







2018 arXiv | Objective-Reinforced Generative Adversarial Networks (ORGAN) for Sequence Generation Models

Paper:https://arxiv.org/abs/1705.10843
Code: https://github.com/gablg1/ORGAN
本论文由Gabriel L. Guimaraes (gabriel@pagedraw.io), Benjamin Sanchez-Lengeling (beangoben@gmail.com), Carlos Outeiral (carlos@outeiral.net), Pedro Luis Cunha Farias (pfarias@college.harvard.edu) and Alan Aspuru-Guzik (alan@aspuru.com)联合编写。虽然作者提出的ORGAN在效果上虽然没有特别突出,但是其中使用强化学习是值得学习的。
在基于序列的生成模型中,除了生成可能从数据分布中提取的样本外,通常还需要根据某些领域特定的指标对样本进行微调。本文作者提出了一种方法,利用对抗训练和基于专家的奖励与强化学习的组合来指导样本的结构和质量。基于SeqGAN(基于序列的生成对抗网络(GAN)框架,将数据生成器建模为强化学习设置中的随机策略),并扩展了训练过程,除鉴别器奖励外,还包括领域特定目标。这两种奖励的混合可以通过一个可调参数进行控制。为了提高训练的稳定性,利用沃瑟斯坦距离作为判别器的损失函数。在两个任务中证明了这种方法的有效性:生成编码为文本序列和有旋律的分子。实验结果表明,该模型生成的样本能够保持从数据中获取的原始信息,保持样本多样性,并在期望的指标上有所改善。
介绍
强化生成对抗网络(ORGAN)是对原始生成对抗网络(GAN)的改进。在深入研究ORGAN的理论和实现之前,让我简单介绍一下GAN的基础知识。一个简单的GAN由两个神经网络组成:Generator和Discriminator。
Generator(G) 生成器
生成器的主要目的是生成类似于真实数据/分布的假样品,以至于鉴别器无法区分真实数据和假数据。换句话说,它试图欺骗歧视者。
Discriminator(D)判别器
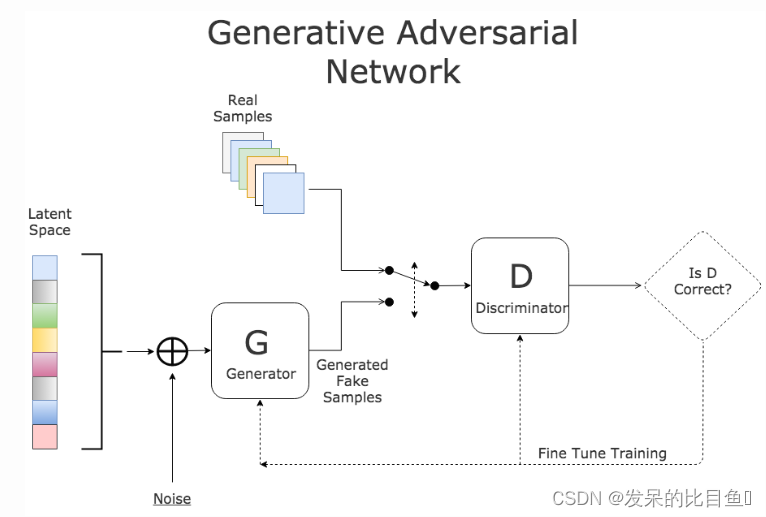
这两个网络相互对抗,试图通过他们的工作证明自己更好。它们的主要目标是生成与训练数据中包含的一些数据点相似的数据点。给定一个初始训练分布
p
d
a
t
a
p_{data}
pdata,生成器
G
G
G从带有随机噪声z的分布
p
s
y
n
t
h
p_{synth}
psynth中采样x,而鉴别器D从p(synthetic)或
p
d
a
t
a
p_{data}
pdata中查看样本,并尝试将它们的身份(y)分类为真实的
x
∈
p
d
a
t
a
x \in p_{data}
x∈pdata或虚假的
x
∈
p
s
y
n
t
h
x \in p_{synth}
x∈psynth。该模型遵循一个最小-最大博弈,其中我们最小化生成器函数
l
o
g
(
1
D
(
G
(
z
)
)
log(1D(G(z))
log(1D(G(z)),以便通过生成非常接近原始分布的样本来欺骗鉴别器,同时最大化鉴别器函数
l
o
g
(
D
(
x
)
)
log(D(x))
log(D(x)),以便它能够更准确地分类假数据点和真实数据点。
- 对于一个数据点,有:
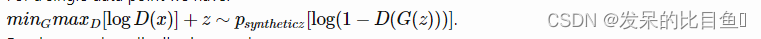
- 对于完整的分布,有:
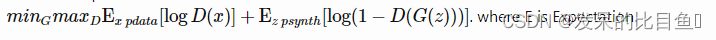
训练GAN
训练GAN仍然是一个伟大的研究课题。但是各种各样的问题限制了GAN的功率和稳定性。GAN在训练时的另一个稳定性也是一个主要障碍。如果您开始训练GAN,您将意识到鉴别器部分比它的生成器对应部分更强大。因此,生成器将无法有效地训练。这将反过来在训练GAN的过程中造成巨大的损失。相反,如果鉴别器过于宽松;它可以生成任何图像。因此整个想法对于GAN来说是无用的。
训练分为两个阶段
- 判别器训练:我们在标记的训练集上训练判别器,以供一定的时期范围。必须以这种方式对其进行训练,以便将训练数据正确区分为真实(1)。这是通过改变时期数来实现的。在训练判别器时,发电机处于冻结模式(冻结意味着将训练设置为false。网络只能向前通行,并且不应用后传播)。之后,我们生成假数据并训练歧视器,直到它有效地预测。计算损失并优化网络参数并更新梯度。
- 生成器训练:现在训练Generator,我们以判别器的预测为目标来训练Generator。与之前的训练步骤类似,我们在冻结模式下有discriminator。计算损耗,优化网络参数,更新梯度。
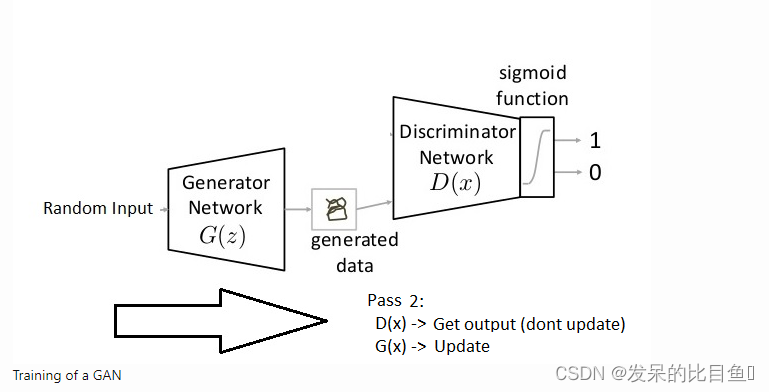
这是GAN的简要介绍。现在,让我们来看看ORGAN和GAN的对比。在器官,主要的区别是应用强化学习(RL)训练生成器的方式,它产生输出与期望的性质。在ORGAN中,我们绕过了生成器微分问题,将特定的离散序列作为RL生成器梯度设置中的随机策略。换句话说,我们使用策略梯度更新生成器参数。
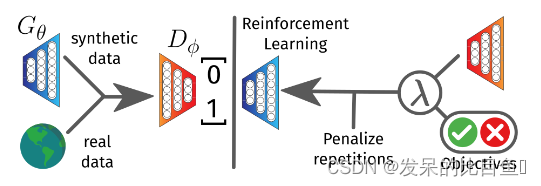
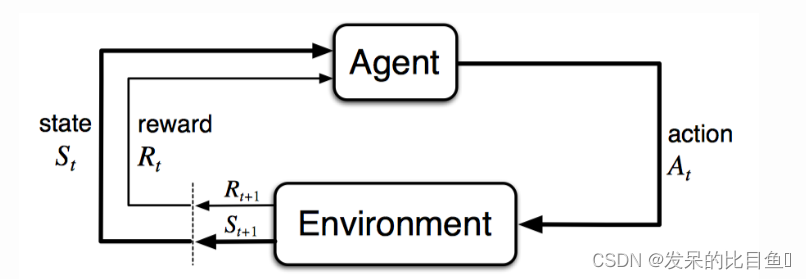
强化学习
在RL环境中,我们将生成器视为代理。我们有
s
s
s作为带有奖励函数
Q
Q
Q的状态,
a
a
a是在状态
s
s
s中行动者从动作空间
a
a
a中选择的动作。动作空间
A
A
A包含所有可能的字符,以选择下一个字符
x
t
+
1
x_{t+1}
xt+1。状态
s
t
s_t
st是一个已经生成的字符
X
1
:
t
X_{1:t}
X1:t的部分序列。
Q
(
s
,
a
)
Q(s,a)
Q(s,a)是行动价值函数,表示在采取行动
a
a
a并遵循当前策略完成剩余序列的状态
s
s
s时的预期奖励。当我们处于状态
s
s
s时,我们估计每个可能的动作的
Q
Q
Q值,然后选择
Q
Q
Q值最高的动作。设
R
(
X
1
:
T
)
R(X_{1:T})
R(X1:T)是为全长序列定义的奖励函数。现在,如果我们有一个不完全序列
X
1
:
t
X_{1:t}
X1:t,处于状态
s
s
s,那么生成器
G
θ
G_θ
Gθ(读
G
G
G由
θ
θ
θ参数化)必须产生一个下一个令牌
x
t
+
1
x_{t+1}
xt+1的动作
a
a
a。代理人的假设策略是
G
(
y
t
∣
Y
1
:
t
−
1
)
G(y_t|Y_{1:t-1})
G(yt∣Y1:t−1),我们的目标是最大化预期长期报酬
J
θ
J_θ
Jθ。
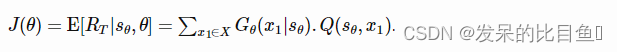
生成分子的奖励是通过特定属性的奖励指标来计算的。一些例子包括LogP、合成可及性、天然产物相似性、化学美(药物相似性的定量估计)、谷本相似性、最近邻相似性。
**强化方法:**使用RDKit化学信息学包实现分子度量。指标包括合成可及性、天然产品可能性、药物相似性、LogP、最近邻相似性。强化提供了一个质量度量(在0和1之间),它给出了特定分子的可取性,1是高度可取的,0是高度不可取的。
强化度量的主要目标是通过优化生成器来生成与初始数据分布相似的分子,从而最大化奖励。然后由鉴别器和奖励指标分析生成的分子。然后优化和训练生成器来欺骗鉴别器。
我们已经完成了训练的前半部分。以上步骤称为预训练。现在我们将训练生成器和鉴别器,但有一个策略梯度。由于这个生成器之前已经被训练过了,让我们知道它是如何在初始字符的帮助下生成自己的分子的。对于每个生成的角色,计算损失并更新模型。对于Generator,计算策略梯度损失。然后优化生成器并更新所有参数。
政策梯度技术
让我们从正常的任意政策开始,然后采取一些行动。如果在这之后,奖励比预期的要好,我们就必须增加这些行动的概率。如果回报更差,我们采取这些行动的可能性就会降低。
策略函数 策略函数计算给定奖励的输出序列的LogSoftmax、目标和序列的长度。它的产出是负的,因为我们想要最小化损失,但最大化政策梯度。Policy梯度损失函数是这样的。

其中
Q
(
s
,
a
)
Q(s,a)
Q(s,a)状态
s
s
s下行为
a
a
a的期望奖励,
G
(
y
t
∣
Y
1
:
t
1
)
G(y_t|Y_{1:t 1})
G(yt∣Y1:t1)为策略。
要获得关于政策梯度的更详细的展望,请参阅本博客。
















 6248
6248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











