







摘要
本文将从零开始构建一个多分类的 PyTorch 项目,以预测二手手机的价格区间。我们会详细介绍数据集构建、模型设计、模型训练、模型评估等流程,并结合可视化(如混淆矩阵、分类报告)来剖析模型效果。最后,还给出多种可行的改进方法(如使用 Adam、增加网络深度、标准化数据等),帮助你快速提升模型表现。
目录
1. 项目背景与需求
2. 数据准备与可视化
3. 模型构建与改进思路
4. 训练与评估
6. 改进思路
7. 总结
1. 项目背景与需求
小明创办了一家手机公司,他需要根据手机的各种硬件配置(如 RAM、CPU、分辨率等)来预测二手手机的价格区间。我们将价格区间用 0、1、2、3 四个数字表示。因此这是一个 多分类问题。
为此,我们收集了 2000 条二手手机数据,每条数据包含 20 个特征以及一个目标标签(价格区间)。本文将演示如何:
1. 读取并可视化数据
2. 构建全连接神经网络模型
3. 使用 Adam 优化器(可选)训练模型
4. 评估模型并可视化结果(混淆矩阵、分类指标)
2. 数据准备
先上完整代码,读者可在阅读代码注释时一并了解实现过程。请确保在 data/phone 目录下有一个名为 手机价格预测.csv 的数据文件,其中最后一列是价格区间(0/1/2/3),前 20 列是各类特征。
import torch
from torch.utils.data import TensorDataset, DataLoader
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import time
# 新增:为了查看分类指标和混淆矩阵
from sklearn.metrics import confusion_matrix, classification_report
# ========== 1. 数据集构建与可视化 ==========
def create_dataset(standardize=False):
"""
从本地 CSV 文件读取数据,并将其拆分为训练集和验证集。
参数:
- standardize: 布尔值,是否对数据进行标准化处理(转换为均值0、方差1)
返回:
- train_dataset: 训练数据构建的 TensorDataset 对象
- valid_dataset: 验证数据构建的 TensorDataset 对象
- input_dim: 输入特征的数量(即特征的维度)
- class_num: 分类类别数(本例中为4,代表4个价格区间)
- x_train, x_valid, y_train, y_valid: 分割后的训练与验证数据,便于后续可视化或其他操作
"""
# 1. 使用 pandas 读取 CSV 数据,文件路径为 'data/phone/手机价格预测.csv'
data = pd.read_csv('data/phone/手机价格预测.csv')
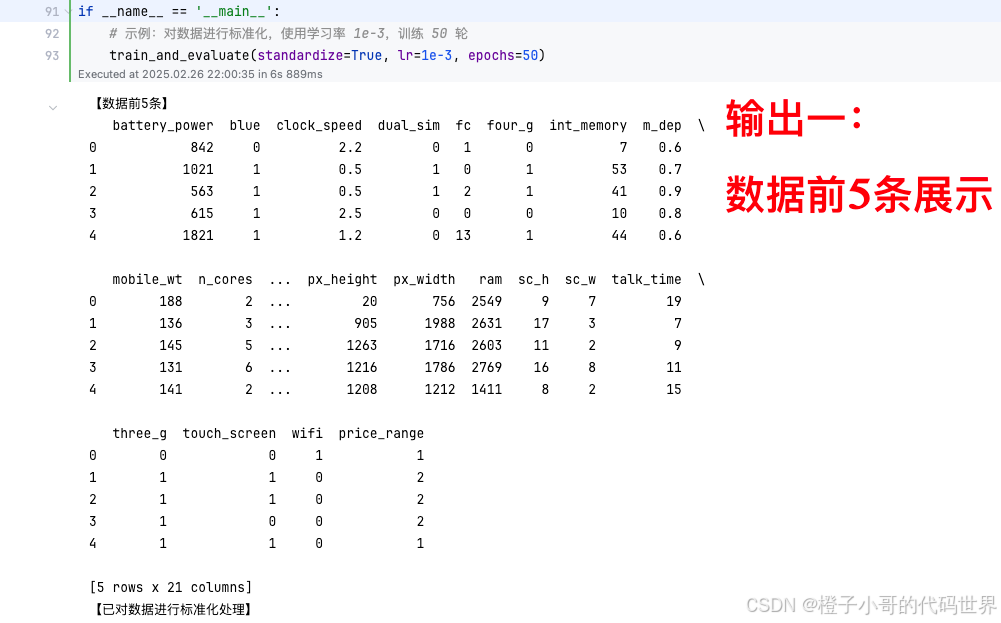
# 简单查看数据的前5条,帮助了解数据结构与分布情况
print("【数据前5条】")
print(data.head(5))
# 2. 分离特征和标签。这里假设 CSV 文件最后一列为价格区间(目标变量),前面为特征
x, y = data.iloc[:, :-1], data.iloc[:, -1]
# 3. 转换数据类型:
# 将特征数据转换为 float32 类型,标签转换为 int64 类型(PyTorch 通常要求标签为长整型)
x = x.astype(np.float32)
y = y.astype(np.int64)
# 可选:对数据进行标准化处理
if standardize:
# 计算特征数据的均值和标准差
mean_vals = x.mean()
std_vals = x.std() + 1e-8 # 加上一个极小值防止除0错误
# 对数据进行 Z-Score 标准化: (x - 均值) / 标准差
x = (x - mean_vals) / std_vals
print("【已对数据进行标准化处理】")
# 4. 划分训练集和验证集,使用 sklearn 的 train_test_split
# train_size=0.8 表示 80% 的数据用于训练,20% 用于验证;random_state 保证每次划分一致
x_train, x_valid, y_train, y_valid = train_test_split(
x, y, train_size=0.8, random_state=88
)
# 5. 将 pandas DataFrame 转为 NumPy 数组,再转换为 PyTorch 张量
# 构造 TensorDataset 对象,便于后续使用 DataLoader 加载数据
train_dataset = TensorDataset(
torch.from_numpy(x_train.values),
torch.tensor(y_train.values)
)
valid_dataset = TensorDataset(
torch.from_numpy(x_valid.values),
torch.tensor(y_valid.values)
)
# 6. 获取输入特征数(即数据集中的列数)和标签类别数(通常为4个价格区间)
input_dim = x_train.shape[1] # 特征的维度
class_num = len(np.unique(y)) # 目标类别数
return train_dataset, valid_dataset, input_dim, class_num, x_train, x_valid, y_train, y_valid代码说明
1. 数据集构建部分
• 使用 pandas.read_csv 读取存放数据的 CSV 文件,路径为 'data/phone/手机价格预测.csv'。
• 利用 data.head(5) 打印前 5 条数据,方便快速了解数据结构。
• 利用 iloc 分离特征(前几列)与标签(最后一列)。
• 将特征转换为 float32,标签转换为 int64 以符合 PyTorch 数据要求。
• 若设置 standardize=True,则对特征进行 Z-Score 标准化:每个特征减去均值并除以标准差(加上微小值以防除零)。
• 使用 train_test_split 将数据分为 80% 的训练集和 20% 的验证集。
• 最后将数据从 DataFrame 转换为 NumPy 数组,再转换为 PyTorch 张量,并封装成 TensorDataset 对象返回,同时获取特征维度和类别数。
3. 模型构建
我们使用一个三层的全连接神经网络,结构如下:
• 输入层(大小 = input_dim)
• 第 1 层:线性层(输入 20 → 输出 128)
• 第 2 层:线性层(输入 128 → 输出 256)
• 第 3 层:线性层(输入 256 → 输出 4)
# ========== 2. 模型构建 ==========
import torch.nn.functional as F
from torchsummary import summary # 可选:用于查看模型结构,需要先安装 torchsummary
class PhonePriceModel(nn.Module):
def __init__(self, input_dim, output_dim):
"""
构造一个三层全连接神经网络,用于手机价格区间分类。
参数:
- input_dim: 输入特征的数量(例如:20)
- output_dim: 分类数量(本例中为4)
"""
super(PhonePriceModel, self).__init__()
# 第 1 层全连接层:将输入特征映射到128个隐藏节点
self.linear1 = nn.Linear(input_dim, 128)
# 第 2 层全连接层:将128个隐藏节点映射到256个隐藏节点
self.linear2 = nn.Linear(128, 256)
# 第 3 层全连接层(输出层):将256个隐藏节点映射到 output_dim 个节点(对应分类数)
self.linear3 = nn.Linear(256, output_dim)
# 可选:添加 Dropout 层用于正则化,防止过拟合(此处注释掉,可根据需要启用)
# self.dropout = nn.Dropout(p=0.3)
def forward(self, x):
"""
定义前向传播函数
参数:
- x: 输入张量,形状为 [batch_size, input_dim]
返回:
- output: 网络的输出(未经过 softmax),形状为 [batch_size, output_dim]
"""
# 第 1 层:线性变换后使用 ReLU 激活函数
x = F.relu(self.linear1(x))
# 第 2 层:线性变换后使用 ReLU 激活函数
x = F.relu(self.linear2(x))
# 可选:在第二层后添加 Dropout 层(用于正则化)
# x = self.dropout(x)
# 第 3 层:线性变换输出最终结果
output = self.linear3(x)
return output
# 如果需要查看模型结构,可在主函数中调用 summary
if __name__ == '__main__':
# 假设 input_dim 和 class_num 已从 create_dataset 函数中获得
# 这里仅做示例,实际使用时请保证 input_dim 和 class_num 的值已定义
input_dim = 20 # 示例输入特征数
class_num = 4 # 示例分类数量
model = PhonePriceModel(input_dim, class_num)
summary(model, input_size=(input_dim,), batch_size=16)模型构建部分
• 定义了一个继承自 nn.Module 的 PhonePriceModel 类。
• 在 __init__ 方法中,依次创建三层全连接层(nn.Linear),分别实现输入层到隐藏层、隐藏层到隐藏层、隐藏层到输出层的映射。
• 在 forward 方法中,按顺序对输入数据依次通过各层,并在前两层后使用 ReLU 激活函数。
• 可选项:在第二层之后可以添加 Dropout 层来减少过拟合风险(此处代码已注释,可根据需要启用)。
• 最后返回的是网络的输出 logits,适合后续与 CrossEntropyLoss 搭配使用。
查看模型结构
• 使用 torchsummary.summary 函数(需要预先安装 torchsummary)来查看模型各层的参数数量和输出形状。
• 示例中假设 input_dim 为 20,class_num 为 4,批次大小为 16。
4. 训练与评估
下面的代码中,我们用 Adam,学习率也可以自行调节。并且支持选择是否标准化数据。
def train_and_evaluate(standardize=True, lr=1e-3, epochs=50):
"""
训练并评估手机价格分类模型
参数:
- standardize: 布尔值,是否对输入特征数据进行标准化处理(均值为0,标准差为1)
- lr: 学习率(控制参数更新的步长)
- epochs: 训练轮数(整个训练集被迭代的次数)
"""
# ========== 数据集构建 ==========
# 调用 create_dataset 函数,构建训练集和验证集数据,同时获取输入特征数和类别数,
# 以及训练集和验证集的原始数据(用于后续可视化等操作)
train_dataset, valid_dataset, input_dim, class_num, x_train, x_valid, y_train, y_valid = create_dataset(standardize=standardize)
# ========== 模型构建 ==========
# 实例化一个手机价格分类模型,输入维度为 input_dim,分类数为 class_num
model = PhonePriceModel(input_dim, class_num)
# 查看模型结构(可选操作,需要提前安装 torchsummary)
# summary(model, input_size=(input_dim,), batch_size=16)
# ========== 损失函数与优化器 ==========
# 定义损失函数,使用 CrossEntropyLoss,适用于多分类任务
criterion = nn.CrossEntropyLoss()
# 使用 Adam 优化器对模型参数进行优化,学习率设为 lr
optimizer = optim.Adam(model.parameters(), lr=lr)
# ========== 训练模型 ==========
# 开始训练指定轮数
for epoch_idx in range(epochs):
# 使用 DataLoader 封装训练数据集,每个批次(batch)包含8个样本,数据顺序随机打乱(shuffle=True)
dataloader = DataLoader(train_dataset, shuffle=True, batch_size=8)
# 记录当前轮训练开始的时间
start_time = time.time()
total_loss = 0.0 # 用于累计该轮次所有 batch 的损失值
total_num = 0 # 记录处理的 batch 数量(用于计算平均损失)
# 遍历每个 batch 数据
for x, y in dataloader:
# 前向传播:将当前批次数据 x 输入模型,获得输出 logits(未经 softmax)
output = model(x)
# 计算当前批次的损失值,CrossEntropyLoss 内部会先对 logits 计算 softmax 再计算交叉熵损失
loss = criterion(output, y)
# 清空优化器中存储的梯度,防止梯度累加
optimizer.zero_grad()
# 反向传播:自动计算损失关于模型参数的梯度
loss.backward()
# 根据计算得到的梯度更新模型参数
optimizer.step()
# 累加当前 batch 的损失
total_loss += loss.item()
total_num += 1
# 计算本轮训练的平均损失,并打印该轮次的损失和耗时
print("Epoch: %2d | Loss: %.4f | Time: %.2fs"
% (epoch_idx + 1, total_loss / total_num, time.time() - start_time))
# ========== 模型保存 ==========
# 训练完成后,将模型的参数(state_dict)保存到 'model/phone.pth' 文件中
torch.save(model.state_dict(), 'model/phone/phone_new.pth')
print("模型已保存到 model/phone/phone_new.pth")
# ========== 模型评估:验证集准确率 ==========
# 将模型切换到评估模式,评估模式下会关闭 dropout、batch normalization 等训练时的特殊行为
model.eval()
# 使用 DataLoader 加载验证集数据,每个批次包含8个样本,且不打乱数据顺序
valid_loader = DataLoader(valid_dataset, batch_size=8, shuffle=False)
correct = 0 # 用于记录预测正确的样本数
total = 0 # 记录验证集总样本数
# 在评估时不需要计算梯度,因此使用 no_grad() 上下文管理器
with torch.no_grad():
for x, y in valid_loader:
# 前向传播获得验证集样本的预测输出
output = model(x)
# 使用 argmax 获取预测类别,即取输出中最大值的索引(dim=1 表示按行操作)
y_pred = torch.argmax(output, dim=1)
# 累加预测正确的样本数(y_pred == y 返回布尔型张量,通过 sum() 得到正确的数量)
correct += (y_pred == y).sum().item()
# 累加本 batch 中的样本数
total += y.size(0)
# 计算验证集的准确率(预测正确样本数 / 总样本数)
acc = correct / total
print("验证集准确率: %.5f" % acc)
if __name__ == '__main__':
# 示例:对数据进行标准化,使用学习率 1e-3,训练 50 轮
train_and_evaluate(standardize=True, lr=1e-3, epochs=50)训练过程
- • 使用 DataLoader 按批次加载数据;每个批次计算前向传播、损失计算、反向传播以及参数更新。
- • 使用 Adam 优化器 代替传统的 SGD,使学习过程更快、更稳定;可以通过调节学习率(lr)和训练轮数(epochs)进行优化。
- • 每个 epoch 后打印平均损失和耗时,并最终保存模型参数。
5. 结果分析:混淆矩阵与分类指标
仅仅查看准确率并不能完整评估模型的好坏。我们可以在验证集上计算 混淆矩阵和分类报告(precision, recall, f1-score 等)。
def evaluate_metrics(standardize=True):
"""
加载训练好的模型,对验证集进行预测,并输出混淆矩阵和分类指标报告。
参数:
- standardize: 布尔值,是否对数据进行标准化处理,默认为 True。
"""
# 1. 加载数据
# 调用 create_dataset 函数构建数据集,返回训练集、验证集以及数据维度信息
# 此外还返回原始的 x_train, x_valid, y_train, y_valid 以便后续可能进行可视化等操作
train_dataset, valid_dataset, input_dim, class_num, x_train, x_valid, y_train, y_valid = create_dataset(standardize=standardize)
# 2. 实例化模型并加载已训练的参数
# 根据输入特征数(input_dim)和类别数(class_num)构造模型
model = PhonePriceModel(input_dim, class_num)
# 加载保存在 'model/phone.pth' 文件中的模型参数
model.load_state_dict(torch.load('model/phone.pth'))
# 将模型切换到评估模式,评估模式下会关闭 dropout、batch normalization 等训练时特有的功能
model.eval()
# 3. 使用 DataLoader 进行预测
# 构造验证集的 DataLoader,不需要打乱数据,批次大小设置为 8
valid_loader = DataLoader(valid_dataset, batch_size=8, shuffle=False)
# 初始化两个空列表,分别用于存储所有预测结果和真实标签
all_preds = []
all_labels = []
# 在 no_grad() 上下文中,不会计算梯度,从而节省内存和加速推理
with torch.no_grad():
# 遍历验证集中的每个批次数据
for x, y in valid_loader:
# 将当前批次数据 x 输入模型,得到输出 logits(未经过 softmax 转换)
output = model(x)
# 使用 torch.argmax 函数沿着每行(dim=1)选取最大值对应的索引,作为预测类别
y_pred = torch.argmax(output, dim=1)
# 将预测结果转换为列表,并添加到 all_preds 中
all_preds.extend(y_pred.tolist())
# 同时,将真实标签转换为列表添加到 all_labels 中
all_labels.extend(y.tolist())
# 4. 计算混淆矩阵
# 使用 sklearn.metrics.confusion_matrix 函数计算混淆矩阵,
# 混淆矩阵的行表示真实标签,列表示预测标签
cm = confusion_matrix(all_labels, all_preds)
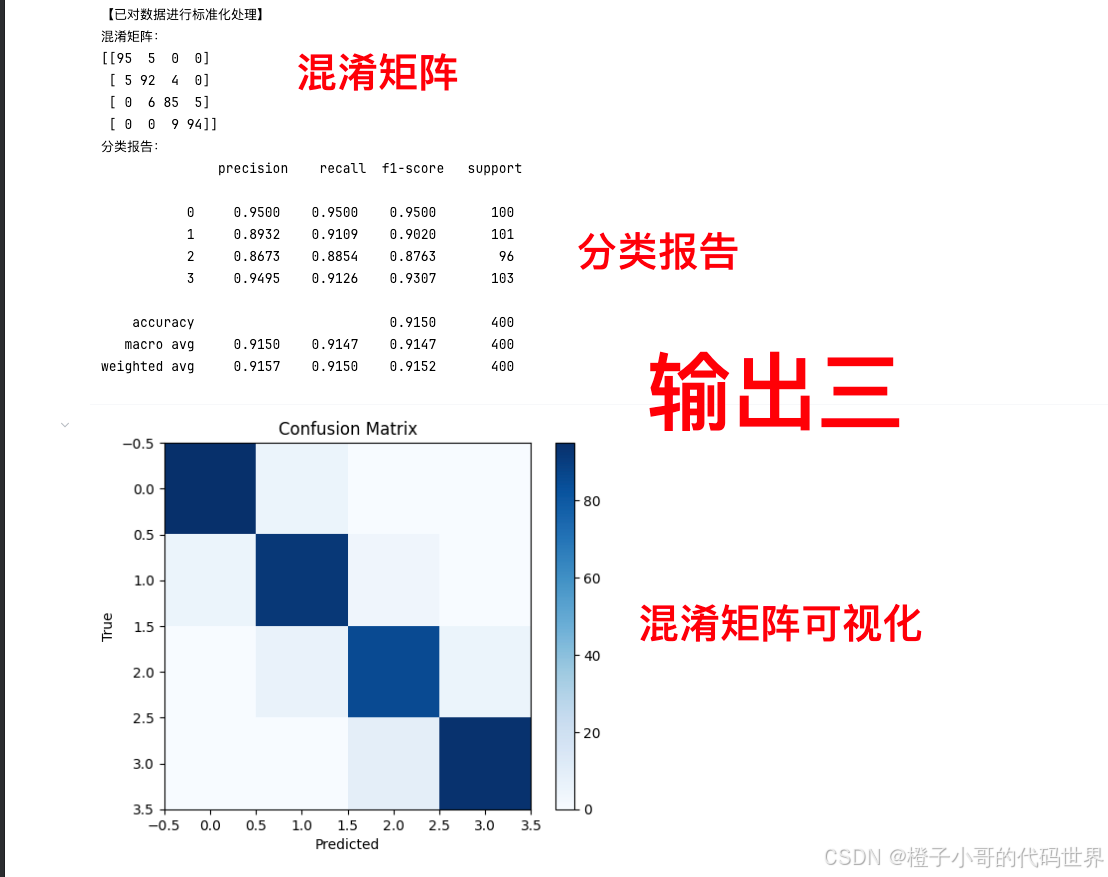
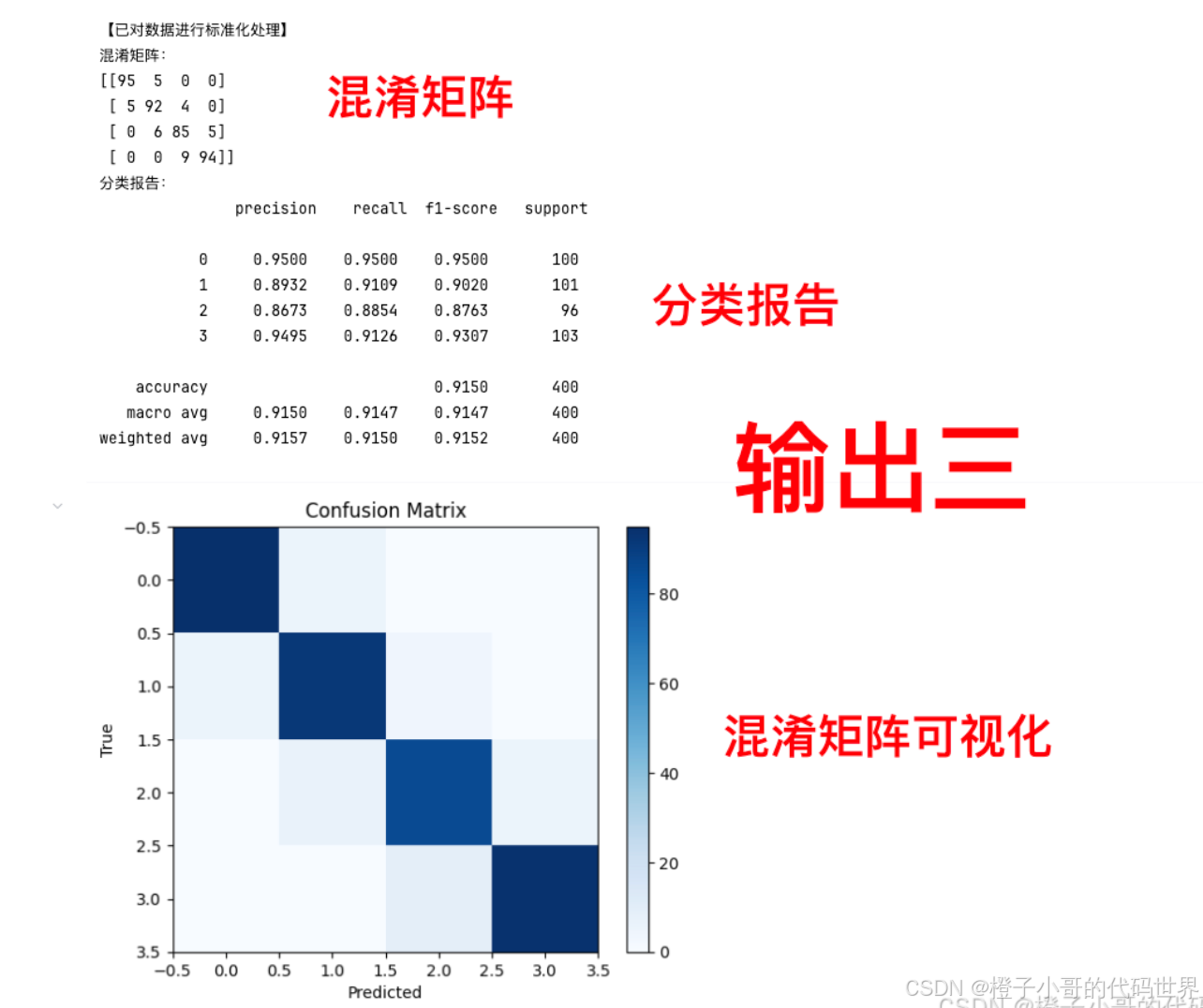
print("混淆矩阵:")
print(cm)
# 5. 打印分类报告
# 使用 sklearn.metrics.classification_report 生成分类指标报告,包含精确率(precision)、召回率(recall)和 F1 分数
report = classification_report(all_labels, all_preds, digits=4)
print("分类报告:\n", report)
# 6. 可视化混淆矩阵(简单示例)
# 使用 matplotlib.pyplot 绘制混淆矩阵图像
plt.imshow(cm, cmap='Blues') # 使用蓝色渐变显示混淆矩阵数值的大小
plt.title("Confusion Matrix") # 设置图像标题
plt.colorbar() # 添加颜色条,表示数值大小
plt.xlabel("Predicted") # x 轴标签表示预测类别
plt.ylabel("True") # y 轴标签表示真实类别
plt.show() # 显示绘制的图像
if __name__ == '__main__':
evaluate_metrics(standardize=True)• 混淆矩阵:行表示真实标签,列表示预测标签。对角线越大越好。
• 分类报告:包括精确率(precision)、召回率(recall)、F1-score 等指标。
6. 代码的输出与解释:

下面对混淆矩阵和分类报告做详细解释,帮助你理解模型在各类别上的表现:
一、混淆矩阵解读
混淆矩阵展示了模型在每个类别上的预测结果,其行表示真实标签,列表示预测标签。对于你的混淆矩阵:
[[95 5 0 0]
[ 5 92 4 0]
[ 0 6 85 5]
[ 0 0 9 94]]• 第一行(真实类别 0):
- • 模型正确预测 95 个样本为类别 0,
- • 错误地将 5 个样本预测为类别 1,
- • 没有预测为类别 2 或类别 3。
- • 支持数(support)为 100,即真实类别 0 的样本总数为 100。
• 第二行(真实类别 1):
- • 模型正确预测 92 个样本为类别 1,
- • 错误预测 5 个样本为类别 0,
- • 错误预测 4 个样本为类别 2,
- • 没有预测为类别 3,
- • 支持数为 101。
• 第三行(真实类别 2):
- • 模型正确预测 85 个样本为类别 2,
- • 错误预测 6 个样本为类别 1,
- • 错误预测 5 个样本为类别 3,
- • 没有预测为类别 0,
- • 支持数为 96。
• 第四行(真实类别 3):
- • 模型正确预测 94 个样本为类别 3,
- • 错误预测 9 个样本为类别 2,
- • 没有预测为类别 0 或 1,
- • 支持数为 103。
通过混淆矩阵,我们可以直观地看出:
• 模型在类别 0 和类别 3 上表现较好(正确率较高)。
• 类别 2 的召回率较低,因为有 6 个样本被错误预测为类别 1,还有 5 个被误认为类别 3。
二、分类报告解读
分类报告提供了精确率(precision)、召回率(recall)、F1-score 以及每个类别的样本数(support):
precision recall f1-score support
0 0.9500 0.9500 0.9500 100
1 0.8932 0.9109 0.9020 101
2 0.8673 0.8854 0.8763 96
3 0.9495 0.9126 0.9307 103
accuracy 0.9150 400
macro avg 0.9150 0.9147 0.9147 400
weighted avg 0.9157 0.9150 0.9152 400• Precision(精确率):
- 表示预测为某个类别的样本中,有多少比例是正确的。
- 例如,对于类别 0:精确率为 0.9500,说明模型预测为类别 0 的样本中有 95% 真的是类别 0。
• Recall(召回率):
- 表示真实属于某个类别的样本中,有多少比例被正确预测。
- 例如,对于类别 0:召回率为 0.9500,说明真实类别 0 的样本中有 95% 被模型正确识别。
• F1-score:
- 是精确率和召回率的调和平均值,综合考虑两者的平衡。
- 类别 0 的 F1-score 为 0.9500,说明精确率和召回率都很高。
• Support:
- 表示该类别在验证集中的样本数量。
- 如类别 0 的支持数为 100,类别 1 为 101 等。
• Overall Accuracy(总体准确率):
- 整体准确率为 0.9150,表示验证集 400 个样本中有 91.5% 被正确分类。
• Macro avg 和 Weighted avg:
- Macro avg 是对各类别指标(精确率、召回率、F1-score)的简单平均,不考虑每个类别的样本数量。
- Weighted avg 则考虑了各类别的样本数,即各类别的指标按支持数加权平均。
这里二者数值都在 0.91 左右,说明各类别整体表现较为均衡。
三、总结
• 混淆矩阵:直观展示了每个真实类别与预测类别的分布情况,帮助发现哪些类别容易混淆。例如,你可以看到类别 2 有部分样本被误判为类别 1 和类别 3。
• 分类报告:提供了各类别的精确率、召回率、F1-score,以及总体准确率,这些指标帮助我们量化模型的分类性能。如果精确率高,说明误报较少;召回率高,说明漏报较少;F1-score 综合考虑二者。
结合这两部分内容,可以对模型在各个类别上的表现进行全面评估,从而决定是否需要进一步改进模型(例如通过增加数据、改进网络结构、调整超参数等)。
7. 改进思路
-
1. 使用 Adam 替代 SGD:
- Adam 已经在示例中演示,可以帮助模型更快收敛。
-
2. 学习率调整:
- 可从 1e-3 改为 1e-4 或 5e-4 等,观察效果。
-
3. 数据标准化:
- 在 create_dataset(standardize=True) 中已演示,可以让训练更平稳。
-
4. 增加网络深度或宽度:
- 在网络中多加几层,如 self.linear4 = nn.Linear(512, 1024) 等,并使用合适的激活函数与正则化。
-
5. 延长训练轮数:
- 从 50 提升到 100、200,观察是否出现过拟合。
-
6. 添加正则化或 Dropout:
- 在第二层或更多层后加 Dropout,或在优化器里加 weight_decay 来抑制过拟合。
8. 问题解答
1. 混淆矩阵,可不可以给我一个口诀或者快速的判断方案?
可以用一个简单的口诀来快速判断混淆矩阵的好坏,比如:
“对角线亮,非对角暗”
具体解释如下:
- • 对角线亮:意思是混淆矩阵的对角线上数值(正确分类数)越高越好,说明模型大部分样本都被正确预测。
- • 非对角暗:意思是除对角线外的其他位置(错误分类数)应该尽可能低,说明错误率低,误判较少。
另外,你可以记住下面的判断步骤:
- 1. 观察对角线总和:如果对角线数值占总数的比例很高,说明整体准确率好。
- 2. 关注特定类别:对于某一行(真实类别),如果非对角线数值较大,则说明该类别的漏报(召回率低);对于某一列(预测类别),如果非对角线数值较大,则说明该类别的误报(精确率低)。
- 3. 综合评估:可以结合精确率、召回率和F1-score来全面评价模型性能。
这个口诀和步骤能帮助你快速从混淆矩阵中获得直观的信息,判断模型在哪些类别上表现良好,哪些类别还需要改进。
2. 为什么训练的时候 loss = criterion(output, y), 预测的时候 y_pred = torch.argmax(output, dim=1),同样是 output = model(x) ,为什么output 应用不一样 请问这两个的区别是什么,为什么会有这样的区别呢?
在训练过程中,我们直接将模型的原始输出(通常称为 logits)传入损失函数(例如 CrossEntropyLoss),而损失函数内部会自动进行 softmax 和对数变换,再计算损失;这样做可以保持梯度信息并实现反向传播。如果在训练过程中提前对 logits 进行 argmax(选取最大概率),就会丢失连续的概率信息,导致无法进行有效的梯度更新。
而在预测或评估阶段,我们不再需要反向传播,这时需要给出具体的分类结果,因此会使用 torch.argmax 来从 logits 中选取具有最大概率的类别作为最终的预测结果。
我们主要讲解下训练过程:
我们以一个具体例子来说明这一过程。假设模型输出的 logits 为一个长度为 4 的向量:

1. 计算 softmax 概率
交叉熵损失(CrossEntropyLoss)内部会先对 logits 进行 softmax 计算,得到各类别的预测概率。softmax 函数的计算公式为:

2. 选择真实类别对应的概率

3. 计算负对数似然损失

4. 反向传播计算梯度

小结

8. 总结
在本案例中,我们完成了一个 多分类 任务的 完整流程:
- 1. 数据读取与预处理(包括可选标准化、查看前 5 条数据);
- 2. 构建三层全连接网络;
- 3. 使用 Adam 优化器训练;
- 4. 验证集上评估准确率;
- 5. 混淆矩阵与分类报告 做更全面的分析。
在此基础上,不断尝试超参数调优、网络结构调整,就可以在相同的数据集上获得更好的性能。大道至简,只要理解了上述流程,面对其他多分类任务时,也能举一反三、灵活应用。
以上就是本文全部内容,希望对你有所帮助!如果你觉得文章不错,不妨一键三连(点赞、收藏、关注)支持一下。祝你在深度学习的世界里越走越远,成为下一个“炼丹大师”!


















 1438
1438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









