










 本文探讨了AIOps中的日志聚类方法,旨在解决企业面临的大规模、异构日志管理问题。通过TF-IDF进行特征提取,PCA降维,再用DBSCAN进行聚类,帮助运维人员快速定位问题和异常检测,提升效率。
本文探讨了AIOps中的日志聚类方法,旨在解决企业面临的大规模、异构日志管理问题。通过TF-IDF进行特征提取,PCA降维,再用DBSCAN进行聚类,帮助运维人员快速定位问题和异常检测,提升效率。

背景
日志是软件系统中获取系统状态的重要来源,日志中包含的运行时状态报告以及错误信息被广泛地用于系统运维中,同时日志也是AIOps实践中经常要面对的数据类型。随着现阶段企业软件系统变得日益庞大和复杂,对于系统产生的海量异构日志,可以通过日志聚类的方法,将相同模式的日志归为一类,以此快速的掌握日志全貌,同时能够方便后续的问题定位与异常检测。
日志聚类是蓝鲸日志平台正在紧锣密鼓,全力产品化的功能之一,关于蓝鲸日志平台,可以点击查看历史文章详细了解——数字化转型趋势下,如何实现日志统一管理?
企业日志管理现状
规模庞大:随业务发展的大规模系统和设备,每天都会产生海量日志,据统计,每小时打印的日志达到约50Gb(约1.2亿~ 2亿行)的量级。
格式不统一:各类系统、设备产生的日志多样,对于不同用户或开发者自定义的日志格式更加多变
综上,日志信息规模大、内容杂、并且格式也难以做到统一规范,这对于运维人员平时的审查和排查故障来说是一个头疼的问题,如果能够通过AI的聚类算法将海量日志划分为固定的几种或者几十种模式,这样原来的千千万万条日志就会被归类为具有代表性的几十条,可以方便运维人员更高效率的进行日志查看和故障排查。
日志聚类
What
日志聚类,是指通过计算日志文本间的相似度,将相似度高的日志聚合成一类,并提取它们的共同pattern的方法,本文首先会基于自然语言处理对日志进行特征提取,而后利用日志文本的相似度对日志聚类,从而挖掘日志模板。
Why
比如某个服务在短时间内产生了大量报警,同时产生了大量日志,而某一类的关键报错日志可能条数较少,则很容易被其他日志淹没,若能在产生大量日志的同时,使用日志聚类对日志进行汇总、抽象聚类,则能够使运维人员发现异常日志与正常日志“类别”上的不同,从而快速定位到异常日志,发现问题。
How
通过上面的讲解,我们对什么是日志聚类以及日志聚类如何应用有了大致的了解,下面将讲述如何实现日志聚类。
1.基于TF-IDF的单词转向量
要想实现日志聚类,首先要将文本类型的日志转换成机器学习可以识别的特征+数据的形式,目前存在多种方法可以实现,这里我们选用的是常见且便于理解的TF-IDF方法。
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术,常用于挖掘文章中的关键词,而且算法简单高效。
下面用截取的一段linux日志说明相关概念:
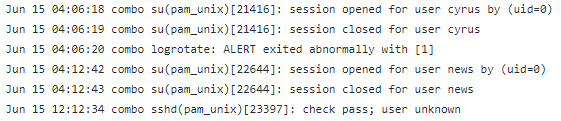
分词:
首先将每行文本按照空格分开。(实际处理时还会有其他分词符号,这里仅是为了便于说明)
词频(TF):
某个词在其行文本中出现的次数。比如上文的combo在每行日志的词频都等于1。
逆文档频率(IDF):
总文本行数除以包含该词语的文本的行数,再将得到的商取对数再加1得到。比如上文的combo在第三行文本的逆文档频率等于log(6/6)+1即1。
词频-逆文档频率(TF-IDF):
词频*逆文档频率。则combo这个单词的TF-IDF值即为1 * 1为1。
可以看到,TF-IDF与一个词在所有文本中的出现次数成正比,与该词在所有文本行的出现次数成反比。因此,TF-IDF可以在一定程度上表征一个词语在整个文本中的重要程度——一个在所有文本中都出现的词一般没那么重要。
优点:简单易懂,计算效率高
缺点:无法体现单词的上下文结构
2.降维
经过上面的分词和对每个单词的TF-IDF值计算,我们得到了标准的机器学习矩阵输入(以每个单词作为特征,以每行文本的每个单词在所有特征下的TF-IDF值作为数值),而所有不重复的单词构成了词向量空间。
对于海量日志而言,所有不重复的单词的数量是极大的,这就会导致输入的矩阵维度极高,也极其稀疏,为了提高运算的效率和聚类的效果,在这一步我们需要对上面的高维矩阵进行降维操作,这里也选择比较常用的PCA(主成分分析)降维算法。以下简单介绍下其原理:
为了将数据的维数从 n 维降到 k 维,我们按照散度(也就是数据的分散程度)降低的顺序对轴列表进行排序,然后取出前k项。
现在开始计算原始数据 n 维的散度值和协方差。根据协方差矩阵的定义,两个特征列的协方差矩阵计算公式如下:
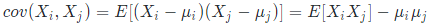
上式中的 μi 表示第 i个特征的期望值,且协方差都是对称的,向量与其自身的协方差就等于其散度,假定X是观测矩阵,则协方差矩阵如下:
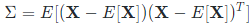
样本X的最大方差位于协方差矩阵的最大特征值对应的特征向量上。也就是说想要保留一个矩阵的最大信息,我们只需要保留该矩阵的最大特征值所对应的特征向量所组成的矩阵即可,这个过程就是降维了。
因此,从数据中保留的主要成分就是与矩阵的顶部k最大特征值对应的特征向量。
降维一般具有以下好处:
有助于数据可视化;
缓解维度爆炸问题,改善模型训练效果;
在压缩数据的同时让信息损失最小化;
可以提高模型训练效率。
3.聚类
经过上面的铺垫,日志的词向量矩阵变得更加好用了,接下来我们使用机器学习中的聚类算法对上面的矩阵进行聚类运算,并给每一类都打上标签,方便后续的汇总。这里聚类的算法我们选择比较出名的密度聚类算法DBSCAN,其大致步骤如下:
输入:样本集D={x1,x2,……,xm},邻域参数(ε, MinPts)
初始化核心对象集合Ω=∅,初始化类别k=0。
遍历D的元素,如果是核心对象,则将其加入到核心对象集合Ω中。
如果核心对象集合Ω中元素都已经被访问,则算法结束,否则转入步骤4。
在核心对象集合Ω中,随机选择一个未访问的核心对象o,首先将o标记为已访问,然后将o标记类别k,最后将o的ε-邻域中未访问的数据,存放到种子集合Seeds中。
如果种子集合Seeds=∅,则当前聚类簇Ck生成完毕, 且k=k+1,跳转到3。否则,从种子集合 Seeds中挑选一个种子点seed,首先将其标记为已访问、标记类别k,然后判断seed是否为核心对象,如果是则将seed中未访问的种子点加入到种子集合中,跳转到5。
优点:能够找出不规则形状的类簇,并且聚类时不需要事先知道类簇的个数,聚类结果没有偏倚。
缺点:当输入矩阵的密度不均匀、类别间距相差很大时,效果不好;另外调参相对于传统的K-Means之类的聚类算法稍复杂。
流程图:

效果:
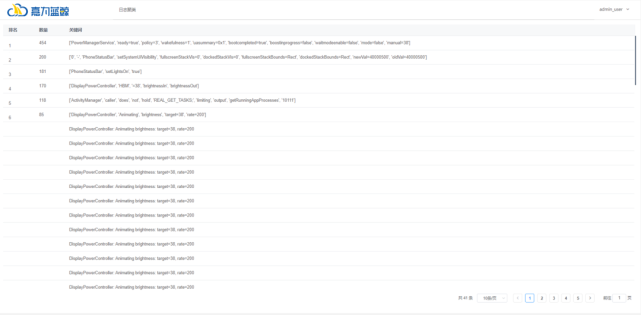
日志聚类:
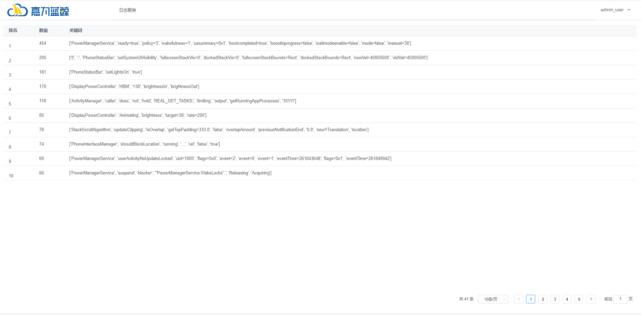
对其中一类进行展开,查看原日志:
总结
通过日志聚类,我们可以将海量日志数据经过AI算法分成几类或者几十类,运维人员也可以按照业务的实际情况调整聚类的精度,控制聚类的类别数量,加快查看日志的效率。
而一般的日志都会带有时间戳,我们还可以在日志聚类的基础上通过分析某类日志的数量变化情况实现异常检测和对系统的故障做出一定程度的定位,那么日志异常检测又该如何实现呢?关注嘉为蓝鲸,下期与您一同探索AIOps——基于Spell方法的日志异常检测。


















 305
305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









