






Qwen-VL是一种基于Qwen-7B的大规模视觉语言模型,旨在处理和理解文本与图像信息。其架构由三个核心组件构成:大型语言模型(LLM)、视觉编码器和位置感知的视觉语言适配器。
-
大型语言模型(LLM):
- Qwen-VL采用Qwen-7B作为其基础语言模型,该模型具备强大的语言生成和理解能力。Qwen-7B的预训练权重被用于初始化Qwen-VL的语言模型部分。
-
视觉编码器(Vision Encoder):
- 视觉编码器采用Vision Transformer(ViT)架构,初始化参数源自OpenCLIP的ViT-bigG模型。在训练和推理过程中,输入图像会被调整至特定分辨率,并通过14步长块处理,生成一组图像特征。
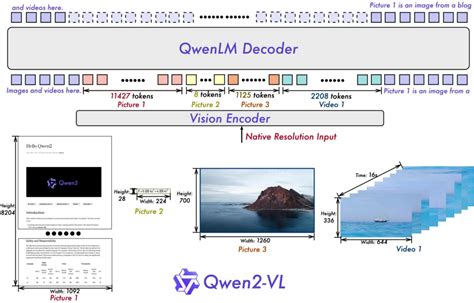
探索阿里通义千问的 Qwen2-VL:新一代视觉语言模型本地 …
- 视觉编码器采用Vision Transformer(ViT)架构,初始化参数源自OpenCLIP的ViT-bigG模型。在训练和推理过程中,输入图像会被调整至特定分辨率,并通过14步长块处理,生成一组图像特征。
-
位置感知的视觉语言适配器(Position-aware Vision-Language Adapter):
- 该适配器是一个随机初始化的单层交叉注意力模块,用于压缩图像特征序列,减少长序列处理中的效率问题。它通过一组可学习的query向量与图像特征进行交叉注意力操作,将视觉特征压缩到固定长度的序列中。
Qwen-VL的训练流程分为三个阶段:
-
预训练阶段:
- 使用大规模图像-文本对数据集进行预训练,冻结LLM参数,优化Vision Encoder和VL Adapter,目标是对齐视觉和语言特征。
-
多任务预训练阶段:
- 使用高质量细粒度VL标注数据,同时训练多个任务,提升模型的多模态能力,输入分辨率提升至448x448,不冻结任何模块。
-
监督微调阶段:
- 冻结Vision Encoder,优化LLM和VL Adapter参数,使用对话交互数据进行提示调优,得到交互式Qwen-VL-Chat模型。
Qwen-VL在多个视觉基准测试中表现出色,尤其在细粒度的文字识别和检测框标注方面具有显著优势。此外,它支持多语言处理、多图像输入以及复杂的视觉任务如视觉问答、图像描述和视觉定位等。
Qwen-VL通过整合复杂组件和多任务训练,实现了从文本到图像的高效理解和处理能力,成为实际应用中极具潜力的解决方案。
分享研究追问
答案
Qwen VL是阿里云开发的一种大型视觉语言模型(Large Vision Language Model, LVLM),其架构设计旨在处理和理解多模态数据,包括文本和图像。以下是对Qwen VL架构的详细解析。
整体架构
Qwen VL的架构主要由三个核心组件构成:
- 大型语言模型(LLM):
- 视觉编码器(Visual Encoder):
- 位置感知适配器(Position-aware Vision-Language Adapter):
工作原理
Qwen VL通过以下步骤实现多模态数据的处理和融合:
- 数据预处理:
- 特征融合:
- 任务执行:
性能与应用
Qwen VL在多个标准测评中表现优异,如Zero-shot Captioning、VQA、DocVQA和Grounding等任务,均取得了最佳效果。此外,该模型支持多语言对话,包括中文和英文,能够进行长文本识别和多图交互对话,是首个支持中文开放域定位的通用模型
.
特点总结
- 强大的性能:在标准测试中表现优异。
- 多语言支持:天然支持多种语言的对话。
- 细粒度识别:相较于其他模型,Qwen VL支持448分辨率,提升了细节识别能力。
- 灵活性:支持多种输入形式,如图像、文本及检测框,并能生成相应的输出。
通过以上架构设计与工作原理,Qwen VL展现了其在多模态任务中的强大能力,有效处理复杂的文本与图像信息,为未来的应用提供了广阔的前景。
分享
改写
相关事件
| 事件名称 | 事件时间 | 事件概述 |
|---|---|---|
| Qwen-VL的发布与应用 | 2023-09-24至2024-11-01 | 技术发展Qwen-VL是一款集成视觉编码器和位置感知视觉语言适配器的大规模视觉语言模型,支持多任务和多语言处理。 |
| Qwen2-VL的发布与性能提升 | 2024-08-30至2024-09-24 | 技术发展Qwen2-VL是基于Qwen-VL的更新版本,支持动态分辨率处理和多模态旋转位置嵌入,显著增强了图像理解能力。 |
| Qwen-VL在多模态领域的应用探索 | 2023-09-24至2024-11-01 | 技术应用Qwen-VL在图像描述、视觉问答、视觉定位等多模态任务中展现出强大的处理能力,并支持多种语言。 |
| Qwen-VL与Spring AI Alibaba框架结合实现文字识别 | 2024-11-01 | 技术应用利用通义Qwen VL模型结合Spring AI Alibaba框架,实现了高效的文字识别服务,提升了开发效率。 |
相关组织
| 组织名称 | 概述 |
|---|---|
| 阿里云 | 科技/云计算阿里云是阿里巴巴集团的云计算品牌,负责开发和发布Qwen系列模型,包括Qwen-VL。 |
| OpenCLIP | 科技/人工智能OpenCLIP是一个开源项目,提供用于视觉编码器的ViT-bigG模型预训练权重。 |
来源
1. PDF
2.
[2024-12-02]3.
QwenLM 多模态版本. Alibaba Qwen team.
[2024-11]4.
[2024-09-09]5.
Qwen-VL模型架构与训练流程详解. ModelScope魔搭社区.
[2024-04-25]6.
大模型系列:问答理解定位(Qwen-VL/Llama2/GPT)
[2024-07-11]7.
[2024-11-15]8.
[2024-07-24]9.
Qwen-VL:多功能视觉语言模型,能理解、能定位、能阅读等. 阿里.
[2023-09-24]10.
多模态大模型 Qwen-VL 和 CogVLM 的架构与训练方法
[2024-04-17]11.
[2024-07-19]12.
[2024-09-19]13.
多模态大模型: 盘点&Highlights part2. 延捷.
[2024-09-08]14.
Qwen2-VL全面解读!阿里开源多模态视觉语言模型,多项超越GPT4o与Claude 3.5-Sonnet. 阿里巴巴.
[2024-09-24]15.
[2024-09-19]16.
阿里巴巴开源Qwen2-VL:能理解超20分钟视频,媲美GPT-4o!. 阿里巴巴.
[2024-08-30]17.
MLM之Qwen:Qwen2-VL的简介、安装和使用方法、案例应用之详细攻略. 阿里云.
[2024-08-30]18.
[2024-06-19]19.
[2024-12-04]20.
[2024-09-04]21.
Qwen-VL: A versatile vision-language model for understanding, localization, text reading and beyond
[2024-07-11]22.
[2024-07-05]23.
Qwen-VL技术报告笔记. 韩松岭 AI-Study-Han.
[2024-09-27]24.
[2024-10-09]25.
[2024-01-29]26.
[2024-11-23]27. PDF
Salt Documentation. VMware et al.
28.
Java - 文字识别 ;示例代码基于SpringAI和国产大模型
[2024-11-01]29. PDF
XPU-80 AZ-80 处理器. Ithaca Intersystems et al.
[1981-12-31]30.
[2024-09-23]

















 3143
3143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









