










来源:投稿 作者:小灰灰
编辑:学姐
这是一篇在时尚领域、往细粒度方向做视觉-语言预训练的工作。

论文标题:Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
论文链接:https://arxiv.org/abs/2103.16110
论文代码:https://github.com/mczhuge/Kaleido-BERT
1.网络结构:
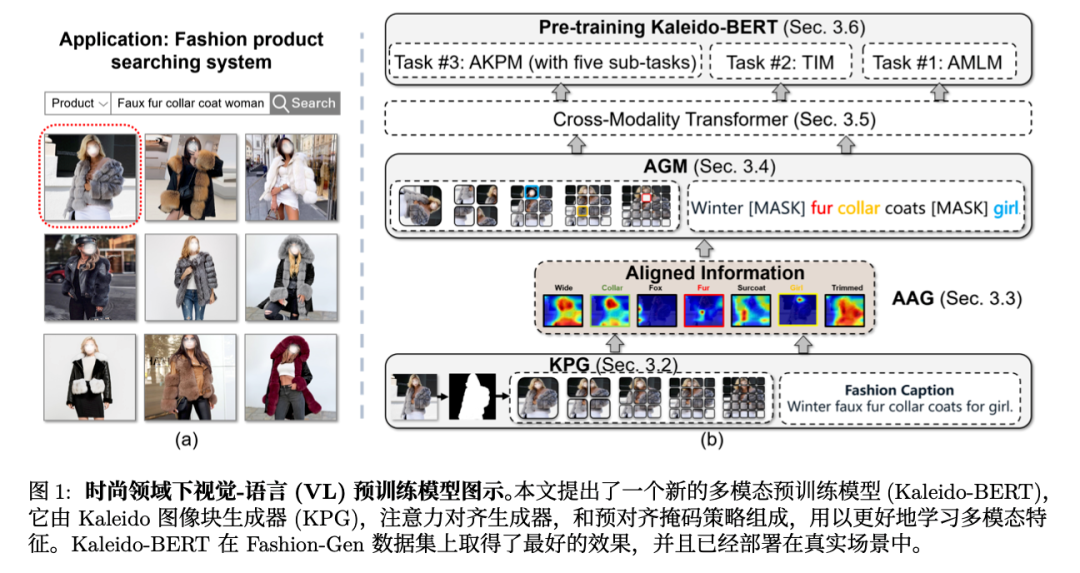
Kaleido-BERT的模型结构图. 1。
它包含 5 个步骤:
-
(1) 在输入阶段,Kaleido-BERT 有两种模态的特征输入:文本输入 (e.g., 商品图像描述) 以及由 Kaleido 图像块生成器 (KPG) 所产生的对应的图像输入。每个文本描述被表征为一系列的词例 (token),而每一张与文本对应的图 像被表示为一系列 Kaleido 图像块。
-
(2) 在图文特征 向量生成的阶段,本研究使用了注意力对齐生成器 (AAG) 去产生词例与 Kaleido 图像块的预对齐信息,以便图像和文本隐式地进行语义对齐。
-
(3) 在交互 阶段,与现有的随机掩码策略不同,本文提出采用预对齐掩码策略 (AGM) 以缓解跨模态语义交互难度。
-
(4) 词例和 Kaleido 图像块的特征向量在 Kaleido- BERT 得到充分交互后,模型渐进式的学习视觉-语言的语义信息并产生多模态细粒度表征。
-
(5) 除了 掩码语言模型 (Masked Language Modeling,MLM) 和图文匹配任务 (Image-Text Matching, ITM) 外, 本工作还使用了 5 种新型的预对齐 Kaleido 模型 (Aligned Kaleido Patch Modeling, AKPM),即: 旋转, 拼图, 伪装, 着色和修复任务。
1.1 Kaleido 图像块生成器
以一张商品图片作为输入,并将其送入 Kaleido 图像块生成器 (KPG)。如图.下图所示,KPG 使用 了显著性检测网络去提取 前景分割图,并以前景图为依据框定主体目标。受空 间包络 (spatial envelop)以及分块策略的启发,本文探索将单张图像切分不同的尺度 (即, 1×1, 2×2, . . . , 5×5)。
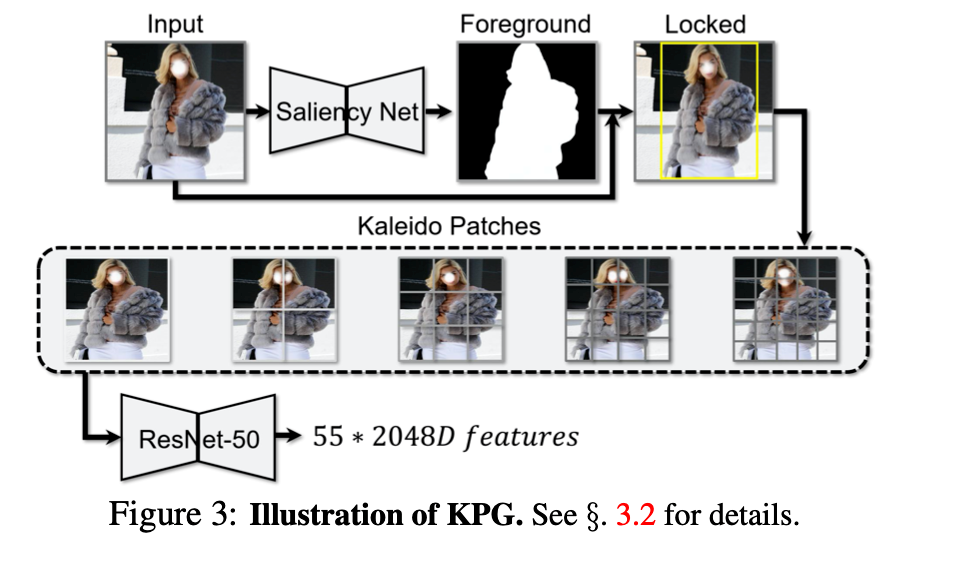
这些图像块就是“Kaleido(百变)”图像块。除此之外,也可以根据特定任务的难 度去考虑更为细致的划分 (如 6×6,或像是 Pixel- BERT的 N×N 划分)。最终,每一张图像被划 分为 55 块 Kaleido 图像块。为了生成这些图像块的 特征向量,本文采用 ResNet-50作为骨干网络 进行模型的特征提取。
1.2 注意力对齐生成器
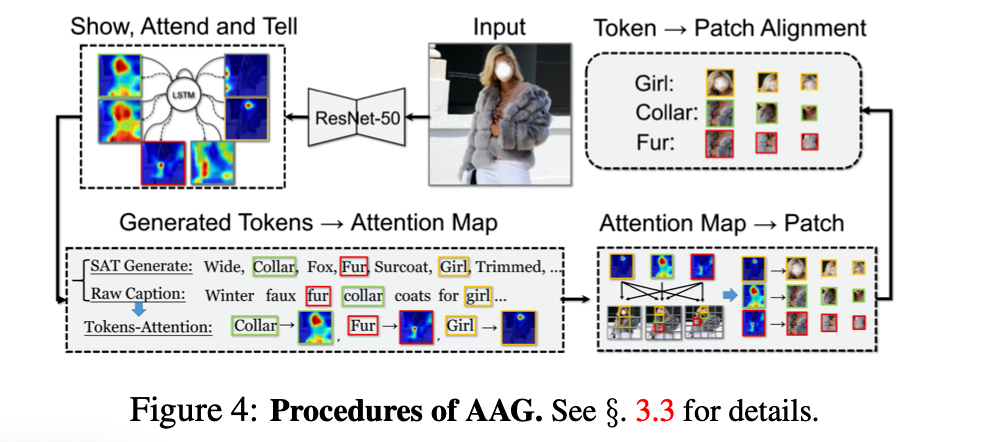
注意力对齐生成器 (AAG) 目的是产生文本词例 (token) 与 Kaleido 图像块之间的模糊对齐。如下图中, 直接使用了著名的 SAT 网络,将其在 FashionGen 数据集上重新训练。
之后,它作为文本生成器,自动描述图像的内容。在图像描述阶段,SAT 网络会对每一个词例生成注意力热图,以这些热图为依据可以推断生成的词与图像区域的关系。
若生成的描述和原本描述有共现的单词,将依照 共现单词的注意力热图来判断该单词倾向于与哪一 Kaleido 图像块关联。从而得到一部分原始描述中的单词与 Kaleido 图像块的对齐信息。
1.3 预对齐掩码策略
通过注意力对齐生成器,模型获得了关联好的 〈token, patch〉 对。虽然这些对齐信息并不十分精确,但它提供了不同模态间潜在的语义关联。至此, 可依照这些信息修改原始的随机掩码策略。
将这些信息利用到预训练阶段,它能更好地帮助 Kaleido- BERT 隐式地探索跨模态语义关系。与随机掩码策略不同,预对齐掩码策略 (AGM) 会给予更高优先级去掩码有预对齐信息的词例或图像块。当选中了某一预对齐 〈token, patch〉 进行掩码时,会随机掩码图像或文本中的其中一侧,这有利于 Kaleido-BERT 通过现有信息 (单模态保留的特征) 去推测另一模态丢失的特征。
当所有预对齐图像文本对都被遍历后,仍然出现没有足够的预对齐 图像-文本对进行预对齐掩码策略时,则重新采用随 机掩码策略补足所需要的掩码个数。通过这样的方式,得到了词例 (token) 与图像块 (patch) 的候选掩码。
AGM 策略在 Kaleido 图像块中的 3×3、4×4、 5×5 层级生效。
本文研究工作没有将掩码策略应用于 1×1、2×2 这两种尺度是因为掩码大的图像块会 增加模型的预训练难度 (且意义不大)。根据经验,本文分别在 3×3 图像块挑出 1 块,4×4 图像块挑出 2 块,5×5 图像块挑出 3 块进行掩码。
1.4 多模态 Transformer
使用原始的 BERT构建多模态 Trans- former,这使得 Kaleido-BERT 易于开发和迁移。沿用了 FashionBERT 的做法,即将词例序列 (i.e., 由 WordPieces产生) 的位置信息编码为 0,1,2,3,...,N。
在 BERT 中, 每一个文本训练语料是由其本身的词嵌入、语义特 征、位置编码特征相加而来,再接一个归一化层 (LN Layer) 生成最后的特征向量。而对于图像训练特征, 先将每一个图像块的位置信息编码成五维的特征 ([x1, x2, y1, y2, w ∗ h])。然后将图像块特征与它的位 置编码特征分别送入到一个全连接层 (FC),将它们映射到同一个维度上。
最后,采用相加通过全连接层后的特征 (i.e., FC (seg_id), FC (img_feature), FC (pos_emb))的方式,可以得到每一个图像块的视觉特征向量,最后将它们送入 LN 层。
1.5 预训练
为了缓解视觉与语言的语义隔阂,促进多模态表征学习,本文设计了三种训练任务促进预训练过 程,分别是: 预对齐掩码语言模型 (AMLM)、图文 匹配任务 (ITM) 以及提出的预对齐 Kaleido 图像块模型 (AKPM)
2.1适用任务
1. 文本检索 (ITR).
文本检索作为一种下游任务,需要模型判断一个句子是否准确地描述一张图片。
本文在 Fashion-Gen 采样了一些商品图像和标题作为图像文本对,并使用原始的产品信息作为正样本。与此同时,打乱数据集并使用不匹配的 图像文本对作为负样本。
为增加难度,正负样本均采自同样的子类目,因此它们会较难被 PTM 区分。 此外,本文使用 Rank@1, Rank@5, Rank@10 评估检索性能。
2. 图像检索 (ITR).
图像检索任务以文本描述为线索,对最相关的商品图像进行排序。
与文本检索类似,本文使用真正的商品图像文本对作为正样本,并从同子类目中的商品中随机选取 100 个不 相关的描述作为负样本。通过预测样本的匹配分数,本文依旧使用 Rank@1, @5, @10 作为评价指标。
3. 类目/子类目预测 (CR & SUB).
类目是描述商品至关重要的信息,这些信息在现实应用中非常有价值。
本文使用分类任务来进行此任务,目的是预测商品的类目和子类目,比如 {HOODIES, SWEATERS}, {TROUSERS, PANTS}。在实施过程中,直接在 [CLS] 后接一层全连接层来进行该任务。
4. 时尚描述 (FC).
图像描述生成是一项很重 要的研究话题,在计算机视觉领域中也有广泛的工作基于此展开。时尚描述的准确率可以衡量多模态模型的生成能力。
2.2 消融实验
有三个影响 Kaleido-BERT 性能表现的主要因素,它们分别在不同阶段起作用。
输入层: Kaleido 图像跨生成器 (KPG);向量层: 预对齐掩码策略 (AGM);
以及任务层: 对齐 Kaleido 图像块模型。
因此本文实施了针对这些因素的消融实验,去进一步分析这些组件/策略。实验的结果展示在表. 4和图. 7中。

关注下方《学姐带你玩AI》🚀🚀🚀
回复“预训练”获取预训练相关高分必读论文
码字不易,欢迎大家点赞评论收藏!














 1101
1101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









