






前阵子,SAM+多模态迎来了新突破,字节、北大联合提出了市面上第一个结合SAM2和LLaVA的多模态大模型,在视频编辑和内容创作等任务中实现了SOTA性能。
实际上,这方向的研究热度一直在爆发式增长,去年CVPR/ICML/NeurIPS等顶会中相关论文占比近1/3,今年的CVPR 2025上,SAM+多模态更是火热(比如实现了视觉与任务统一的SAGE方法),无疑是发论文的好选择。
如果感兴趣,建议同学们抓紧上手,SAM+多模态现在仍处于技术红利期,可以多关注跨学科交叉(比如生物医学+量子计算+SAM),以及产业界真实需求(比如特斯拉FSD v13已集成定制化SAM模块)。
本文整理了10篇SAM+多模态2025新论文,基本都有代码,方便需要参考的同学找idea,如果觉得有用记得点赞支持下哦~
全部论文+开源代码需要的同学看文末
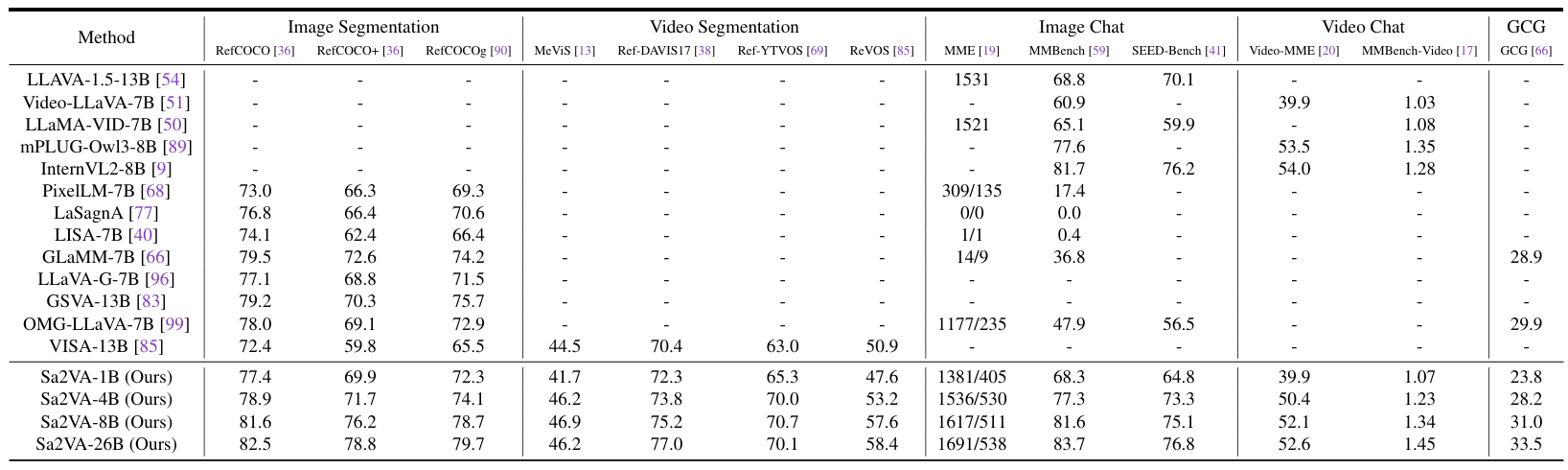
Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos
方法:论文提出Sa2VA模型,将SAM-2(视频分割模型)与LLaVA(视觉语言模型)结合,通过LLM生成指令标记,指导SAM-2进行精准分割,实现图像和视频的多模态密集理解。
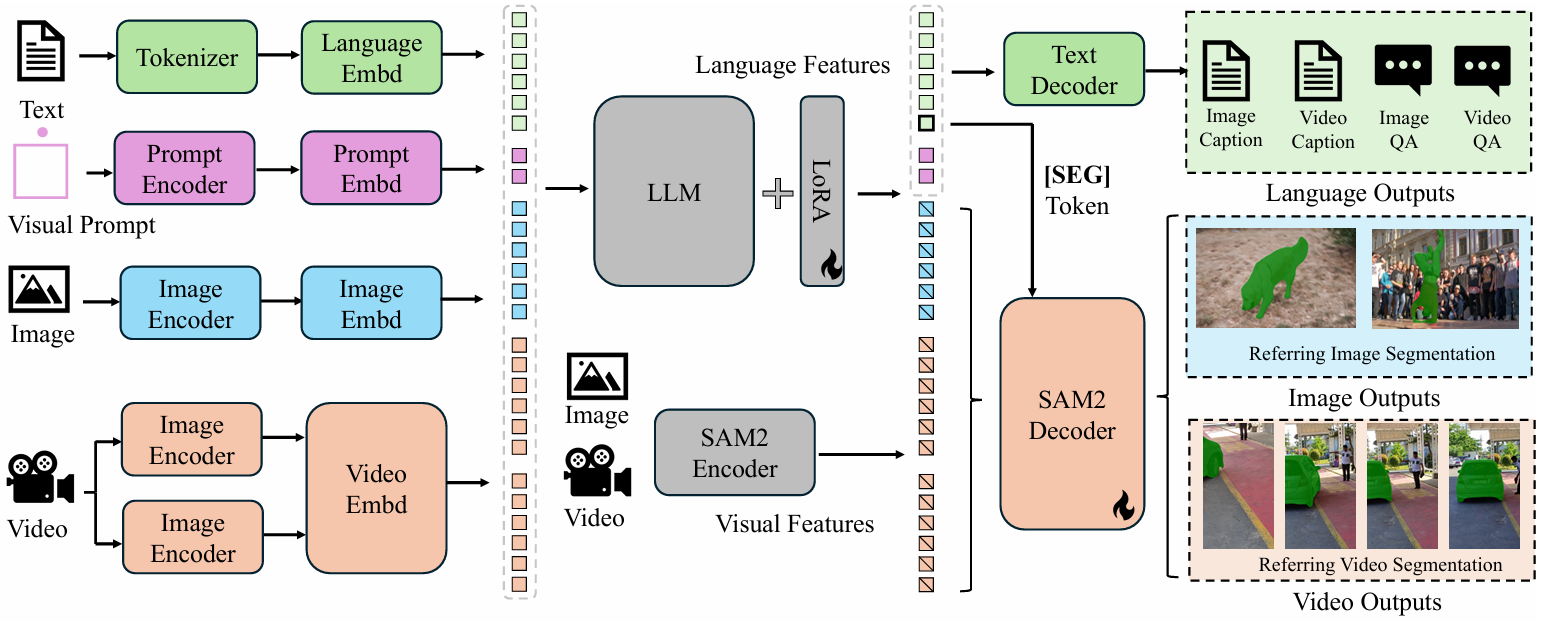
创新点:
-
提出Sa2VA模型,将SAM-2和LLaVA结合,实现图像和视频的统一多模态理解。
-
将多种任务(如分割、对话、问答)统一为单次指令调优,通过LLM处理视觉标记。
-
创建Ref-SAV数据集,包含72k复杂视频场景的对象表达,用于提升模型性能并作为新的基准。
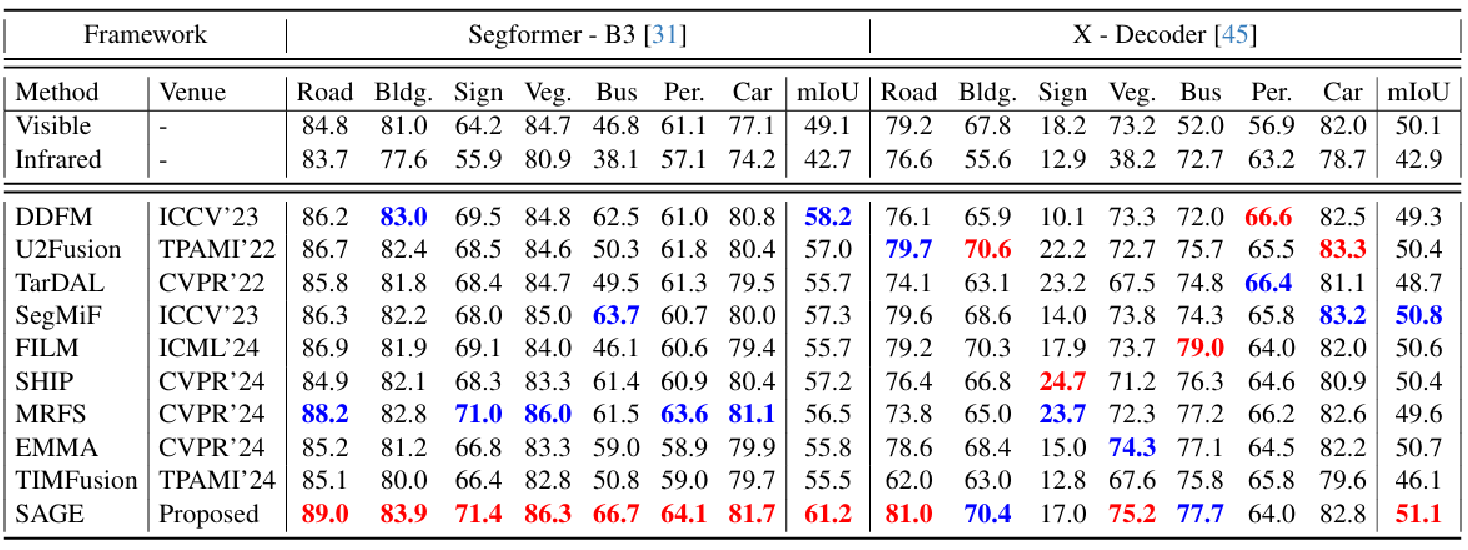
Every SAM Drop Counts: Embracing Semantic Priors for Multi-Modality Image Fusion and Beyond
方法:论文提出了一种基于SAM的多模态图像融合方法,通过语义持久注意力模块和双层优化蒸馏机制,高效融合红外与可见光图像,在提升视觉质量的同时增强对下游任务的适应性,摆脱了对SAM的依赖,提高了部署效率。
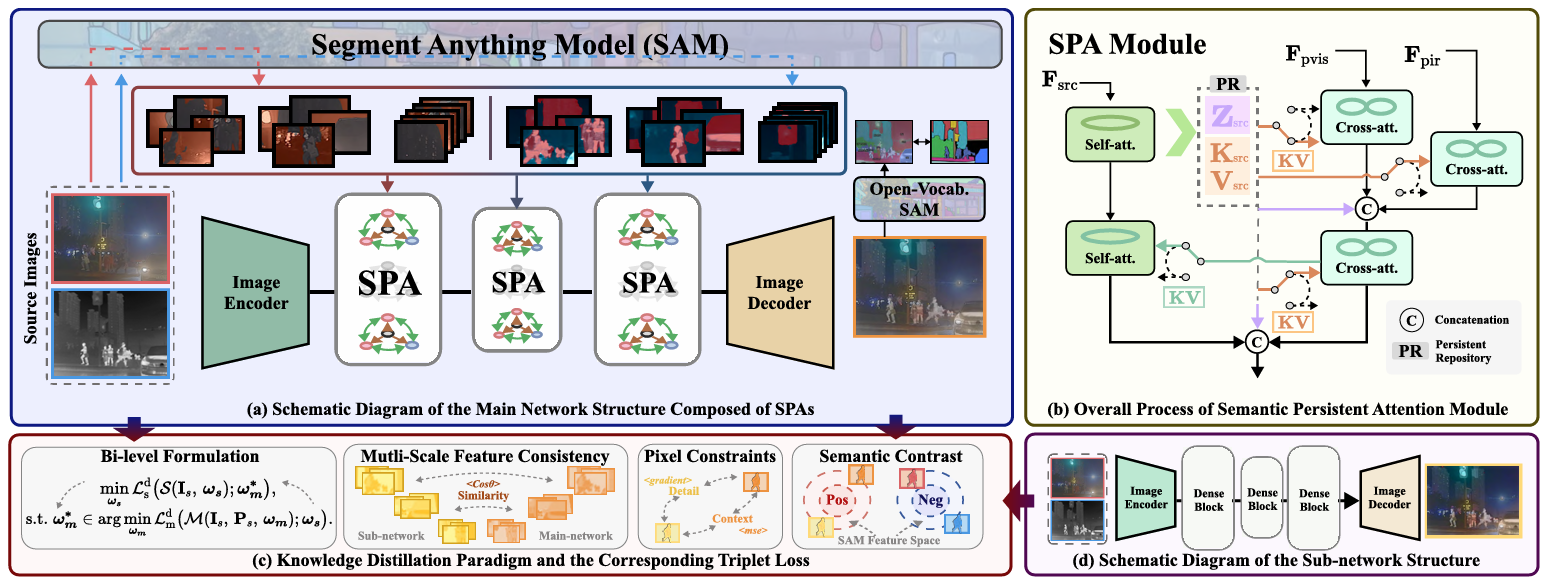
创新点:
-
设计了语义持久注意力(SPA)模块,高效整合语义信息,保留源图像细节。
-
提出双层优化蒸馏机制,摆脱对SAM的依赖,降低计算负担。
-
平衡视觉效果与下游任务性能,提升实际应用效率。
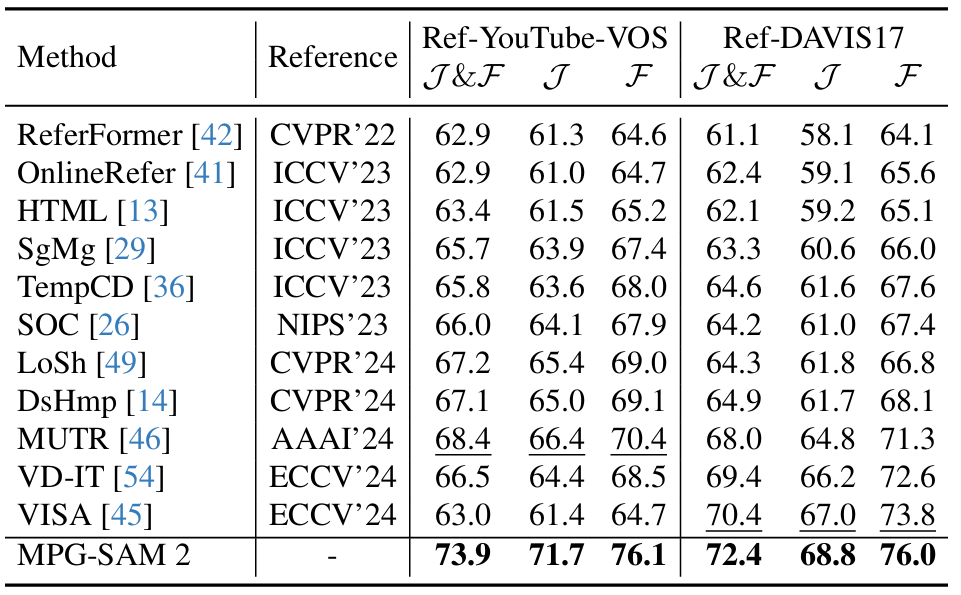
MPG-SAM2: Adapting SAM 2 with Mask Priors and Global Context for Referring Video Object Segmentation
方法:论文提出了一种名为MPG-SAM 2的框架,用于视频目标分割。该模型通过多模态编码器整合视频和文本信息,生成伪掩码和全局上下文,提升SAM 2在视频目标分割中的性能。
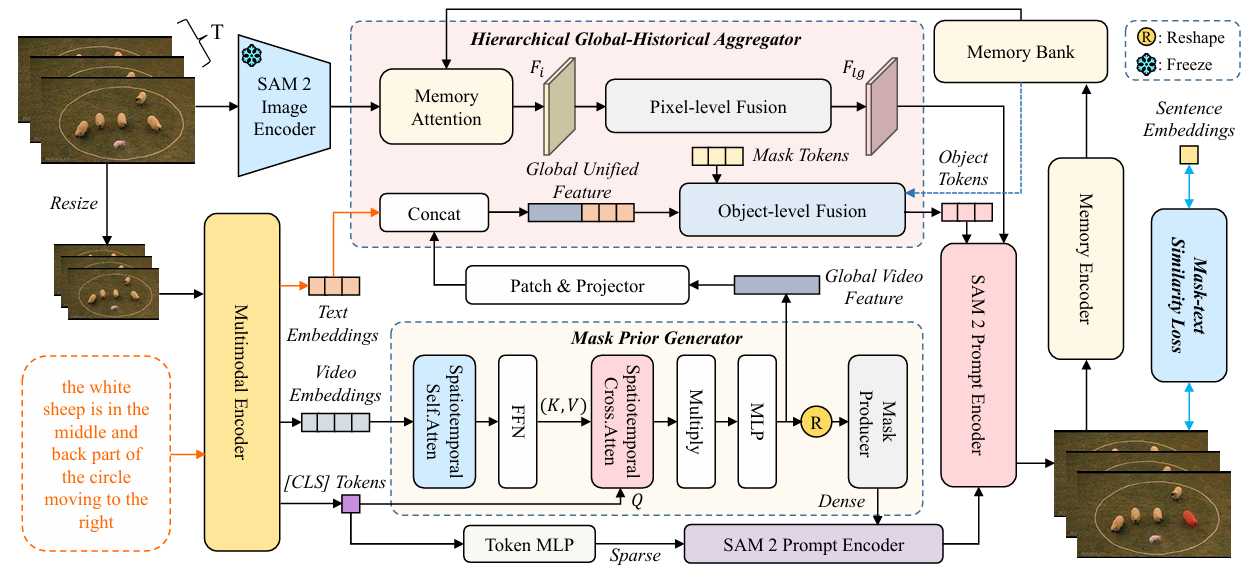
创新点:
-
提出MPG-SAM 2框架,用多模态编码器联合编码视频和文本特征。
-
设计掩码先验生成器,为SAM 2生成目标对象的伪掩码作为密集提示。
-
引入层次化全局-历史聚合器,增强目标表示和时间一致性。
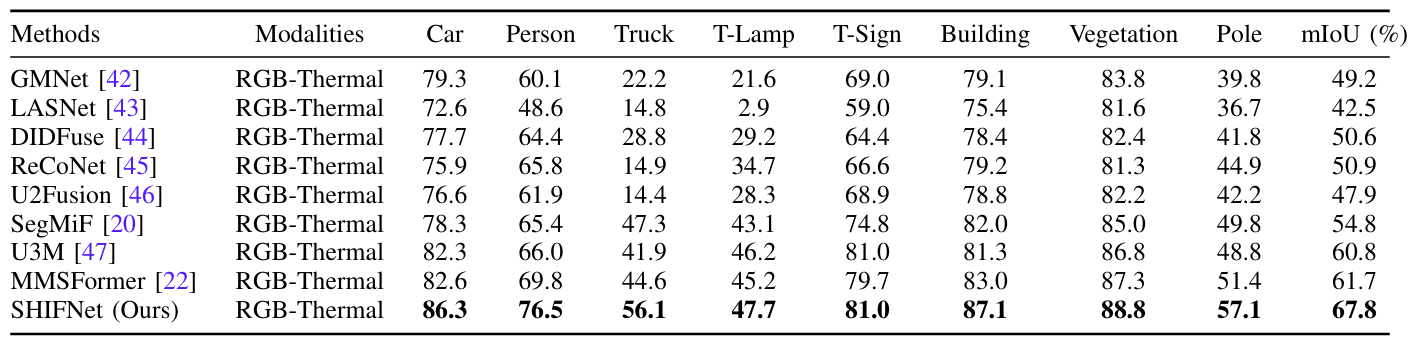
Unveiling the Potential of Segment Anything Model 2 for RGB-Thermal Semantic Segmentation with Language Guidance
方法:论文提出SHIFNet框架,通过语言引导的跨模态融合和语义增强模块,优化SAM2在RGB-T语义分割中的性能。SACF动态调RGB与热成像融合权重,克服RGB偏好;HPD用全局语义信息和类别嵌入提分割精度。
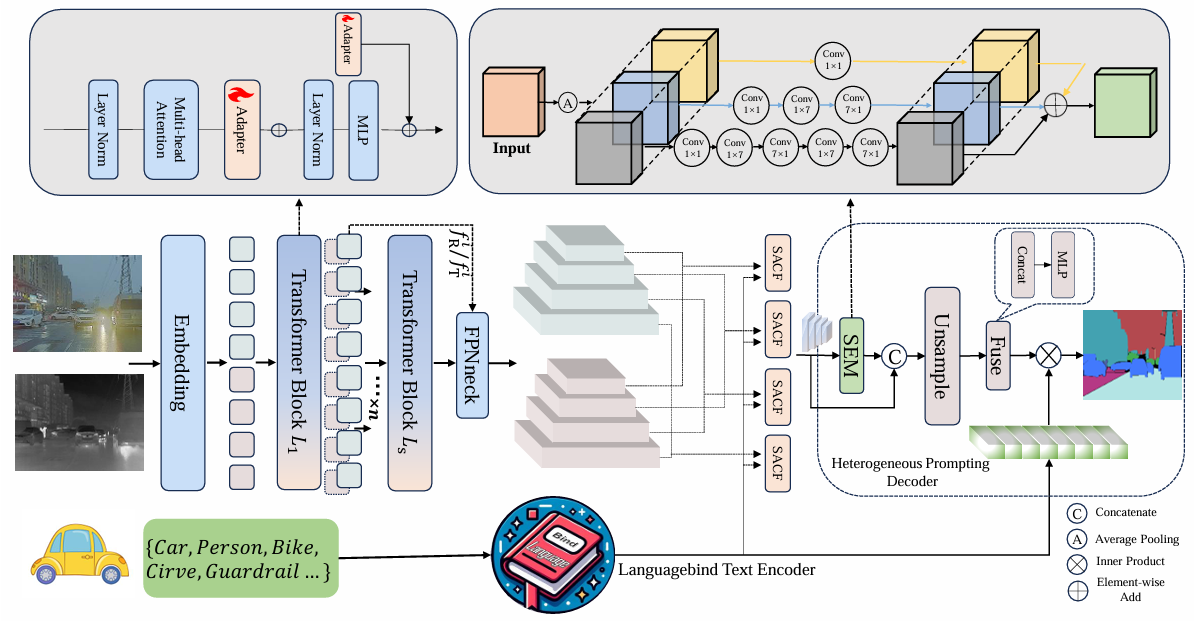
创新点:
-
提出SHIFNet框架,通过语言引导解锁SAM2在RGB-Thermal语义分割中的潜力,解决其多模态分割中的模态偏好问题。
-
设计SACF模块,利用文本信息动态调整RGB和热成像特征的融合权重,克服SAM2的RGB偏置。
-
提出HPD模块,整合全局语义信息并利用类别嵌入优化特征,提升跨模态语义一致性。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“222”获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏

















 1179
1179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









