






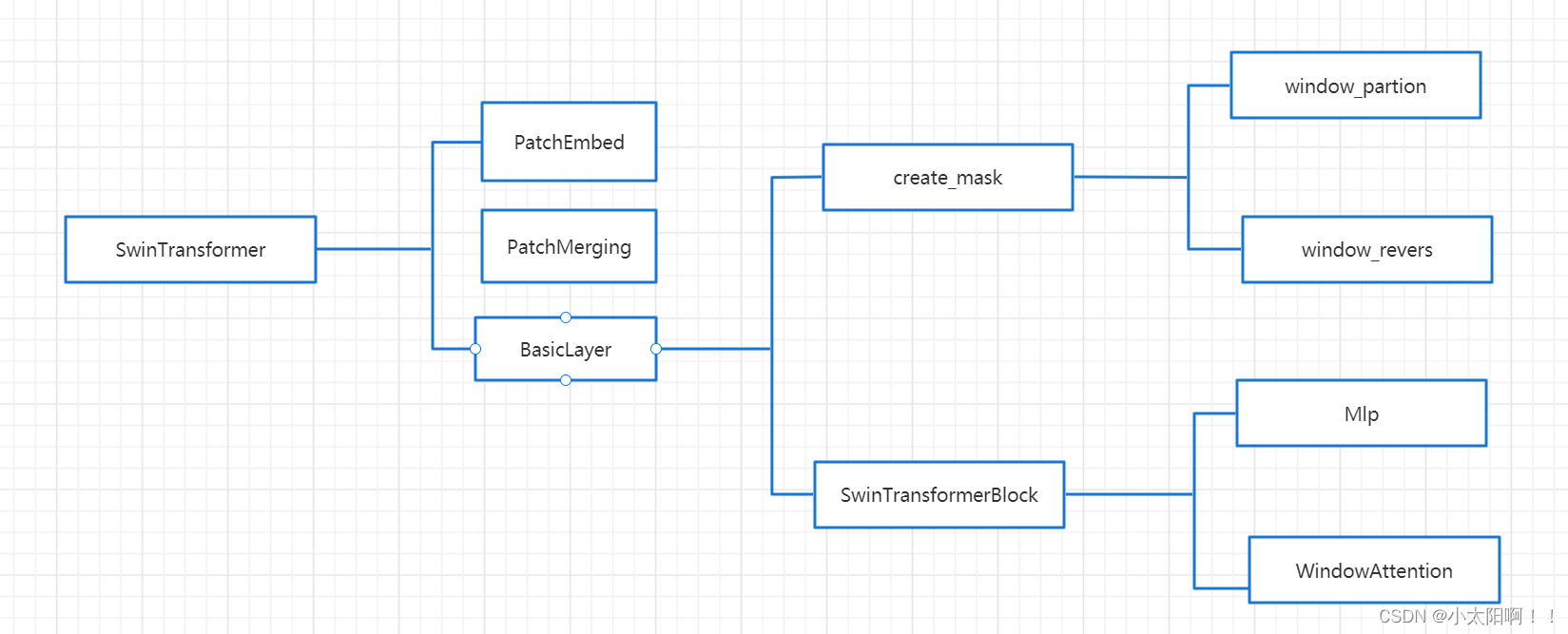
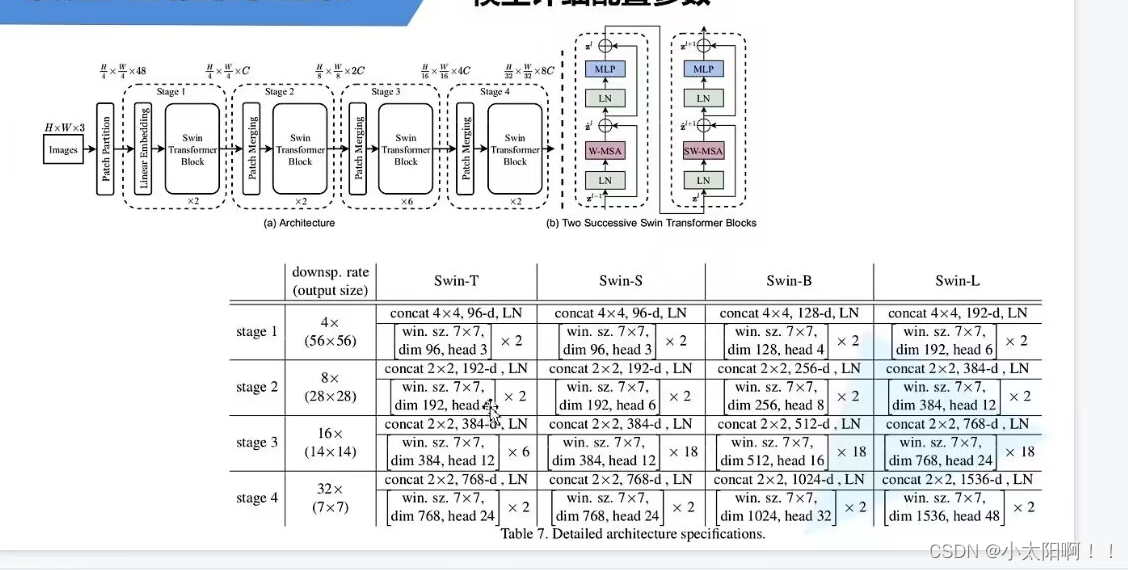
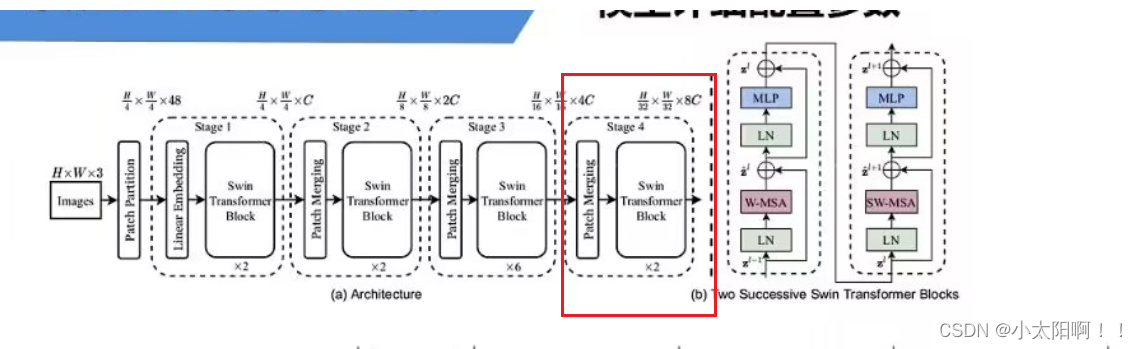
网络整体结构

patchpatition:
用一个
4x4
大小的窗口对输入图像进行分割,分割后对每一个窗口,在
channel
方向进行展平,因此经过patchpartion
之后,特征图的宽高变为原来的
1/4
,
Linear embedding:
对每一个
channe
都进行一个
learnorm
处理。
每一个
stage
都会重复
Swin Transformer blocks N
次(
N是偶数)。

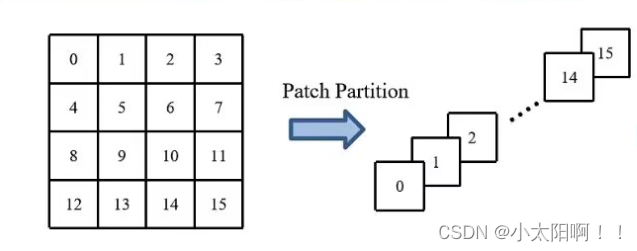
Patch partition:
如上图,通过一个
4x4
大小的窗口对特征图进行分割,之后,对每一个窗口在深度方向
(
按通道维度
)
进行
展平(
通道之后的全部变成
1维)。变成













































也就是说将每个像 素沿深度方向进行拼接,因为每个像素都为RGB
三通道,因此最终的
channel
是
48
。 在通过Linear Embedding
对通道进行调整,将通道变为
c
。
Patch Merging(其实就是进行下采样,将传入的特征图的H和W降低2倍,channel翻倍)
首先经过
W-MSA
之后的黄色特征图的窗口划分如图所示
将
W-MSA
的窗口又经过偏移之后(右下移动
M/2
,
M
是
window_size
)
由于上述
windows
变为了
9
个,如下图所示
经过循环移位之后
(A
、
C
先去下方,
B
、
A
再去右方
)
此时就可以划分为
4
个
window
在后续的进行
MSA
自注意力之前,要加上一个
masked
,如下图
上述使用了掩码之后,就可以得到只有自己和自己之间的自注意力结果。
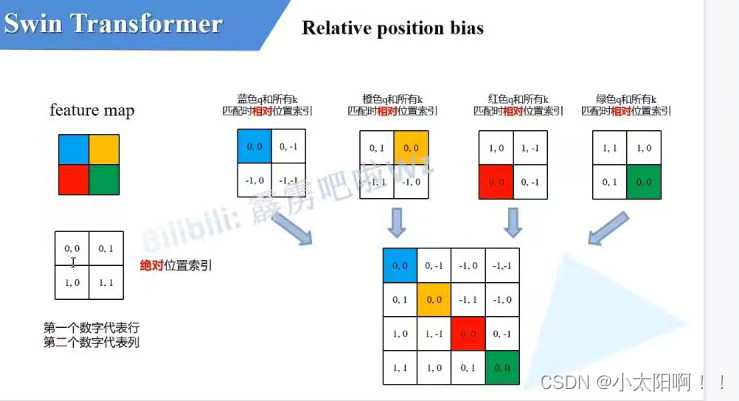
Relative position bias
B
就是偏移
大的特征图是将每一块在行的位置上展平得到的。
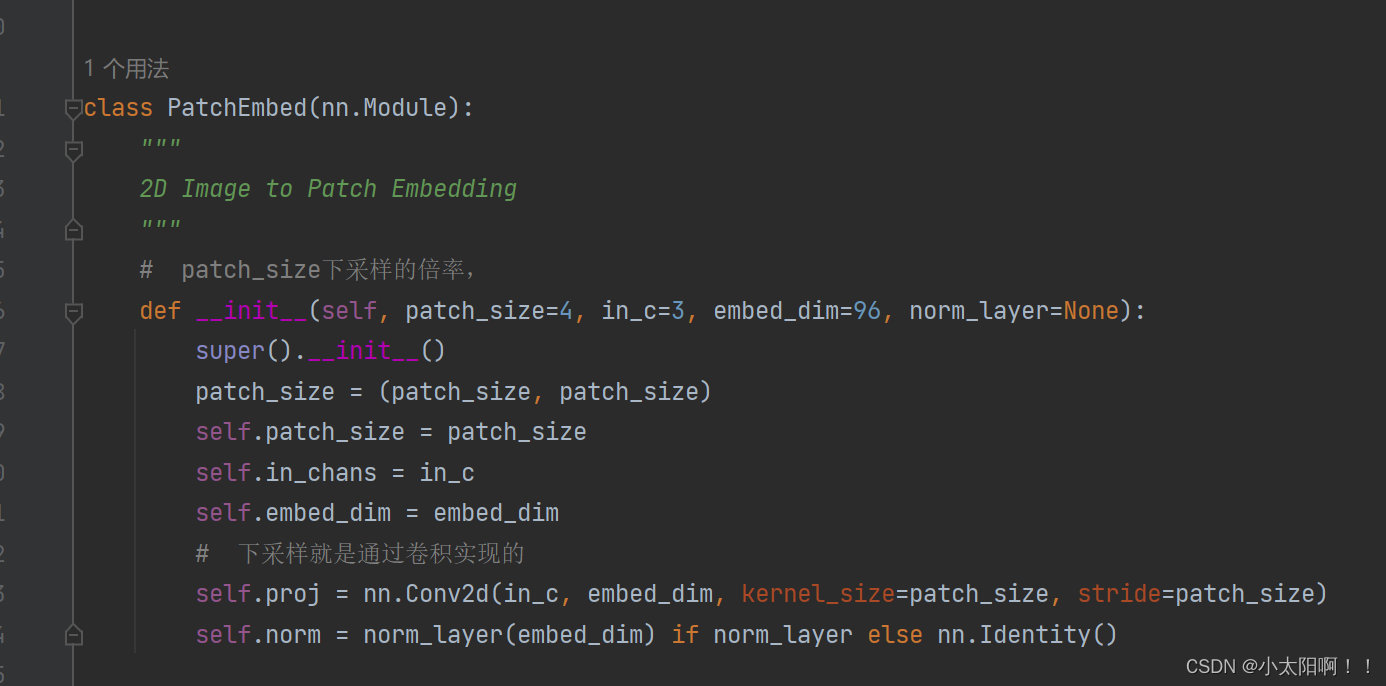
SwinTransformer类
初始化


这里
num_features
是
embed_dim
的
8
倍
Patchembed(patch partion+linear Embedding)
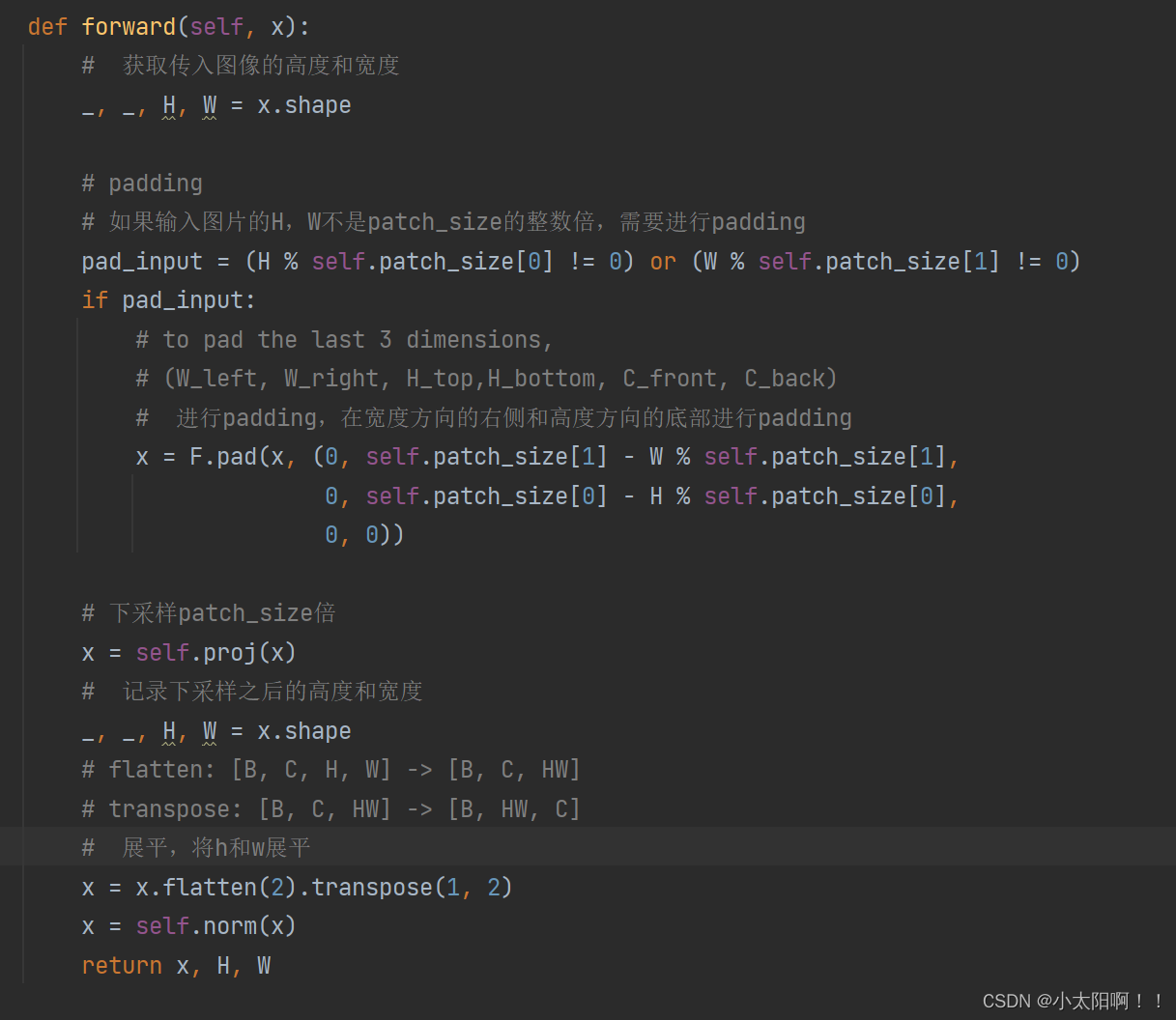
上述就是
patch partition
(将特征图通过卷积划分成一个一个的
patch
之后,将
patch
按照通道维度进行展平)
PatchMerging类





BasicLayer类实现swin_transformer中的每一个stage



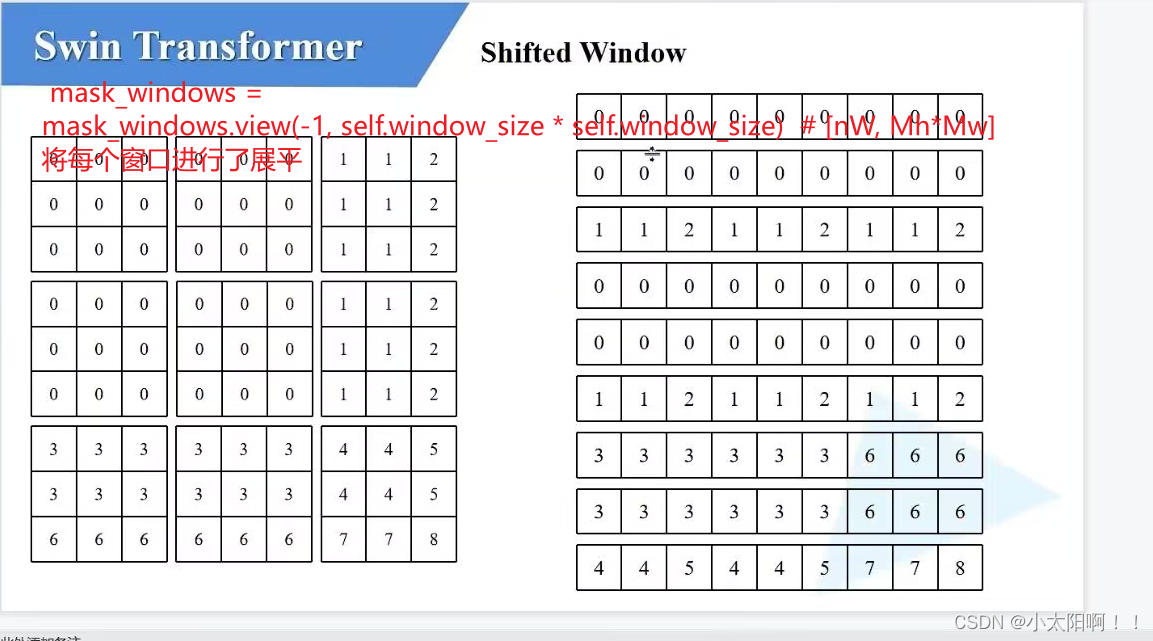
create_mask方法
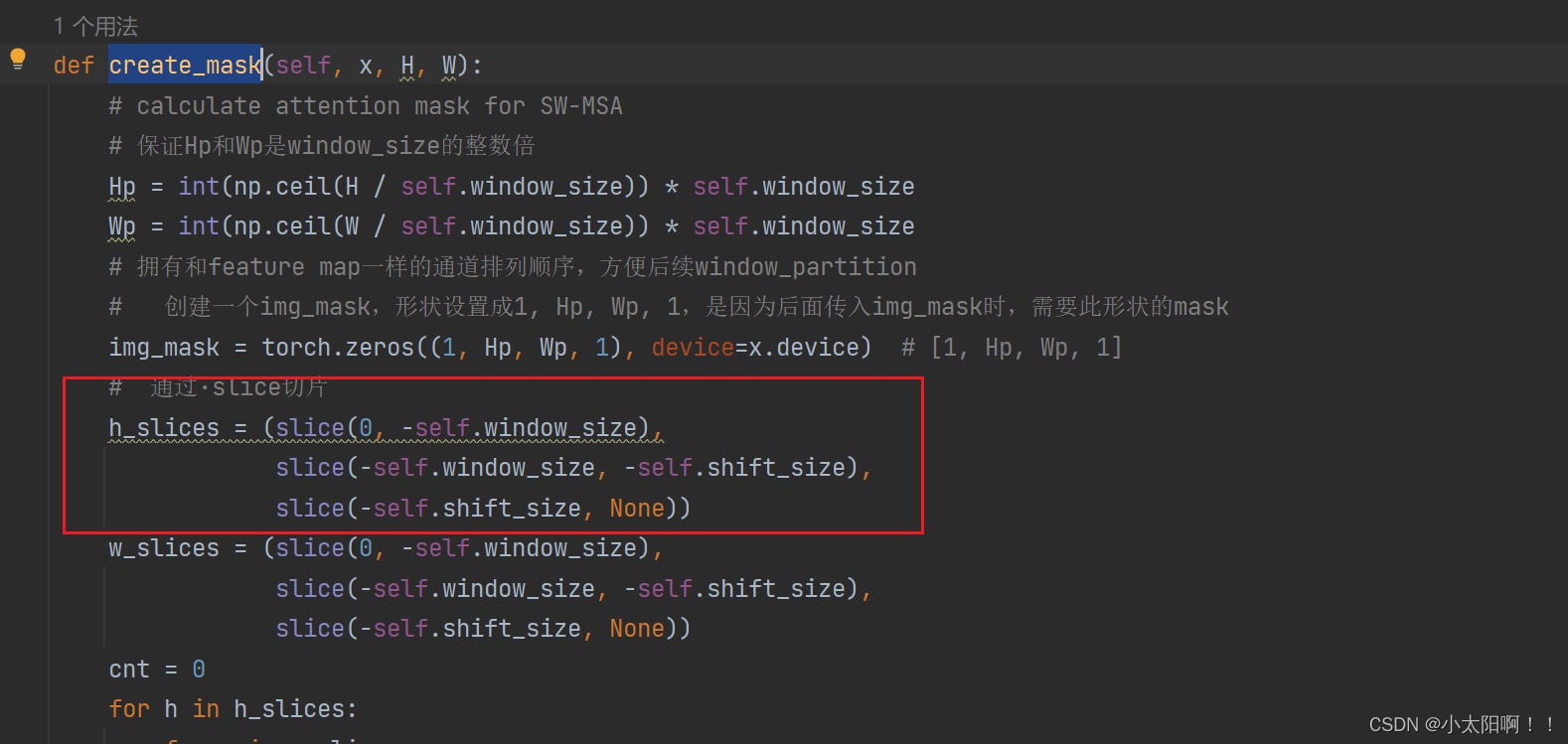
举例:使用特征图为
9x9
,窗口为
3x3
的大小时。
第一步划分
winow
,使用的
window
尺寸
M=3
上述左侧的三个
{
就是
h_slices = (slice(0, -self.window_size), slice(-self.window_size, -self.shift_size), slice(-self.shift_size, None))里的三个切片,第一个切片从(
0
,
-3
),取不到
-3
第二个切片从(
-3
,
-1
)取不到
-1
第三个切片(-1
到末尾)
右图是
此处得到的
img_mask
window_partition函数

window_reverse函数




一开始通过
window_partition
得到
9
个窗口,接着通过
view
方法,将窗口展平。
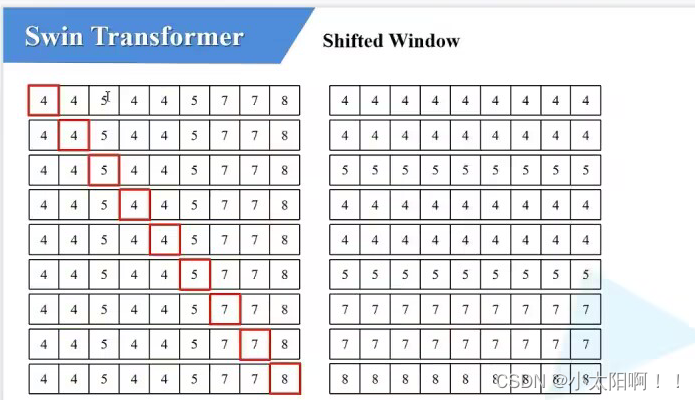
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2) # [nW, 1,
Mh*Mw] - [nW, Mh*Mw, 1]
这里的
tensor
相减会
涉及广播机制
,对于
第一个矩阵
而言,会将第二个维度的数据 复制
Mh*Mw
次
相当于将上图右边的矩阵的每一个行向量复制
Mh*Mw
次(
9
次)。
对于第二个矩阵,会在最后一个维度将数据复制
Mh*Mw
次对于第一个矩阵的广播机制,相当于将上述的行向量复制了Mh*Mw
次
(
一个窗口内像素的个数
)
举例:
将最后一行复制
9
次,如图左所示:
对于第二个矩阵,是将最后一个维度上的数据复制
9
次(因为加了一维,对每一个行向量来说又多了一个新的维度),因此,每一行上的每一个数要复制9
次,得到右边的行向量。再将左边和右边进行相减(
就
是
attention
的过程
)。
相减之后得到如右图所示,右图表示同一区域的用
0
表示,不同区域的是非
0
SwinTransformerBlock
构建每一个
block
的类
MLP类

回到
SwinTransformerBlock
类的
forward
函数中
WindowAttention类(实现了W-MSA和SW-MSA的部分功能)
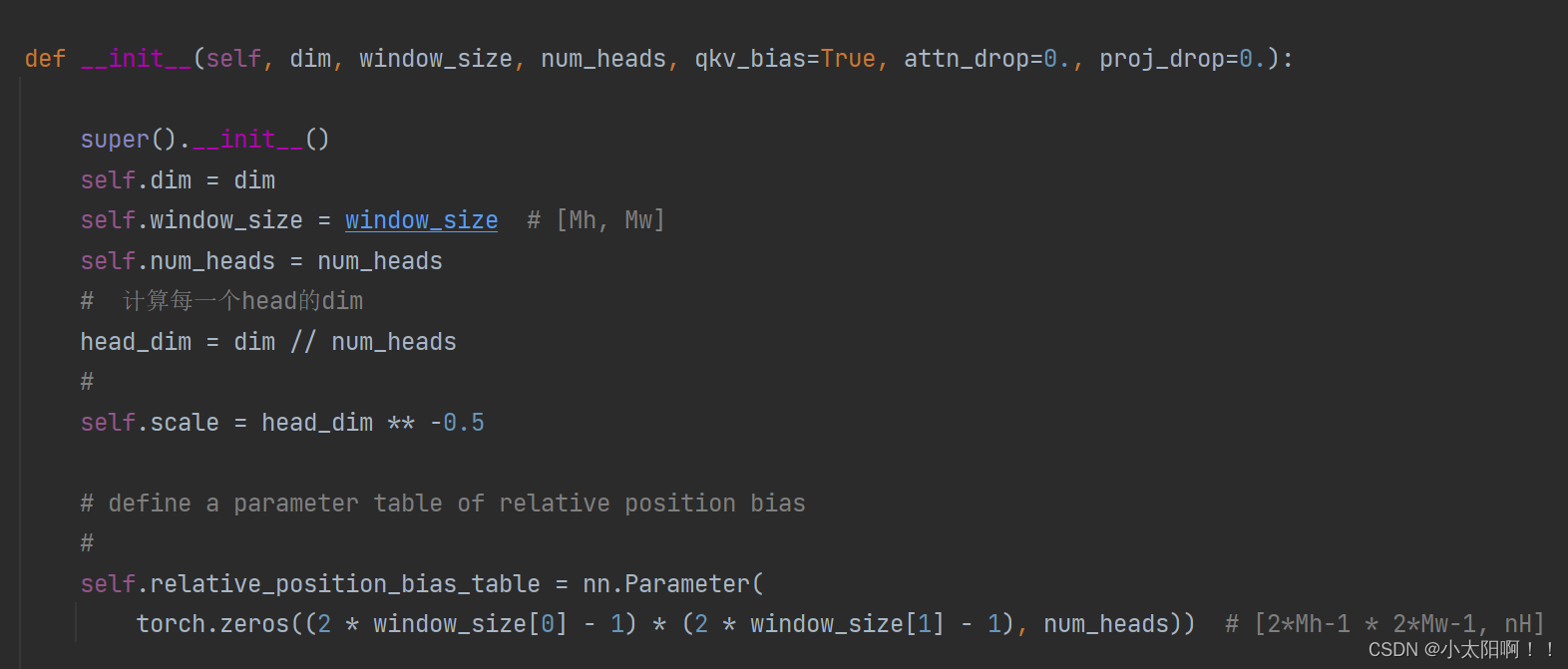
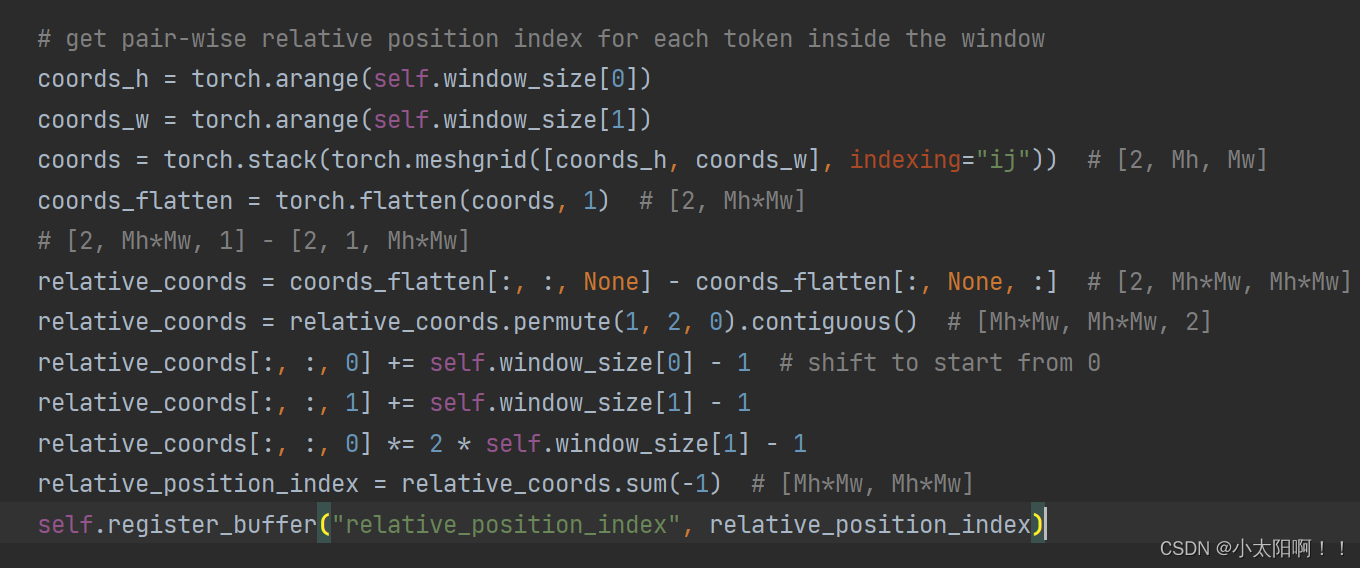
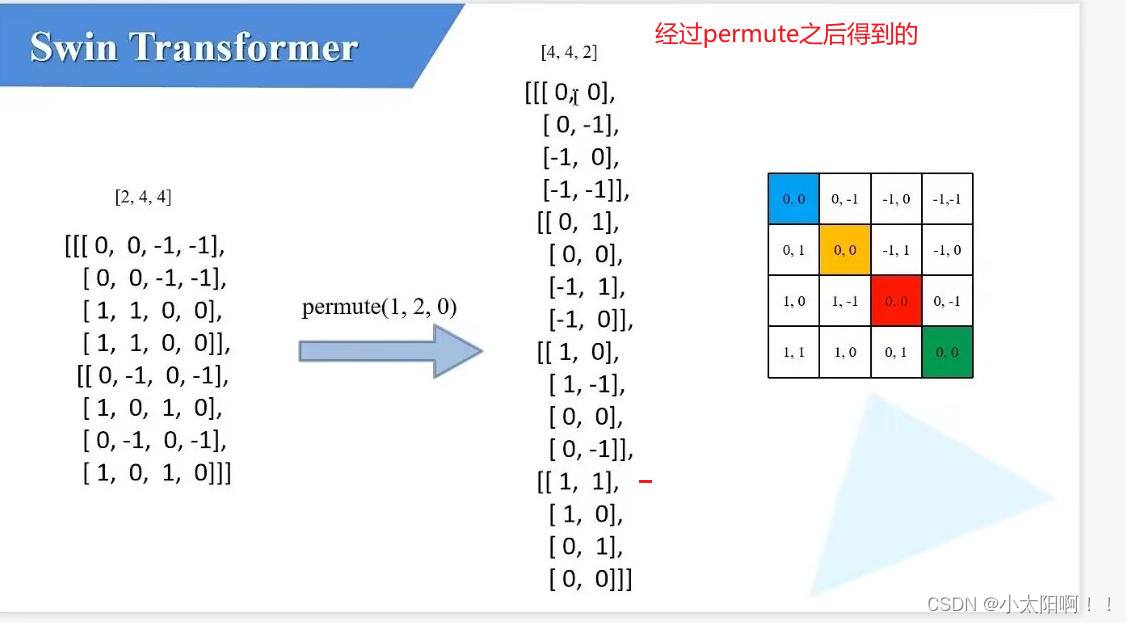
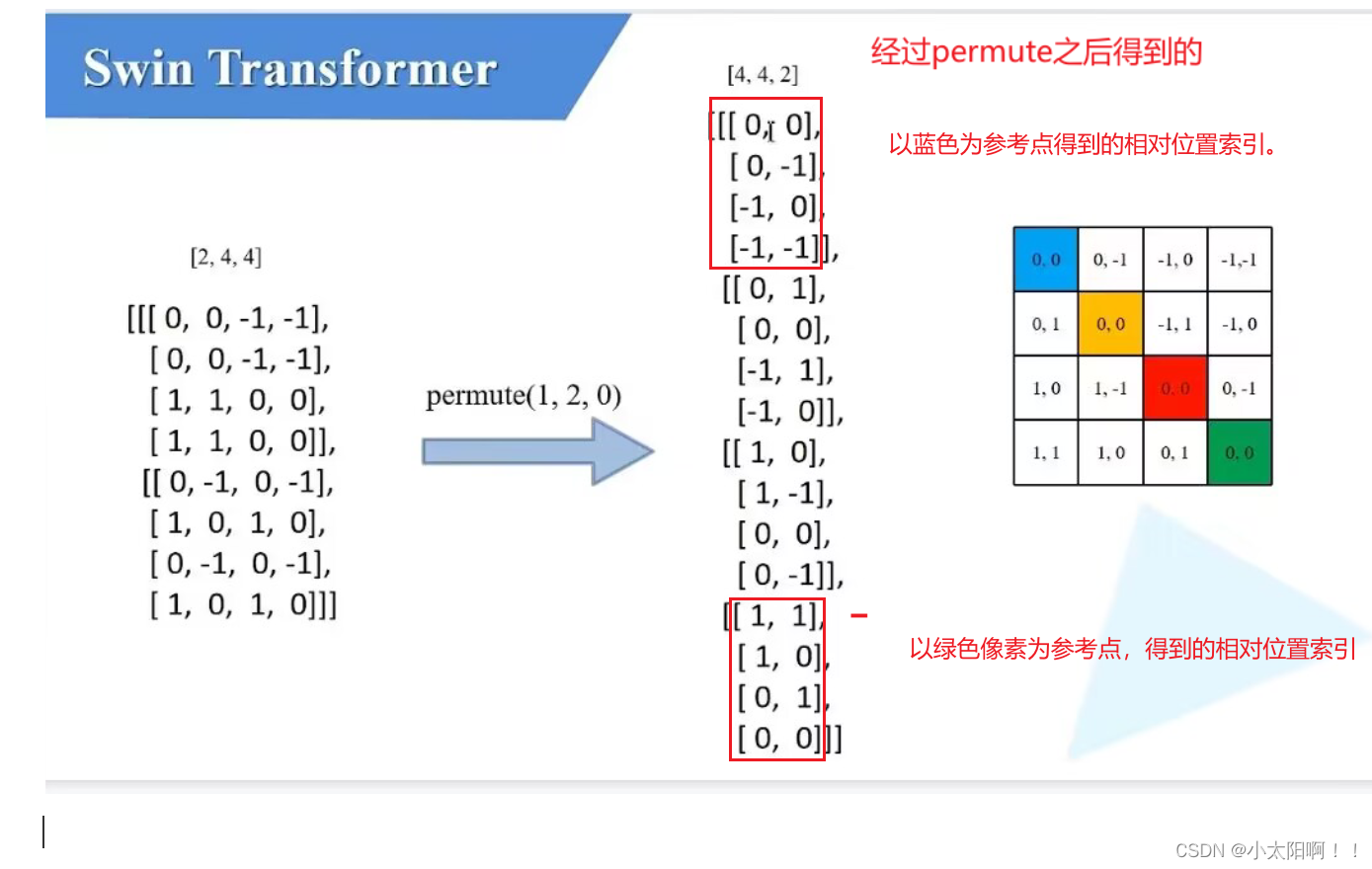
上述是生成
relative_position_index
的过程。假设
window_size
为
2
时
coords_h
喝和
·coords_w
均为
0,1 coords = torch.stack(torch.meshgrid([coords_h, coords_w], indexing="ij")) # [2, Mh, Mw]
生成网格 coords_flatten = torch.flatten(coords, 1) # [2, Mh*Mw] 展平,从Mh
维度展平
第一行是
featuremap
上每一个像素对应的行标,第二行是 feature map上每一个像素对应的列标。
相减之后的结果如上图。得到的就是相对位置索引的矩阵。
得到
relative_persition_index
forward
函数














 433
433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









