







文章目录
参考资料
- https://zhuanlan.zhihu.com/p/102197348
- https://zhuanlan.zhihu.com/p/45418829
- 如何通俗易懂地理解基于模型的强化学习?
- Model-Based RL
- https://zhuanlan.zhihu.com/p/162787188
1. Model based vs Model free
1. Model-based
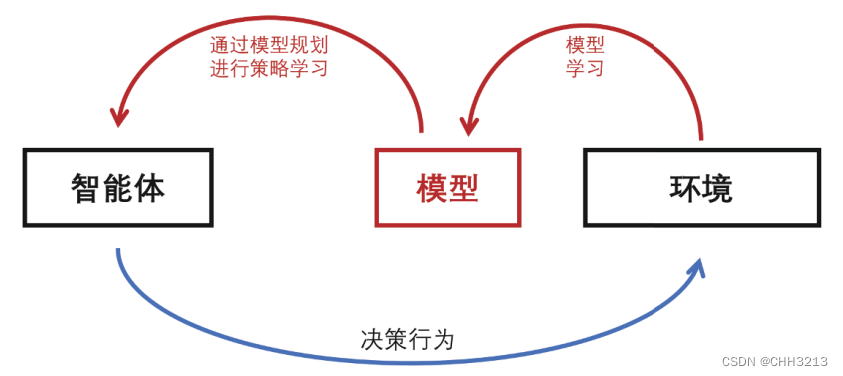
强化学习中所说的model-based并不是已知环境模型,或者已知状态转移概率。而是要从经验中学习到一个环境模型或者其他映射,并利用这个learned model 加速策略迭代的进程。
model-based 旨在高效的利用experience,提高学习效率以及实现 data-efficient。
一般来说,model-based的好处是由于其对环境的动力学特性(dynamic )进行建模,其sample efficiency更好,在样本很少的情况下学习的更好。但是一般来说其渐近表现不如model-free的算法好,即收敛之后的性能。
model-based算法有两个关键的问题,一个是建立什么样的模型,一个是怎样使用模型去做控制。
1.1 模型建立
模型的选择有:
1)nonparametric类方法,比如Bayesian nonparametric model;
2)local models,比如guided policy search,这个方法主要是反复的找更好的轨迹,并且把策略朝着该轨迹上拟合;
3)parametric models,比如使用神经网络来拟合,这种方法又分为deterministic模型和stochastic模型,deterministic计算更简单但是在样本少的时候会更容易overfit。
1.2 使用模型做控制
使用模型来做控制的方法主要有:
1)policy based method,即利用模型去探索并找到一个好的policy π : s t → a t \pi: s_t \to a_t π:st→at ,属于learning;
2)model predictive control(MPC),这种方法不去寻求一个依赖于当前状态的策略,而是每次遇到一个新的选择的时候,都基于模型去逐步预测、模拟、做选择。属于planning。
2. Model-free
Model-free就是我们常听到的 DQN, DDPG, PPO ,SAC等SOTA算法。它和model-based 的区别就在于是否利用经验做策略迭代之外的事。Model-free RL不需要去学Transition或者Reward Models。
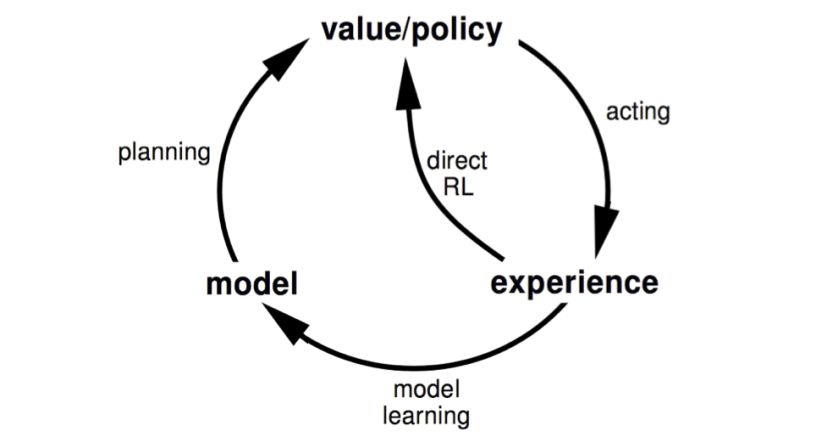
model-free在其中就是下图的 direct RL,因此 model-free 就是value/policy->acting->experience->direct RL->value/policy 的过程。
Model-free RL方法一般分成3类:
- Value-Based Method (Q-Learning,DQN等)。
- Policy-Based Method (Policy Gradient)。
- Policy and Value Based Method(Actor Critic,如典型的DDPG)。
所谓的 model-based 就是在其上增加了 model learning->model->planning 的过程。通过 experience data 学习得到一个环境的模型。
显然,所有model-free都可以转变为model-based, model-based只是一个框架,任意的model-free算法都可以嵌套进去。
3. 经验的其他用途
除了用于策略迭代外,经验还可用于:
- 拟合环境模型以及即时奖励模型 ,作为新的数据源补充算法的训练
Dyna, ME-TRPO, NAF - 拟合未来的值函数以及即时奖励,辅助决策
VPN, I2A - 拟合未来的Q值,用于增加Q值预估的质量,将其在环境模型中展开(rollout)
MVE, STEVE, MBPO
rollout定义可以参考如下:

4.Model-free vs Model-based
- 无模型的方法不需要构建环境模型。智能体直接与环境交互,并基于探索得到的样本提升其策略性能。
- 与基于模型的方法相比,无模型的方法由于不关心环境模型,无须学习环境模型,也就不存在环境拟合不准确的问题,相对更易于实现和训练。
- 然而,无模型的方法也有其自身的问题。最常见的问题是,有时在真实环境中进行探索的代价是极高的,如巨大的时间消耗、不可逆的设备损耗及安全风险,等等。比如在自动驾驶中,我们不能在没有任何防护措施的情况下,让智能体用无模型的方法在现实世界中探索,因为任何交通事故的代价都将是难以承受的。
















 1302
1302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











