










赛题目标:利用语义分割在卫星图像中识别对流尾迹
比赛链接:https://www.kaggle.com/competitions/google-research-identify-contrails-reduce-global-warming
赛题解析+baseline代码
比赛背景
凝结尾迹,简称尾迹,已经在全球变暖问题上引起了极大的关注。尾迹是在飞机发动机排气中形成的冰晶云状轨迹,特别是当飞机飞过大气中超饱和区域时。他们有一种独特而令人担忧的能力,即在大气中捕获热量,从而对全球变暖做出贡献。这种效应最初在约75年前的军用航空领域中被发现,但自那时以来,它已成为所有航空旅行的关注点。
多年来,研究人员一直在开发预测模型,以更好地理解和预测尾迹的形成,并量化它们对全球变暖的贡献。这些模型利用大量的天气数据,旨在提供一种可靠的方法来预测尾迹的发生及其对气候的影响。
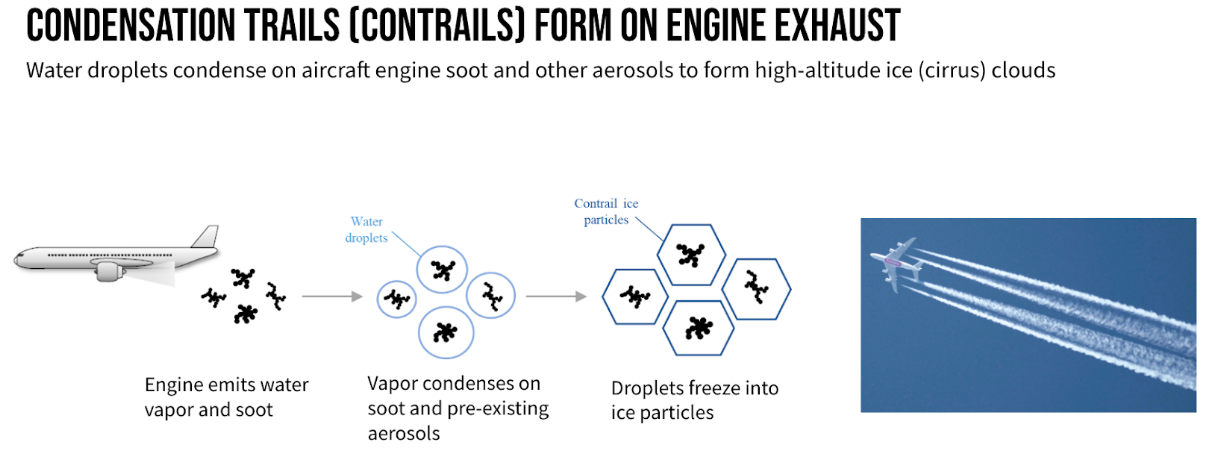
然而,要确保这些模型的可靠性和适用性,验证是至关重要的。这就是卫星图像的用途。通过将尾迹模型的预测与卫星图像显示的实际情况进行比较,研究人员可以验证模型的准确性。虽然这个验证过程很繁琐,但它对于在飞行员和更广泛的航空业中树立对模型的信心是必不可少的。
理解和减轻尾迹的产生是减少航空业对气候变化影响的重要部分。事实上,目前估计尾迹占人类造成的全球变暖的约1%。因此,航空业尽可能减少他们产生的尾迹,从而减少对全球变暖的贡献,这是一个极其重要和引人注目的方面。
通过协助验证和进一步完善这些尾迹模型,我们可以在全球共同抗击全球变暖的战斗中做出实质性的贡献。随着模型准确性的每一次提高,航空业都在减轻其对环境影响的方面更近一步,实现一种经济有效且可扩展的解决方案。
比赛任务
参赛者将需要设计并实现深度学习模型,进行精确的语义分割,从而在卫星图像中识别和定位凝结尾迹。我们鼓励使用包括但不限于ResNet、VGGNet、Inception、Xception等经典的编码器模型,以及Unet、Unet++、DeepLabv3+等高效的解码器模型。参赛者需要提交的最终模型应能精确识别并预测凝结尾迹的位置。
本次比赛旨在利用深度学习技术,特别是语义分割方法,从卫星图像中精确识别飞机的凝结尾迹。这些尾迹是飞机发动机排气形成的冰晶云状结构,它们对全球气候变化的影响不容忽视。因此,通过深度学习技术对卫星图像进行语义分割,能够更准确地研究、预测凝结尾迹的形成以及它们对全球变暖的贡献。
评价指标
本次比赛的指标为global Dice coefficient
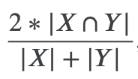
X表示测试数据中所有预测出的尾迹像素的整个集合,而Y则表示测试数据中所有真实的尾迹像素的集合。Dice系数的最大分数为1,这表示预测出的二值掩膜与真实的二值掩膜之间有完美的重叠。
‣ 比赛格式要求一个以空格分隔的配对列表。例如,'1 3 10 5' 表示像素1,2,3,10,11,12,13,14应该被包含在掩膜中。度量标准会检查这些配对是否被排序、为正数,以及解码后的像素值是否没有重复。像素从上至下、从左至右编号:1是像素(1,1),2是像素(2,1),等等。
数据描述
这个比赛的数据集来自GOES-16高级基线成像仪(ABI),该数据在Google Cloud Storage上公开提供。我们的任务是使用静止卫星图像来识别航空尾迹。
‣ 原始的全盘图像通过双线性重采样进行重新投影,生成一个局部场景图像。由于尾迹在时间上下文中更容易识别,所以提供了间隔10分钟的一系列图像。每个例子(记录id)包含恰好一个带标签的帧。
‣ 可以从预印本《OpenContrails:对GOES-16 ABI上的尾迹检测进行基准测试》了解更多关于数据集的信息。
‣ 标记指南可以在这份补充材料中找到,一些关键的标记指导如下:
-
尾迹必须包含至少10个像素;
-
在其生命周期中,尾迹的长度至少要是其宽度的3倍;
-
尾迹必须要么突然出现,要么从图像的边缘进入;
-
尾迹应该在至少两张图像中可见。
‣ 基本上有4个或更多不同的标注者对每张图像进行标注以确定真实情况。当超过50%的标注者将其标注为尾迹时,像素被认为是尾迹。训练数据中包括了单个的标注(human_individual_masks.npy)以及汇总的真实标注(human_pixel_masks.npy)。验证数据只包含汇总的真实标注。
-
train/ - 训练集;每个文件夹代表一个记录id,并包含以下数据: -
band_{08-16}.npy:大小为H x W x T的数组,其中T = n_times_before + n_times_after + 1,表示序列中的图像数量。在标记的帧之前和之后分别有n_times_before和n_times_after图像。在我们的数据集中,所有的样例都有n_times_before=4和n_times_after=3。每个频段代表不同波长的红外频道,并基于校准参数转换为亮度温度。文件名中的数字对应GOES-16 ABI带号。ABI带的详情可以在这里找到。 -
human_individual_masks.npy:大小为H x W x 1 x R的数组。每个样例由R个单独的人工标记者标记。R对于所有样品不同。标记的遮罩值为0或1,对应于band_{08-16}.npy中的(n_times_before+1) -th图像。它们只在训练集中提供。 -
human_pixel_masks.npy:大小为H x W x 1的数组,包含二值化的地面真实值。如果被超过一半的标签器标记为尾迹,则在评估中像素被视为尾迹像素。 -
validation/- 和训练集一样,但没有个体标签注释;如果需要,可以将此用作训练数据。 -
test/ - 测试集;你的目标是在这些记录中识别出尾迹。注意:因为这是一个代码比赛,你不能访问你的笔记本会重新运行的实际测试集。这里显示的记录是验证数据的前两个记录的副本(没有标签)。隐藏的测试集的大小大约和验证集一样(±5%)。重要提示:提交应该使用游程编码,没有预测(例如,没有尾迹)的地方应该在提交中标记为'-'。(参见此笔记本了解详情。) -
{train|validation}_metadata.json- 每个记录的元数据信息;包含时间戳和复现卫星图像的投影参数。 -
sample_submission.csv- 一个正确格式的样本提交文件。
代码讲解
-
定义了一个深度学习模型的配置。
-
创建了一个自定义的PyTorch数据集,用于读取和预处理尾迹图像,同时处理图像的归一化和尺寸调整。
-
制定了一个PyTorch Lightning模块,包括模型架构、损失函数、优化器和学习率调度器,同时详细说明了训练和验证步骤。
-
创建了训练和验证集的DataLoaders,设置了检查点、提前停止和进度条的回调,并初始化了模型和PyTorch Lightning训练器,然后使用该训练器对模型进行训练。
-
设定了一个自定义测试数据集用于处理测试图像,并为测试集创建了一个DataLoader。
-
定义了执行行程长度编码和将列表转换为字符串的函数,这些函数用于创建最终的提交。
-
对测试DataLoader进行迭代,为每一批图像做出预测,对预测的掩码应用阈值,并将预测的掩码转换为用于提交的行程长度编码。
-
利用ContrailsDataset类进行训练/验证和测试,但在使用中存在细微差别。对于训练/验证,该类使用数据帧的尾迹路径和标签,对于测试,它直接读取记录数据并返回图像ID。
LightningModule类使用的是带有ResNeSt26D编码器的UNet模型,搭配Dice损失函数。优化器采用AdamW,学习率调度器根据配置,可以是CosineAnnealingLR或ReduceLROnPlateau。
在训练结束后,模型会对测试集进行预测,对预测的掩码进行阈值处理,然后使用行程长度编码将预测的掩码转换为需要的提交格式。
完整baseline代码获取看这里👇
关注下方【学姐带你玩AI】🚀🚀🚀
回复“飞机”获取完整baseline代码
码字不易,欢迎大家点赞评论收藏!















 2216
2216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









