







一、GAN的发展史
目录
7.Age-cGAN(Age Conditional Generative Adversarial Networks)
诞生
生成器网络将来自潜在空间的随机噪声矢量(不是来自潜在空间的所有GAN样本)变换为真实数据集的样本。
GAN具有大量的实际用例,如图像生成,艺术品生成,音乐生成和视频生成。此外,它还可以提高图像质量,图像风格化或着色,面部生成以及其他更多有趣的任务。
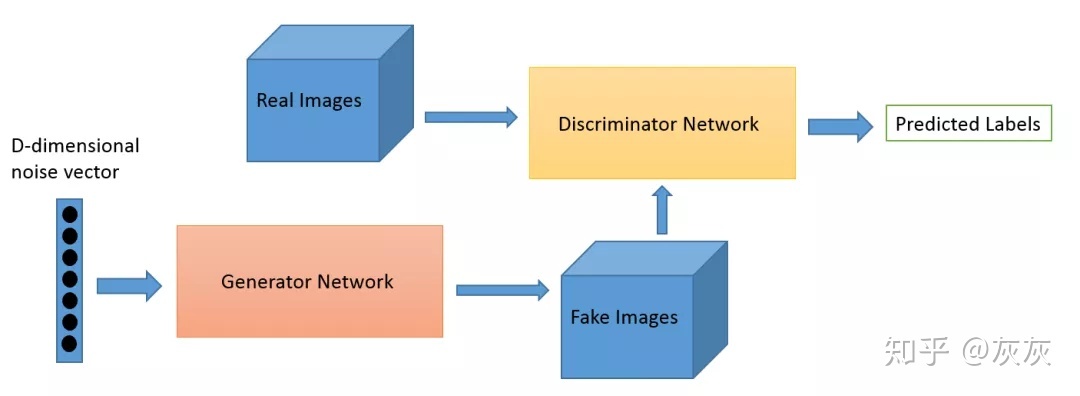
上图表示了一般的GAN网络的架构。
- 首先,从潜在空间采样D维的噪声矢量并发送到生成器网络。
- 生成器网络将该噪声矢量转换为图像。
- 然后将生成的图像发送到鉴别器网络以进行分类。
- 鉴别器网络不断地从真实数据集和由发生器网络生成的图像获得图像,它的工作是区分真实和虚假的图像。
所有GAN架构都遵循这样的设计。
青春期
在青春期,GAN产生了许多流行的架构,如DCGAN,StyleGAN,BigGAN,StackGAN,Pix2pix,Age-cGAN,CycleGAN等。这些结构的结果都非常令人满意。下面详细讨论这些GAN架构。
1.DCGAN
这是第一次在GAN中使用卷积神经网络并取得了非常好的结果。之前,CNN在计算机视觉方面取得了前所未有的成果。但在GAN中还没有开始应用CNNs。Alec Radford,Luke Metz,Soumith Chintala等人“Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks”提出了DCGAN。这是GAN研究的一个重要里程碑,因为它提出了一个重要的架构变化来解决训练不稳定,模式崩溃和内部协变量转换等问题。从那时起,基于DCGAN的架构就被应用到了许多GAN架构。

2.BigGAN
一个谷歌的实习生和谷歌DeepMind部门的两名研究人员发表了一篇“Large Scale GAN Training for High Fidelity Natural Image Synthesis”的论文。本文是来自Heriot-Watt大学的Andrew Brock与来自DeepMind的Jeff Donahue和Karen Simonyan合作的实习项目。

这些图像都是由BigGAN生成,正如你看到的,图像的质量足以以假乱真。这是GAN首次生成具有高保真度和低品种差距的图像。之前的最高初始得分为52.52,BigGAN的初始得分为166.3,比现有技术(SOTA)好100%。此外,他们将Frechet初始距离(FID)得分从18.65提高到9.6。这些都是非常令人印象深刻的结果。它最重要的改进是对生成器的正交正则化。

3.StyleGAN
StyleGAN是GAN研究领域的另一项重大突破。StyleGAN由Nvidia在题为“A Style-Based Generator Architecture for Generative Adversarial Network”的论文中介绍。

来源:https://http://medium.com/syncedreview/gan-2-0-nvidias-hyperrealistic-face-generator-e3439d33ebaf
StyleGAN在面部生成任务中创造了新记录。算法的核心是风格转移技术或风格混合。除了生成面部外,它还可以生成高质量的汽车,卧室等图像。这是GANs领域的另一项重大改进,也是深度学习研究人员的灵感来源。
4.StackGAN
StackJANs由Han Zhang,Tao Xu,Hongsheng Li还有其他人在题为StackGAN: Text to Photo-Realistic Image Synthesis with Stacked Generative Adversarial Networks的论文中提出。他们使用StackGAN来探索文本到图像的合成,得到了非常好的结果。一个StackGAN由一对网络组成,当提供文本描述时,可以生成逼真的图像。

正如上图所看到的,提供文本描述时,StackGAN生成了逼真的鸟类图像。最重要的是生成的图像正类似于所提供的文本。文本到图像合成有许多实际应用,例如从一段文本描述中生成图像,将文本形式的故事转换为漫画,创建文本描述的内部表现。
语意 – 图像 – 照片 的转换
在2017年标题为“ 高分辨率图像合成和带条件GAN的语义操纵 ”的论文中,演示了在语义图像或草图作为输入的情况下使用条件GAN生成逼真图像。

5.CycleGAN
CycleGAN有一些非常有趣的用例,例如将照片转换为绘画,将夏季拍摄的照片转换为冬季拍摄的照片,或将马的照片转换为斑马照片,或者相反。CycleGANs 由Jun-Yan Zhu,Taesung Park,Phillip Isola和Alexei A. Efros在题为“Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks”的论文中提出。CycleGAN用于不同的图像到图像翻译。

6.Pix2pix
对于图像到图像的翻译任务,pix2pix也显示出了令人印象深刻的结果。无论是将夜间图像转换为白天的图像还是给黑白图像着色,或者将草图转换为逼真的照片等等,Pix2pix在这些例子中都表现非常出色。pix2pix网络由Phillip Isola,Jun-Yan Zhu,Tinghui Zhou和Alexei A. Efros在他们的题为“Image-to-Image Translation with Conditional Adversarial Networks”的论文中提出。
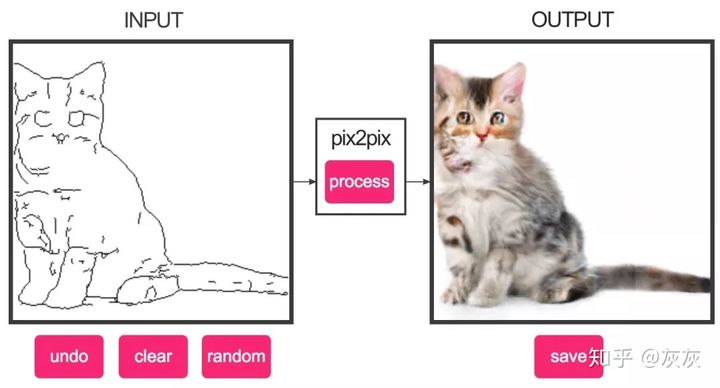
这是一个交互式的演示,能够从草图生成真实图像。
7.Age-cGAN(Age Conditional Generative Adversarial Networks)
面部老化有许多行业用例,包括跨年龄人脸识别,寻找失踪儿童,或者用于娱乐。Grigory Antipov,Moez Baccouche和Jean-Luc Dugelay在他们的题为“Face Aging with Conditional Generative Adversarial Networks”的论文中提出了用条件GAN进行面部老化。

该图显示了Age-cGAN是怎样从原来的年龄转换为目标年龄的。
这些都是非常流行的GAN架构。除了这些,还有数以千计的GAN架构。这取决于哪种架构适合您的需求。
8.提高照片分辨率,让照片更清晰
给GANs 一张照片,他就能生成一张分辨率更高的照片,使得这个照片更加清晰。

9.照片修复
假如照片中有一个区域出现了问题(例如被涂上颜色或者被抹去),GANs可以修复这个区域,还原成原始的状态。

10.自动生成3D模型
给出多个不同角度的2D图像,就可以生成一个3D模型。

11.自动生成模特
在2017年标题为“ 姿势引导人形象生成 ”的论文中,可以自动生成人体模特,并且使用新的姿势。

12.照片到Emojis
GANs 可以通过人脸照片自动生成对应的表情(Emojis)。

13.照片编辑
使用GANs可以生成特定的照片,例如更换头发颜色、更改面部表情、甚至是改变性别。
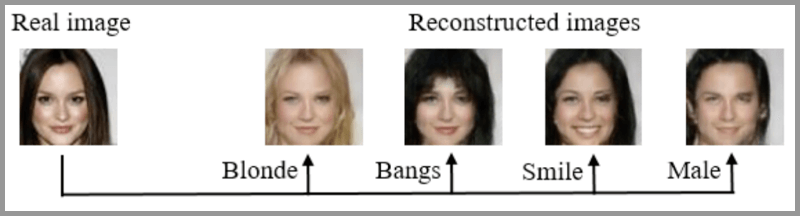
14.预测不同年龄的长相
给一张人脸照片, GANs 就可以帮你预测不同年龄阶段你会长成什么样。

Edmond de Belamy
由GAN创作的Edmond de Belamy在佳士得拍卖会上以432,500美元的价格成交。这是GAN发展的重要一步,全世界第一次目睹了GAN及其潜力。在此之前,GAN主要局限于研究实验室,并由机器学习工程师使用。这一行为使GAN成为面向公众的一个入口。

这个人并不存在
您可能会熟悉 https://thispersondoesnotexist.com 这个网站。它是由优步的软件工程师Philip Wan创建。他根据NVIDIA发布的名为StyleGAN的代码创建了这个网站。每当你刷新时,它都会生成一个新的不存在的人脸,看起来无法判断它是否是假的。这项技术有可能创造一个完全的虚拟世界。

Deep Fakes
DeepFakes是另一个可怕的具有破坏性的技术。基于GAN,可以将人脸粘贴到视频中的目标人物上。人们找到这项技术的缺点,但对于AI研究人员来说,这是一个重大突破。这项技术有可能在电影行业节省数百万美元,在那里需要数小时的编辑来改变面对的特技演员。
这项技术很可怕,但我们也可以把他用在对社会好的一面。
未来发展
StyleGAN目前是GitHub上第六热门的python项目。到目前为止提出的GAN的数量已经达到了数千。这个GitHub仓库有一个受欢迎的GAN列表及论文:https://github.com/hindupuravinash/the-gan-zoo
现在
GAN已被用于增强游戏图形。我对GAN的这种用例感到非常兴奋。最近,NVIDIA发布了一个视频,其中展示了如何使用GAN对视频中的环境进行游戏化。
参考:https://zhuanlan.zhihu.com/p/63428113
二、StyleGAN的发展史
StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets(2022)
https://sites.google.com/view/stylegan-xl/
StyleGAN3 (2021)
- Project page: Alias-Free Generative Adversarial Networks (StyleGAN3)
- ArXiv: https://arxiv.org/abs/2106.12423
- PyTorch implementation: GitHub - NVlabs/stylegan3: Official PyTorch implementation of StyleGAN3
StyleGAN2-ADA (2020)
- ArXiv: https://arxiv.org/abs/2006.06676
- PyTorch implementation: GitHub - NVlabs/stylegan2-ada-pytorch: StyleGAN2-ADA - Official PyTorch implementation
- TensorFlow implementation: GitHub - NVlabs/stylegan2-ada: StyleGAN2 with adaptive discriminator augmentation (ADA) - Official TensorFlow implementation
- MetFaces dataset: GitHub - NVlabs/metfaces-dataset
StyleGAN2 (2019)
- ArXiv: https://arxiv.org/abs/1912.04958
- Video: https://youtu.be/c-NJtV9Jvp0
- TensorFlow implementation: GitHub - NVlabs/stylegan2: StyleGAN2 - Official TensorFlow Implementation
StyleGAN (2018)
- ArXiv: https://arxiv.org/abs/1812.04948
- Video: https://youtu.be/kSLJriaOumA
- TensorFlow implementation: GitHub - NVlabs/stylegan: StyleGAN - Official TensorFlow Implementation
- FFHQ dataset: GitHub - NVlabs/ffhq-dataset: Flickr-Faces-HQ Dataset (FFHQ)
Progressive GAN (2017)
- ArXiv: https://arxiv.org/abs/1710.10196
- Video: https://youtu.be/G06dEcZ-QTg
- TensorFlow implementation:
GitHub - tkarras/progressive_growing_of_gans: Progressive Growing of GANs for Improved Quality, Stability, and Variation - Theano implementation:
GitHub - tkarras/progressive_growing_of_gans at original-theano-version - CelebA-HQ dataset:
GitHub - tkarras/progressive_growing_of_gans: Progressive Growing of GANs for Improved Quality, Stability, and Variation
我有见到有人使用 Progressive GAN生成分子图像:https://towardsdatascience.com/molecule-synthesis-using-ai-10e0e1f89568
StyleGAN (2018)
A Style-Based Generator Architecture for Generative Adversarial Networks(基于风格的生成对抗网络生成器体系结构)
StyleGAN是当时最先进的高分辨率图像合成方法,已被证明可以在各种数据集上可靠地工作。除了逼真的人像,StyleGAN还可以用于生成其他动物,汽车甚至房间。
并且它也可以控制生成的人脸的风格(控制头发、眼睛...)
StyleGAN2 (2019):
Analyzing and Improving the Image Quality of StyleGAN(优化和提升StyleGAN的图像质量)
主要改进包括:(着重处理的伪影问题)
- 生成的图像质量明显更好(FID分数更高、artifacts减少)
- 提出替代progressive growing的新方法,牙齿、眼睛等细节更完美
- 改善了Style-mixing
- 更平滑的插值(额外的正则化)
- 训练速度更快
StyleGAN2-ADA (2020):
Training Generative Adversarial Networks with Limited Data(用有限的数据训练生成对抗网络)
StyleGAN、StyleGAN2的生成效果非常好,很大原因是有强大的数据集,比如生成的高清人脸训练集有14w张(FFHQ有7w张,图像翻转x2就是14w张)。大规模的数据集一般情况下很难采集,但是小数据集会导致模型过拟合,为了解决过拟合,可以在训练的时候对数据进行图像增强,比如随机裁剪、水平翻转、加噪声、一定范围内改变色调等。但是,数据增强会导致生成图片也有对应的增强,比如对原图加入了噪声,会导致生成图片也有噪声,这是我们不期望看到的。如何让小数据集的数据增强不出现在生成结果中呢?
这篇论文提出了stylegan2-ada方法。ada全称是adaptive discriminator augmentation,解决了需要训练的数据量大,以及使用数据增强后生成的图像带有噪声的问题
StyleGAN3 (2021)
Alias-Free Generative Adversarial Networks(Alias-Free生成对抗网络)
在GAN的合成过程中,某些特征依赖于绝对像素坐标,这会导致:【细节似乎粘在图像坐标上,而不是所要生成对象的表面】,而stylegan3从根本上解决了stylegan2图像坐标与特征粘连的问题,实现了真正的图像平移、旋转等不变性,大幅度提高了图像合成质量。

通过上图可以看出来stylegan2生成的毛发等细节会粘在屏幕上,和人物的形态变化不一致。



















 1157
1157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











