







1、MiDaS
参考:
https://github.com/isl-org/MiDaS
https://pytorch.org/hub/intelisl_midas_v2/
https://colab.research.google.com/github/pytorch/pytorch.github.io/blob/master/assets/hub/intelisl_midas_v2.ipynb#scrollTo=5A32CL3tocrZ

代码
import cv2
import torch
import urllib.request
import matplotlib.pyplot as plt
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
model_type = "DPT_Large" # MiDaS v3 - Large (highest accuracy, slowest inference speed)
#model_type = "DPT_Hybrid" # MiDaS v3 - Hybrid (medium accuracy, medium inference speed)
#model_type = "MiDaS_small" # MiDaS v2.1 - Small (lowest accuracy, highest inference speed)
midas = torch.hub.load("intel-isl/MiDaS", model_type)

device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
midas.to(device)
midas.eval()
midas_transforms = torch.hub.load("intel-isl/MiDaS", "transforms")
if model_type == "DPT_Large" or model_type == "DPT_Hybrid":
transform = midas_transforms.dpt_transform
else:
transform = midas_transforms.small_transform
img = cv2.imread(filename)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
input_batch = transform(img).to(device)
with torch.no_grad():
prediction = midas(input_batch)
prediction = torch.nn.functional.interpolate(
prediction.unsqueeze(1),
size=img.shape[:2],
mode="bicubic",
align_corners=False,
).squeeze()
output = prediction.cpu().numpy()
plt.imshow(output)
# plt.show()


视频
import cv2
import torch
import numpy as np
import torch.nn.functional as F
# 假设你已经有一个训练好的模型 'midas'
# midas = torch.load('path_to_your_model')
# midas.eval()
# 加载视频
video_path = '20240807_024802.mp4'
cap = cv2.VideoCapture(video_path)
# 获取视频的宽度和高度
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 获取视频的帧率
fps = cap.get(cv2.CAP_PROP_FPS)
# 创建 VideoWriter 对象
output_path = 'output_video2.mp4'
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(output_path, fourcc, fps, (frame_width, frame_height), isColor=True)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# 将帧转换为模型输入格式
img = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
input_batch = transform(img).to(device)
with torch.no_grad():
prediction = midas(input_batch)
prediction = torch.nn.functional.interpolate(
prediction.unsqueeze(1),
size=frame.shape[:2],
mode="bicubic",
align_corners=False,
).squeeze()
output = prediction.cpu().numpy()
# 可视化结果
output = (output - output.min()) / (output.max() - output.min()) # 归一化到 [0, 1]
# output = (output * 255).astype(np.uint8)
# output = cv2.cvtColor(output, cv2.COLOR_GRAY2BGR)
output = cv2.applyColorMap((output * 255).astype(np.uint8), cv2.COLORMAP_JET)
# 写入视频
out.write(output)
cap.release()
out.release()
cv2.destroyAllWindows()

2、ZoeDepth
https://huggingface.co/spaces/shariqfarooq/ZoeDepth
https://github.com/isl-org/ZoeDepth
https://colab.research.google.com/github/isl-org/ZoeDepth/blob/main/notebooks/ZoeDepth_quickstart.ipynb#scrollTo=OJ9bY7rrVuAq
报错:ZoeDepth: Unexpected key(s) in state_dict: “core.core.pretrained.model.blocks.0.attn.relative_position_index”
解决: pip install timm==0.6.7
代码:
git clone https://github.com/isl-org/ZoeDepth.git
cd ZoeDepth
import torch
from zoedepth.utils.misc import get_image_from_url, colorize
from PIL import Image
import matplotlib.pyplot as plt
zoe = torch.hub.load(".", "ZoeD_N", source="local", pretrained=True, version='ZoeD_N-Nov13-2023')
zoe = zoe.to('cuda')
#@title Predicting depth from a url image
img_url = "http://static1.squarespace.com/static/6213c340453c3f502425776e/62f2452bc121595f4d87c713/62f3c63c5eec2b12a333f851/1661442296756/Screenshot+2022-08-10+at+15.55.27.png?format=1500w" #@param {type:"string"}
img = get_image_from_url(img_url)
depth = zoe.infer_pil(img)
colored_depth = colorize(depth)
fig, axs = plt.subplots(1,2, figsize=(15,7))
for ax, im, title in zip(axs, [img, colored_depth], ['Input', 'Predicted Depth']):
ax.imshow(im)
ax.axis('off')
ax.set_title(title)

本地图片
img = Image.open("/content/loong.png").convert("RGB") # load
# depth_numpy = zoe.infer_pil(image) # as numpy
depth = zoe.infer_pil(img)
colored_depth = colorize(depth)
fig, axs = plt.subplots(1,2, figsize=(15,7))
for ax, im, title in zip(axs, [img, colored_depth], ['Input', 'Predicted Depth']):
ax.imshow(im)
ax.axis('off')
ax.set_title(title)

看着原图与深度图尺寸一致

本地运行完整代码:
import torch
from zoedepth.utils.misc import get_image_from_url, colorize
from PIL import Image
import matplotlib.pyplot as plt
# Zoe_N
model_zoe_n = torch.hub.load(r".", "ZoeD_N", source="local", pretrained=True)
img = Image.open(r"C:\Users\loong\Downloads\loong.png").convert("RGB") # load
# depth_numpy = zoe.infer_pil(image) # as numpy
depth = model_zoe_n.infer_pil(img)
print(depth.shape,depth)
colored_depth = colorize(depth)
fig, axs = plt.subplots(1,2, figsize=(15,7))
for ax, im, title in zip(axs, [img, colored_depth], ['Input', 'Predicted Depth']):
ax.imshow(im)
ax.axis('off')
ax.set_title(title)
# Save the figure
output_filename = "output_image.png"
plt.savefig(output_filename)
# Show the figure
plt.show()
彩色
import numpy as np
img = Image.open("/content/loong.png").convert("RGB") # load
depth = zoe.infer_pil(img)
# 归一化深度图
depth_normalized = (depth - depth.min()) / (depth.max() - depth.min())
# 反转颜色映射
depth_normalized = 1 - depth_normalized
# 应用颜色映射
colored_depth = plt.get_cmap('jet')(depth_normalized)
# 将 RGBA 转换为 RGB
colored_depth = (colored_depth[:, :, :3] * 255).astype(np.uint8)
fig, axs = plt.subplots(1, 2, figsize=(15, 7))
for ax, im, title in zip(axs, [img, colored_depth], ['Input', 'Predicted Depth']):
ax.imshow(im)
ax.axis('off')
ax.set_title(title)
plt.show()

transformers加载使用
https://huggingface.co/docs/transformers/main/en/model_doc/zoedepth
from transformers import pipeline
from PIL import Image
import requests
# url = "http://images.cocodataset.org/val2017/000000039769.jpg"
# image = Image.open(requests.get(url, stream=True).raw)
image = Image.open(r"C:\Users\loong\Downloads\right1.png")
pipe = pipeline(task="depth-estimation", model="Intel/zoedepth-nyu-kitti")
result = pipe(image)
depth = result["depth"]


3、Depth-Anything
https://github.com/DepthAnything/Depth-Anything-V2
from transformers import pipeline
from PIL import Image
pipe = pipeline(task="depth-estimation", model="depth-anything/Depth-Anything-V2-Small-hf")
image = Image.open(r"C:\Users\loong\Downloads\right1.png")
result = pipe(image)
depth = result["depth"]

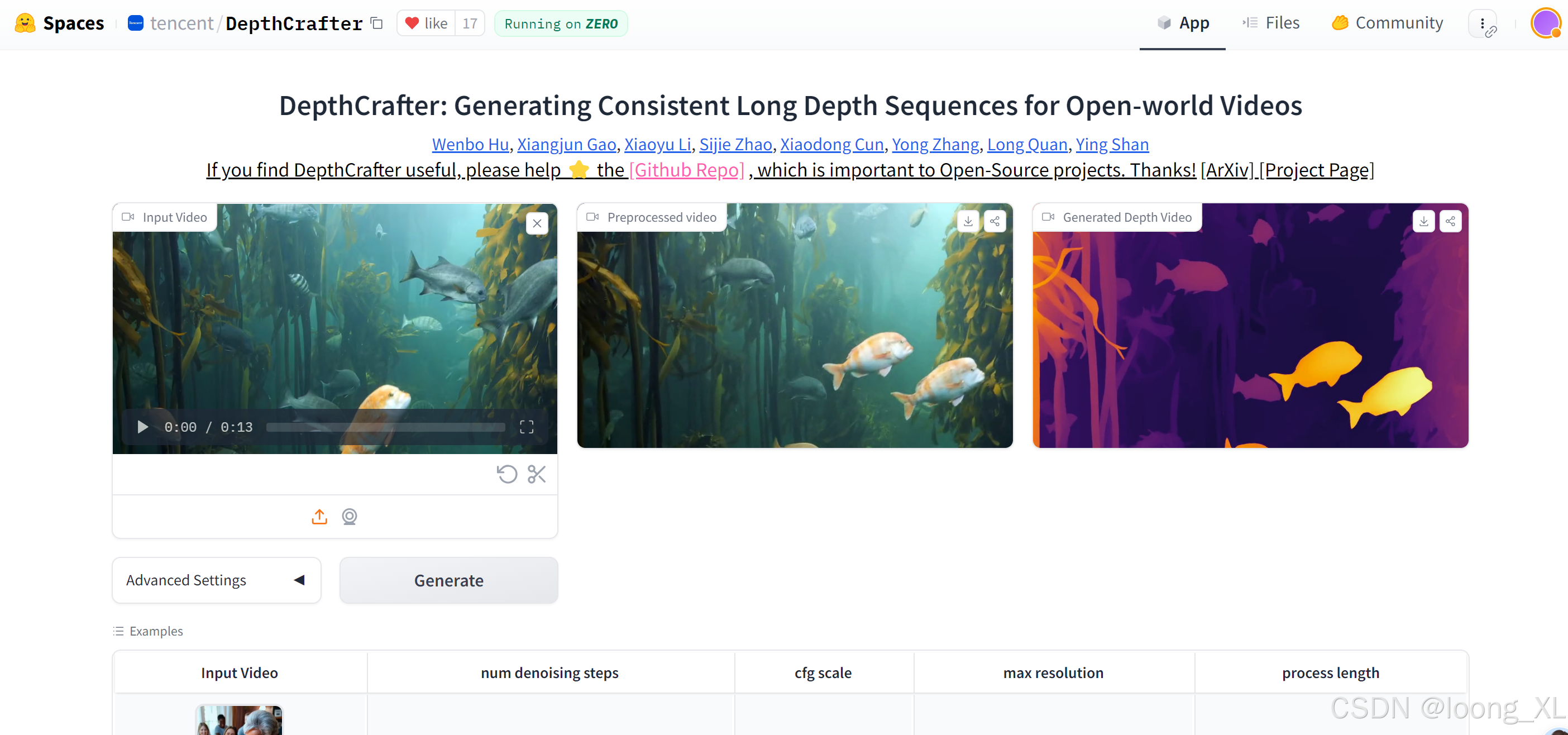
4、DepthCrafter
DepthCrafter 视频深度图
在线demo:https://huggingface.co/spaces/tencent/DepthCrafter
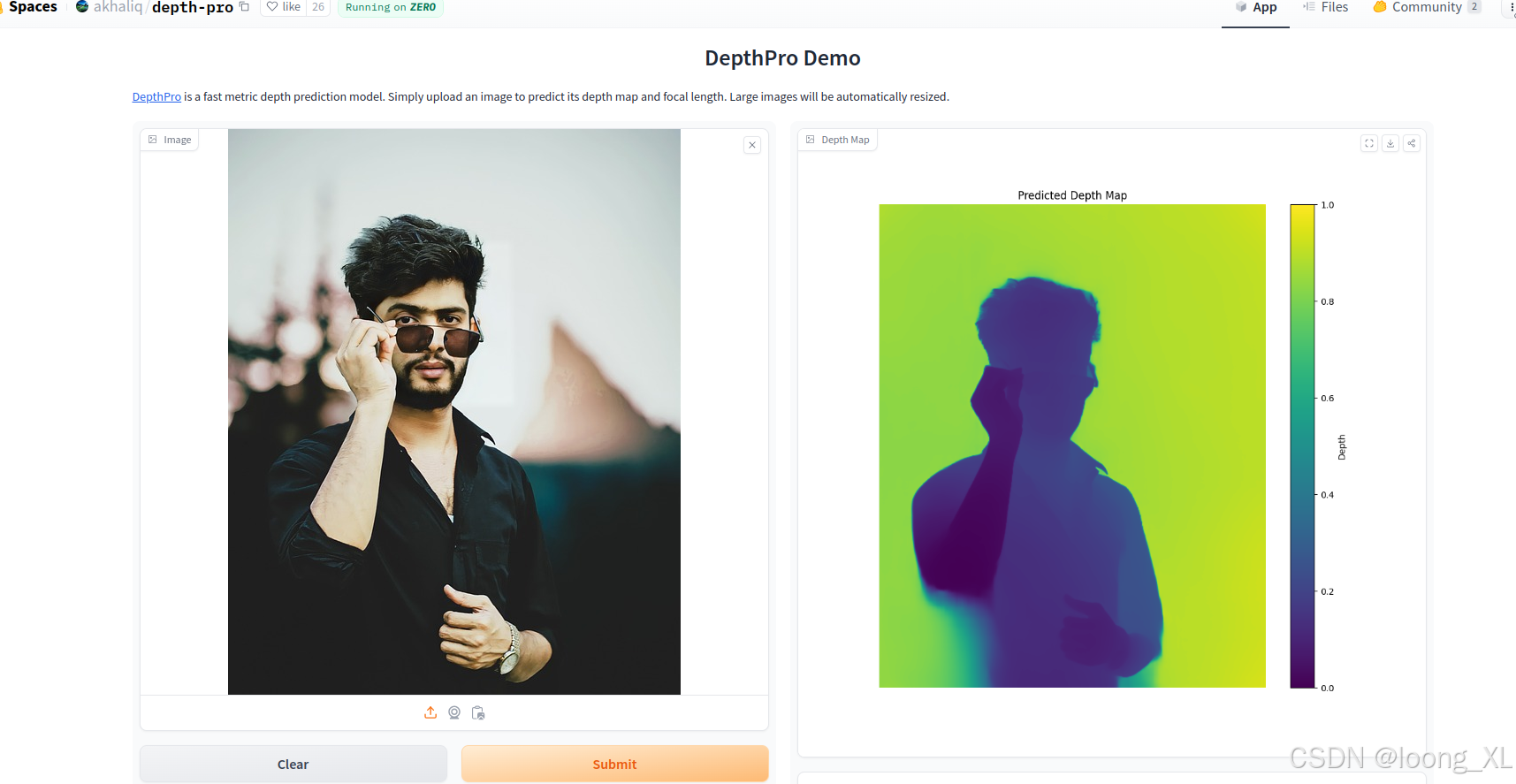
5、depth-pro
https://huggingface.co/spaces/akhaliq/depth-pro
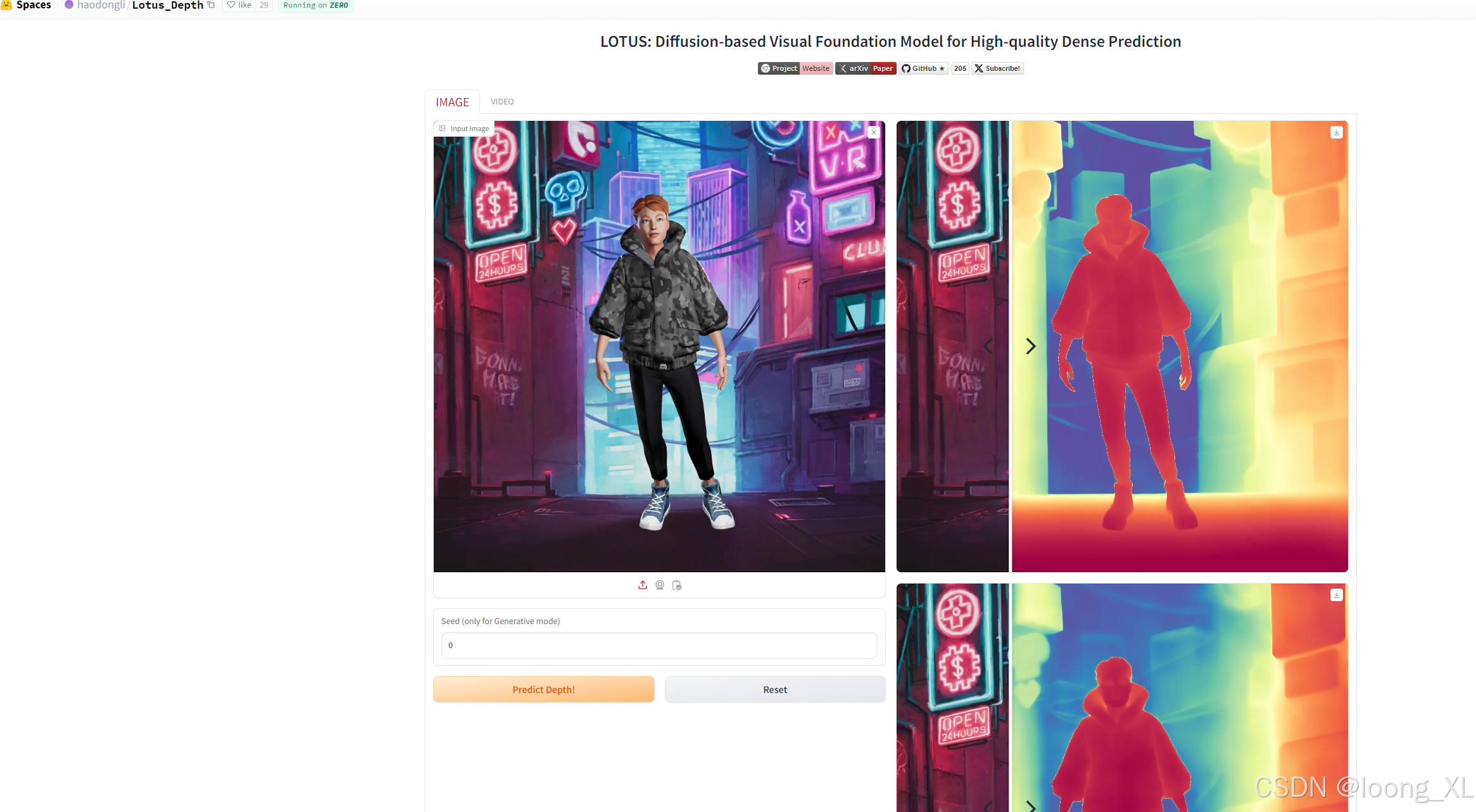
6、Lotus_Depth
https://huggingface.co/spaces/haodongli/Lotus_Depth
LOTUS: Diffusion-based Visual Foundation Model for High-quality Dense Prediction
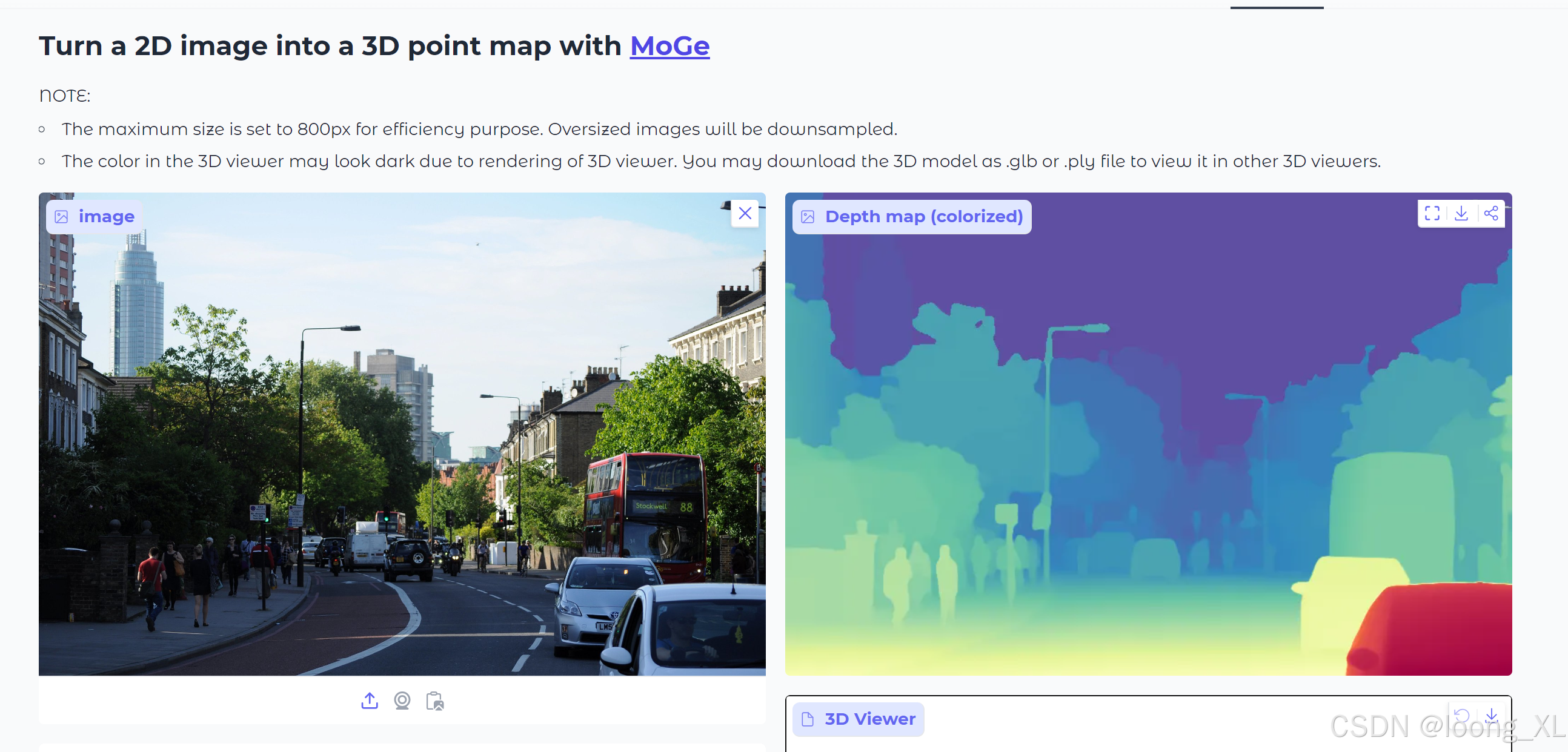
7、MoGe
https://huggingface.co/spaces/Ruicheng/MoGe



















 8962
8962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











