







简 介
Ranger 软件是一个快速实现高维数据的随机森林。支持集成分类、回归和生存树。用参考实现验证包,并将运行时和内存使用情况与其他实现进行比较。新软件被证明是最好的缩放与特征,样本,树的数量,并尝试分裂的特征。最后,表明 Ranger 是最快和最有效的实现随机森林在全基因组关联研究的规模上分析数据。

软件包安装
if(!require(ranger))
install.packages("ranger")
if(!require(ranger))
devtools::install_github("imbs-hl/ranger")数据读取
数据说明:
futime: survival or censoring time
fustat: censoring status
age: in years
resid.ds: residual disease present (1=no,2=yes)
rx: treatment group
ecog.ps: ECOG performance status (1 is better, see reference)
data(cancer, package="survival")
head(ovarian)## futime fustat age resid.ds rx ecog.ps
## 1 59 1 72.3315 2 1 1
## 2 115 1 74.4932 2 1 1
## 3 156 1 66.4658 2 1 2
## 4 421 0 53.3644 2 2 1
## 5 431 1 50.3397 2 1 1
## 6 448 0 56.4301 1 1 2实例操作
参数说明:
?ranger构建模型
根据说明ovarian数据集,构建模型:
library(ranger)
require(survival)
fit <- ranger(Surv(futime, fustat) ~ ., data = ovarian, importance = "impurity")
fit
## Ranger result
##
## Call:
## ranger(Surv(futime, fustat) ~ ., data = ovarian, importance = "impurity")
##
## Type: Survival
## Number of trees: 500
## Sample size: 26
## Number of independent variables: 4
## Mtry: 2
## Target node size: 3
## Variable importance mode: impurity
## Splitrule: logrank
## Number of unique death times: 12
## OOB prediction error (1-C): 0.2568807重要变量分析
fit$variable.importance## age resid.ds rx ecog.ps
## 6.1362046 1.3665241 0.9877156 1.2586800par(mar=c(4,8,4,4))
barplot(sort(fit$variable.importance),las=2,horiz = T)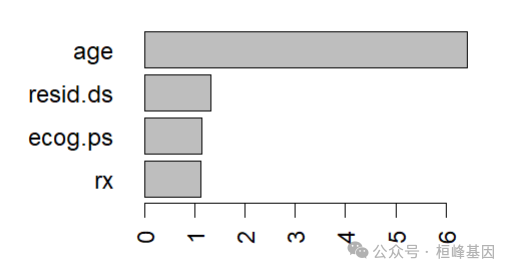
预测
pred <- predict(fit, ovarian, type = "response")
pred$num.independent.variables
## [1] 4ovarian$pred = ifelse(pred$survival[, 1] > median(pred$survival[, 1]), "High", "Low")一致性
library(Hmisc)
rcorr.cens(pred$survival[, 1], Surv(ovarian$futime, ovarian$fustat))
## C Index Dxy S.D. n missing
## 0.7889908 0.5779817 0.1475544 26.0000000 0.0000000
## uncensored Relevant Pairs Concordant Uncertain
## 12.0000000 436.0000000 344.0000000 214.0000000生存分析
直接做生存分析即可:
library(survminer)
km <- survfit(Surv(futime, fustat) ~ pred, data = ovarian)
ggsurvplot(km, data = ovarian, surv.median.line = "hv", legend.title = "Risk Group",
legend.labs = c("High Risk", "Low Risk"), pval = TRUE, ggtheme = theme_bw())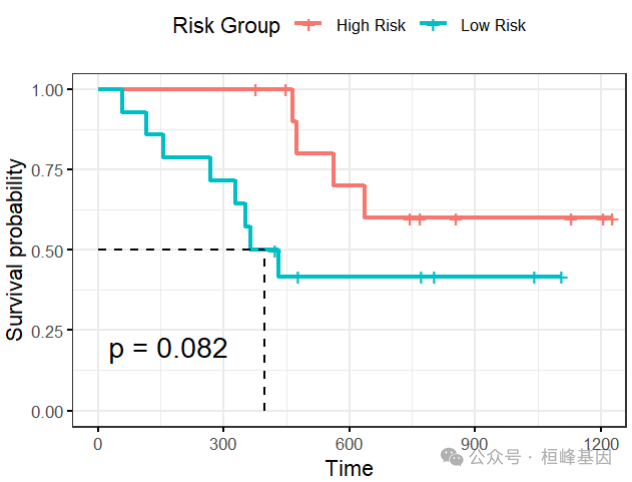
绘制ROC曲线
library(pROC)
roc <- roc(ovarian$fustat, pred$survival[, 1], legacy.axes = T, print.auc = T, print.auc.y = 45)
roc$auc
## Area under the curve: 0.7083plot(roc, legacy.axes = T, col = "red", lwd = 2, main = "ROC curv")
text(0.2, 0.2, paste("AUC: ", round(roc$auc, 3)))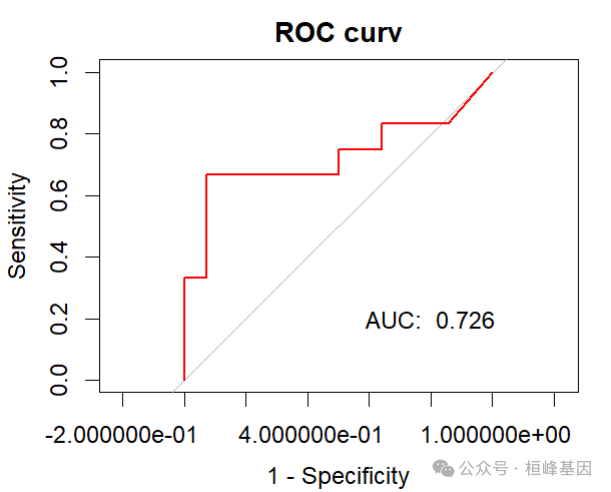
Reference
Wright, M. N. & Ziegler, A. (2017). ranger: A fast implementation of random forests for high dimensional data in C++ and R. J Stat Softw 77:1-17.
Schmid, M., Wright, M. N. & Ziegler, A. (2016). On the use of Harrell’s C for clinical risk prediction via random survival forests. Expert Syst Appl 63:450-459.
Wright, M. N., Dankowski, T. & Ziegler, A. (2017). Unbiased split variable selection for random survival forests using maximally selected rank statistics. Stat Med 36:1272-1284.
基于机器学习构建临床预测模型
ML 6. 癌症诊断机器学习之分类树(Classification Trees)
ML 7. 癌症诊断机器学习之回归树(Regression Trees)
ML 8. 癌症诊断机器学习之随机森林(Random Forest)
ML 9. 癌症诊断机器学习之梯度提升算法(Gradient Boosting)
ML 10. 癌症诊断机器学习之神经网络(Neural network)
ML 11. 机器学习之随机森林生存分析(randomForestSRC)
ML 12. 机器学习之降维方法t-SNE及可视化(Rtsne)
ML 13. 机器学习之降维方法UMAP及可视化 (umap)
ML 18. 机器学习之贝叶斯分析类器(Naive Bayes)
ML 20. 机器学习之袋装分类回归树(Bagged CART)
ML 21. 机器学习之临床医学上的生存分析(xgboost)
ML 22. 机器学习之有监督主成分分析筛选基因(SuperPC)
ML 23. 机器学习之岭回归预测基因型和表型(Ridge)
ML 24. 机器学习之似然增强Cox比例风险模型筛选变量及预后估计(CoxBoost)
ML 25. 机器学习之支持向量机应用于生存分析(survivalsvm)
ML 26. 机器学习之弹性网络算法应用于生存分析(Enet)
ML 27. 机器学习之逐步Cox回归筛选变量(StepCox)
ML 28. 机器学习之偏最小二乘回归应用于生存分析(plsRcox)
ML 31. 机器学习之基于RNA-seq的基因特征筛选 (GeneSelectR)
ML 32. 机器学习之支持向量机递归特征消除的特征筛选 (mSVM-RFE)
ML 33. 机器学习之时间-事件预测与神经网络和Cox回归
ML 34. 机器学习之竞争风险生存分析的深度学习方法(DeepHit)
ML 35. 机器学习之Lasso+Cox回归筛选变量 (LassoCox)
ML 36. 机器学习之基于神经网络的Cox比例风险模型 (Deepsurv)
ML 37. 机器学习之倾斜随机生存森林 (obliqueRSF)
ML 38. 机器学习之基于最近收缩质心分类法的肿瘤亚型分类器 (pamr)
ML 39. 机器学习之基于条件随机森林的生存分析临床预测 (CForest)
ML 40. 机器学习之基于条件推理树的生存分析临床预测 (CTree)
ML 41. 机器学习之参数生存回归模型 (survreg)
ML 42. 机器学习之Akritas条件非参数生存估计 (akritas)
ML 43. 机器学习之梯度增强线性模型用于生存数据 (glmboost)
ML 44. 机器学习之梯度提升回归树用于生存数据 (BlackBoost)
桓峰基因,铸造成功的您!
未来桓峰基因公众号将不间断的推出机器学习系列生信分析教程,
敬请期待!!
桓峰基因官网正式上线,请大家多多关注,还有很多不足之处,大家多多指正!http://www.kyohogene.com/
桓峰基因和投必得合作,文章润色优惠85折,需要文章润色的老师可以直接到网站输入领取桓峰基因专属优惠券码:KYOHOGENE,然后上传,付款时选择桓峰基因优惠券即可享受85折优惠哦!https://www.topeditsci.com/



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









