







在人工智能领域,多模态推理一直是研究的热点和难点。随着技术的不断进步,如何让机器像人类一样,通过视觉、文本等多种模态信息进行深度思考和推理,成为了众多科研团队追求的目标。近日,阿里通义千问团队推出的QVQ-Max视觉推理模型,为这一领域带来了新的突破和惊喜。

一、QVQ-Max:不仅仅是“看懂”,更是深度推理
QVQ-Max作为阿里通义千问团队在视觉推理领域的新成果,其核心能力在于对图片和视频内容的深度理解和推理。与传统的视觉理解模型不同,QVQ-Max不仅能够识别图像中的物体、场景等基本信息,还能进一步结合背景知识和上下文信息,进行复杂的分析和推理。
例如,在处理一道几何题时,QVQ-Max可以根据题目附带的图形,推导出正确的答案。这种能力不仅体现了模型对视觉信息的精准解析,更展示了其强大的逻辑推理能力。这种深度推理能力,使得QVQ-Max在解决复杂问题时表现出了超越传统模型的优势。
二、应用场景:从教育到生活,从艺术到编程
QVQ-Max的多模态处理能力,使其在多个领域都有广泛的应用前景。在教育领域,它可以协助学生解答配有图表的数学、物理等科目的难题,并通过直观的方式讲解复杂概念。对于教师来说,QVQ-Max可以成为教学辅助工具,帮助设计教学内容和评估学生的学习成果。
在日常生活中,QVQ-Max可以根据衣柜照片推荐穿搭方案,基于食谱图片指导用户烹饪。这种能力为人们的生活带来了极大的便利,也让人工智能更加贴近普通用户的需求。
在艺术创作方面,QVQ-Max能够根据用户上传的草稿,帮助其完善成一幅完整的作品。对于设计师和艺术家来说,这无疑是一个强大的创作助手。此外,QVQ-Max还能够看视频自学编程,观看了一个类似贪吃蛇的小游戏视频后,很快就复刻了一个类似游戏,并给出了完整的代码。这种能力为编程教育和软件开发领域带来了新的可能性。
三、技术突破:从QVQ到QVQ-Max
QVQ-Max的推出,是阿里通义千问团队在视觉推理领域的一次重要技术突破。与去年12月发布的QVQ-72B-Preview相比,QVQ-Max在多个方面进行了优化和升级。首先,QVQ-Max在模型结构上进行了改进,增强了对多模态信息的融合和处理能力。其次,通过大量的训练数据和优化算法,QVQ-Max在视觉理解和推理任务上的表现更加出色。
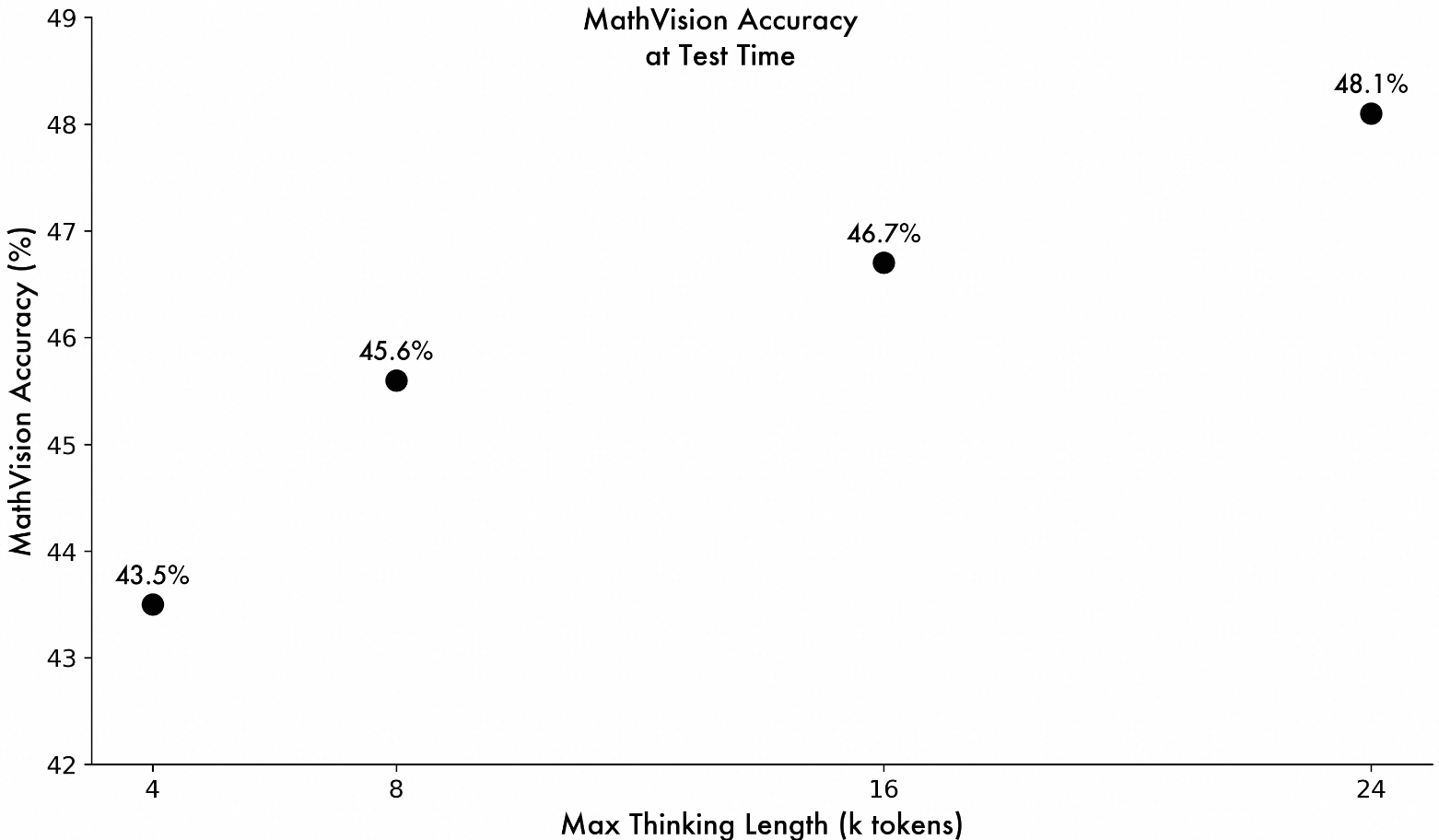
此外,QVQ-Max还引入了一些新的技术,如逐步推理机制,使得模型在解决复杂问题时能够更加细致和准确。这种逐步推理机制,不仅提高了模型的准确率,还增强了其可解释性,让用户能够更好地理解模型的思考过程。
四、未来展望:更智能、更实用的视觉推理模型
QVQ-Max的推出,标志着阿里通义千问团队在视觉推理领域迈出了重要的一步。然而,这只是一个开始。未来,研究人员将继续优化模型的性能,提高其在多模态信息处理和复杂推理任务上的能力。
可以预见的是,随着技术的不断发展和完善,QVQ-Max将为人工智能领域带来更多的可能性和惊喜。它将成为人们生活和工作的得力助手,为解决各种实际问题提供强大的支持。
总之,阿里通义千问推出的QVQ-Max视觉推理模型,以其强大的多模态处理能力和深度推理能力,为人工智能领域注入了新的活力。我们有理由相信,在不久的将来,QVQ-Max将在更多的领域发挥其独特的优势,为人类创造更多的价值。
https://chat.qwen.ai/

















 132
132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









