










恕我直言:这篇文章与“GCAN: Graph Convolutional Adversarial Network for Unsupervised Domain Adaptation CVPR 2019”的思想基本一致,只是做了一个应用,但是也能发一篇高水平刊物,就很说明问题,不过文章很多在故障诊断的应用手法还是值得借鉴
一、预备知识:
无监督域自适应方法(Unsupervised Domain Adaptation):用于学习域不变和区分性特征。代表方法包括域对抗网络DANN和MMD(最大平均差异度量)方法。
MMD是重构希尔伯特空间的非参数度量函数,它经常用于评估两个分布期望的相似性。MMD方法作为深度网络的一部分用于学习可迁移特征。
DANN来自于生成对抗网络,其利用域判别器和特征提取器之间的两层minmax博弈层可以提取迁移特征。特征提取器旨在提取域不变特征去“欺骗”域判别器,而域判别器又被训练用于区分特征提取器提取的特征是来自于源域还是目标域。通过这样的对抗训练,特征提取器可以学习到两个域的全局分布。
GCN可以聚合k范围内的邻点信息以此取得图平滑,但是传统GCN只能在一个固定接收域内聚集信息;而多接收域GCN(MRF-GCN)可以获得丰富的特征表示并将数据结构信息嵌入至特征表示中。
二、所提方法:
A.域对抗网络:
在本工作中,主要讨论新工作环境下无标签样本的故障诊断。传感器数据分为源域(有标签)和目标域(无标签)。在UDA中,假定源域和目标域的标签空间是相同的,而特征空间是不同但有关联的。本文的目标是建立一个深度网络,能够预测目标域的样本标签。
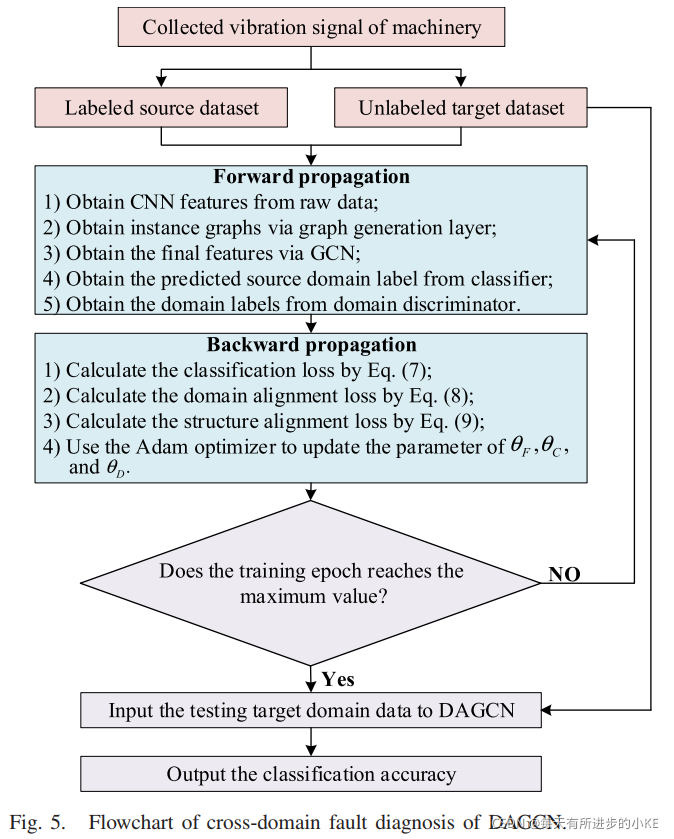
提出的基于变工况故障诊断的DAGCN流程如下图:首先原始数据输入至CNN以获取特征映射,然后每个特征向量被视作是节点。通过提出的GGL方法,特征向量值被视作自动生成图的节点特征。之后,获取的图被导入至GCN以此将数据结构信息嵌入至节点特征。最后,获得的节点特征被用于故障分类以及域对抗训练。因此,可以将步骤总结为:图生成,目标函数以及模型参数更新。
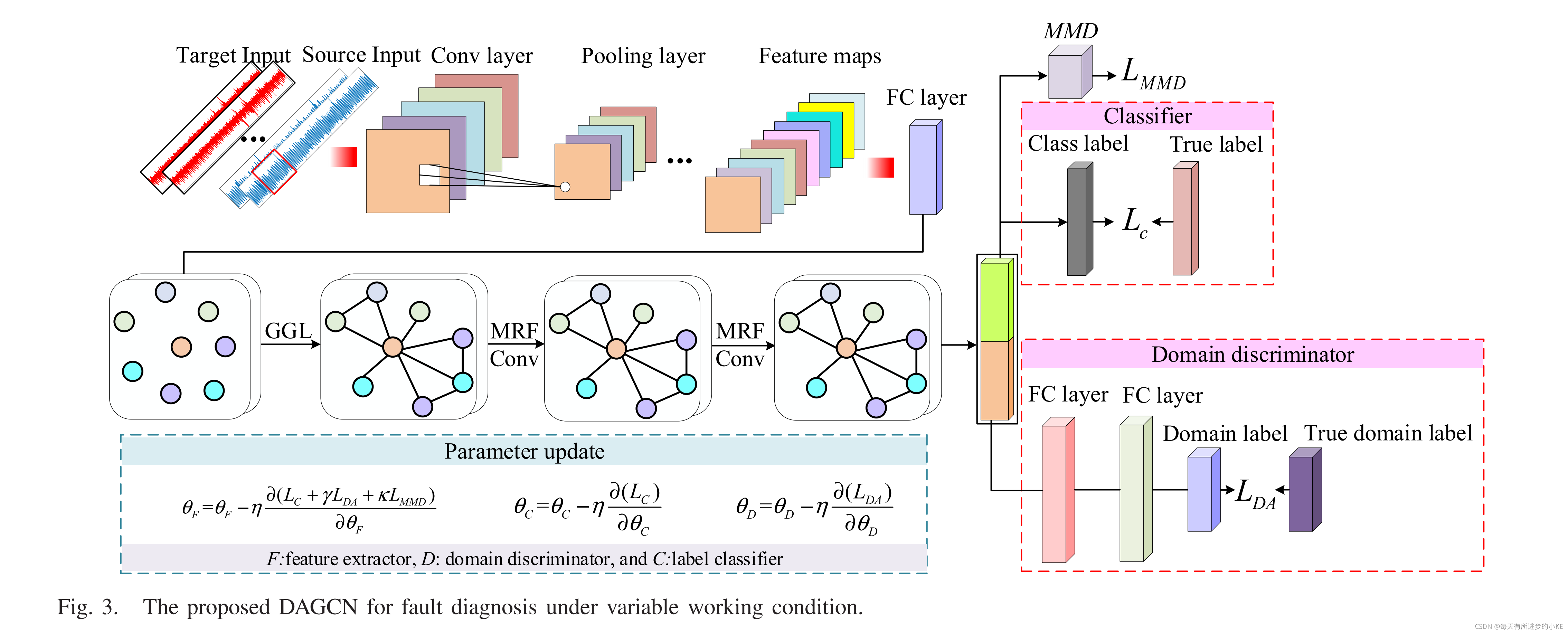
B. 图生成
图有两个比较重要的组成部分,即邻接矩阵A和节点特征矩阵X。为了获取X,一个CNN被用于从输入数据中获取特征,获取的节点特征映射可以表示为:
![]()
![]() 是一个小批次输入矩阵。
是一个小批次输入矩阵。
提出了一种GGL,获取邻接矩阵A,并从小批量输入矩阵构造实例图,其过程如图4所示。首先,将提取的特征矩阵输入多层感知器(MLP)。然后,通过MLP特征及其转置矩阵之间的矩阵乘法得到邻接矩阵。最后,根据top-k排序机制选择每个节点的前k个最近邻。因此,邻接矩阵可由下式得到:

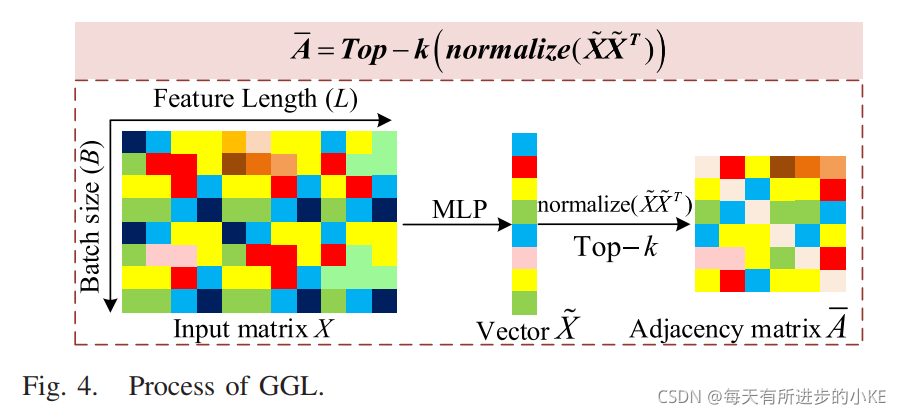
Top−k(·)返回A在每列前k个最大值的索引,使邻接矩阵稀疏,减少了计算负担。
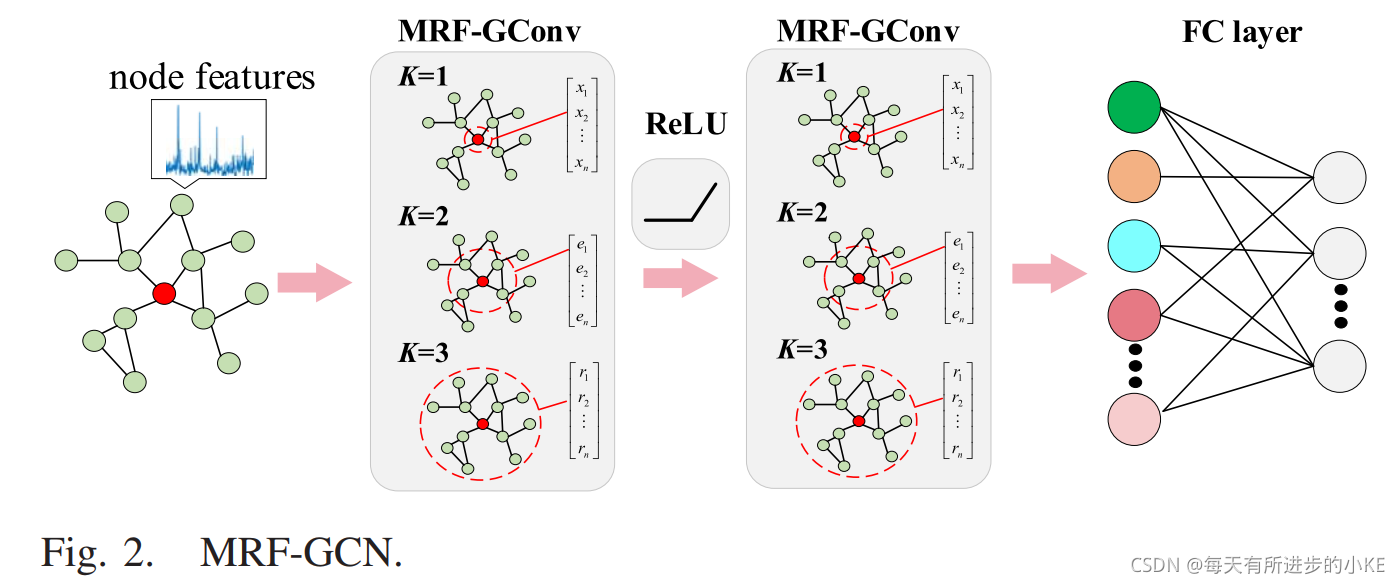
如图2所示,三层接收域(K1, K2, and K3的取值为[1, 2, 3])的MRF-GCN被用于重构实例图。因此,对于一个输入图,通过MRF-GCN所得到的特征表示可以定义为:
![]()
其中![]() 是第一和第二层MRF-Conv的学习得到的特征表示,W是可训练的权重矩阵。
是第一和第二层MRF-Conv的学习得到的特征表示,W是可训练的权重矩阵。
C.UDA的目标函数
目标函数由三部分组成:特征提取器(F)、域判别器(D)和标签分类器(C)。为了提取迁移特征和构建上述的三种重要信息(类标签,域标签,数据结构信息),总体目标函数包括分类损失、域一致性损失和结构一致性损失三个部分。
1)分类损失:真实标签和预测标签的分类损失为交叉熵函数:
![]()
其中,![]() 表示标签分类器的预测结果,
表示标签分类器的预测结果,![]() 表示交叉熵损失。
表示交叉熵损失。![]() 表示数学期望。
表示数学期望。
2) 域一致性损失:由于域协变移位问题(the domain covariant-shift problem),仅用源域数据训练的标签分类器不能很好地处理目标域数据。为了解决这个问题,一个域判别器(D)用来判断提取的特征是来自目标域还是源域,并训练特征提取器欺骗域判别器。当域判别器和特征提取器的minmax博弈达到均衡时,可以捕获域不变特征(即域判别器已无法判别特征提取器所提的特征,说明不同域的特征已无法区分,也就是得到域不变特征)。这里采用二进制交叉熵损失作为域一致性损失,记为:
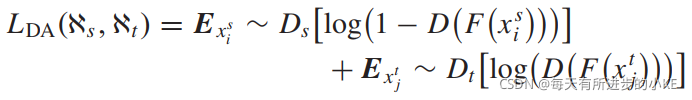
其中![]() 分别表示目标域第j个和源域第i个提取特征。D(·)取值为0或1,可以用来区分样本属于哪个域(源域为1,目标域为0)。
分别表示目标域第j个和源域第i个提取特征。D(·)取值为0或1,可以用来区分样本属于哪个域(源域为1,目标域为0)。
the domain covariant-shift problem:
假设q1(x)是测试集中一个样本点的概率密度,q0(x)是训练集中一个样本点的概率密度。最终我们估计一个条件概率密度p(y|x,θ),它由x和一组参数θ={θ1,θ2......θm}所决定。对于一组参数来说,对应loss(θ)函数评估性能的好坏
综上,当我们找出在q0(x)分布上最优的一组θ'时,能否保证q1(x)上测试时也最好呢?
传统机器学习假设训练集和测试集是独立同分布的,即q0(x)=q1(x),所以可以推出最优θ'依然可以保证q1(x)最优。但现实当中这个假设往往不成立,伴随新数据产生,老数据会过时,当q0(x)不再等于q1(x)时,就被称作covariate shift
————————————————
原文链接:https://blog.csdn.net/mao_xiao_feng/article/details/54317852交叉熵加入对数函数的原因:预测输出与 y 差得越多,L 的值越大,也就是说对当前模型的 “ 惩罚 ” 越大,而且是非线性增大,是一种类似指数增长的级别。这是由 log 函数本身的特性所决定的。这样的好处是模型会倾向于让预测输出更接近真实样本标签 y。
3)结构一致性(对准)损失:在对源域和目标域特征结构进行对准的过程中,采用MMD度量作为结构偏差对准损失,表示为:
![]()
其中φ(·)表示非线性映射函数,表示通过将提取的特征嵌入到RKHS(重构希尔伯特空间)中来测量该距离。
4)总体目标函数:结合定义的三个损失函数,实现UDA的总体目标函数可以写成
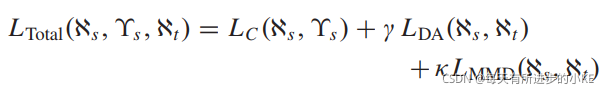
其中γ和k是权衡参数(the tradeoff parameters)。
D.模型参数更新
令θF,θC、θD分别表示特征提取器、标签分类器和域判别器的参数。在模型训练过程中,可以通过反向传播(BP)算法更新DAGCN中各部分的参数,记为
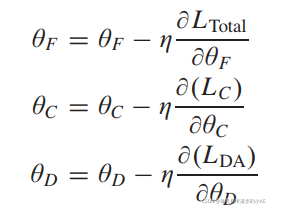
其中∂表示偏导数算子,η表示学习率。
特别是在特征提取器中,MRF-GCN参数可以通过计算以下公式来更新:
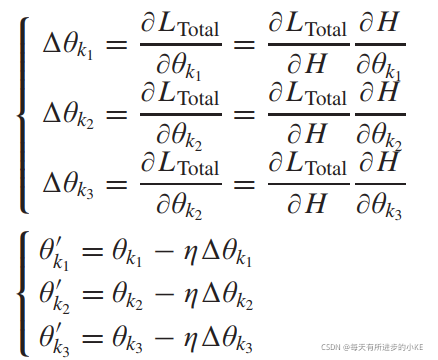
通过MRF-GCN所得到的特征表示为H,![]() 是 MRF-GCN三层接收域的参数 ,
是 MRF-GCN三层接收域的参数 ,![]() 表示更新后的参数。
表示更新后的参数。
通过最小化定义的总体目标函数,优化DAGCN参数,得到域不变特征和判别特征,使使用带标记源域数据训练的分类器能够正确地对未带标记目标域数据进行分类。因此,算法一总结了利用所提出的DAGCN对UDA进行故障诊断的算法,图5给出了利用所提出的DAGCN实现跨域故障诊断的详细流程图。

三、实验
数据集分别来自于变速箱和航空发动机润滑油配件控制系统
A.实验1:齿轮箱故障诊断
1)数据描述:齿轮箱测试平台由驱动装置、轴、齿轮箱和负载(a drivemotor, a shaft, a gearbox, and the load)组成。在本实验中,对齿轮箱输出轴的齿轮预设了两种不同类型的齿轮故障,包括齿面磨损和四种不同故障级别的齿裂纹在内的齿轮故障如图7所示,加上健康状态,齿轮的健康状态共有六种(4+1+1)。变速器Y方向安装加速度计(Accelerometers)采集振动信号,传感器采样频率为10240 Hz。模拟四种不同转速(1000、1100、1200和1400 r/min),将每种转速视为一种工况。


本实验采用Z-score归一化方法对采集的数据进行归一化。然后使用窗口长度为1024的滑动窗口对原始振动信号进行分割,形成子样本,在分割过程中,每个样本之间不存在重叠。在每个工况下,每个健康状态产生1000个样本,所以6个健康状态总共得到6000个样本。另外,为了获得一种工况的训练集,在每种健康工况下随机选取80%的样本,其余20%作为测试集。因此,每一种工况下,总共有4800个样本用于训练,1200个样本用于测试。
z-score标准化,也称为标准化分数,这种方法根据原始数据的均值和标准差进行标准化,经过处理后的数据符合标准正态分布,即均值为0,标准差为1(根据下面的转化函数很容易证明),转化函数为:
————————————————
原文链接:https://blog.csdn.net/jzwong/article/details/51839721
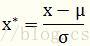
我们使用0、1、2和3分别表示四种不同的工作条件(四种转速工况)。因此,我们进行了12个跨领域(A^2_4)的任务进行综合分析。为简单起见,我们使用![]() 表示跨域任务
表示跨域任务![]() ,即模型用域a的数据进行训练,用域b的数据进行测试。值得注意的是,在特征迁移阶段,将域a的带标签样本和域b的少量未带标签样本输入到DAGCN中进行对抗训练,其余的域b的未带标签样本用于模型测试。
,即模型用域a的数据进行训练,用域b的数据进行测试。值得注意的是,在特征迁移阶段,将域a的带标签样本和域b的少量未带标签样本输入到DAGCN中进行对抗训练,其余的域b的未带标签样本用于模型测试。
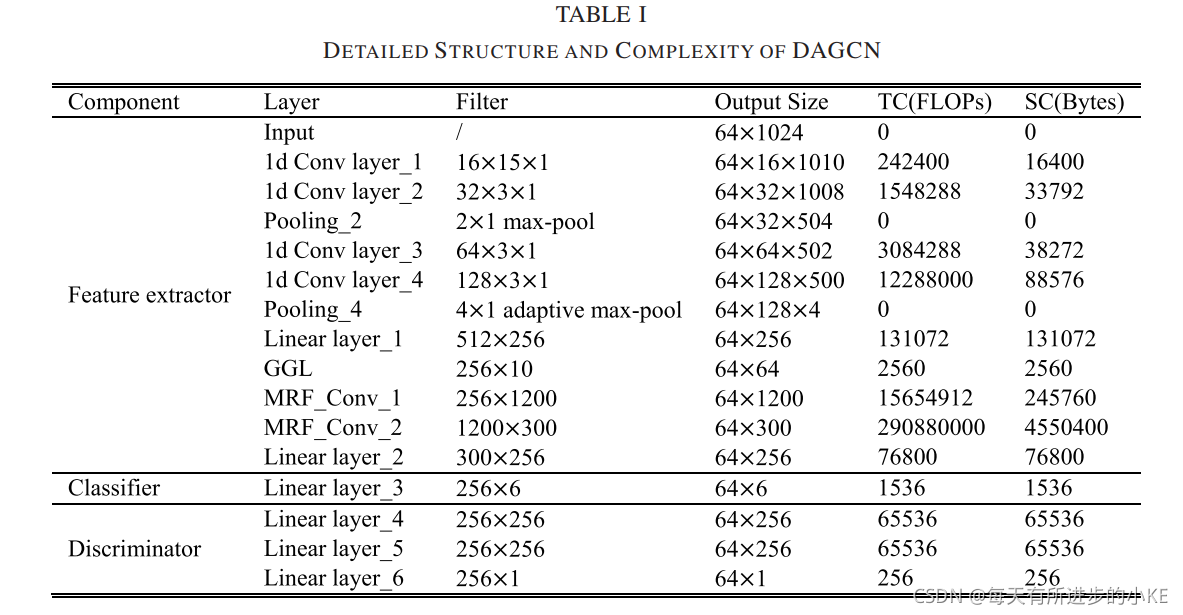
2)诊断结果:为了证明所提出的DAGCN的优越性,我们采用了6种比较方法,分别是JAN[20]、MKMMD[21]、CORAL[22]、DANN[26]、CDANN和CDANN+E(CDANN 带熵条件)[27]。六种比较方法的特征提取器都是一个四层CNN,而特征提取器也被用来获得一个直接迁移的基准。此外,DAGCN的详细结构如表1所示,其中前四层特征提取器为卷积层(convolutional layer, Conv),后两层为MRF-GConv层。
在模型训练中,使用300个epoch对模型进行训练,在前50个epoch对每个模型进行预训练,不使用目标域样本。初始学习速率设置为0. 001,学习速率衰减是在epoch150和250时分别乘0.1(即学习率在150epoch为1e-4,250epoch时为1e-5)。
两个权衡参数(即γ和κ)由![]() 计算,其中τ取10,在迁移学习策略未激活时e取0,在迁移学习策略激活后e取1。本次实验的评价指标是整体的准确性,为了减少结果的随机性,最终结果采用了最后10个epoch的平均值。本次实验的结果如表II所示
计算,其中τ取10,在迁移学习策略未激活时e取0,在迁移学习策略激活后e取1。本次实验的评价指标是整体的准确性,为了减少结果的随机性,最终结果采用了最后10个epoch的平均值。本次实验的结果如表II所示
3)结果分析:
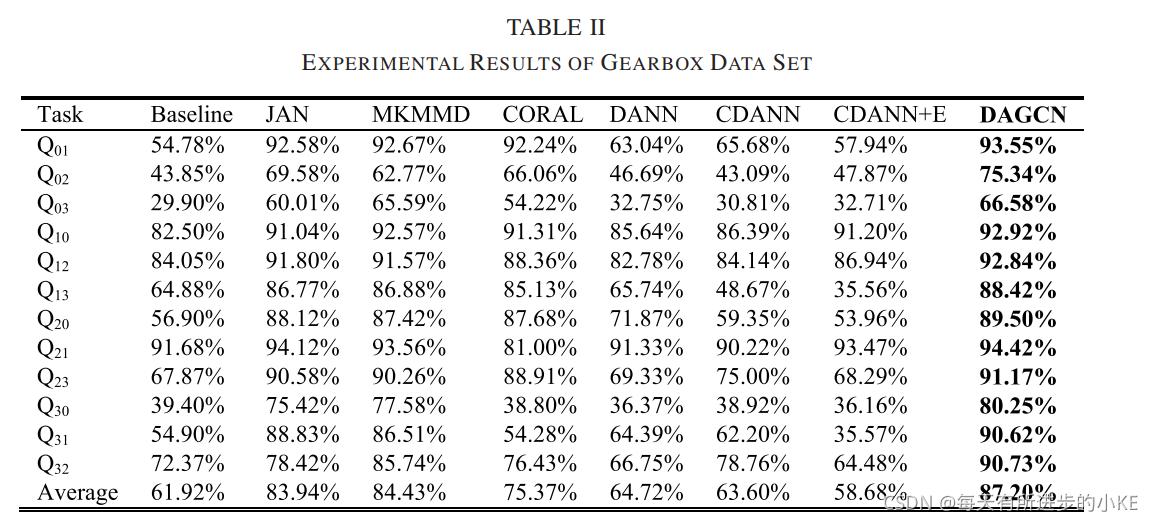
从表II可以看出,所提出的DAGCN在每个跨域任务中都能获得最好的结果,而基于映射的方法(JAN、MKMMD和CORAL方法)比基于对抗性的方法(DANN、CDANN和CDANN+E)有更好的结果。在最困难的任务Q30中,表现最差的模型诊断准确率为36.16%,而提出的DAGCN诊断准确率为80.25%。在最简单的任务,即任务Q21中,表现最差的模型获得的诊断准确率为81%,而DAGCN达到94.42%。这些结果表明,尽管领域差异变得越来越大,跨领域任务变得越来越困难,DAGCN仍然可以获得性能提高
四、模型讨论
A.消融实验
为了找出模型各部分对模型性能的影响,在该区域进行了消融研究。两个变体进一步从提出的DAGCN衍生而来:1) DAMMD:只有四层CNN被用于特征提取(无GCN);2) TGCN: DAGCN无分布偏差对准损失(即只有分类损失)。两种变体的实验结果和提出的DAGCN在变速箱数据集上的实验结果如表4所示
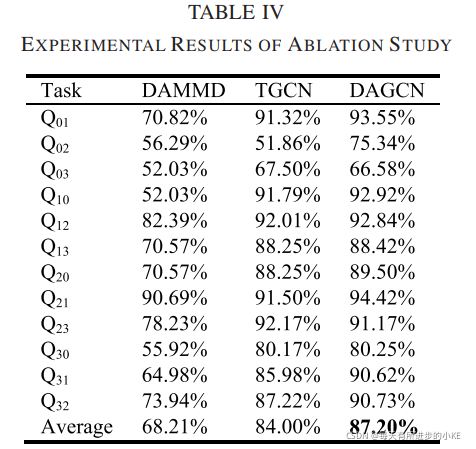
从这些结果中可以看出,所提出的DAGCN比TGCN高3.20%,比DAMMD高18.74%。如此大的改进表明,考虑数据结构并将其嵌入到学习的特征表示中是至关重要的。此外,调整源和目标域特性之间的分布也可以提高模型的性能。
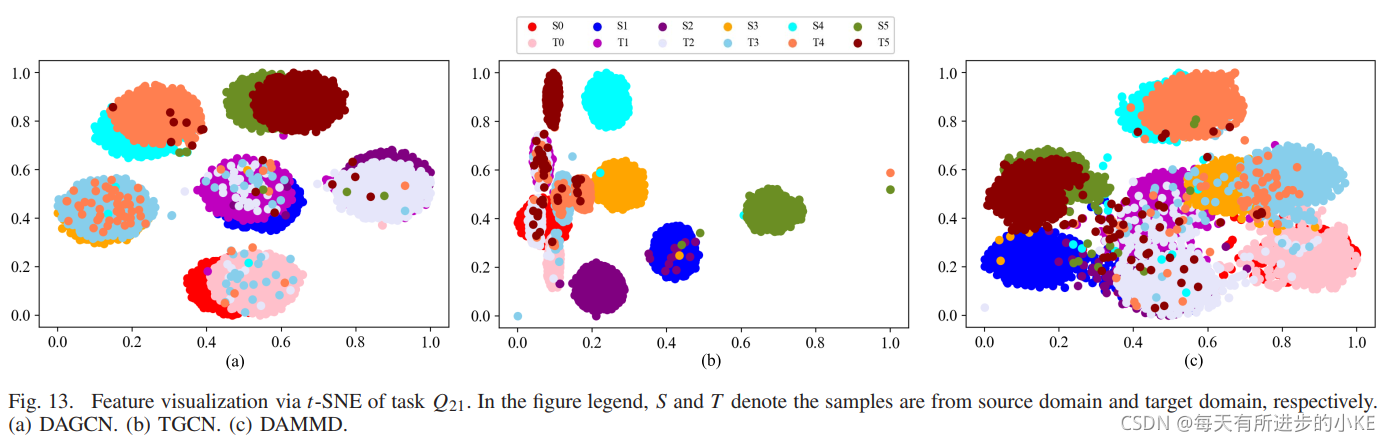
为了显示三种方法学习到的特征,通过t-SNE将特征提取器最后一层的特征可视化,图13展示了任务Q21中三种方法的可视化特征。如图13(a)所示,两个不同域的两个特征都被很好地划分为六个部分(代表6种故障类型)。同时,源域和目标域(源域是工况2,目标域是工况1)的同类特征也能很好地对齐。此外,从图13(b)和(c)可以发现,TGCN比DAMMD学习到更好的域不变特征,(TGCN利用了数据结构信息,有更好的域不变性特征;DAMMD利用域对齐准则,有更好可区分性特征)这与实验结果一致。结果表明,所提出的DAGCN学习了域不变性和可区分性特征,这对实现域自适应很重要。

















 3635
3635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









