









问题引入:
我们知道sequence启动时,需要挂载至sequencer上。因为Sequence不是component组件,不会出现在UVM的树结点上,因此若想通过树结点访问sequence,需要将其挂载在组件类的sequencer上。
那么Sequence 挂载在哪个sequencer中?
Sequence默认挂载在sequence的成员变量m_sequencer上,但也可指定挂载在其它的sequencer上
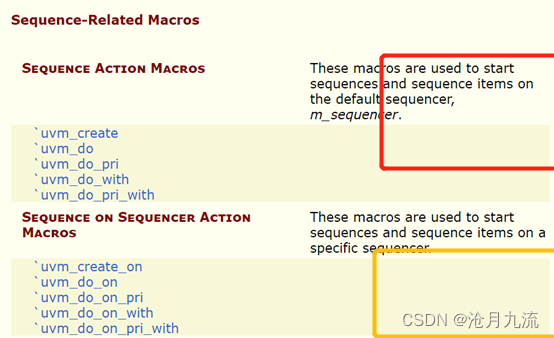
现在可以回归主题,m_sequencer与p_sequencer究竟是什么?
其实m_sequencer与p_sequencer本质上是一样的,都是指向同一个sequencer(即sequence start时挂载的那个sequencer)
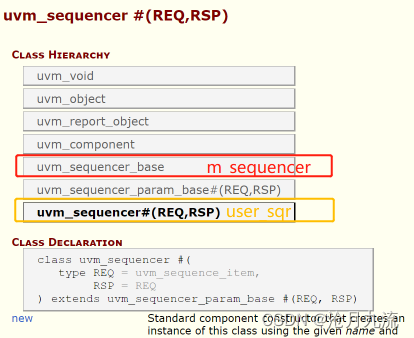
区别在于它们的类型不同,m_sequencer是sequence的成员变量,其类型为uvm_sequencer_base。而p_sequencer类型为user_sequencer(用户定义的),在sequence中通过uvm_declare_p_sequencer(user_sequencer)可以声明一个为user_sequencer类型的成员变量,之后UVM会在pre_body()阶段之前将通过$cast自动完成m_sequencer转化为p_sequencer的过程(此时p_sequencer指向m_sequencer指向的sequencer)。而m_sequencer的赋值是在sequence启动时即将sequence挂载至某sequencer上时,UVM会自动将该sequencer的句柄赋值给m_sequencer。
为什么引入m_sequencer与p_sequencer?
m_sequencer的引入使得嵌套的sequence得以更加方便地实现,这样就可以在一个sequence中启动其它的sequence,内部这些sequence都可以挂载在m_sequencer中,因为m_sequencer实质上也是最外部sequence挂载sequencer的句柄,因此无论外部sequence今后挂载在哪一个sequencer上,嵌套的sequence都能挂载在同一个sequencer上,当有多个相同类型的sequence时,使用嵌套的sequence能简化了测试代码,提高了可靠性。
p_sequencer的引入是为了解决sequence访问其挂载的sequencer变量的问题,若直接使用m_sequencer会因句柄类型问题编译报错。因为想要访问挂载的sequencer中的变量,应该与该sequencer同一类型,而m_sequencer是uvm_sequencer_base,不同于该sequencer,因此引入了类型与该sequencer一样且值与m_sequencer相同的p_sequencer!














 707
707











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









