







 超级会员免费看
超级会员免费看
EA2N: EVIDENCE-BASED AMR ATTENTION NETWORK FOR FAKE NEWS ETECTION
Ea2n:基于证据的抽象语义表示注意力网络假新闻检测
摘要:该研究包括来自维基数据的外部知识,并偏离了许多最先进(SOTA)事实核查模型采用的对社会信息的依赖来检测假新闻。该文提出了一种基于证据的AMR注意力网络EA2N用于假新闻检测。EA2N利用抽象语义表示(AMR),并使用提出的证据链接算法从维基数据中融合知识,突破了假新闻检测的边界。所提出的框架包含了新颖语言编码器和图编码器的组合来检测假新闻。语言编码器有效地结合了transformer编码的文本特征和情感词汇特征,而图编码器通过外部知识将AMR编码为证据,称为WikiAMR图。设计了一个路径感知的图学习模块,用于通过证据捕获实体之间的关键语义关系。广泛的实验支持了该模型的卓越性能,超过了SOTA方法。该研究不仅推进了假新闻检测领域的发展,还展示了AMR和外部知识在鲁棒的NLP应用中的潜力,有望提供更可信的信息图景。
1 介绍
利用外部知识进行事实核查进行假新闻检测是假新闻检测的方法之一。当前,基于知识的方法主要有KAN、FinerFact、Dual-CAN等,KAN模型利用了来自维基数据(Wikidata)的外部证据,FinerFact (Jin等人,2022)和Dual-CAN (Yang等人,2023)则采用了支持新闻文章真实性的社会信息。但这些在捕捉某些细节方面存在局限性。准确地说,这些模型很难维持较长的文本依赖关系,并且在捕捉复杂的语义关系(如事件、位置、触发词等)方面效率较低。此外,将外部知识整合到这些模型中的方法可靠性不高且耗时。例如,KAN只考虑单个实体的上下文,无法将两个实体之间的上下文联系起来。另一方面,FinerFact gather支持来自社交平台的声明,这是耗时的。虽然社交真实性产生了良好的效果,但这些信息可能会被社交媒体用户为了个人利益而操纵。为了应对这些挑战,本研究在一种新的图表示的帮助下,有效地利用了新闻文章和维基数据中发现的证据的复杂语义关系。
本文提出一种新的假新闻检测模型,利用语义丰富的知识库将新闻文章分类为真或假。该模型引入了抽象语义表示(AMR)来理解句子的逻辑结构。进一步,该模型通过一种新的证据链接算法建立AMR图中发现的实体之间的关系。该算法利用Wikidata来连接证据,从而形成一个称为WikiAMR的图。据我们所知,这是第一个用于假新闻检测的基于证据的AMR图语义特征的研究。
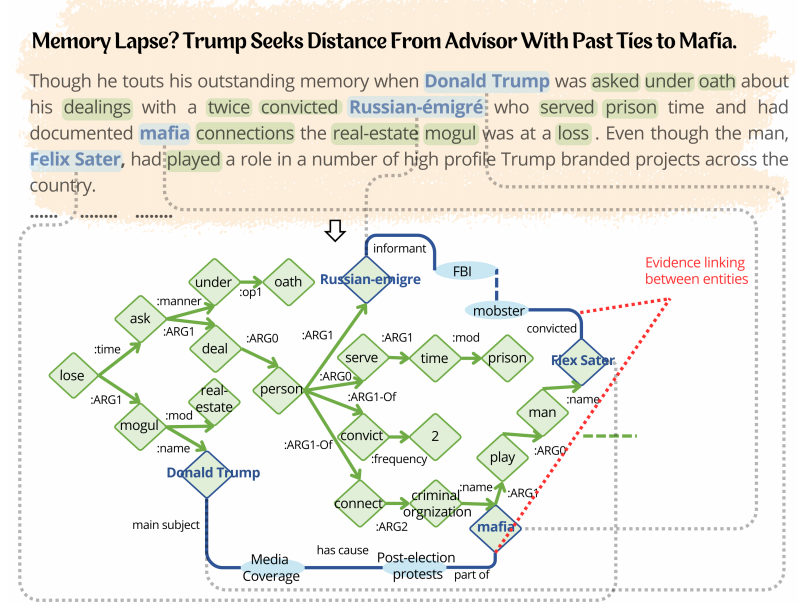
为了说明这一点,图1展示了一个使用Wikidata在新闻文章上构建的WikiAMR示例。在这一点上,实体“Donald Trump”和“Mafia”之间建立了联系,其中节点“媒体报道”和“Post - election抗议”通过“主体”、“有原因”和“路径的一部分”等关系连接起来。同样,在“俄罗斯移民”和“FlexSter”之间出现了一条连接的证据路径。这些实例为评估新闻内容的可信度提供了有价值的证据。
接下来,为了编码WikiAMR图,我们使用了一个路径感知(path-aware)的图学习模块。该模块使用关系增强的全局注意力,专注于实体之间的重要关系,并考虑实体及其关系计算注意力得分。通过修改实体的图转换器(Graph Transformer,Cai & Lam, 2020),所提出模型可以有效地对WikiAMR图中的关系路径进行推理。为了增强语言编码器的能力,我们还使用从新闻文章的不同片段中提取的情感特征(Ghanem et al., 2021),并与语言嵌入连接。最后,将语言表示和AMR图输入到使用transformer的分类层,以预测新闻的准确性。本研究的主要贡献如下:
- 引入EA2N,一种新的基于证据的AMR注意力网络,用于假新闻检测,对通过外部知识链接的证据进行推理。
- 提出WikiAMR图,一种从外部知识图谱中提取的AMR实体之间的无向证据路径的新型图结构。
- 证据链接算法,生成WikiAMR,从实体级和上下文级过滤,以提高模型性能。
- 针对最新技术对EA2N进行综合评估,展示了其优越的性能和有效性。
2 相关工作
该部分,将假新闻检测研究分为三个部分:基于文本的方法、知识感知的方法和基于AMR的方法。
2.1 基于文本的方法
基于文本的方法主要依靠从文章中提取的文本内容来验证新闻的真实性。在早期,重点主要是开发一个基于语言特征的手工创建特征的补充集合(Feng等人,2012;Ma等人,2016;Long等人,2017;Rashkin等人,2017;刘和吴,2018)。这些早期研究需要大量的工作来评估这些手工设计的特征的功效。最近,Ghanem等人(2021)提出了FakeFlow,涉及利用具有词汇特征的文本将新闻分类为假新闻。在许多工作中促进了假新闻的早期检测(Wei等人,2021;Azevedo et al., 2021),然而,它们的有效性是有限的,因为它们忽略了有助于新闻验证的辅助知识。
2.2 基于知识感知的方法
知识感知方法利用辅助知识来辅助新闻的验证过程。Monti等人(2019)扩展了经典的CNN,通过分析用户活动、内容、社交图等对图进行操作,而Shu等人(2020b)发现用户画像特征在假新闻检测中很有用。Lu和Li(2020)采用了同时使用新闻内容和社会语境的共同注意力模型。后来,Wang et al.(2020)和Hu et al.(2021)利用实体链接从Wikidata中捕获实体描述,并将其集成到他们的模型中以识别假新闻。最近,KAN (Dun et al., 2021)考虑了来自Wikidata的外部知识来扩展领域知识,Jin等人(2022)提出了Finerfact,一种利用社会信息来检测假新闻的细粒度推理框架。最近提出的双能(Yang et al., 2023)方法以新闻内容以及社交媒体回复和外部知识为目的。由此证明,更好的假新闻检测需要外部知识的获取。
2.3 基于AMR的方法
Banarescu等人(2013)提出的AMR使用PropBank、框架集和句子词汇来表示节点之间的关系。它利用了上百种语义关系,包括否定、连接、命令和维基化。它旨在用相同的AMR图表示具有相同语义的不同句子。各种NLP领域,如摘要、事件检测、问答等,都有效地使用了AMR。尽管AMR在NLP中有广泛的应用,但还没有研究用于捕获文档中的复杂语义关系以用于假新闻检测。最近,Zhang等人使用AMR来识别脱离上下文的多模态假信息。在认识到语义关系的重要性后,我们开始探索利用AMR来检测假新闻。
3 方法
3.1 问题定义
我们的目标是对新闻文章进行二分类,将它们分类为真(y = 0)或假(y = 1)。形式上,给定一篇新闻文章S,任务是学习一个函数F,使F: F(S)→y,其中y∈{0,1}表示新闻文章的真实标签。
3.2 语言编码器
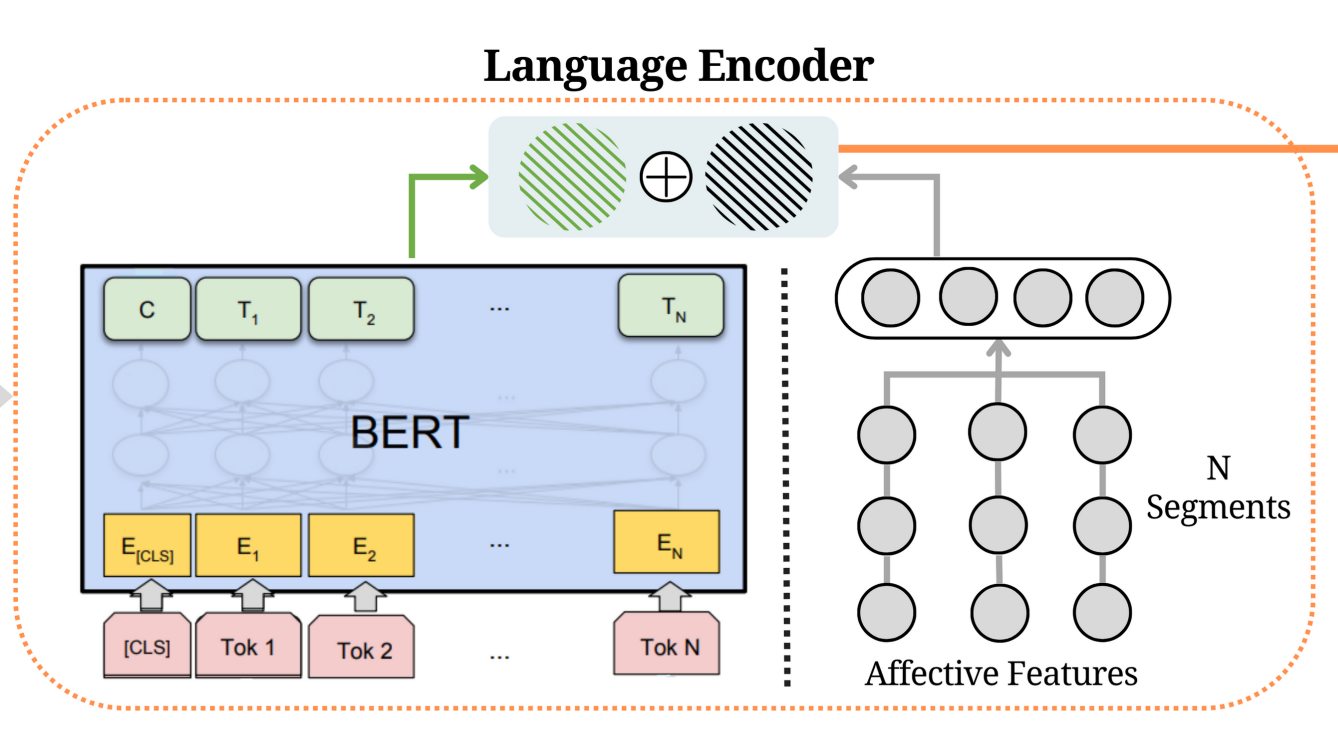
在语言编码器中使用BERT模型对句子中的token序列进行编码。
设一篇新闻文章S表示为元组(T, B),其中T表示新闻文章的标题,B表示新闻文章的正文,都包含一组单词{w1, w2,…, wn}。为了创建最终的输入文本,我们使用特殊的“[SEP]”标签连接标题和正文。之后,我们首先将这些单词标记化,并以以下方式输入BERT模型以获得最终的嵌入层Hi:
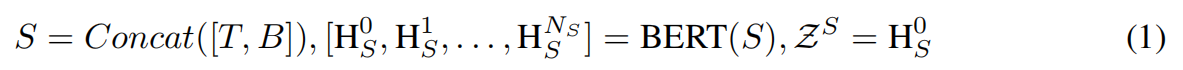
我们从文章S中n个不同的段{s1, s2,…, sn}提取情感词汇特征,如情感、情感、道德、夸大,以增强语言编码器的能力。通过明智地捕捉特征段的分布,增强了更有效地区分文档的能力。第j段sj∈S的每个特征向量asj用词频表示,词频中考虑了文章长度作为权重因子。这种方法允许我们有效地捕获和表示文章中每个片段的独特特征,考虑到片段长度的变化。将BERT得到的嵌入向量与融合情感特征形成的表示向量拼接,得到最终的语言向量
:
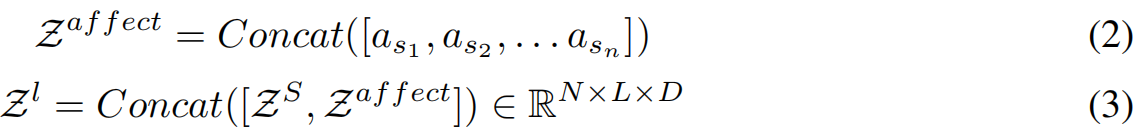
这里N是批量大小,L是最大序列长度,D是语言特征向量的维度。
3.3 图编码器
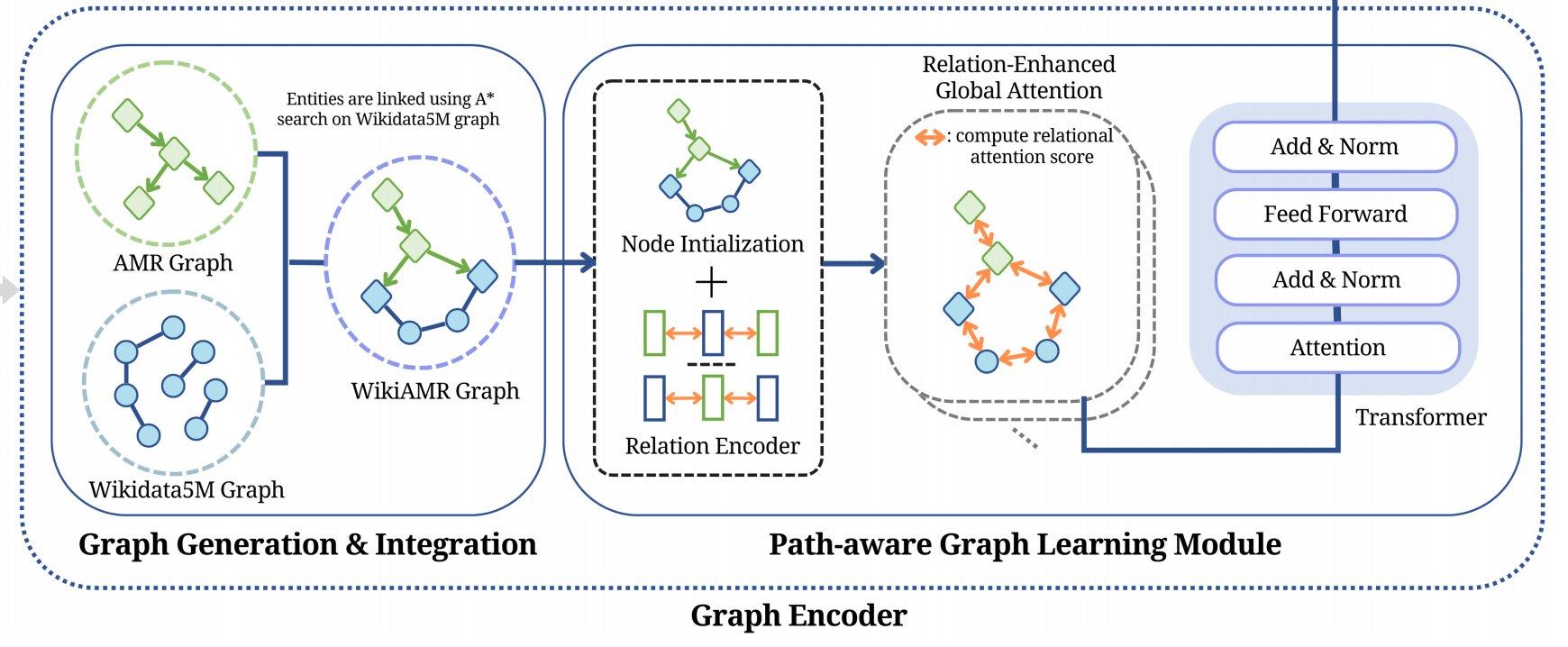
图编码器模块在将语言表示转换为结构化和抽象形式方面起着至关重要的作用。我们采用抽象语义表示(AMR) 将新闻文章的含义编码在图结构中。
图编码器由三个关键组件组成,每个组件负责过程中的特定任务,从AMR的生成到外部知识的整合,最后是路径感知的图学习模块。在描述以下小节中每个组件的简明概述之前,让我们在这里定义图的符号。图G通常用元组(V, E)表示,其中V是节点实体的集合,E表示关系边。对于我们在文章中使用的不同图形,我们对G= (V, E)使用了不同的符号,没有详细说明。
3.3.1 AMR的生成
AMR生成过程将新闻文章转换为节点和边的网络,捕捉不同实体之间的关系。AMR生成过程需要对新闻文章进行语义分析,以提取包括语义角色、关系和核心事件在内的语言信息。对于新闻文章S,我们将AMR图表示为
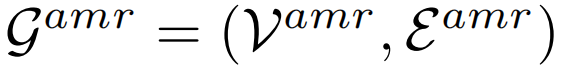
。
举个例子,看看这句话:“唐纳德·特朗普试图与过去与黑手党有联系的顾问保持距离。”下图是对应的AMR图。AMR图是一种表示层次结构的有向无环图,其中节点表示实体(Donald T rumph, maf ia, seek等)。边(arg0, arg1, name等)捕捉了这些实体之间的关系,形成了S的语义结构化表示。

3.3.2 与AMR的证据整合
为了从外部知识图谱中提取AMR中实体间的证据丰富路径,提出了一种证据链接算法。
给定Wikidata知识图谱G wiki = (V wiki, E wiki),该算法通过实体级过滤(ELF)和上下文级过滤(CLF)将G wiki与AMR进行集成。ELF使用Relatedness(·)函数评估实体之间的相关性。当相关性超过ELF阈值(γ)时,启动CLF过程链接实体间的证据。
实体级过滤(ELF):在ELF期间,检查AMR图中的实体对在维基数据中的对应表示和相关性。source(s)和destination(d)实体之间的相关度计算如下:
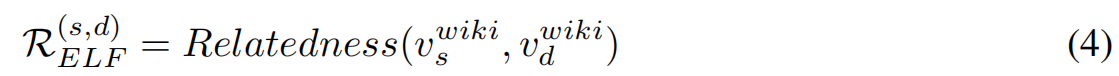
其中vs wiki和vd wiki是维基数据中(vs amr和vd amr)的实体表示。当R (s,d) ELF超过γ时,实体vs amr和vd amr在Wikidata中是相关的。这意味着它们之间存在着潜在的证据路径。
上下文级过滤(CLF): CLF算法确定vs amr和vd amr之间的相关性。该算法遵循一种搜索算法的原则,在知识图谱中搜索从起始实体vs amr到目标实体vd amr的路径。
对于vs amr和vd amr之间的证据路径中的每个vi wiki∈Vwiki的实体,计算vi wiki和vd amr之间的相关度,以预测在源和目的之间找到丰富证据路径的可能性:
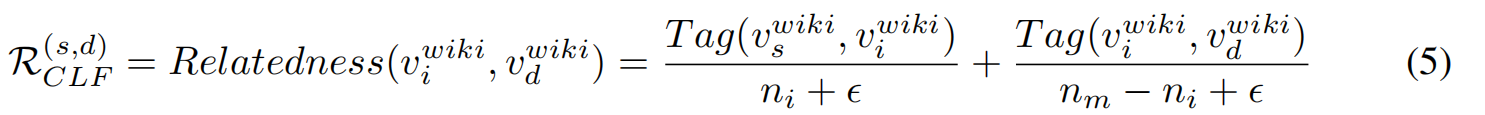
其中Tag(i, j)是从i到j的tagme分数之和,ni和nm分别表示当前的希望和最大跳数,是一个非常小的值,是为了避免被零除。第一项是指从源节点(vs wiki)到当前节点(vi wiki)的Tagme得分的平均值,第二项是指从当前节点(vi wiki)到目标节点(vd wiki)的Tagme得分的启发式值的平均值。如果R (s,d) CLF高于CLF阈值(δ),则实体vi wiki与Wikidata路径中的下一个实体链接,直到到达vd amr。该过程导致实体间证据信息的附着,丰富了AMR图的外部知识。对G amr中的每一对实体重复这个过程,得到的图称为WikiAMR图。在算法1中给出了利用ELF和CLF生成WikiAMR的详细算法。

WikiAMR简称为

,由G amr中实体之间相互连接的无向证据路径组成。这种结构促进了对外部知识中存在的证据的推理,以及从文本文档中提取的有向无环结构。数学上可以表示为:
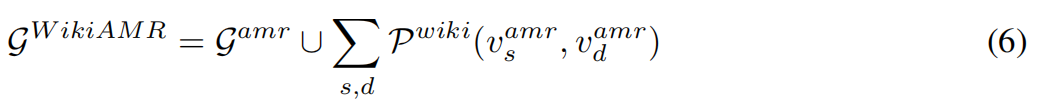
其中,P wiki是vs amr和vd amr之间的证据路径,P表示由这些证据路径生成的图。
继续上面的例子,假设我们想要链接实体Donald Trumph和Mafia,使用Relatedness(·)函数计算它们之间的相关性RELF。如果RELF > γ, Donald T rumph和M af ia实体被认为是相关的,可能在它们之间存在证据路径。识别出相关实体后,计算下一个实体vi wiki、媒体覆盖率和目标实体M af ia之间的RCLF。如果RCLF > δ,则实体vi wiki在AMR图中与实体vi wiki +1链接,直到到达目的地。这导致了附件的相关证据信息。在AMR中的所有实体对上重复上述操作,最终得到的图被表示为WikiAMR。
3.3.3 路径感知图学习模块
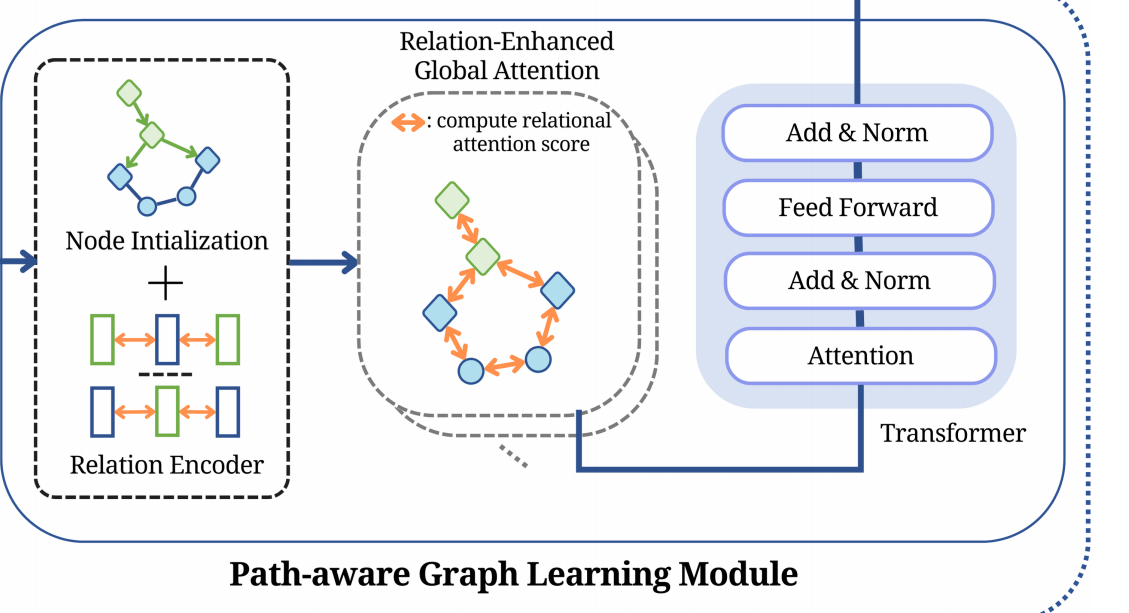
该模块通过从丰富的WikiAMR图中生成信息特征,在EA2N中起着至关重要的作用。这些特征捕捉了基本的语义关系,使模型能够更深入地理解新闻文章中存在的信息。该模块涉及一个图Transformer,它利用多头注意力机制以促进有效推理和表示学习的方式处理WikiAMR表示。
关系路径编码器
从上一节获得的WikiAMR被传递给节点初始化和关系编码器,以获得
![]()
中的WikiAMR编码,其中D'是图编码的维度。
为了便于模型识别GW ikiAMR中的显式图路径,采用关系编码器捕获两个实体之间的最短路径。使用基于门控循环单元(GRU)的循环神经网络将表示此路径的序列转换为关系向量。这种关系编码的数学表示如下:
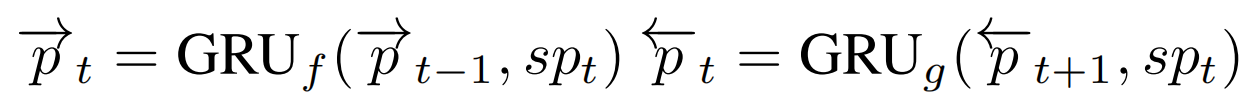
其中,spt表示两个实体之间关系的最短路径。根据Cai & Lam(2020)的论文,为了计算注意力得分,最终的关系编码rij被分为两个单独的编码:ri→j和rj→i,这两个编码是通过一个线性层和参数矩阵Wr得到的。
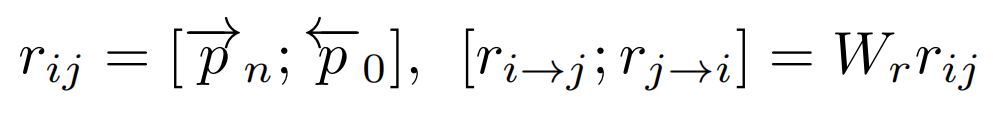
图Transformer使用多头注意力机制处理输入GW ikiAMR。然后基于实体表示及其关系表示计算注意力得分αij;
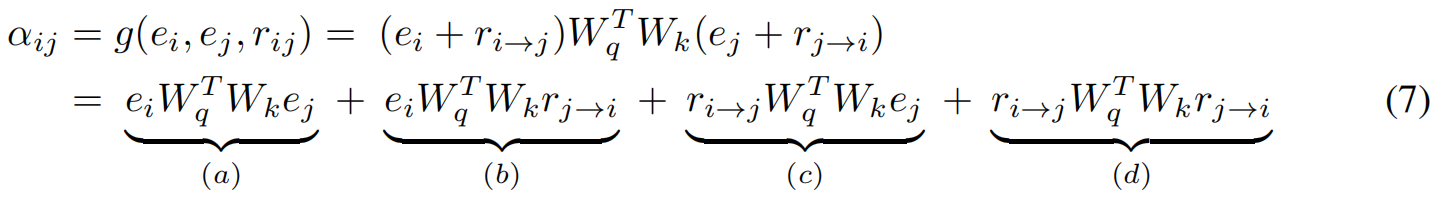
这里的注意力权重是根据关系对实体进行计算的,公式7中的每个术语都有一个解释。该术语(a)表示基于内容的寻址,(b)和(c)捕获了源依赖和目标依赖的关系偏差,(d)体现了普遍的关系偏差,包含了更广泛的关系交互视角。总的来说,该方程解释了模型推理和权衡实体-关系交互的综合机制。
图Transformer进行表示学习
图Transformer应用自注意力来捕获每个WikiAMR图表示中不同位置之间的依赖关系。编码器由多个相同的块组成,其中核心是多头注意力。该模型计算编码路径的注意力权重,以学习增强表示。给定一组注意力头H,每个头计算不同的查询(Qi)、键(Ki)和值(Vi)矩阵,然后通过可学习权重矩阵(Wi)线性组合,以产生最终的表示:
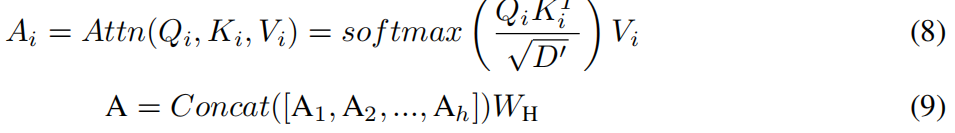
这里,h、Ai和WH表示注意力头的数量、第i个注意力头的输出和可学习的权重矩阵。这种动态方法增强了复杂语义的抽取。
计算注意力权重后,图Transformer(GT)将集成的WikiAMR表示
编码如下:
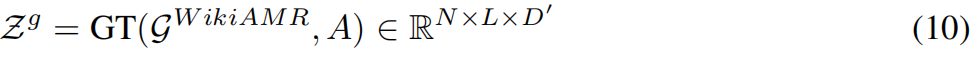
其中Z g表示从图Transformer获得的最终图嵌入,D'是特征向量的维数。
3.4 分类模块
EA2N的最后阶段涉及分类模块,该模块利用语义信息丰富的AMR表示和丰富的语言特征生成假新闻预测。我们将图
![]()
和语言特征
![]()
连接起来以创建最终的融合嵌入:、
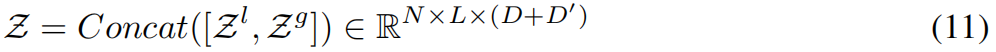
最后,我们将Z通过一个分类transformer (CT),然后是一个softmax层,以获得真实和假的最终概率Ypred。
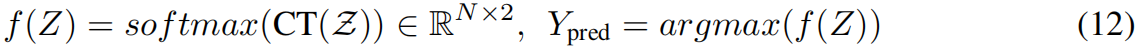
4 实验
4.1数据集和评价指标
为了评估EA2N的有效性,本文在两个基准数据集上进行了实验,即PolitiFact和gossip 。
这些数据集分别由815篇和7612篇新闻文章组成,以及记者和领域专家分配的标签。关于预处理和实现细节的其他信息可以在附录a中找到。
评价指标:准确率(Pre)、召回率(Rec)、F1-score、准确率(Acc)和ROC曲线下面积(AUC)。
使用5折交叉验证并报告平均结果。
4.2 Baseline
(一)第一组仅利用文本信息
- SVM
- DTC
- RFC
- GRU-2
- FF (FakeFlow)
(二)融合了辅助知识
- BTransE
- KCNN
- GCAN
- KAN
- FinerFact
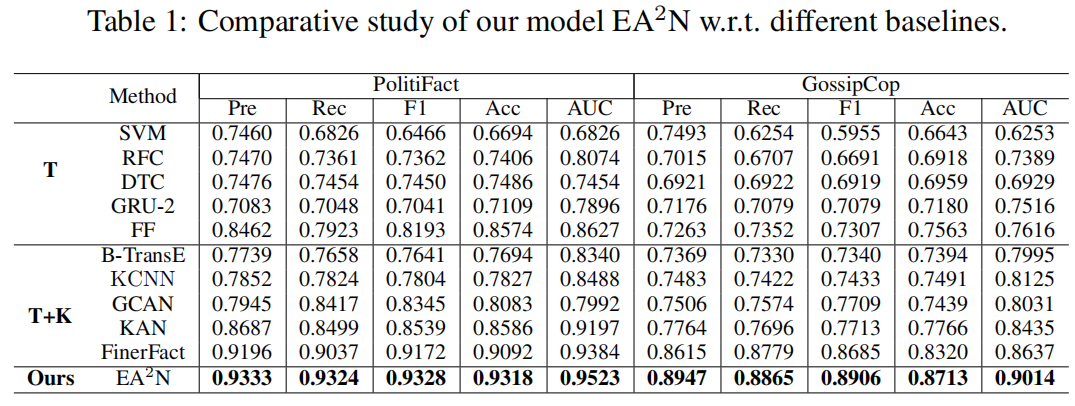
实验结果如下表:
4.3 消融实验
4.3.1 不同语言编码器的比较
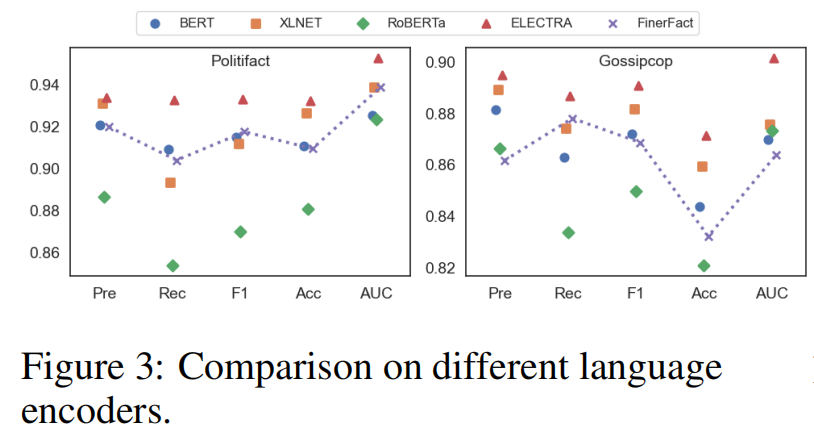
本文采用了几个基于transformer的模型来评估EA2N对各种文本编码的有效性。这些包括BERT-base ,RoBERTa-base,XLNET-base和electric -base 。此评估的结果,连同基线(FinerFact)结果,如图3所示。值得注意的是,ELECTRA优于其他模型,在Politifact数据集上的F1-score和准确率分别为0.9328和0.9318,在gossip数据集上分别为0.8906和0.8713。通过比较剩余的模型,XLNET和BERT都表现出了优于RoBERTa的性能。与基准模型相比,利用多种文本编码器,EA2N模型优于现有的其他假新闻检测模型,在性能上有显著提升。
4.3.2 不同EA2N变体的比较
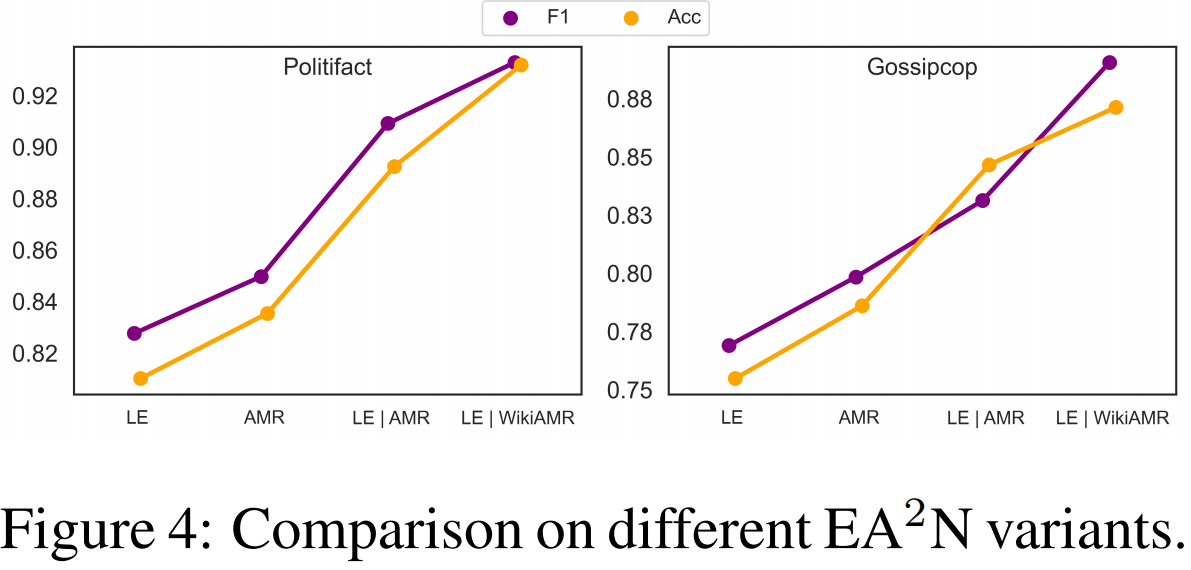
通过引入不同的变体,对EA2N (LE|WikiAMR)模型进行了实验,包括:1)语言编码器(LE) 2) AMR (AMR)和3)带有AMR的语言编码器(LE|AMR)。我们从图4中发现,只有AMR模型比只有LE模型表现更好。当结合语言编码器和AMR (LE|AMR)时,比仅有的LE和AMR模型有6-8%的显著改进。此外,当将AMR中的证据集成到最终模型(LE|WikiAMR)时,对两个数据集的性能都比LE|AMR模型进一步提高3-4%。我们进行双尾t检验,观察到EA2N变体之间存在显著性差异,得到显著性得分(p-value) < 0.01,因此拒绝零假设。对此的详细分析将在附录A.3.4中给出。


















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











