







摘要
Model-based强化学习(MBRL)比Model-free强化学习(MFRL)更加sample efficient。目前对于MBRL的研究没有标准,作者们可能会使用自己设计的环境、一些闭源且不能复现的结果。本文收集了大批MBRL算法,并在18个为MBRL特别设计的基准环境上按照统一的设置运行。本文还描述了三个未来MBRL研究的关键挑战:动力瓶颈、规划周期困境、提前终止困境、
介绍
尽管近期MBRL的研究取得喜人的进展,这些方法是如何相互比较的,以及如何与baseline比较是不明确的。可复现性和开源代码的匮乏都是强化学习中持续存在的问题。在MBRL中,这些问题尤为严重,因为对环境进行了改进:观察的预处理、奖励函数的改进、使用不同的episode视野。
为了量化MBRL的科学进展,本文在18个基于标准OpenAI Gym的环境上检测了11个MBRL算法和4个MFRL算法。为了测试其鲁棒性,检测引入了观察和动作的随机性。
基于经验评估,本文提出了三个MBRL方法性能停滞的主要原因:1)动力瓶颈:收集到更能多数据无法增强性能;2)规划周期困境:增加规划周期虽然提供了更准确的奖励评估,也由于维数灾难和建模误差导致了性能的下降;3)提前终止困境:MBRL无法达到像MFRL那样在提前终止时可以有更具方向性的探索以获取更快的学习。
算法
第一类:Dyna-style算法
在Dyna算法中,训练迭代两步:1)使用当前策略,数据从环境交互中被收集起来,用于学习动力模型;2)使用学习到的模型生成的想象数据来提升策略。这种类型的算法靠使用丰富虚拟经验且不使用与真实环境交互的model-free算法来学习策略。
Model-Ensemble Trust-Region Policy Optimization(ME-TRPO)
ME-TRPO使用一个神经网络的集成来对动力建模,可以有效克服建模误差。模型使用L2损失函数训练。在策略改善步中,策略通过在学习到的动力模型生成的经验上,使用TRPO来更新。
Stochastic Lower Bound Optimization(SLBO)
SLBO是ME-TRPO的变种,有单调改进的理论保证。SLBO使用multistep L2范式损失来训练动力。
Model-Based Meta-Policy-Optimization(MB-MPO)
MB-MPO放弃对准确模型的依赖,元学习一个可以适应不同动力的策略。MB-MPO学习一个神经网络的集成,不过集成中的每个模型被当成一个不同的任务来元学习。
第二类:Policy Search with Backpropagation through Time
这类算法利用模型的导数,能够计算强化学习目标关于策略的解析梯度,并改进相对应的策略。
Probabilistic Inference for Learning Control(PILCO)
高斯过程(GP)被用来对环境的动力进行建模。动力模型是一个概率的、无参数的函数。通过计算目标关于策略参数的解析梯度,训练策略以最大化强化学习目标。训练过程在使用当前策略收集数据和增强策略之间迭代。
Iterative Linear Quadratic-Gaussian(iLQG)
算法在强化学习奖励函数上使用一个二次逼近,在动力上使用一个线性逼近,将问题转化成一个可以由线性二次调节器(LQR)解决的。iLQG是一个模型预测控制(MPC)算法,每一个time-step都会进行一次重规划。
Guided Policy Search(GPS)
Stochastic Value Gradients(SVG)
SVG通过使用真实环境的观察来解决组合模型误差的问题。为了适应模型预测与实际转移之间的不匹配,SVG中的动力模型是基于概率的。通过计算真实轨迹关于策略的解析梯度来改进策略。
第三类:Shooting Algorithm
这种类型的算法提供一种方法来大致解决模型预测控制中面对非线性动力和非凸奖励函数时的滚动优化问题。随着对动力建模的神经网络的使用,这种算法更受欢迎。
Random Shooting(RS)
Model-Free Model-based(MB-MF)
Probabilistic Ensembles with Trajectory Sampling(PETS-RS和PETS-CEM)
在PETS中,动力由一个概率神经网络模型的集成建模。PETS-RS和RS除了建模方式外其他一样。而在PETS-CEM中,线上优化问题由交叉熵方法来解决。
第四类:Model-free Baselines
包括Trust-Region Policy Optimization(TRPO)、Proximal-Policy Optimization(PPO)、Twin Delayed Deep Deterministic Policy Gradient(TD3)和Soft Actor-Critic(SAC)。前两个是前沿在线MFRL算法,后两个是前沿离线MFRL算法。
实验
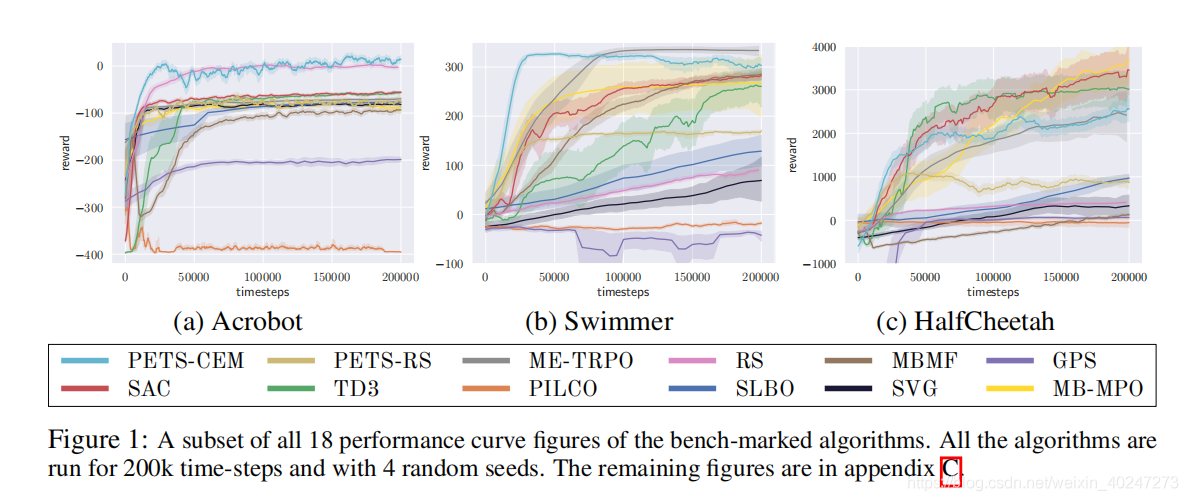
Figure 1是具有代表性的性能曲线,纵坐标是奖励。


噪声环境
对观察和动作添加高斯白噪声,对MBRL算法的性能普遍造成不好的影响。其中,ME-TRPO和SLBO更容易出现灾难性的性能下降。而shooting方法如PETS和RS,重规划成功地补偿了不确定性。另一方面,Dyna-style方法 MB-MPO对噪声表现出了非常强的鲁棒性。
动力瓶颈
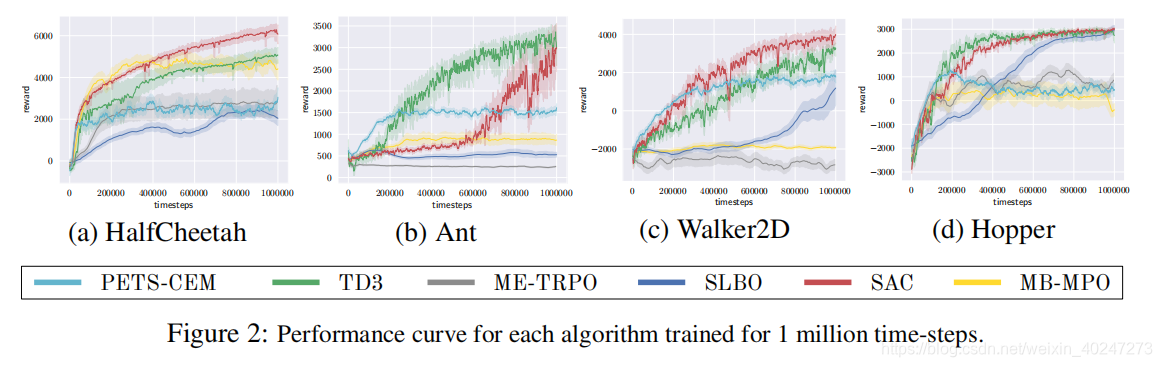
学习模型时,更多的数据不能得到更好的表现。可能有几点原因:1)预测误差随时间累积;2)策略和学习的动力是耦合的,使agent更倾向于局部最小值。
规划周期困境
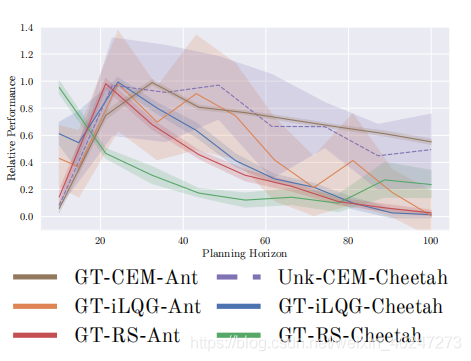
增加规划周期并不能增强表现。20-40的规划周期表现最好。
提早终止困境
提早终止并不能为MBRL算法带来更好的表现。
Reference
- Wang T , Bao X , Clavera I , et al. Benchmarking Model-Based Reinforcement Learning[J]. 2019.

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









