






首发!Megrez-3B-Omni全模态,图像理解、OCR、文本、语音
CourseAI CourseAI 2024年12月18日 21:29 湖北
模型简介
-
Megrez-3B-Omni是由无问芯穹(Infinigence AI)研发的端侧全模态理解模型,基于Megrez-3B-Instruct扩展,同时具备图片、文本、音频三种模态数据的理解分析能力
-
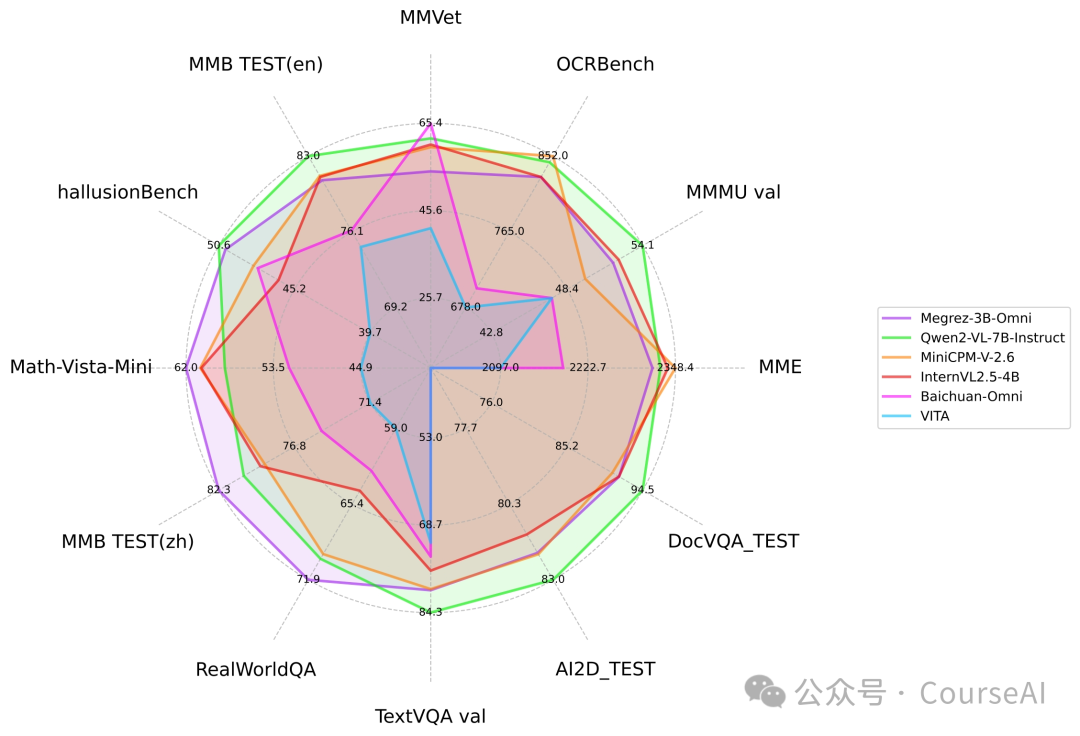
在图像理解方面,基于SigLip-400M构建图像Token,在OpenCompass榜单上(综合8个主流多模态评测基准)平均得分66.2,超越LLaVA-NeXT-Yi-34B等更大参数规模的模型。
-
图像识别方便,Megrez-3B-Omni也是在MME、MMMU、OCRBench等测试集上目前精度最高的图像理解模型之一,在场景理解、OCR等方面具有良好表现。
-
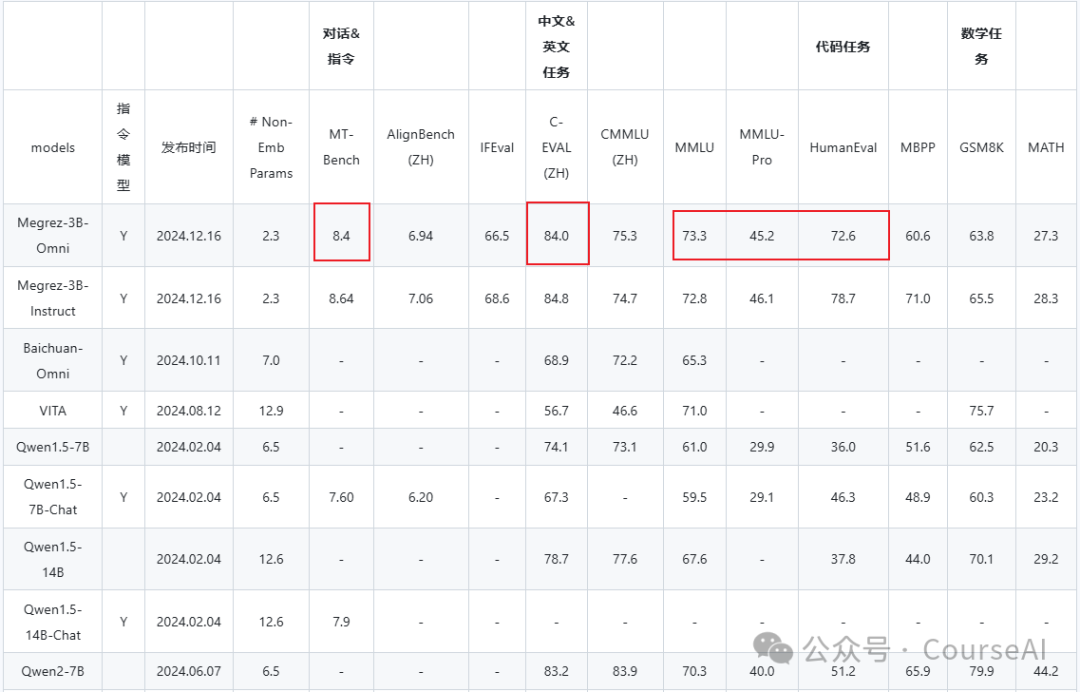
在语言理解方面,Megrez-3B-Omni并未牺牲模型的文本处理能力,综合能力较单模态版本(Megrez-3B-Instruct)精度变化小于2%,保持在C-EVAL、MMLU/MMLU Pro、AlignBench等多个测试集上的最优精度优势,依然取得超越上一代14B模型的能力表现
-
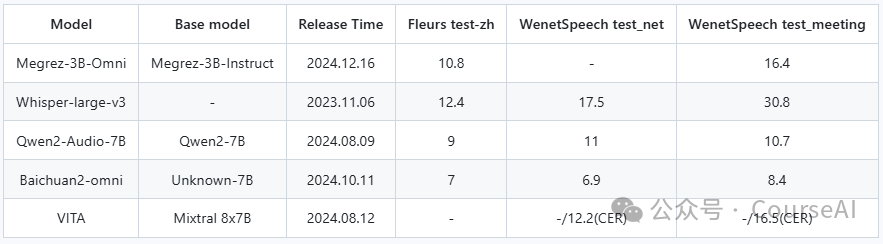
在语音理解方面,采用Qwen2-Audio/whisper-large-v3的Encoder作为语音输入,支持中英文语音输入及多轮对话,支持对输入图片的语音提问,根据语音指令直接响应文本,在多项基准任务上取得了领先的结果
Megrez-3B-Omni实战
Megrez-3B-Omni实战地址:https://huggingface.co/spaces/Infinigence/Megrez-3B-Omni
import torch
from transformers import AutoModelForCausalLM
path = "{{PATH_TO_PRETRAINED_MODEL}}"# Change this to the path of the model.
model = (
AutoModelForCausalLM.from_pretrained(
path,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
.eval()
.cuda()
)
# Chat with text and image
messages = [
{
"role": "user",
"content": {
"text": "Please describe the content of the image.",
"image": "./data/sample_image.jpg",
},
},
]
# Chat with audio and image
messages = [
{
"role": "user",
"content": {
"image": "./data/sample_image.jpg",
"audio": "./data/sample_audio.m4a",
},
},
]
MAX_NEW_TOKENS = 100
response = model.chat(
messages,
sampling=False,
max_new_tokens=MAX_NEW_TOKENS,
temperature=0,
)
print(response)
-
请将图片尽量在首轮输入以保证推理效果,语音和文本无此限制,可以自由切换
-
语音识别(ASR)场景下,只需要将content['text']修改为“将语音转化为文字。”
-
OCR场景下开启采样可能会引入语言模型幻觉导致的文字变化,可考虑关闭采样进行推理(sampling=False),但关闭采样可能引入模型复读
Megrez-3B-Omni的能力
-
Megrez-3B-Omni与其他开源模型在主流图片多模态任务上的性能比较
| Language Module | Vision Module | Audio Module | |
|---|---|---|---|
| Architecture | Llama-2 with GQA | SigLip-SO400M | Whisper-large-v3 (encoder-only) |
| # Params (Backbone) | 2.29B | 0.42B | 0.64B |
| Connector | - | Cross Attention | Linear |
| # Params (Others) | Emb: 0.31B | Connector: 0.036B | Connector: 0.003B |
| # Params (Total) | 4B | ||
| # Vocab Size | 122880 | 64 tokens/slice | - |
| Context length | 4K tokens | ||
| Supported languages | Chinese & English | ||
-
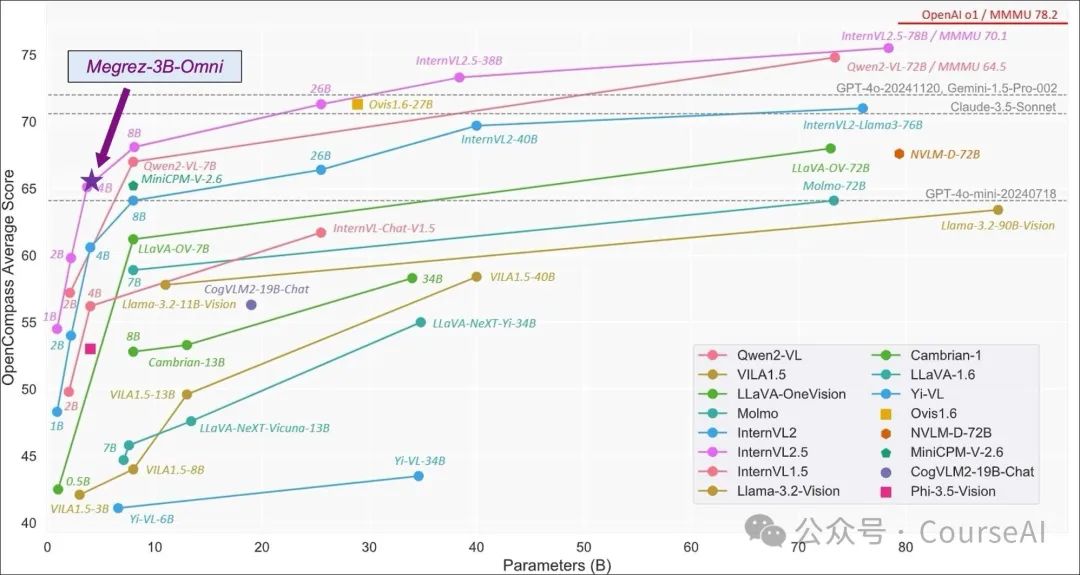
Megrez-3B-Omni在OpenCompass测试集上表现,图片引用自:InternVL 2.5 Blog Post
文本处理能力
语音理解能力
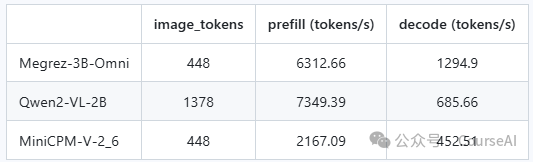
速度
https://github.com/infinigence/Infini-Megrez-Omni https://www.modelscope.cn/models/InfiniAI/Megrez-3B-Omni https://www.modelscope.cn/models/InfiniAI/Megrez-3b-Instruct
推荐阅读

















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









