






Filippo Aleotti Matteo Poggi Stefano Mattoccia
Department of Computer Science and Engineering (DISI)
University of Bologna, Italy
从静态图像学习光流
Motivate:作者引入一种策略,从任意单一图像中生成准确的reference 光流注释。
首先:1)给定一个图像,使用单目深度估计网络来为观测场景建立点云(点的集合);
然后,2)利用运动矢量和旋转角度,重建环境中虚拟移动摄像机,使我们能够合成一个新的视图和相应的光流场。
 大体流程如上图:在第2)步生成新的视图:视图会存在2种问题 collisions(碰撞),holes(空洞),
大体流程如上图:在第2)步生成新的视图:视图会存在2种问题 collisions(碰撞),holes(空洞),
collisions:碰撞,多个来自I0中的像素经扭曲出现在I1的同一个位置,多对一;
holes:空洞,I0经扭曲,得到I1,但是I1中的部分像素无法在I0中得到,因此该部分区域是黑色的

为了加深理解,可以看I0 和(B)I1的区别,右上角大片黑色区域为holes,鸟身上的条纹既有collisions(碰撞),也有holes(空洞)。
所以文章主要内容就是,作者如何产生虚拟移动的相机并生成新的图片I1,以及如何解决新图片里包含的collisions(碰撞),hole(空洞)两个问题。请往下看:
接下来进入文章主题,作者如何提出策略来得到I1:

这部分叫Depthstillation pipeline(深度估计管道):
首先,作者对I0进行深度估计:
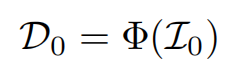
Φ 是单目深度估计网络,(这里作者使用MiDas、Megadepth。MiDas效果更好一些)
得到深度估计Do后,作者采样相机内参得到K-1矩阵把I0的像素P0映射到了3D空间,在此基础上利用D0得到了拍摄I0时,相机的虚拟位置c0的深度信息,再经过随机的三角旋转R1 和平移t1得到c1位置的虚拟相机,然后把P0经过K映射成I1。得到新视角图I1。

Each pixel p0 in I0 ;inverse intrinsics matrix K^−1
transformation matrix T0→1 = (R1|t1) :rotation R1[− π/18 , π/18 ]; translation t1 [-0.2, 02]
在估计深度时,作者引入双边滤波 bilateral filter,来优化深度图粗糙的边缘信息,如下图(A)、(C)。


经过上面的操作,作者就得到了一个Warped 的I1,也得到了一个可预测的光流flow。
但是I1会出现文章开头提到的2个问题:
collisions (i.e., multiple pixels from I0 being warped to the same location in I1) ;
holes (i.e., pixels in I1 over which no pixel from I0 is projected).
那么该怎么解决呢?
对Collisions: To handle collisions, we keep track of pixels p1 having multiple projections p0 in a binary collision mask M (i.e., collisions are labeled as 1, other pixels as 0) and select, for each, the one having minimum depth according to camera in position c1(i.e. the closest, to be displayed in I1.)
利用二值掩码M,将具有多个p0像素映射的像素p1标记为1(也就是碰撞发生的区域),其他像素标记为0,由于多个像素映射到同一点。那么我们在那么多像素中,选择一个深度最浅的像素值对p1点进行填充(为什么选择深度浅的呢,因为作者假设,更近的点遮盖了其他的点),因此也就解决了Collisions问题,此时得到了矩阵M,以便处理holes问题。M矩阵如下:

对Holes:
利用二值掩码H,将在I1中出现,但没有在I0中出现的像素标记为0(黑色区域),其余的标记为1。H矩阵如下(F)。利用 inpainted [5]操作(好像opencv集成了该函数,直接调用),得到了(G)。

 然而,值得注意的是,(G)中的一些区域,比如图像右边的鸟的翅膀,会受到不同种类的文物的影响。例如,由于摄像机的运动,I1中鸟的一些像素没有填充了I0中鸟本身的RGB值,而是填充了背景值。所以作者相对这部分值进行跟踪,再次inpainted操作。
然而,值得注意的是,(G)中的一些区域,比如图像右边的鸟的翅膀,会受到不同种类的文物的影响。例如,由于摄像机的运动,I1中鸟的一些像素没有填充了I0中鸟本身的RGB值,而是填充了背景值。所以作者相对这部分值进行跟踪,再次inpainted操作。

作者发现(G)中填充出错的部分在(E)中显示为0区域,所以作者想把这部分给追踪到,那么作者对(E)进行图像形态学中的膨胀操作,也就是希望亮的地方越亮! (利用一个核函数,把0变成1)如下图(H)

因此,作者只需要检测(E)和(H)中那些值从0变为1,即可。得到集合(I),那么作者综上,就得到了final mask (J),对(J) 进行inpatined操作。就得到了最终的(K)

为了使数据更加真实,作者加入了虚拟移动。利用训练的实例分割网络Ω,将图像里N个目标分割出来,然后利用cπ进行移动,并投影到I1。

效果如下 ,c)是发生虚拟运动的产物。


 接下来是实验部分,实验部分较多,不一一讲解。
接下来是实验部分,实验部分较多,不一一讲解。



dCOCO是作者利用所提策略自己生成的。可以看到
经过dCOCO训练,效果是好很多。
















 583
583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









