






案例研究:使用异构计算的 Avatar AI 个人助理
在 2023 年 Snapdragon 峰会上,我们展示了一个语音驱动的 AI 个人助理,配有实时动态的屏幕头像,运行在 Snapdragon 8 Gen 3 的智能手机上。该应用有许多复杂的工作负载,具有不同的计算需求,同时运行。利用 SoC 中处理器的多样性,并将适当的工作负载运行在最合适的处理器上对于实现良好的用户体验至关重要。

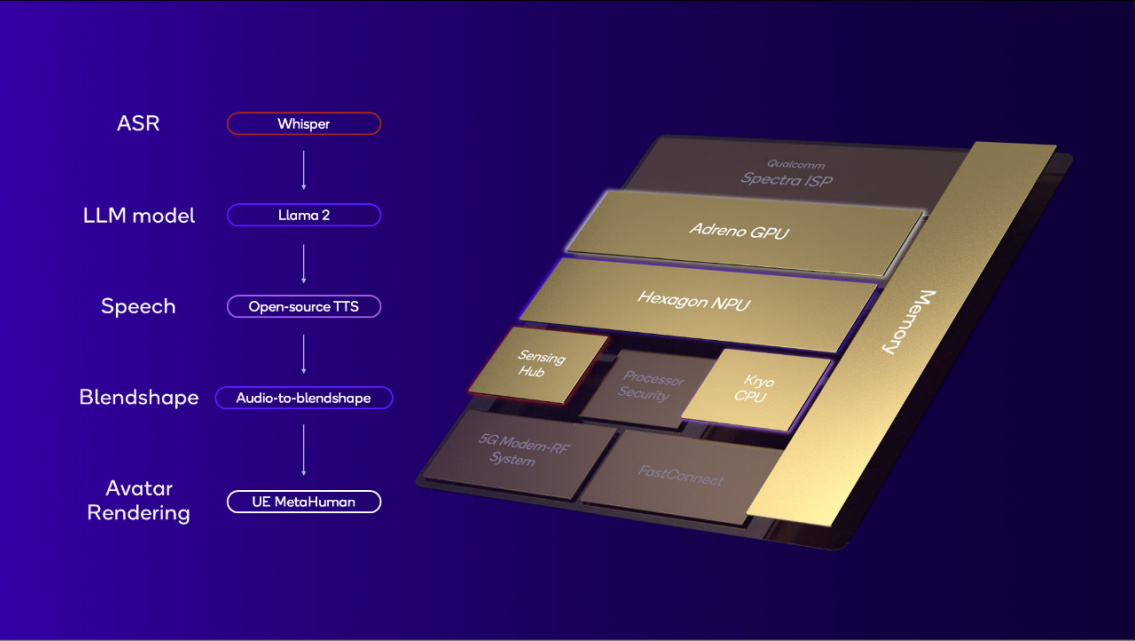
让我们看看工作负载是如何分配的:
- 当用户与助理对话时,语音通过 Whisper 转换为文本,这是 OpenAI 的 ASR 生成式 AI 模型。这在 高通Sensing Hub 上运行。
- 然后,助理使用 Llama 2-7B 作为其 LLM 来生成文本响应。这在 NPU 上运行。
- 然后使用在 CPU 上运行的开源 TTS 模型将文本转换为语音。
- 与此同时,头像必须与语音同步渲染,以提供引人入胜的用户界面。音频用于创建混合形状,使嘴巴和面部表情能够正确动画。这个传统的 AI 工作负载在 NPU 上运行。
- 最终的头像渲染在 GPU 上运行。在所有这些步骤中,数据在内存子系统中高效传输,并尽可能保持在芯片上。
这个个人助理演示利用 高通AI 引擎的所有多样化处理器高效处理生成式和传统 AI 工作负载。
在 Snapdragon 上的领先 AI 性能
要实现领先的性能,需要出色的硬件和软件。虽然每秒万亿次操作(TOPS)可以指示硬件潜力,但只有软件才能使硬件的可访问性和整体利用率得以实现。AI 基准测试提供了更好的性能指示,但最终的衡量标准在于实际应用中对峰值性能、持续性能和每瓦特性能的测量。尽管生成式 AI 基准和应用仍处于起步阶段,以下是对目前可用竞争性 AI 指标的分析,这些指标展示了 Snapdragon 平台的领先性能。
Snapdragon 8 Gen 3 智能手机上的领先 AI 性能
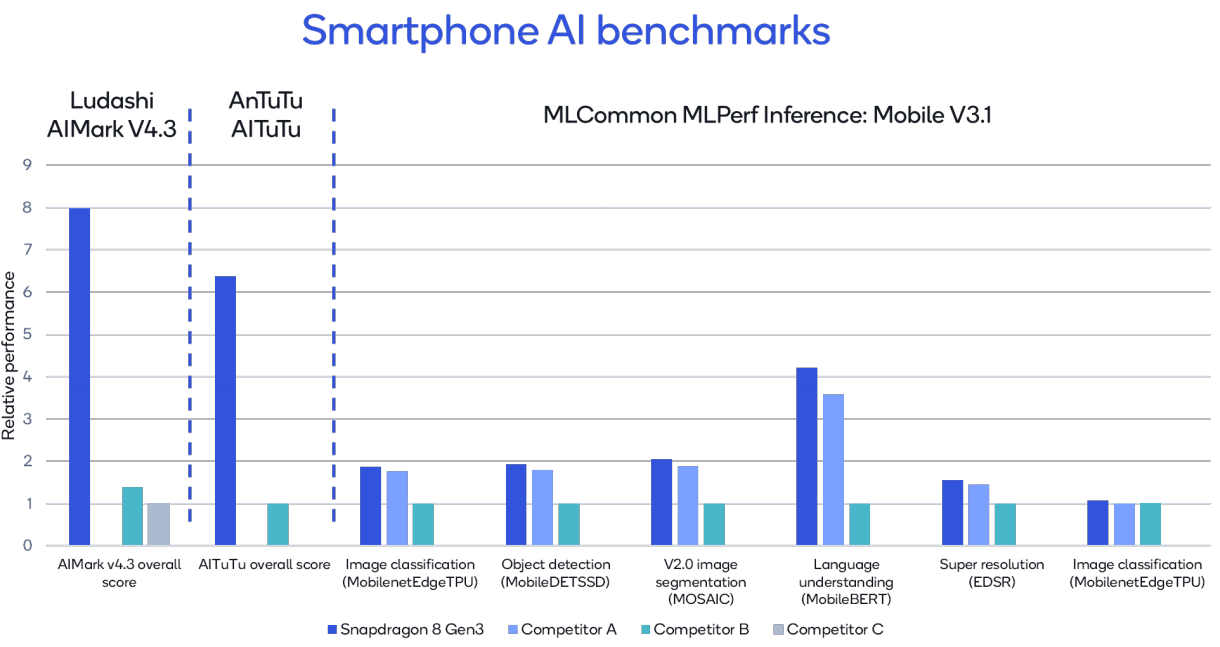
在 MLCommon 的 MLPerf Inference Mobile V3.1 基准中,Snapdragon 8 Gen 3 的性能领先于其他智能手机竞争对手。例如,在 MobileBert(一个生成式 AI 语言理解模型)上,Snapdragon 8 Gen 3 的表现比竞争对手 A 高出 17%,比竞争对手 B 高出 321%。在 Ludashi 的 AIMark V4.3 基准测试中,Snapdragon 8 Gen 3 的总体得分分别是竞争对手 B 和 C 的 5.7 倍和 7.9 倍。在 AnTuTu 的 AITuTu 基准测试中,Snapdragon 8 Gen 3 的总体得分是竞争对手 B 的 6.3 倍。
在 Snapdragon 峰会上,我们展示了两个生成式 AI 应用,能代表 LLM 和 LVM 常见架构的实际性能。在 Snapdragon 8 Gen 3 上,我们的个人助理演示运行 Llama 2-7B,速度高达每秒 20 个令牌。Fast Stable Diffusion 在不到 0.6 秒的时间内生成了 512x512 的图像,且几乎没有失去精度。我们的 Llama 和 Stable Diffusion 指标在智能手机中处于领先地位。
Snapdragon X Elite 上的领先 AI 性能
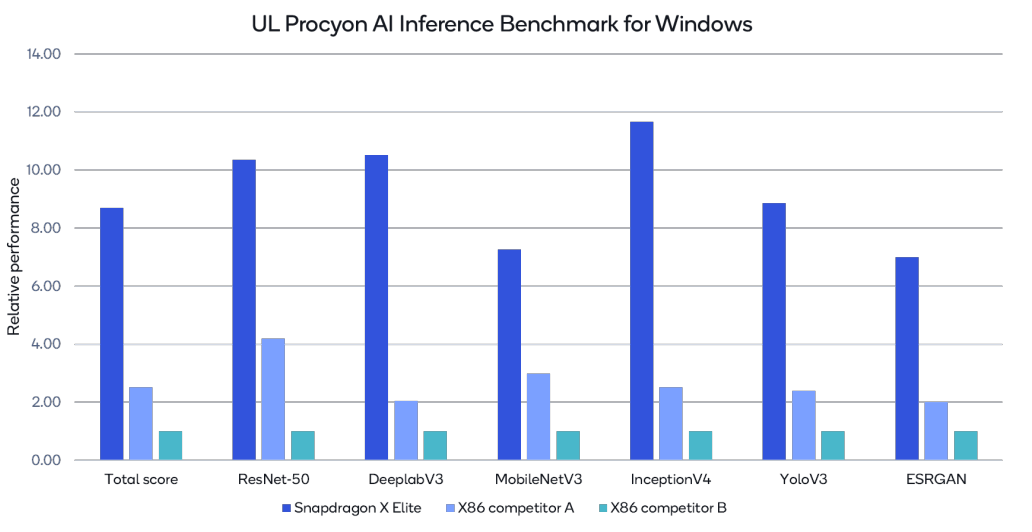
在 Snapdragon X Elite 上,Hexagon NPU 的 45 TOPS 显著高于竞争对手最新 X86 芯片的 NPU TOPS 数量。在 UL 的 Procyon AI 基准测试中,Snapdragon X Elite 的性能领先于其他 PC 竞争对手。例如,Snapdragon X Elite 的基准总体得分分别是 X86 竞争对手 A 和 B 的 3.4 倍和 8.6 倍。
在 Snapdragon X Elite 上,Llama 2-7B 在 高通Oryon CPU 上运行速度高达每秒 30 个令牌。Fast Stable Diffusion 在不到 0.9 秒的时间内生成了 512x512 的图像,且几乎没有失去精度。我们的 Llama 和 Stable Diffusion 指标在笔记本电脑中处于领先地位。
通过我们的软件堆栈访问我们的 AI 处理器
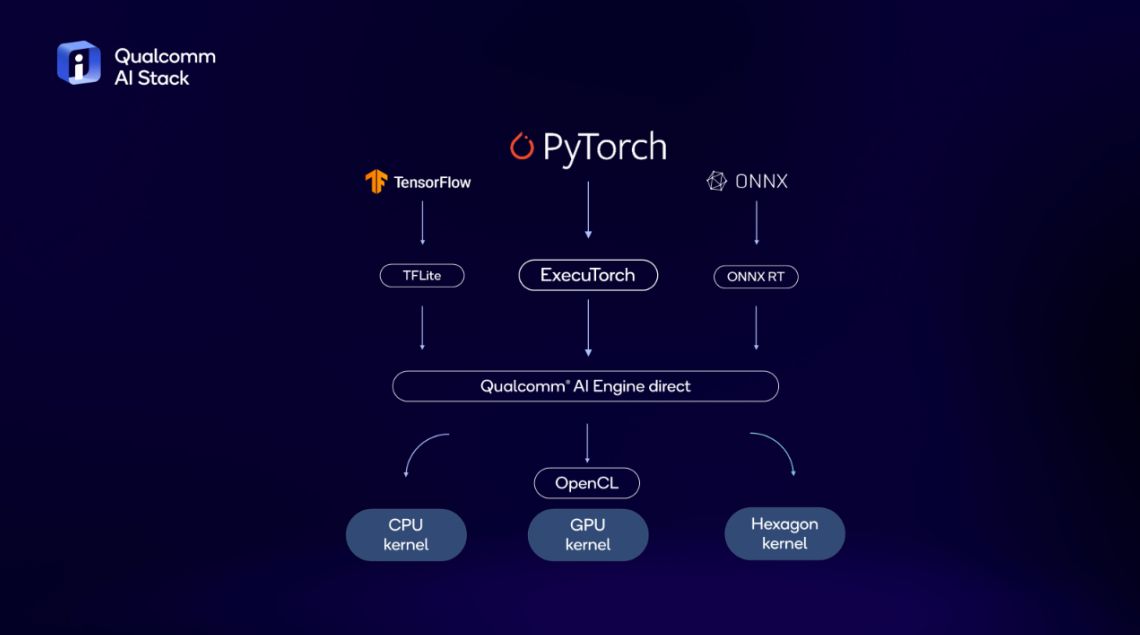
仅拥有出色的 AI 硬件是不够的。使 AI 加速通过异构计算能够被开发者访问,对于设备端 AI 的扩展至关重要。高通AI Stack 将我们的互补 AI 软件产品统一为一个单一包。OEM 和开发者可以在我们的产品上创建、优化和部署他们的 AI 应用,并利用 高通AI 引擎的性能——旨在让开发者只需创建一次 AI 模型,并在不同产品上无处不在地部署。

高通AI Stack 从上到下支持流行的 AI 框架——如 TensorFlow、PyTorch、ONNX 和 Keras——以及运行时——如 TensorFlow Lite、TensorFlow Lite Micro、ExecuTorch 和 ONNX 运行时——以及可直接与 高通AI 引擎 SDK(软件开发工具包)耦合以实现更快开发的这些运行时的代理。
此外,AI Stack 还包括我们的 高通 Neural Processing SDK,用于 Android、Linux 和 Windows 的推理。我们的开发者库和服务支持最新的编程语言、虚拟平台和编译器。
在软件堆栈的低层,我们的系统软件包括基本的实时操作系统(RTOS)、系统接口和驱动程序。覆盖不同产品线,我们还提供丰富的操作系统支持,包括 Android、Windows、Linux 和 QNX,以及部署和监控基础设施如 Prometheus、Kubernetes 和 Docker。
为了实现对 GPU 的直接跨平台访问,支持 OpenCL 和 DirectML。对于 CPU,通常是 AI 编程的起始点,因为它的可编程性强且存在于所有平台,我们的 LLVM 编译器基础设施优化使得加速和高效的 AI 推理成为可能。
我们专注于 AI 模型优化,以提高功率效率和性能。如果一个小而快速的 AI 模型提供低质量或不准确的结果,那么它就没有价值。我们采取全面和原则性的 approach——通过量化、压缩、条件计算、神经架构搜索(NAS)和编译——来缩小 AI 模型并高效运行,同时尽量不牺牲精度,即使是那些已经被行业优化为移动设备的模型。
例如,量化对性能、功率效率、内存带宽和存储都有益。Hexagon NPU 原生支持 INT4,我们的 AI 模型效率工具包(AIMET)提供了开发的量化工具,利用 高通AI 研究创造的技术来限制精度损失,同时减少比特精度。对于生成式 AI,基于变换器的 LLM(如 GPT、Bloom 和 Llama)在量化到 8 位或 4 位权重时通常会大幅受益,因为它们是内存受限的。
通过量化感知训练和/或进一步的量化研究,许多生成式 AI 模型可以量化到 INT4。实际上,INT4 已成为 LLM 的趋势,并逐渐成为常态,特别是在开源社区以及希望在边缘设备上运行大参数模型的需求中。对 INT4 的支持使得在不损害精度或性能的情况下,实现更高的功率节省——在运行更高效的神经网络时,提供高达 90% 的性能提升和 60% 的每瓦特性能提升,相比于 INT8。低位整数精度对于功率高效的推理至关重要。
结论
具有多样化处理器的异构计算对于最大化生成式 AI 应用的性能和功率效率至关重要。Hexagon NPU 专门设计用于持续和高性能 AI 推理,相比竞争对手提供了卓越的性能、功率效率和面积效率。高通AI 引擎由 Hexagon NPU、Adreno GPU、高通Kryo 或 高通Oryon CPU、高通Sensing Hub 和内存子系统组成,提供了一种一流的异构计算解决方案,适用于按需、持续和普遍的使用案例。
通过定制设计整个系统,我们能够进行适当的设计权衡,并利用这些洞察来提供更具协同效应的解决方案。我们的迭代改进和反馈周期使得不仅我们的 NPU,而且基于最新神经网络架构的 AI 堆栈能够不断快速提升。我们在智能手机和 PC 的 AI 基准测试及生成式 AI 应用中的领先性能,正是我们差异化解决方案和全栈 AI 优化的结果。
高通AI Stack 使开发者能够在不同产品之间创建、优化和部署 AI 应用,从而让 高通AI 引擎上的 AI 加速可访问且可扩展。技术领导力、定制硅设计、全栈 AI 优化和生态系统赋能的结合,使 高通技术在推动设备端生成式 AI 的开发和采用方面独树一帜。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









