








 超级会员免费看
超级会员免费看

参考:
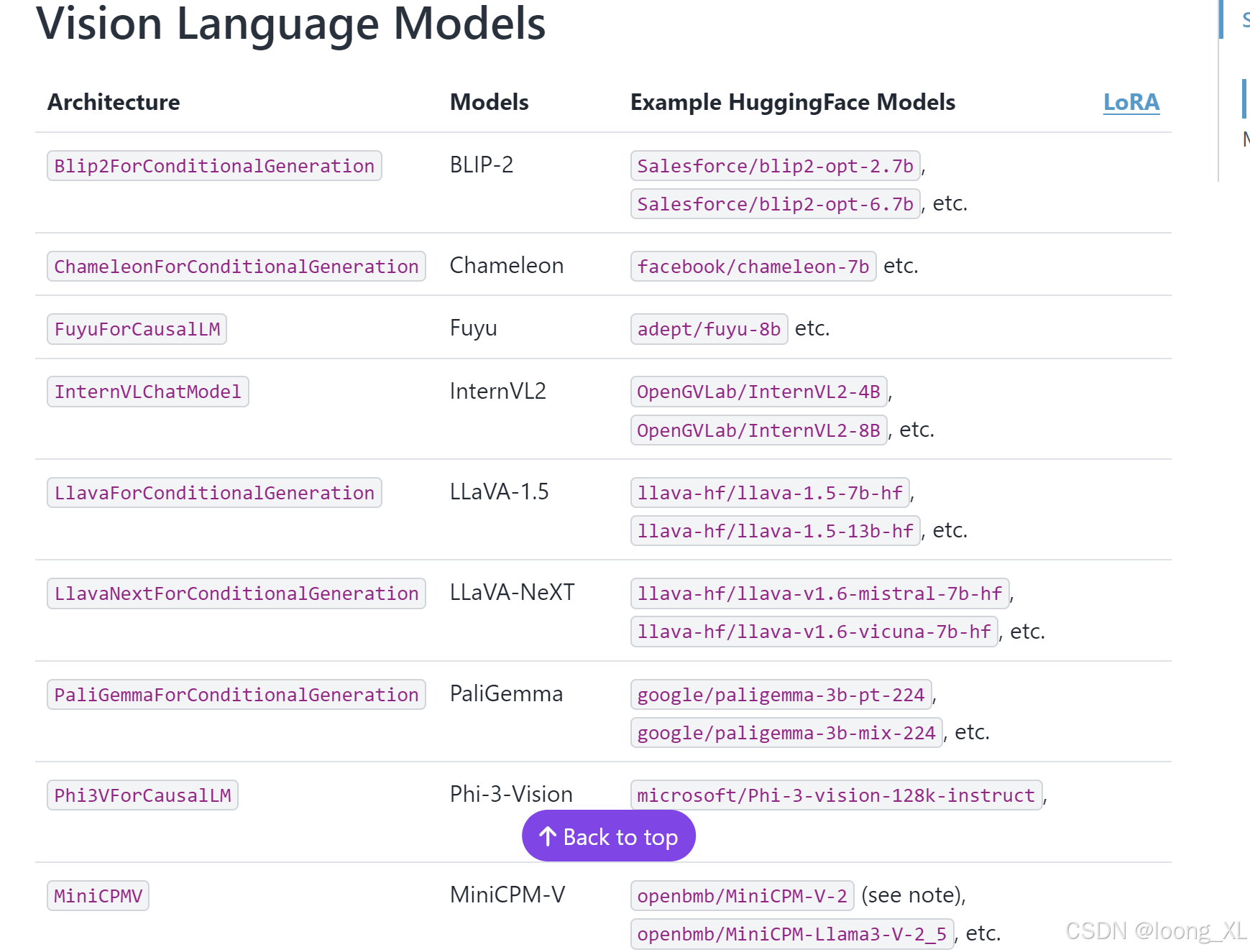
支持模型
https://docs.vllm.ai/en/latest/models/supported_models.html
模型要升级到这:
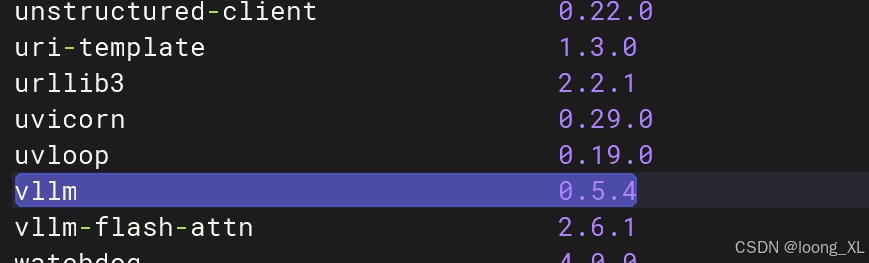
torch-2.4.0
triton-3.0.0
部署:
CUDA_VISIBLE_DEVICES=1 vllm serve /ai/InternVL2-4B --host 1** 参考:
支持模型
https://docs.vllm.ai/en/latest/models/supported_models.html
模型要升级到这:
torch-2.4.0
triton-3.0.0
部署:
CUDA_VISIBLE_DEVICES=1 vllm serve /ai/InternVL2-4B --host 1**  1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























