






LiteRT 架构
LiteRT 框架旨在通过优化延迟、模型大小和功耗,在具有低功耗要求的设备(如移动、嵌入式和边缘平台)上运行模型。
该框架在委托的帮助下运行模型。委托是使用库在特定硬件上高效运行神经网络模型的软件层。
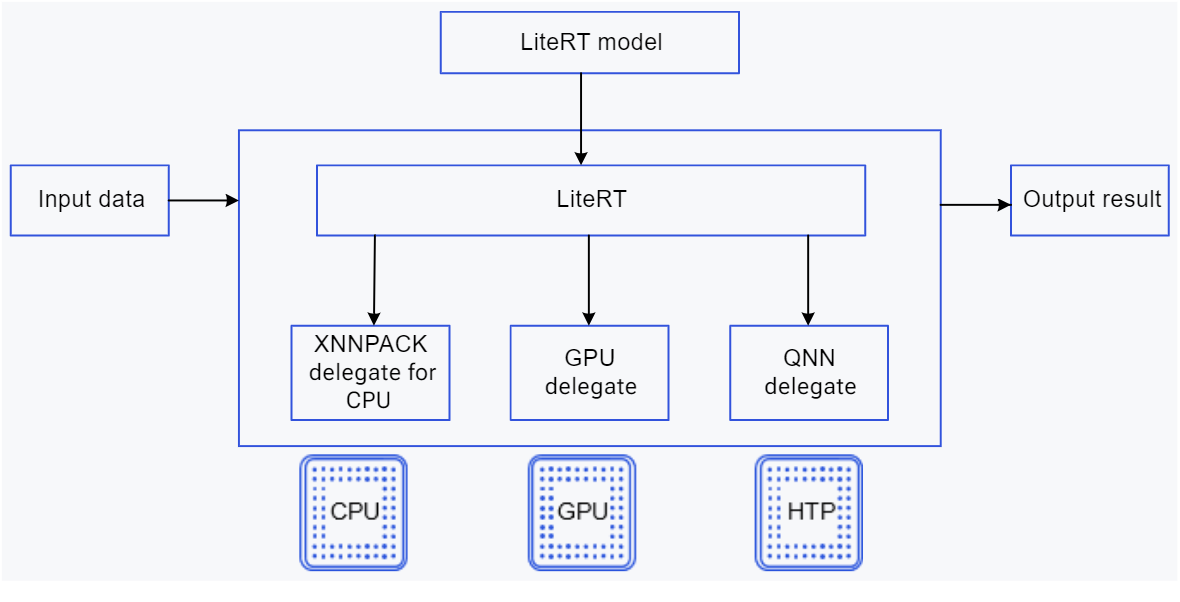
LiteRT 设备上推理
LiteRT 设备上推理将模型加载到解释器中,解释器解析模型并使用委托来运行它。
该过程包括以下内容:
- 推理将 LiteRT 模型加载到 LiteRT 解释器接口中,解释器解析模型以识别其中存在的神经网络运算符。
- 解释器接口进一步配置为使用委托运行模型。
- 解释器对提供的输入调用模型推理,并将相应的输出保存到提供给解释器接口的缓冲区中。
Qualcomm 支持使用委托在以下加速器上执行 LiteRT 模型:
- CPU
- Adreno GPU
- Hexagon Tensor Processor
下表列出了委托及其加速器。

LiteRT 的委托
委托使您可以将 LiteRT 图形执行卸载到硬件加速器,例如 CPU、GPU 和 Hexagon Tensor Processor。
目前,支持以下委托。
CPU 的 XNNPACK 委托
XNNPACK 委托使用 XNNPACK 库在 CPU 上高效加速 LiteRT 模型。
XNNPACK 是 Google 的一个开源库,它执行以下操作:
- 为 Arm CPU 提供神经网络运算符的优化实现
- 使用低级 CPU 指令(例如 Arm® Neon™ 指令集)来优化运算符以实现高效执行
XNNPACK 委托可以运行 32 位浮点和 INT8 格式的模型。有关更多信息,请参阅 TensorFlow Lite 的 XNNPACK 后端。
GPU 委托
GPU 开源委托在各种特定于供应商的 GPU(包括 Adreno GPU)上加速 LiteRT 模型。
LiteRT 可以使用 GPU 委托来提高 GPU 的并行处理能力,从而加快推理速度。GPU 委托使用 OpenCL 内核在 GPU 上的 LiteRT 模型执行图内运行神经网络操作。
GPU 委托默认与 LiteRT 库一起交叉编译,并经过优化以在 Adreno GPU 上运行以下 LiteRT 模型:
- 16 位浮点
- 32 位浮点
有关更多信息,请参阅 LiteRT 的 GPU 委托。
QNN 委托
QNN 委托是专为特定于供应商的硬件加速而设计的专有委托,用于加速 LiteRT 模型。它基于 LiteRT 的外部委托接口。
您可以使用 QNN 委托将部分或整个 LiteRT 模型卸载到专用的 Qualcomm 硬件上,例如 Adreno GPU 和 Hexagon Tensor Processor。
此委托通过减少 CPU 工作负载来提高模型执行性能和能效。它还使用现有的 Qualcomm AI Engine 直接 API 和可用的后端来加速模型。有关更多信息,请参阅 Qualcomm AI Engine 直接 SDK。
QNN 委托可以在可用硬件上以 32 位浮点精度和 INT8 精度执行模型。
您可以使用以下接口构建应用程序:
- Qualcomm AI Engine 直接委托接口
- LiteRT 外部委托接口
使用独立 LiteRT 应用程序时,您可以访问这两个接口。但是,如果您使用 IM SDK 部署 LiteRT 模型,则 Qualcomm TensorFlow Lite 的 qtimltflite GStreamer 插件将使用 QNN 委托。有关更多信息,请参阅利用外部委托。
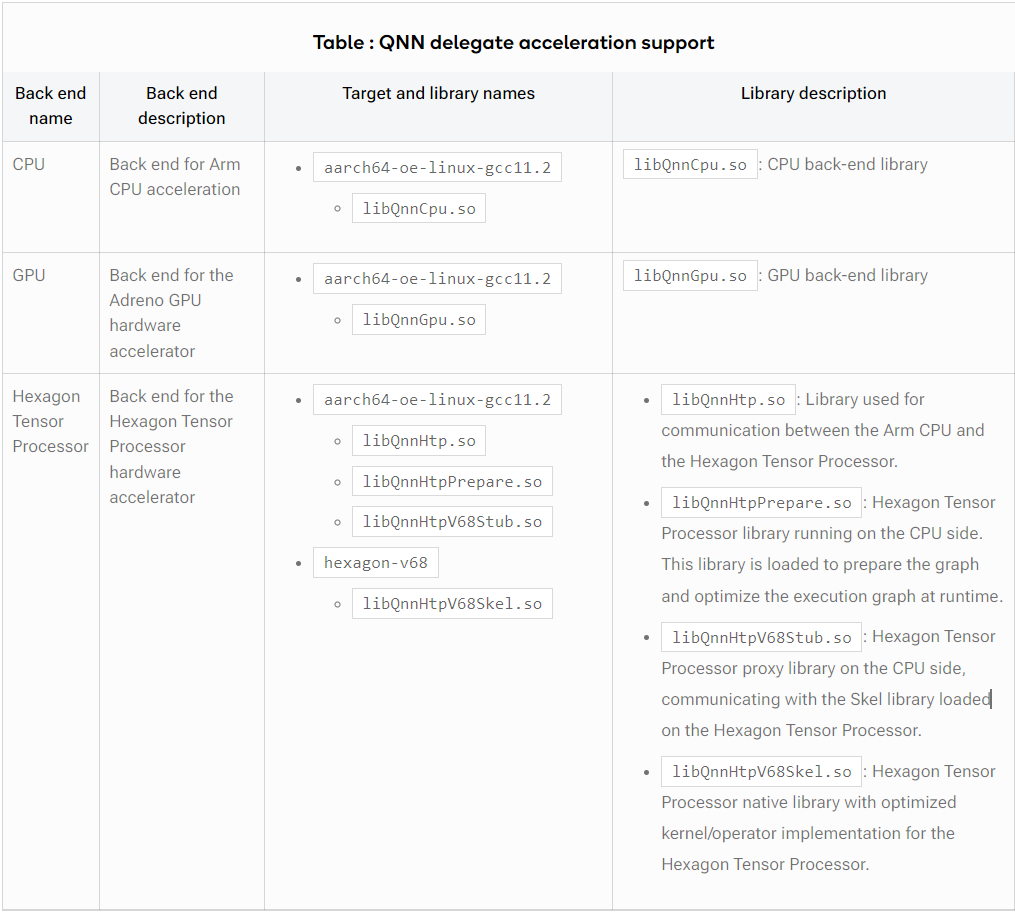
下图显示了来自 Qualcomm AI Engine 直接 SDK 的 QNN 委托库的目录结构:

Qualcomm AI Engine 直接委托接口
Qualcomm AI Engine 直接委托接口(也称为 QNN 委托)提供 QnnTFLiteDelegate.h 标头作为接口。您可以在将应用程序链接到 QNN 委托库之前将此标头包含在应用程序中。
您可以在 aarch64-oe-linux-gcc11.2 交叉编译器工具链三元组目录中找到兼容的 QNN 委托库和 QNN 库。
注意
根据 Qualcomm Linux 开发套件的 Hexagon Tensor Processor 版本选择适当的库。版本如下:
- QCS6490/QCS5430:Hexagon Tensor Processor v68
- QCS9075:Hexagon Tensor Processor v73
- QCS8275:Hexagon Tensor Processor v75
LiteRT 外部委托接口
要使用外部委托接口运行 LiteRT 模型,应用程序必须加载 libQnnTFLiteDelegate.so QNN 委托库。 C/C++ 应用程序和 libQnnTFLiteDelegate.so 委托库彼此之间没有依赖关系。因此,如果委托发生变化,您不必重新编译应用程序。
除了 LiteRT Android C API 之外,还可以将以下内容集成到 C/C++ Android 应用程序中,方式与 LiteRT Android C API 相同:
- external_delegate.h 头文件
- libexternal_delegate.so 共享库
QNN 委托在 Hexagon Tensor 处理器、GPU 和 CPU 上提供加速。要自定义使用 QNN 委托和外部委托接口运行模型的位置和方式,您必须提供其他外部委托选项。有关说明,请参阅 QNN 委托的外部委托选项。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









