






摘要
知识蒸馏在学习目标检测中的紧凑模型方面表现出强大的能力。以往用于目标检测的KD方法主要集中在模仿区域内的深层特征,而不是模仿分类logit,因为它在提取定位信息方面效率低下,改进较小。在本文中,通过重新表述定位的知识蒸馏过程,提出了一种新的定位蒸馏(LD)方法,该方法可以有效地将定位知识从教师传递给学生。此外,我们还启发性地引入了有价值的定位区域的概念,该概念可以帮助选择性地提取特定区域的语义和定位知识。结合这两个新的组成部分,我们首次证明了logit模仿可以优于特征模仿,并且对于提取对象检测器,定位知识蒸馏比语义更重要。
1、介绍
定位是目标检测中的一个基本问题。边界盒回归是迄今为止目标检测中最流行的定位方式,其中Dirac delta分布表示直观且流行多年。然而,定位模糊性仍然是一个常见的问题,即物体不能通过其边缘可靠地定位。例如,有些图片中的物体边缘定位不明确。对于轻量型检测器来说,这个问题更糟糕。缓解这一问题的方法是知识蒸馏(KD),它作为一种模型压缩技术,已被广泛验证为通过转移大型教师网络捕获的广义知识来提高小型学生网络的性能。
谈到目标检测中的KD,以前的工作已经指出,用于分类的原始logit蒸馏技术效率低下,因为它只传递语义知识(即分类),而忽略了定位知识蒸馏的重要性。因此,现有的目标检测的KD方法大多侧重于增强师生之间深层特征的一致性,并利用各种模仿区域进行蒸馏。下图展示了用于目标检测的三个流行的KD结构。然而,由于语义知识和定位知识在特征图上是混合的,很难判断为每个位置传递混合知识是否有利于性能,以及哪些区域有利于某种类型知识的传递。
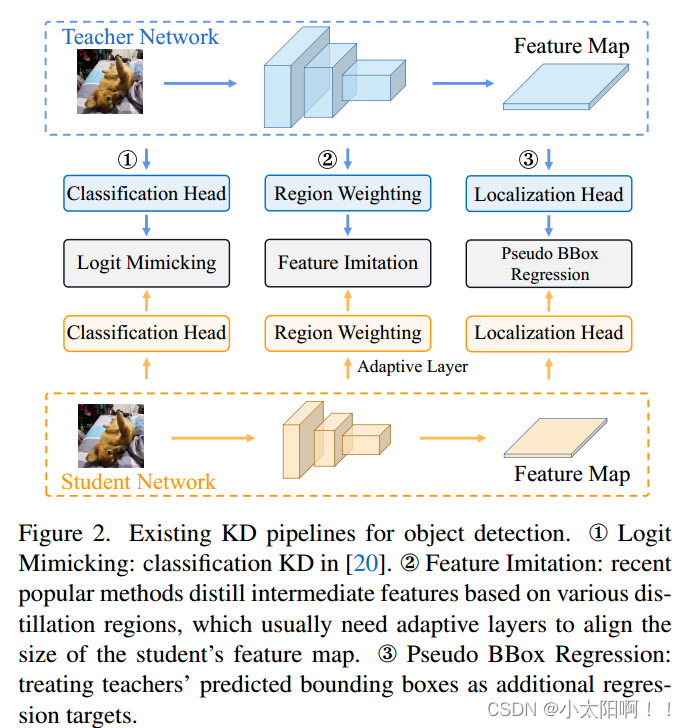
受上述问题的启发,本文提出了一种新的分而治之的提取策略,该策略将语义知识和定位知识分别转移,而不是简单地提取特征图上的混合知识。对于语义知识,我们使用原始的分类KD。对于定位知识,我们重新表述了定位的知识转移过程,并通过将边界框切换到概率分布,提出了一种简单而有效的定位蒸馏(LD)方法。这与之前的工作截然不同,之前的工作把教师的输出视为额外的回归目标(如上图中的BBox回归)。得益于概率分布表示,我们的LD可以有效地将教师学到的丰富的回归知识传递给学生。此外,在所提出的分治蒸馏策略的基础上,我们进一步引入了有价值的定位区域(VLR),以帮助有效地判断哪些区域有利于分类或定位学习。通过一系列实验,我们首次证明了原始logit模仿可以比特征模仿更好,并且定位知识提取比语义知识更重要、更有效。我们认为,基于各自的有利区域分别提取语义和定位知识可能是训练更好的目标检测器的一种很有前途的方法。
2、方法
在本节中,我们将介绍所提出的蒸馏方法。我们提出了一种新的分而治之的蒸馏策略,该策略基于语义和定位知识各自的偏好区域提取它们,而不是提取特征图上的混合知识。为了转移语义知识,我们简单地在分类头上采用分类KD,而对于定位知识,提出了一种简单而有效的定位蒸馏(LD)。这两种技术都是基于单个头部的logit,而不是深层特征。然而,为了进一步提高蒸馏效率,我们引入了有价值的定位区域(VLR),它可以帮助判断哪种类型的知识有利于不同区域的转移。
2.1 Preliminaries
对于给定的边界框B,传统表示有两种形式,即{x,y,w,h}(中心点坐标、宽度和高度)和{t,b,l,r}(从采样点到顶部、底部、左侧和右侧边缘的距离)。这两种形式来自Dirac delta分布,它只关注ground-truth位置,但不能对边界框的模糊性进行建模。这在以前的工作中也得到了明确的证明。
在我们的方法中,我们使用了最近的边界框的概率分布表示,它更全面地描述了边界框的定位不确定性。设是一个边界框的边。其值通常可以表示为:
x是以为单位的回归坐标,Pr(x)是相应的概率。传统的Dirac delta表示是上述等式的一个特例,其中当
时,
,否则
,通过将连续回归范围
量化为具有n个子区间的一致离散变量,
,其中,
,给定边界框的每条边可以使用SoftMax函数表示为概率分布。
2.2定位蒸馏
在本小结中,我们提出了定位蒸馏,这是一种提高目标检测蒸馏效率的新方法。我们的LD是从包围盒的概率分布表示的角度发展而来的,包围盒最初是为通用目标检测设计的,并携带丰富的定位信息。
LD的工作原理图如下图所示。
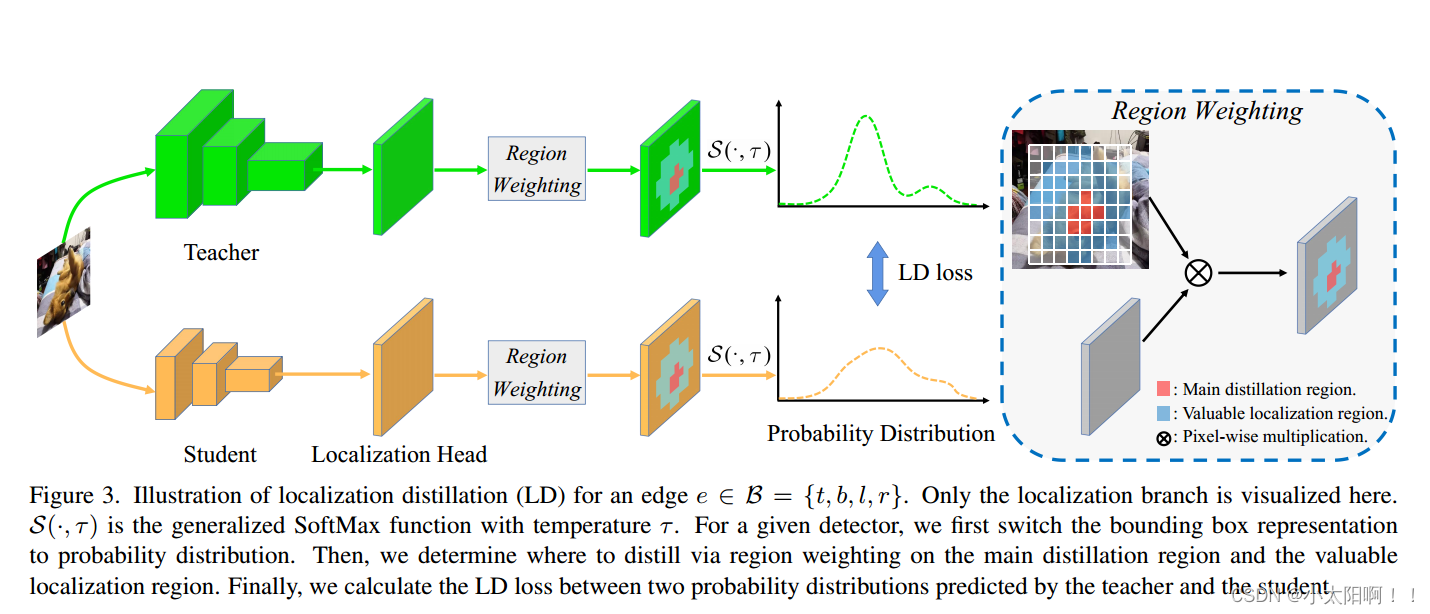
给定任意密集检测器,首先将边界框表示从四元表示切换到概率分布。选择B={t,b,l,r}作为边界框的基本形式。与{x,y,w,h}形式不同,{t,b,l,r}形式中每个变量的物理意义是一致的,这便于我们将每个边的概率分布限制在相同的区间范围内。这两种形式的性能没有差异。因此,当给出{x,y,w,h}形式时,我们首先将其切换到{t,b,l,r}形式。
设x是由定位头针对边缘e的所有可能位置预测的n个logits,分别由教师和学生的表示。我们使用广义SoftMax函数
将
变换为概率分布
。注意,当
时,它等于原始SoftMax函数。当
时,则它倾向于Dirac delta分布。当
,它将退化为均匀分布。经验上,
被设置为软化分布,使概率分布携带更多信息。
用于测量两个概率之间的相似性的定位蒸馏通过以下方式获得:
表示K1-Divergence损失。边界框B的所有四条边的LD可以公式化为:
讨论。我们的LD首次尝试使用logit模拟来提取用于目标检测的定位知识。尽管盒子的概率分布表示已被证明在通用目标检测中有用,但没有人探索其在定位知识蒸馏中的性能。我们将盒子的概率分布表示和KL-Divergence损失相结合。证明了这种简单的logit模拟技术在提高目标检测器的蒸馏效率方面表现良好。
2.3有效的回归区域
以前的工作大多通过最小化损失来迫使学生的深层特征模仿教师的深层特征。然而,一个问题是:我们是否应该一视同仁地使用整个模仿区域来提取混合知识?根据我们的观察,答案是否定的。以前的工作指出,知识蒸馏模式在分类和回归方面是不同的。因此,我们在本小节中描述了有价值的定位区域(VLR),以进一步提高蒸馏效率,我们认为这将是训练更好的学生检测器的一种很有效的方法。
具体来说,蒸馏分为两部分,主蒸馏区和有价值定位区。通过标签分配直观地确定主蒸馏区,即检测头的正样本位置。有价值的区域可以通过以下过程得到:
首先,对于FPN的第l层,我们计算所有anchor 框和ground truth
之间的矩阵
。然后,我们将DIoU的下界设置为
,
是标签分配的正IoU阈值。VLR可以定义为
。我们的方法只有一个超参数
,它控制VLR的范围。当
时,预测anchor框和GT框之间的DIoU满足
的所有位置被确定为VLR。当
时,VLR将逐渐收缩为空。这里我们使用DIoU,因为它对靠近对象中心的位置给与更高的优先级。
与标签分配类似,我们的方法在多级FPN中为每个位置分配属性。通过这种方式,GT盒外的一些位置也被考虑在内。因此,我们实际上可以将VLR视为主蒸馏区的往外延伸。注意,对于无anchor检测器,例如FCOS,我们可以使用特征图上的预设anchor,并且不改变其回归形式,从而使定位学习保持为无anchor类型。而对于通常每个位置设置多个anchor的基于anchor的检测器,我们展开anchor框来计算DIoU矩阵,然后分配它们的属性。
2.4 整个蒸馏过程
训练学生S的总损失为:
是分类损失,
是边界框回归损失,
是分布焦点损失。
和
分别是主蒸馏区和有价值定位区的蒸馏掩码。
是KD损失,
分别表示学生和教师分分类头输出logits,
是ground truth类标签。所有蒸馏损失将根据其类型由所有相同的权重因子加权,例如,LD损失遵循bbox回归,KD损失遵循分类。此外,值得一提的是,由于LD损失具有足够的引导能力,因此可以禁用DFL损失项。此外,我们可以启用或禁用四种类型的蒸馏损失,以便以单独的蒸馏区方式蒸馏学生。
3、结论
提出了一种用于密集目标检测的灵活定位蒸馏,并设计了一个有价值的定位区域,以单独的蒸馏区域方式蒸馏学生检测器。我们发现:
(1)logit模仿可以比特征模仿更好
(2)当提取目标检测器时,用于转移分类和定位知识的分离的提取区域方式是重要的。















 1241
1241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









