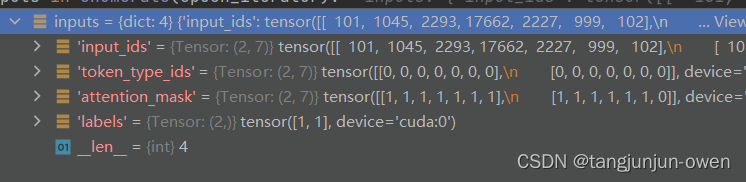
推理的inputs输入如下图:

6、Demo code
可直接复制使用代码,其完整代码如下:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
from torch.utils.data import Dataset, DataLoader
import torch
from transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArguments
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import random
# 随机种子
seed = 42
random.seed(seed)
torch.manual_seed(seed)
# 示例数据
texts = ["I love Hugging Face!", "I hate this.", "This is fantastic!", "I dislike it."]
labels = [1, 0, 1, 0] # 1代表正面,0代表负面
# 划分训练集和验证集
train_texts, val_texts, train_labels, val_labels = train_test_split(texts, labels, test_size=0.2, random_state=seed)
# 加载预训练的Bert tokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
# 数据编码
train_encodings = tokenizer(train_texts, truncation=True, padding=True)
val_encodings = tokenizer(val_texts, truncation=True, padding=True)
class SentimentDataset(torch.utils.data.Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)
# 创建数据集
train_dataset = SentimentDataset(train_encodings, train_labels)
val_dataset = SentimentDataset(val_encodings, val_labels)
# 加载预训练的Bert模型
model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
# 定义训练参数
training_args = TrainingArguments(
output_dir='./out_dirs',
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
num_train_epochs=3,
logging_dir="./logs",
evaluation_strategy="epoch",
report_to="none"
)
# 定义Trainer对象
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=lambda pred: {"accuracy": accuracy_score(pred.label_ids, pred.predictions.argmax(axis=1))}
)
# 开始训练
trainer.train()
# 评估模型
eval_results = trainer.evaluate()
print(f"Accuracy: {eval_results['eval_accuracy']:.4f}")
# 保存模型
model.save_pretrained("./sentiment_model")
# 加载模型
model = BertForSequenceClassification.from_pretrained("./sentiment_model")
# 预测一些示例文本
example_texts = ["I love this!", "I hate it."]
inputs = tokenizer(example_texts, padding=True, truncation=True, return_tensors="pt")
outputs = model(**inputs)
predicted_labels = torch.argmax(outputs.logits, dim=1).tolist()
# 打印预测结果
for text, label in zip(example_texts, predicted_labels):
print(f"Text: {text} -- Predicted Label: {'positive' if label == 1 else 'negative'}")
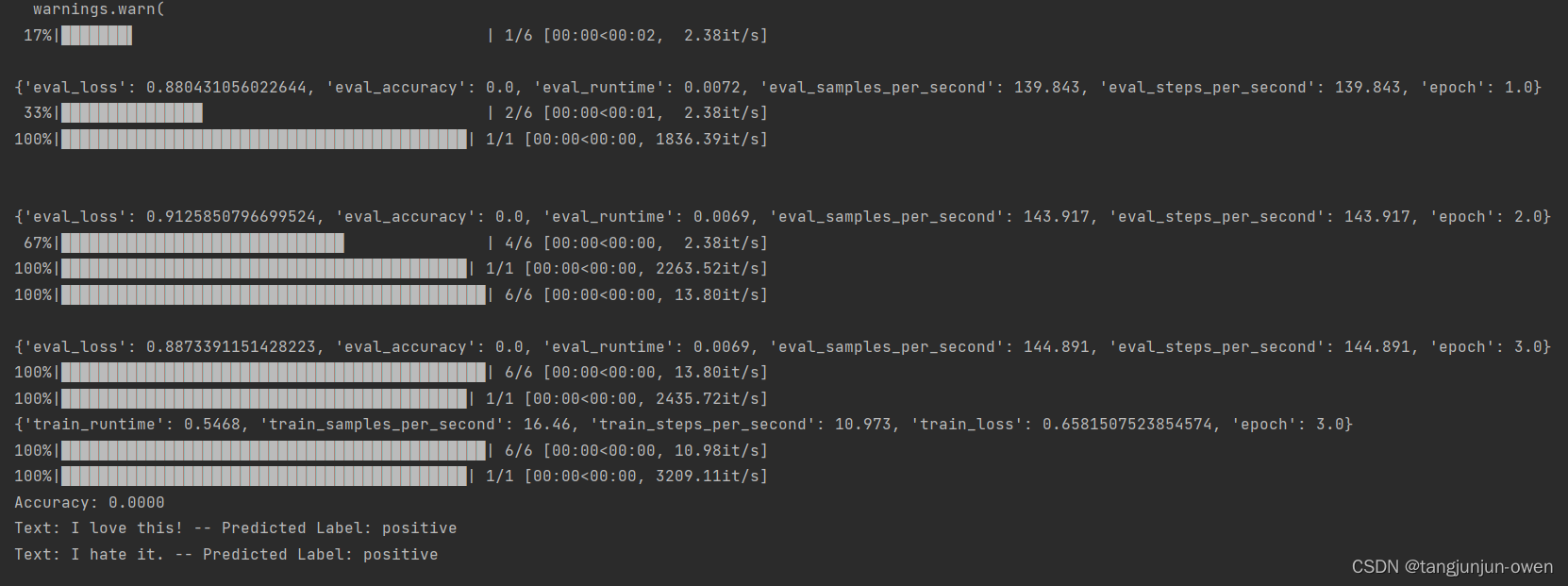
7、Demo运行结果
二、迭代器相关内容
我将在下一章给出Trainer的train函数方法,该节给出一些有利于理解的相关内容。当然,你很理解可以忽略,直接进入下一章中学习。
1、yield返回内容
之所以写这个是后续的dataloader的采样迭代是使用yield方式给出(如:yield from torch.randperm(n, generator=generator).tolist())。为此,我大概介绍一下,yield能返回什么内容。
yield x:返回变量 x 的值。
yield 10:返回整数 10。
yield func():返回函数 func() 的执行结果。
yield from iterable:从可迭代对象中逐个返回元素。
yield后面跟随什么就从后面返回!
2、迭代器中断恢复Demo
这里在介绍一下迭代器意外中断是如何再次开始使用的Demo。其代码如下:
import itertools
# 定义一个列表
numbers_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]
# 创建一个迭代器
numbers_iterator = iter(numbers_list)
# 记住第6次迭代的位置
for a in itertools.islice(numbers_iterator, 6):
print(a)
# 需要重新开始迭代时
print("Restarting iteration:")
for num in itertools.chain([next(numbers_iterator)], numbers_iterator):
print(num)
3、yield from结构
yield from 是 Python 3.3 引入的语法,用于在生成器函数中委托子生成器的执行。它允许一个生成器函数可以调用另一个生成器函数,并将其生成的值逐个 yield 出来。
当一个生成器函数使用 yield from sub_generator() 时,它会暂停自己的执行,调用 sub_generator 生成器函数,并将其生成的值逐个 yield 给外部调用者。一旦 sub_generator 生成器函数执行完毕,控制权会返回到主生成器函数,继续执行余下的代码。
简而言之,yield from 提供了一种简洁的方式来在生成器函数中委托另一个生成器函数的执行,并将其产生的值逐个传递出来。这样可以方便地组合多个生成器,使代码更加清晰和模块化。
4、generator.get_state()函数
generator.get_state() 方法返回的生成器状态信息包含了生成器的当前状态,其中包括以下内容:
种子(seed):用于确定随机数生成的起始点,通过设置种子可以确保生成的随机数序列是可复现的。
锁(mutex):用于保护生成器状态的互斥锁。
伪随机数引擎状态:生成随机数的内部状态,包括当前位置、种子等信息。
这些状态信息一起构成了生成器对象的完整状态,通过保存和恢复这些状态信息,可以实现在重新加载代码后从中断处恢复迭代的功能,同时保持随机数生成的一致性。
其demo如下:
import torch
# 创建一个生成器对象
generator = torch.Generator()
# 设置生成器的种子
generator.manual_seed(42)
# 获取生成器的状态信息
generator_state = generator.get_state()
print(generator_state)
5、迭代器状态与索引恢复Demo
如果你重新加载代码后需要从中断处恢复迭代,你可以通过保存生成器的状态来实现。在 Python 中,可以使用 pickle 模块来序列化生成器对象,将其状态保存到文件中,然后在重新加载代码时重新加载生成器对象并恢复状态。
以下是一个演示如何保存和恢复生成器状态的示例代码:
import torch
import pickle
# 定义一个生成器函数
def random_permutation_generator(n, generator_state, index):
generator = torch.Generator()
generator.set_state(generator_state)
random_permutation = torch.randperm(n, generator=generator).tolist()
for i in range(index, len(random_permutation)):
yield random_permutation[i], i
# 设置随机数生成器种子以确保结果可复现
torch.manual_seed(42)
n = 10 # 生成随机排列的范围为 0 到 n-1
# 定义一个生成器
generator = torch.Generator()
generator.manual_seed(42)
# 创建生成器对象
gen = random_permutation_generator(n, generator.get_state(), 0)
# 模拟迭代中断并保存生成器状态和已生成的索引到文件
for i, (element, index) in enumerate(gen):
print(element)
if i == 4:
with open('generator_state.pkl', 'wb') as f:
state_index = (generator.get_state(), index)
pickle.dump(state_index, f)
break
# 重新加载代码后恢复生成器状态和已生成的索引
with open('generator_state.pkl', 'rb') as f:
generator_state, index = pickle.load(f)
gen = random_permutation_generator(n, generator_state, index)
print("重新加载代码,从中断处继续生成随机排列的数字...")
# 从中断处继续生成随机排列的数字
for element, _ in gen:
print(element)
我们通过保存生成器状态和已生成的索引信息,实现了在中断后恢复生成器状态并从中断处继续生成随机排列的数字。
注:这个帮助我们resume数据加载方式理解。
总结
重点理解本章给出Trainer训练的Demo,后期文章基本在本Demo基础上加工解读。


















 981
981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











