







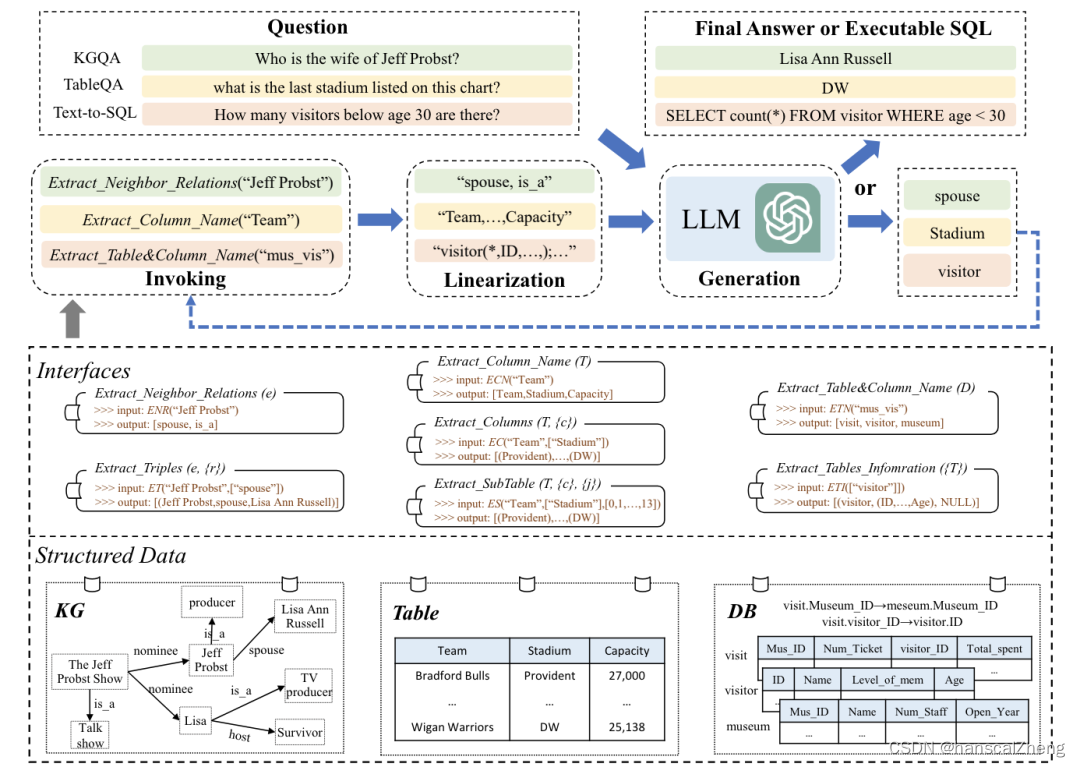
StructGPT旨在研究如何在大型语言模型中统一提高其在结构化数据上的零样本推理能力。其通过使用迭代阅读-推理(IRR)的方式来解决基于结构化数据的问答任务,提出的IRR的方法可以通过构建专门的函数从结构化数据中收集相关证据(即“阅读”),并让大型语言模型集中推理任务,以收集的信息为基础进行推理(即“推理”)。
1 迭代阅读推理(IRR)
StructGPT的主要创新在于其统一的框架设计,使得LLM可以在多种结构化数据类型上进行推理,而无需为每种数据类型单独设计解决方案。此框架基于“工具增强”策略,通过专门设计的接口,来解决基于结构化数据的问题。StructGPT将不同类型的结构化数据(如表格、知识图谱和数据库)视为黑箱系统,通过设计适当的接口来获取所需信息。通过这些接口可以获取表格和列名、列内容、子表等,以及知识图谱中的邻近关系和三元组信息。
2 调用-线性化-生成
论文中还利用了一种“调用-线性化-生成”(invoking-linearization-generation)过程,以帮助大型语言模型在外部接口的帮助下推理结构化数据。在每次迭代中,StructGPT首先调用一个接口从结构化数据中提取相关信息,然后将这些信息转化为文本提示,输入到LLM中生成答案或可执行的SQL查询。通过迭代上述过程,StructGPT逐步收集和处理相关证据,利用LLM的推理能力,最终生成接近问题的目标答案。
3 结语
StructGPT试图统一大语言模型在结构化数据上的零样本推理过程。其利用迭代阅读-推理(IRR)的方式来解决基于结构化数据的问答任务,并取得了一定的效果。
论文地址:https://arxiv.org/pdf/2305.09645.pdf
GitHub地址:https://github.com/RUCAIBox/StructGPT
PS: 欢迎大家扫码关注公众号_,我们一起在AI的世界中探索前行,期待共同进步!


















 778
778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









