







自去年6月圈内知名的llama3-V抄袭事件已经过去了很久,我也因为海内外AI澎湃的发展,而忙于学习提升自我,都没怎么关注面壁这家有趣的国产AI公司了,呵呵🤭
羞愧啊,羞愧啊
MiniCPM-o 2.6
MiniCPM-o 2.6 是 MiniCPM-o 系列中最新、功能最强大的型号。该模型以端到端方式构建,基于 SigLip-400M、Whisper-medium-300M、ChatTTS-200M 和 Qwen2.5-7B,共有 8B 参数。与 MiniCPM-V 2.6 相比,它的性能有了显著提高,并为实时语音对话和多模态实时流媒体引入了新功能。MiniCPM-o 2.6 的显著特点包括:
- 🔥领先的可视化能力。 MiniCPM-o 2.6 在 OpenCompass 上获得了 70.2 的平均分,OpenCompass 是对 8 个常用基准的综合评估。 仅用 8B 参数,它就超越了广泛使用的专有模型,如 GPT-4o-202405、Gemini 1.5 Pro 和 Claude 3.5 Sonnet 对单一图像的理解。 在多图像和视频理解方面,它的表现也优于 GPT-4V 和 Claude 3.5 Sonnet,并显示出良好的上下文学习能力。
- 🎙 最先进的语音功能。 MiniCPM-o 2.6 支持中英文双语实时语音对话。 它在 ASR 和 STT 翻译等音频理解任务上的表现优于 GPT-4o-re-time,并在开源社区的语义和声学评估中显示出最先进的语音对话性能。 此外,它还能实现情感/速度/风格控制、端到端语音克隆、角色扮演等有趣的功能。
- 🎬 强大的多模态实时流功能。作为一项新功能,MiniCPM-o 2.6 可以接受独立于用户查询的连续视频和音频流,并支持实时语音交互。它的性能优于 GPT-4o-202408 和 Claude 3.5 Sonnet,并在开源社区的 StreamingBench(实时视频理解、全方位来源(视频和音频)理解以及多模态上下文理解的综合基准)上显示出一流的性能。
- 💪 强大的 OCR 功能和其他功能。MiniCPM-o 2.6 继承了 MiniCPM-V 系列的常用视觉功能,可处理任何长宽比、最多 180 万像素(如 1344x1344)的图像。对于 25B 以下的型号,它在 OCRBench 上达到了最先进的性能,超过了 GPT-4o-202405 等专有型号。它基于最新的 RLAIF-V 和 VisCPM 技术,具有值得信赖的行为,在 MMHal-Bench 上的表现优于 GPT-4o 和 Claude 3.5 Sonnet,并支持 30 多种语言的多语言功能。
- 🚀 卓越的效率。 除了大小适中,MiniCPM-o 2.6 还显示出最先进的标记密度(即编码到每个视觉标记中的像素数)。 在处理 1.8 百万像素图像时,它只产生 640 个标记,比大多数模型少 75%。 这直接提高了推理速度、首次标记延迟、内存使用和功耗。 因此,MiniCPM-o 2.6 可以在 iPad 等终端设备上高效支持多模态流媒体直播。
- 💫 易于使用。 MiniCPM-o 2.6 可通过多种方式轻松使用:(1) 支持 llama.cpp,可在本地设备上进行高效 CPU 推理;(2) 支持 16 种大小的 int4 和 GGUF 格式量化模型;(3) 支持 vLLM,可进行高吞吐量和内存效率推理;(4) 利用 LLaMA-Factory 在新领域和新任务上进行微调;(5) 利用 Gradio 快速设置本地 WebUI 演示;(6) 在服务器上进行在线 Web 演示。
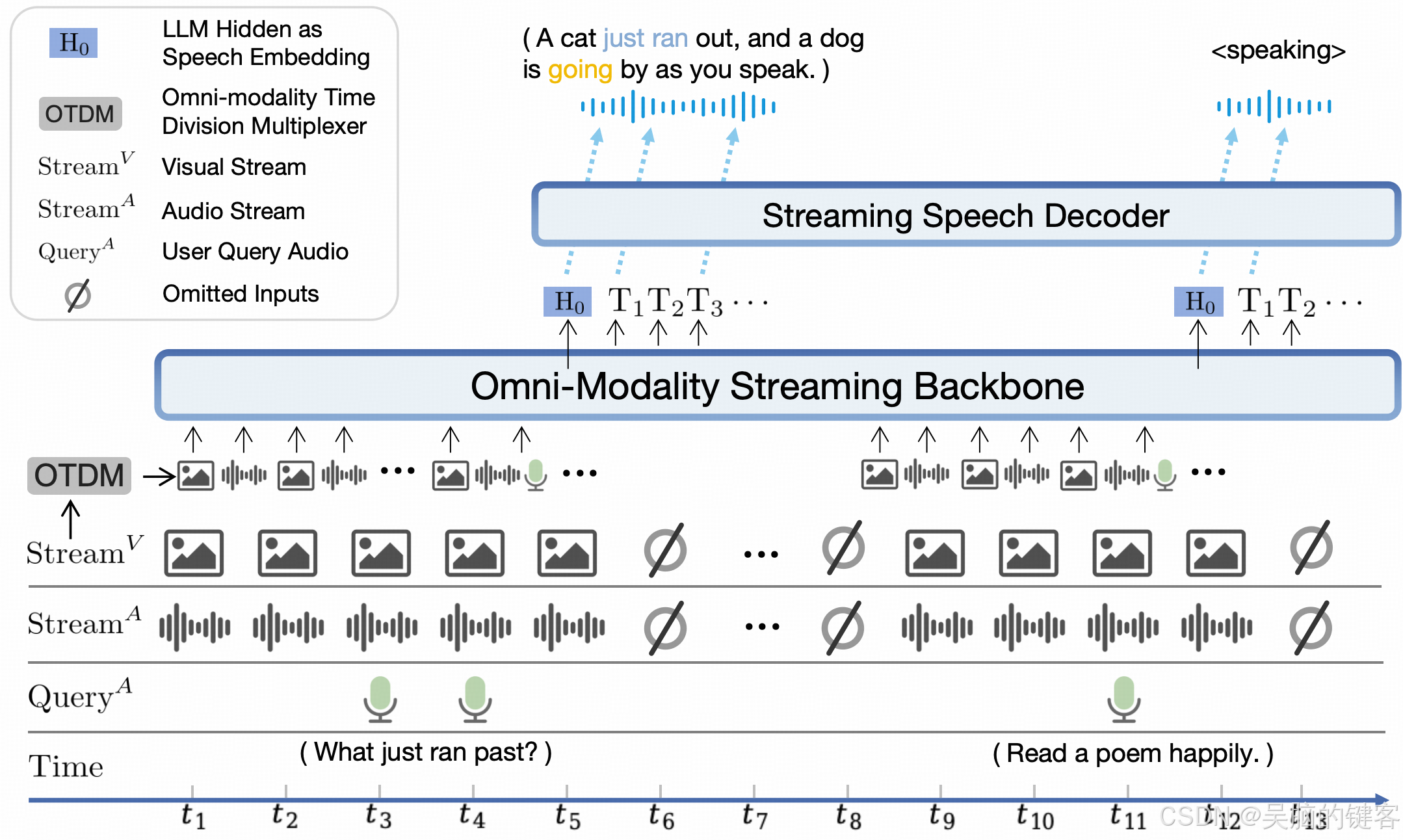
模型结构
- 端到端全模态架构。 不同模态的编码器/解码器以端到端方式连接和训练,以充分利用丰富的多模态知识。
- 全模式实时流媒体机制。 (1) 我们将离线模式编码器/解码器改为在线模式,用于流媒体输入/输出。 (2) 我们为 LLM 主干网中的全模式流处理设计了一种时分复用(TDM)机制。 它将并行的全模式流划分为小周期时间片内的连续信息。
- 可配置的语音建模设计。 我们设计了一种多模态系统提示,包括传统的文本系统提示和新的音频系统提示,以确定助理语音。 这样就能在推理时灵活配置语音,还能促进端到端的语音克隆和基于描述的语音创建。
评估
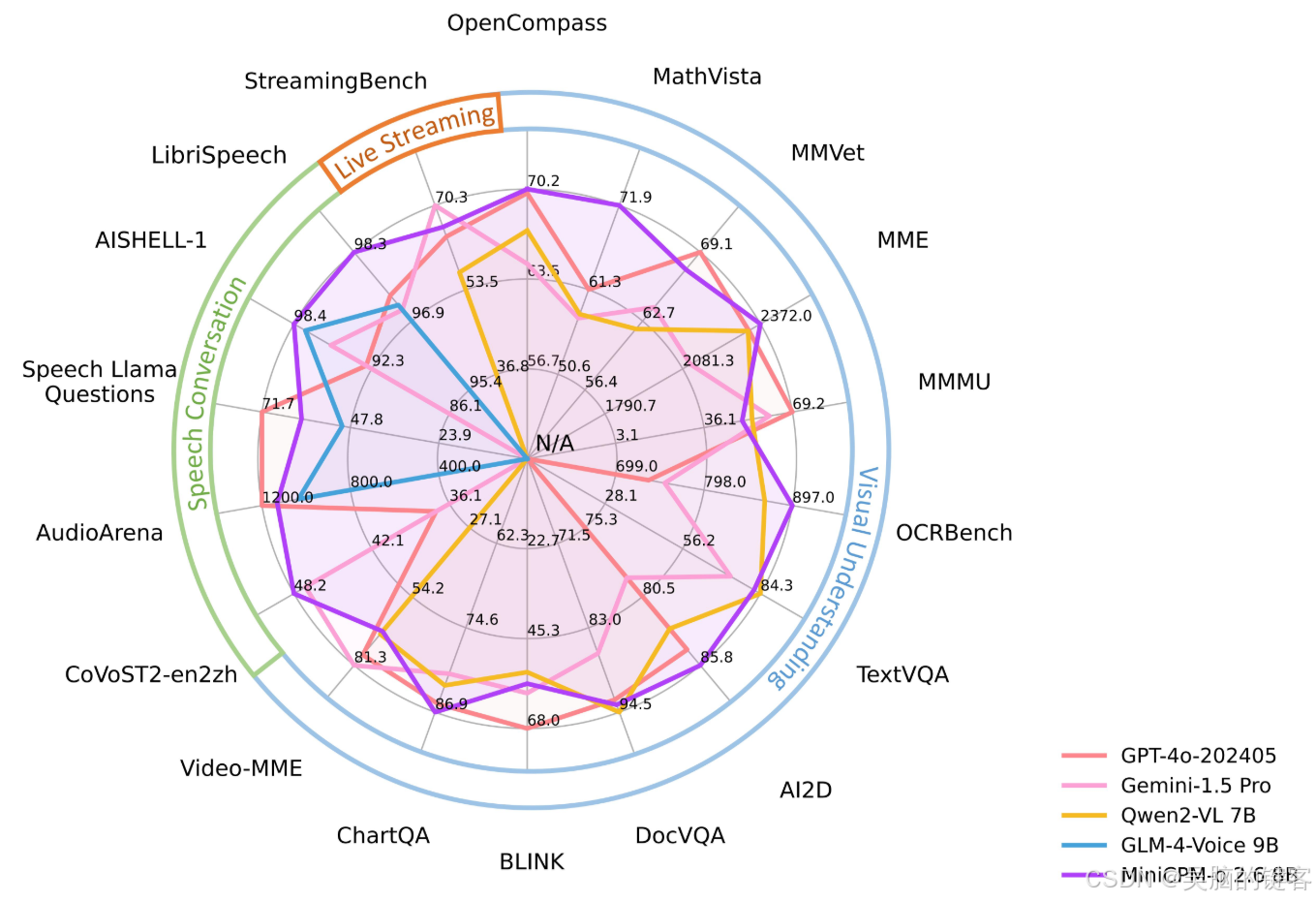
视觉理解结果
图像理解:
| Model | Size | Token Density+ | OpenCompass | OCRBench | MathVista mini | ChartQA | MMVet | MMStar | MME | MMB1.1 test | AI2D | MMMU val | HallusionBench | TextVQA val | DocVQA test | MathVerse mini | MathVision | MMHal Score |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Proprietary | ||||||||||||||||||
| GPT-4o-20240513 | - | 1088 | 69.9 | 736 | 61.3 | 85.7 | 69.1 | 63.9 | 2328.7 | 82.2 | 84.6 | 69.2 | 55.0 | - | 92.8 | 50.2 | 30.4 | 3.6 |
| Claude3.5-Sonnet | - | 750 | 67.9 | 788 | 61.6 | 90.8 | 66.0 | 62.2 | 1920.0 | 78.5 | 80.2 | 65.9 | 49.9 | - | 95.2 | - | - | 3.4 |
| Gemini 1.5 Pro | - | - | 64.4 | 754 | 57.7 | 81.3 | 64.0 | 59.1 | 2110.6 | 73.9 | 79.1 | 60.6 | 45.6 | 73.5 | 86.5 | - | 19.2 | - |
| GPT-4o-mini-20240718 | - | 1088 | 64.1 | 785 | 52.4 | - | 66.9 | 54.8 | 2003.4 | 76.0 | 77.8 | 60.0 | 46.1 | - | - | - | - | 3.3 |
| Open Source | ||||||||||||||||||
| Cambrian-34B | 34B | 1820 | 58.3 | 591 | 50.3 | 75.6 | 53.2 | 54.2 | 2049.9 | 77.8 | 79.5 | 50.4 | 41.6 | 76.7 | 75.5 | - | - | - |
| GLM-4V-9B | 13B | 784 | 59.1 | 776 | 51.1 | - | 58.0 | 54.8 | 2018.8 | 67.9 | 71.2 | 46.9 | 45.0 | - | - | - | - | - |
| Pixtral-12B | 12B | 256 | 61.0 | 685 | 56.9 | 81.8 | 58.5 | 54.5 | - | 72.7 | 79.0 | 51.1 | 47.0 | 75.7 | 90.7 | - | - | - |
| DeepSeek-VL2-27B (4B) | 27B | 672 | 66.4 | 809 | 63.9 | 86.0 | 60.0 | 61.9 | 2253.0 | 81.2 | 83.8 | 54.0 | 45.3 | 84.2 | 93.3 | - | - | 3.0 |
| Qwen2-VL-7B | 8B | 784 | 67.1 | 866 | 58.2 | 83.0 | 62.0 | 60.7 | 2326.0 | 81.8 | 83.0 | 54.1 | 50.6 | 84.3 | 94.5 | 31.9 | 16.3 | 3.2 |
| LLaVA-OneVision-72B | 72B | 182 | 68.1 | 741 | 67.5 | 83.7 | 60.6 | 65.8 | 2261.0 | 85.0 | 85.6 | 56.8 | 49.0 | 80.5 | 91.3 | 39.1 | - | 3.5 |
| InternVL2.5-8B | 8B | 706 | 68.3 | 822 | 64.4 | 84.8 | 62.8 | 62.8 | 2344.0 | 83.6 | 84.5 | 56.0 | 50.1 | 79.1 | 93.0 | 39.5 | 19.7 | 3.4 |
| MiniCPM-V 2.6 | 8B | 2822 | 65.2 | 852* | 60.6 | 79.4 | 60.0 | 57.5 | 2348.4* | 78.0 | 82.1 | 49.8* | 48.1* | 80.1 | 90.8 | 25.7 | 18.3 | 3.6 |
| MiniCPM-o 2.6 | 8B | 2822 | 70.2 | 897* | 71.9* | 86.9* | 67.5 | 64.0 | 2372.0* | 80.5 | 85.8 | 50.4* | 51.9 | 82.0 | 93.5 | 41.4* | 23.1* | 3.8 |
- 我们使用思维链提示对该基准进行了评估。
- 标记密度:最大分辨率下每个视觉标记编码的像素数,即:#最大分辨率下的像素数/#视觉标记数、
注意:对于专有模型,我们根据官方 API 文档中定义的图像编码计费策略计算令牌密度,该策略可提供上限估计值。
多图像和视频理解
| Model | Size | BLINK val | Mantis Eval | MIRB | Video-MME (wo / w subs) |
|---|---|---|---|---|---|
| Proprietary | |||||
| GPT-4o-20240513 | - | 68.0 | - | - | 71.9/77.2 |
| GPT4V | - | 54.6 | 62.7 | 53.1 | 59.9/63.3 |
| Open-source | |||||
| LLaVA-NeXT-Interleave 14B | 14B | 52.6 | 66.4 | 30.2 | - |
| LLaVA-OneVision-72B | 72B | 55.4 | 77.6 | - | 66.2/69.5 |
| MANTIS 8B | 8B | 49.1 | 59.5 | 34.8 | - |
| Qwen2-VL-7B | 8B | 53.2 | 69.6* | 67.6* | 63.3/69.0 |
| InternVL2.5-8B | 8B | 54.8 | 67.7 | 52.5 | 64.2/66.9 |
| MiniCPM-V 2.6 | 8B | 53.0 | 69.1 | 53.8 | 60.9/63.6 |
| MiniCPM-o 2.6 | 8B | 56.7 | 71.9 | 58.6 | 63.9/67.9 |
- 我们自行评估官方公布的checkpoints 。


















 1376
1376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









