







微软一代LayoutLM
用途:表单理解、票据理解、文档图像分类,也就是进行实体识别及分类。这篇文章及实现在最新的微软网站和git上都被删了。和layoutlmv2的区别见本文“LayoutLM 2.0 主要有四点主要升级”。
paper:
https://github.com/microsoft/unilm/tree/master/layoutlm
code:
https://github.com/microsoft/unilm/tree/master/layoutlm
注意unilm代码库包含了微软对通用文档理解的多个工作,包含layoutlm(已不在代码库中)、layoutlmv2、layoutxml、layoutlmv2
结构信息:利用上下左右排列关系
视觉信息:利用加粗、倾斜、字体、字号等信息
文本信息:ocr输出
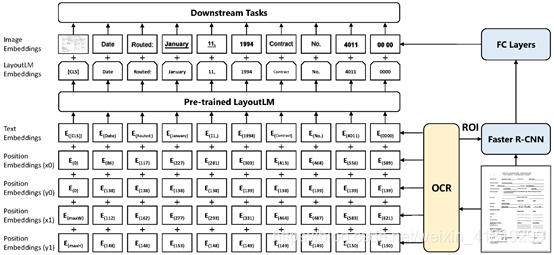
Layoutlm全流程:
文档图像通过ocr获取识别文本text及定位框信息bbox。基于text获取text embedding。基于bbox的左上点(x0,y0)和右下点(x1,y1),将两个坐标归一化为虚拟点,并获取x、y、w、h的position embedding,转为最终的2d position embedding;bbox作为Faster R-CNN的候选框(即ROI),获取每个文本切片的图像特征。
将text和position的embedding信息作为layoutlm预训练模型的输入,输出和image的embedding相加后作为下游任务的输入。 Image Embedding 的融合在预训练模型之后
Text embedding中Cls是整个输入文本的语义,相应的,需要整个的bbox(0,0,maxW,maxH)及整张图的image embedding。可以看到,layoutlm结合了整体和局部的信息。
2种预训练任务:
预训练阶段使用的数据集为 IIT-CDIP 数据集,数据量大小为11,000,000(1100万,千万级别)
MVLM遮罩式视觉语言模型(Masked Visual-Language Model)
mask 部分text信息,但保留其2d position embedding,使模型根据上下文、位置信息及视觉信息,推断被遮挡的词汇。让模型更好地学习文本位置和文本语义的模态对齐关系。
MDC 多标签文档分类(Multi-label Document Classification )
聚合文档类别,获得更高层的语义表示能力。
基网络:用了4种初始化网络,最有效的是RoBERTaLARGE

微软二代LayoutLM2
用途:实体识别、图像分类、视觉问答。
表单理解。任务要求模型从表单中抽取四种类型的语义实体,包括问题、答案、标题、其他。
票据理解。从中抽取名称、价格、数量等30类关键信息实体。抽取店铺名、店铺地址、总价、消费时间四个语义实体。
复杂布局长文档理解。四类关键信息实体进行抽取。
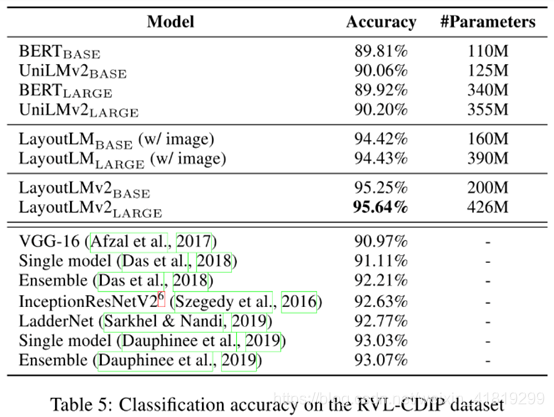
文档图像分类。共16类文档。通常图像分类的准确率排序:文本分类<图像分类<图像+文本分类。如下图所示准确率:bert<VGG<LayoutLM
视觉问答DocVQA。超过一万页文档上的五万组问答对
Paper:https://arxiv.org/abs/2012.14740
简介:新一代多模态文档理解预训练模型LayoutLM 2.0,多项任务取得新突破!
文本向量:包含词向量、一维位置向量、分段向量
图像向量:包含特征向量、一维位置向量、分段向量。无文字区域也可能包含重要视觉信息,因此不使用layoutlm1整体和局部文本区域,而是将图像网格状均分。使用ResNeXt-FPN 网络作为图像编码器,要先抽取原始文档图像的特征图,再将其平均池化为固定尺寸(W×H),接着按行展开平均池化后的特征图,之后经过线性层映射到固定维度,就可以得到图像对应的特征序列。因为基于CNN的视觉模型无法学习顺序信息,LayoutLM额外加上了和BERT一样的Postion Embedding。
布局向量:用左上、右下坐标及wh共6个特征来表示。通过向量嵌入技术,将坐标归一化到[0, 1000]并取整(考虑到原图大小差异性,转化为虚拟坐标),再映射到对应的向量,最后将横纵坐标对应的向量concat。
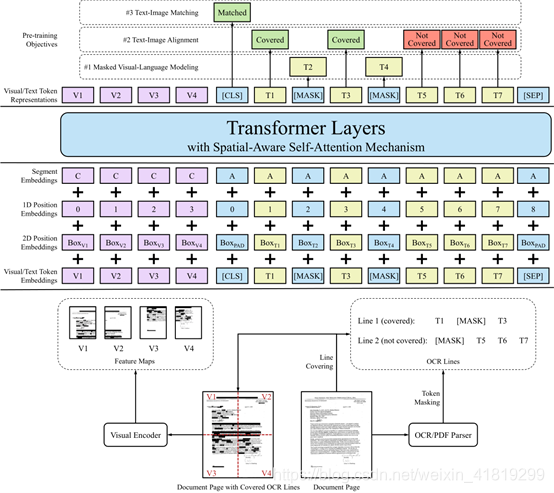
Layoutlm2.0全流程:
对图像进行ocr识别或pdf解析,获取text及bbox信息。对text中的部分【mask】一下,对image的部分【mask】一下。
图像信息:ResNeXt-FPN提取image的图像特征,这里是获得了一个尺寸为4的特征(v1、v2、v3、v4),结合一维相对位置信息1d position embedding(图中的0、1、2、3)、二维box信息2d Position Embedding(每块图像的坐标)、分段向量 segement Embedding(图像的分段向量是C)
文本+布局信息:将句子前后加上头【cls】、尾【sep】标记,中间包含【mask】标记。结合一维相对位置信息1d position embedding(图中的0、1、2、3…,即每个词的索引)、二维box信息2d Position Embedding(每个字的坐标)、分段向量 segement Embedding(文本的分段向量是A)
将图像与文本序列拼接,对应位置加上布局向量。
通过空间感知自注意力的Transformer后,得到更高层的图像及文本表示。并基于三个预训练任务训练模型,其中,任务一即任务二为2种新的预训练任务:
预训练任务一:掩码视觉语言模型(Masked Visual-Language Model)
根据上下文、图像、box信息,推断被遮挡【mask】的内容
预训练任务二:文本—图像对齐(Text-Image Alignment)
在文档图像上随机按行遮盖一部分文本,利用模型的文本部分输出进行词级别二分类,预测每个词是否被覆盖。
预训练任务三:文本—图像匹配(Text-Image Match)
随机地替换或舍弃一部分文档图像,构造图文失配的负样本。以文档级二分类的方式预测图文是否匹配。
空间感知自注意力机制 (spatial-aware self-attention)
使Transformer 模型学习到文档图像中不同文本块之间的相对位置关系,aij为原始自注意力得分,b为相对位置偏差项bias,bias表示位置之间的相对距离。
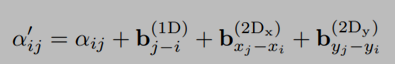
LayoutLM 2.0 主要有四点主要升级:在输入中融合图像信息(#1到#2a)、添加新的多模态对齐预训练任务(#2a到#2d)、在多模态编码器中引入空间感知自注意力机制(#2d到#3)、使用更好的初始化模型(#3到#4)。
在多项任务中,初始化模型的参数量越大,准确率越高。
LayoutLMv2在预训练中首先将模型初始化为UniLMv2的权重,由于UniLMv2是单纯的文本预训练模型,LayoutLMv2接着在IIT-CDIP的大量文档图片上预训练布局特征和视觉特征。

微软二点一代LayoutXLM
简介:微软亚洲研究院提出多语言通用文档理解预训练模型LayoutXLM
LayoutLMv2 模型的多语言扩展版,使用了53种语言的文档。通过 PDF 解析器 PyMuPDF 对pdf文件直接解析,构建了一个三千万大小的数据集XFUN。模型结构本身没有什么突破。
子任务包含实体识别及关系抽取,针对关系抽取 (Relation Extraction, RE)子任务,采取的描述方式是:给定文档 D,语义实体类别集合 C,给定关系集合 R={r_0, r_1, …, r_m},关系抽取任务要求模型预测任意两个语义实体之间的关系,即需要找到函数 Fre:(D, E, R, E) -> L,其中 L 是预测的语义关系集。
词表与v2不同,迁移到自己的任务中需要add_special_tokens,建议v2和xlm的模型都试一下,评估迭代后哪个预训练模型的准确率高。
论文链接:https://arxiv.org/abs/2104.08836
代码/模型:https://aka.ms/layoutxlm
数据集:https://github.com/doc-analysis/XFUN
---
微软三代LayoutLMV3
简介:
文档智能多模态预训练模型LayoutLMv3:兼具通用性与优越性
从论文题目可以看出最大的贡献在于统一了预训练中图像及文档的mask任务。以往的方法在图像及文本上使用的预训练方法不同,如文本有mlm而图像没有掩码预训练任务,v3采用的预训练方法及架构可以统一文本图像掩码。
预训练任务:
MLM:同时mask文本及图像信息,预测mask掉的token
MIM:预测mask前的图像
WPA(Word-Patch Alignment):判断文本词对应图像块是否被掩码,图像文本均未mask为aligned,图像被mask文本未被mask为unaligned,文本被mask的不参与loss计算
输入信息:
文本:
RoBERTa (A Robustly Optimized BERT Pretraining Approach, 一个强力优化的bert预训练方法)
未改变bert的结构,但是在预训练任务、batchsize、数据集、动态mask替代静态mask等方面进行了优化
https://blog.csdn.net/Decennie/article/details/120010025
布局:
采用segment level layout emebdding,即共享ocr检测框,不预估token级别的box了。在代码中体现如下,"total_data['bboxes'][i][j]"表示第i张图片的第j个切片的坐标,这个切片可能是多个字的,通过乘操作复制多份,实现共享。
# xfund.py
cur_doc_bboxs += [total_data['bboxes'][i][j] * len(cur_input_ids)]
# funsd.py
cur_line_bboxes=self.get_line_bbox(cur_line_bboxes)图像 :
DIT代替cnn,DIT(采用了Vit的模型结构、Beit的预训练方法MIM、数据集为文档图像)
原图Resize为224x224-split为16x16-dVAE(Denoising VAE降噪变分自编码器)进行图片分词,得到在码本中的序号,恢复被mask的序号。
在代码实现上,还是用nn.Conv2d实现的
# 输入尺寸 x.shape = torch.size([1,3,224,224])
self.proj = nn.Conv2d(2,768,kernel_size = 16,stride=16)\
x=self.proj(x)
# 输出尺寸 x.shape = torch.size([1,768,14,14])参数量极小
zhuanlan.zhihu.com/p/517895058
词表
v3和v2一样使用了json格式的tokenizer.json,offset map会重复,比如[...,(6,7),(6,7),...],
还会有_或以此符号作为开头的token,可能代表开始。在token.json 中的解释是
“pre_tokenizer”:{"type":"Metaspace","replacement":'_',"add_prefix_space":true}
在v3中,需要注意以下重要公式
224/16 = 14 即图像模态经过vit后有14*14个patch
512+14*14+1 = 709
单个batch的输出长度非512而是709,在ner任务还原到原文的时候需要额外注意这一点。
Layoutlmv3 | Question · Issue #812 · microsoft/unilm · GitHub
"197 = 14 x 14 + 1, where 14 x 14 is the number of image patches, and 1 represents a special token. Figure 3 in the LayoutLMv3 paper gives an overview of the embedding.
You can separate image and text by splitting the output embedding (e.g., [-196:, :] represents image embedding)."
1在代码中是cls_token,并和图像的信息进行拼接
# cls_token 用来作为图像信息的开头?
# x 为处理为shape =[bath,768,14,14]的图像信息
x=torch.cat((cls_token,x),dim=1)在写推理函数时,需要用到DataCollatorFOrKeyValueExtraction这个类,将以下类型的数据作为这个类的输入,类的输出作为model的输入。
[{
'input_ids':xxx,
'attention_mask':xxx, #[1,1,1,1,...]
'labels':xxx,
'bbox':xxx,
'segment_ids':xxx,
'position_ids':xxx,
'images':torch.tensor(patch_transform(for_patches)),
},
{...} # 多张图片
]评估
评估函数调用了datasets.load_metric,返回包括accuracy(每个位置的平均分类准确率)、precision(每个实体的准确率)、recall(每个实体的召回率)、f1、每个实体的precision\recall\f1\number。layoutlm的accuracy能到98%,实体级别准召约94、95%。
优化
可以从超510文本截断、基于ngram思想在切片内部纠正BIO分类等方向进行预处理后处理优化
扩展阅读:
CV中的特征融合SFAM、ASFF、BiFPN、Hyper column
CV中的特征融合SFAM、ASFF、BiFPN、Hyper column_yx868xy的博客-CSDN博客_特征融合模块
信息抽取——关系抽取
多模态预训练模型介绍

















 1550
1550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









