









Snapdragon上的OpenCL介绍 (2)
3.3 OpenCL上的Adreno A3x,A4x和A5x差异
每个新系列的Adreno GPU都对OpenCL的功能和性能进行了许多改进。 本节讨论影响OpenCL性能的关键更改。
3.3.1 L2缓存
除了增加大小之外,从Adreno A320和A330 GPU到Adreno A420,A430,A530和A540 GPU,L2缓存体系结构也得到了显着改进,以提高效率和性能。
3.3.2 本地内存
本地内存已从Adreno A3x改进到A4x和A5x系列,包括大小容量,加载/存储吞吐量和合并访问。 表3-2显示了不同系列上合并访问的区别。
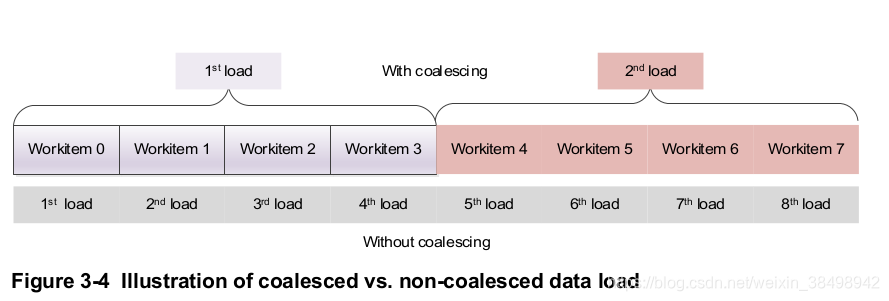
 合并访问是OpenCL和GPU并行计算的重要概念。 基本上,它是指底层硬件可以将多个工作项对数据加载/存储请求进行合并和合并为一个请求,从而提高数据加载/存储效率的情况。 如果没有合并的访问支持,则硬件必须根据每个单独的请求执行加载/存储操作,从而导致性能下降。
合并访问是OpenCL和GPU并行计算的重要概念。 基本上,它是指底层硬件可以将多个工作项对数据加载/存储请求进行合并和合并为一个请求,从而提高数据加载/存储效率的情况。 如果没有合并的访问支持,则硬件必须根据每个单独的请求执行加载/存储操作,从而导致性能下降。
图3-4说明了合并数据负载与非合并数据负载之间的差异。 为了组合来自多个工作项的请求,数据的地址通常需要连续。 在合并的情况下,Adreno GPU可以在一个事务中加载四个工作项的数据,而在没有合并的情况下,相同数量的数据需要进行四个事务。
3.4 图形和计算工作负载之间的上下文切换
3.4.1 上下文切换
在Adreno GPU中,如果在GPU上运行低优先级工作负载时需要执行高优先级任务(例如图形用户界面(UI)渲染),则可能会强制后者暂停,以便GPU切换到高优先级工作负载。 高优先级任务完成后,将继续执行较低优先级的任务。 这种类型的工作负载切换称为上下文切换。 上下文切换通常很昂贵,因为它需要复杂的硬件和软件操作。 但是,这是实现新兴和高级定时关键任务(例如汽车应用程序)的一项重要功能。
3.4.2 限制GPU上的内核/工作组执行时间
有时,计算内核可能运行了过多时间,并触发了导致GPU重置的警报。 为了避免意外的行为,建议不要将带有工作组的计算内核花费很长时间才能完成。 通常,Android设备上的UI呈现持续不断地发生,例如,每30毫秒发生一次,并且长时间运行的计算内核可能会导致UI滞后和无响应,从而损害用户体验。 理想的执行时间取决于大小写。 但是,一般的经验法则是内核执行时间应在数十毫秒的范围内。
3.5 OpenCL标准相关的改进
Adreno A3x GPU支持OpenCL 1.1嵌入式配置文件,而Adreno A4x GPU支持OpenCL 1.2完整配置文件,而Adreno A5x GPU支持OpenCL 2.0完整配置文件。
从OpenCL 1.1嵌入式配置文件到OpenCL 1.2完整配置文件,大部分更改都在软件而不是硬件上进行,例如改进的API功能。
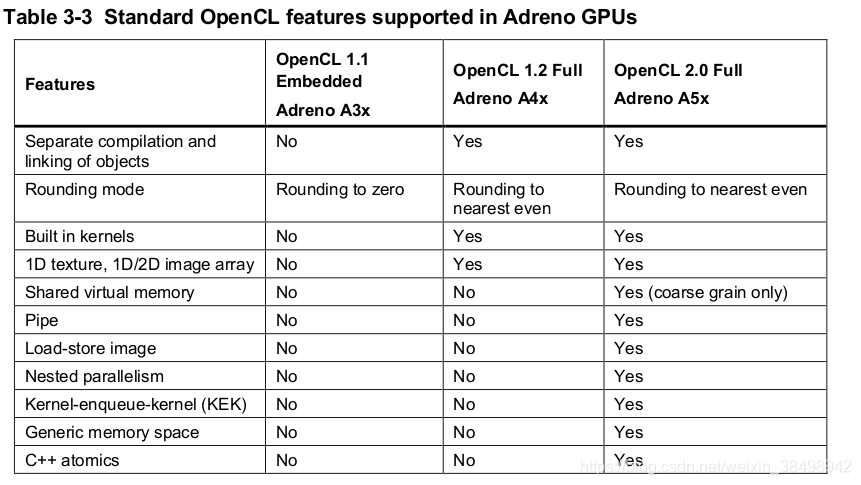
但是,从OpenCL 1.2完整配置文件到OpenCL 2.0完整配置文件,引入了许多新的硬件功能,例如共享虚拟内存(SVM),内核队列内核等。表3-3列出了主要的区别 跨三个Adreno GPU的OpenCL配置文件支持。
3.6 OpenCL扩展
除支持核心OpenCL功能外,Adreno OpenCL平台还通过扩展支持许多其他功能,这些功能可改善OpenCL的可用性并在Adreno GPU中提供高级硬件功能。 可以使用clGetPlatformInfo查询给定Adreno GPU上可用的扩展。 有关这些扩展的文档,请访问QTI开发人员网络网站(https://developer.qualcomm.com)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









