






Masked Generative Distillation(MGD)2022年ECCV
摘要
**目前的蒸馏算法通常通过模仿老师的输出来提高学生的表现。本文表明,教师还可以通过引导学生特征恢复来提高学生的代表性。从这个角度来看,我们提出的掩模生成蒸馏(MGD),它很简单:我们掩模学生特征的随机像素,并通过一个简单的块强制其生成教师的完整特征。**MGD是一种真正通用的基于特征的蒸馏方法,可用于各种任务,包括图像分类、目标检测、语义分割和实例分割。我们用大量的数据集对不同的模型进行了实验,结果表明所有的学生都取得了很好的进步。
介绍
知识蒸馏可以分为两种:第一种是专门为不同的任务而设计的,例如用于分类的基于logit的蒸馏和用于检测的基于head的蒸馏。第二种是基于特征的蒸馏。由于各种网络之间只有头部或投影后的特征是不同的,从理论上讲,基于特征的蒸馏方法可以被用于各种任务。然而,为特定任务设计的蒸馏方法通常不适用于其他任务。例如,OFD和KR对探测器改进有限。FKD和FGD是专门为探测器设计的,由于缺乏neck,无法用于其他任务。
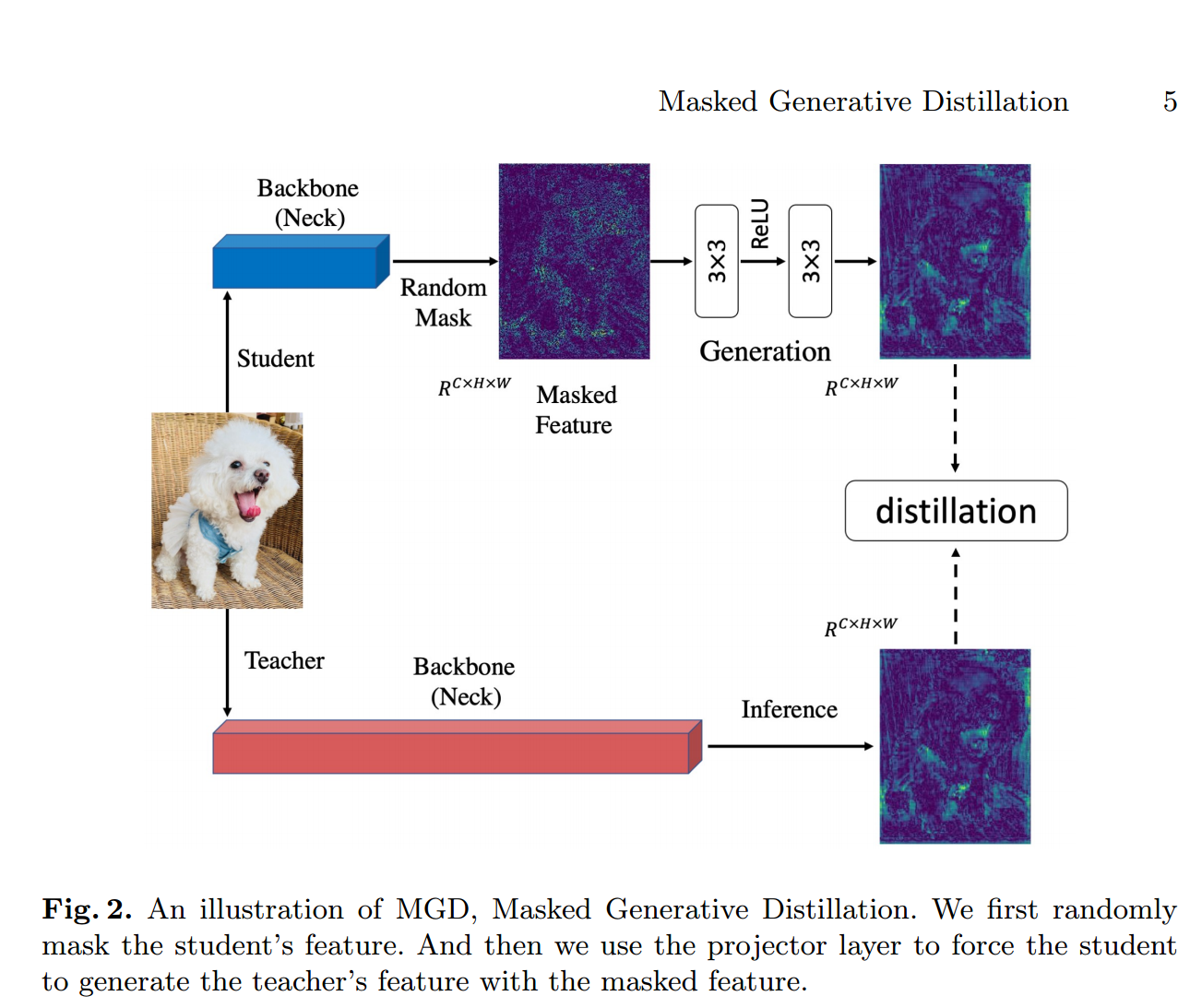
以往基于特征的蒸馏方法,由于教师的特征具有更强的表征能力,通常会让学生尽可能地模仿教师的输出。然而,我们认为没有必要直接模仿老师来提高学生特征的表征能力。用于蒸馏的特征通常是通过深度网络获得的高阶语义信息。特征像素已经在一定程度上包含了相邻像素的信息。因此,如果我们可以使用部分像素通过一个简单的块来还原教师的全部特征,那么这些使用像素的代表性也可以得到提高。从这个角度出发,我们提出了一种简单有效的基于特征的蒸馏方法——掩模生成蒸馏(MGD)。如图2所示,**我们首先对学生特征的随机像素进行mask,然后通过一个简单的块将mask后的特征生成教师的完整特征。由于每次迭代都使用随机像素,因此在整个训练过程中都会使用所有像素,这意味着特征将更加鲁棒,并且其表达能力将得到提高。**在我们的方法中,教师只是引导学生还原特征,并不要求学生直接模仿。
为了验证我们的假设,即在不直接模仿教师的情况下,掩模特征生成可以提高学生的特征表达能力,我们从学生和教师的neck对特征注意力进行了可视化。如图1所示,

学生和教师的特征有很大的不同,与教师相比,学生特征的背景有更高的反应。经过MGD训练以后,学生和教师特征仍有显著差异,但学生对背景的反应大大降低。但是学生的表现超过了FGD,甚至达到了与教师相同的mAP。这也说明MGD训练可以提高学生特征的表征能力。此外,我们还在图片分类和密集检测任务上做了实验。结果表明MGD对图像分类、目标检测和语义分割等任务都有效。MGD可以与其他基于logit或基于head的蒸馏方法相结合,以获得更大的性能收益。综上所述,本文的贡献有:
1、我们提出了一种新的基于特征的知识蒸馏方法,使学生利用被掩蔽的特征来生成教师的特征,而不是直接模仿教师的特征。
2、本文提出了一种新的基于特征的蒸馏方法——掩模生成蒸馏,该方法简单易用,只需要两个超参数。
相关工作
面向密集检测的知识蒸馏
分类和密集预测有很大的区别。许多用于分类的蒸馏工作在密集预测上都失败了。理论上,基于特征的蒸馏方法应该有助于分类和密集预测任务,这也是我们方法的目标。
Chen等首先计算检测器的neck和头部的蒸馏损失。由于前景和背景的极度不平衡,在什么地方进行蒸馏是目标检测的关键。为了避免从背景中引入噪声,FGFI利用细粒度掩模提取物体附近的区域。然而,Defeat指出,来自前景和背景的信息都很重要。GID选择学生和老师在蒸馏中表现不同的领域。FKD利用教师和学生注意力的总和,使学生的注意力集中在可变的区域。FGD提出了焦点蒸馏,它迫使学生学习教师的关键部分,而全局蒸馏则弥补了缺失的全局信息。
方法
对于不同的任务,模型的体系结构差别很大。此外,大多数蒸馏方法都是为特定任务而设计的。然而,基于特征的蒸馏可以同时用户分类和密集预测任务。特征蒸馏的基本方法可表述为:
L
f
e
a
=
∑
k
=
1
C
∑
i
=
1
H
∑
j
=
1
W
(
(
F
k
,
i
,
j
T
−
f
a
l
i
g
n
(
F
k
,
i
,
j
S
)
)
)
2
L_{fea} = \sum_{k=1}^C\sum_{i=1}^H\sum_{j=1}^W((F_{k,i,j}^T - f_{align}(F_{k,i,j}^S)))^2
Lfea=k=1∑Ci=1∑Hj=1∑W((Fk,i,jT−falign(Fk,i,jS)))2
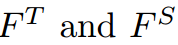 分别表示教师和学生的特征,
分别表示教师和学生的特征,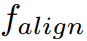 是将学生特征
是将学生特征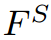 与教师特征
与教师特征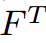 对齐的自适应层。C,H,W表示特征图的形状。这种方法有助于学生直接模仿教师特征。然而,我们提出了掩蔽生成蒸馏(MGD),其目的是迫使学生生成教师的特征,而不是模仿它,从而使学生在分类密集预测方面都有显著的提高。
对齐的自适应层。C,H,W表示特征图的形状。这种方法有助于学生直接模仿教师特征。然而,我们提出了掩蔽生成蒸馏(MGD),其目的是迫使学生生成教师的特征,而不是模仿它,从而使学生在分类密集预测方面都有显著的提高。
带Mask特征的生成
对于基于CNN的模型,更深层的特征具有更大的接受域和更好的原始输入图像的表示。换句话说,特征图像素在一定程度上已经包含了相邻像素的信息。因此,我们可以使用部分像素来恢复完整的特征图。我们的方法旨在通过学生的mask特征来生成老师的特征,这可以帮助学生获得更好的表现。
我们用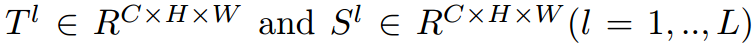 分别表示为教师和学生的第L个特征图。首先,我们设置第l个随机mask来覆盖学生的第l个特征,可以表示为:
分别表示为教师和学生的第L个特征图。首先,我们设置第l个随机mask来覆盖学生的第l个特征,可以表示为:
M
i
,
j
l
=
{
0
,
i
f
R
i
,
i
l
<
λ
1
,
O
t
h
e
r
w
i
s
e
M_{i,j}^l =\left\{\begin{matrix} 0, if R_{i,i}^l < \lambda& \\ 1, Otherwise& \end{matrix}\right.
Mi,jl={0,ifRi,il<λ1,Otherwise
为(0,1)中的随机数,i,j分别为特征图的横坐标和纵坐标。是表示掩码比的超参数。第l个特征映射被第l个随机掩码覆盖。
然后我们使用相应的掩码覆盖学生的特征图,并尝试用左边的像素生成教师的特征图,可以表示为:
G
(
f
a
l
i
g
n
(
S
l
)
×
M
l
→
T
l
)
G(f_{align(S^l)} \times M^l\rightarrow T^l)
G(falign(Sl)×Ml→Tl)
G ( F ) = W l 2 ( R e L U ( W l 1 ( F ) ) ) G(F) = W_{l2}(ReLU(W_{l1}(F))) G(F)=Wl2(ReLU(Wl1(F)))
表示包含两个卷积层的投影层:和,一个激活层ReLU。在本文中,对于自适应层我们采用1x1卷积层,投影层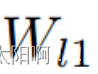
和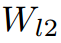 使用3x3卷积层。
使用3x3卷积层。
根据这个方法,我们设计了MGD的蒸馏损失:
L
d
i
s
(
S
,
T
)
=
∑
l
=
1
L
∑
k
=
1
C
∑
i
=
1
H
∑
j
=
1
W
(
T
k
,
i
,
j
l
−
G
(
f
a
l
i
g
n
(
S
k
,
i
,
j
l
)
×
M
i
,
j
l
)
)
2
L_{dis}(S,T) = \sum_{l=1}^L\sum_{k=1}^C \sum_{i=1}^H \sum _{j=1}^W(T_{k,i,j}^l - G(f_{align}(S_{k,i,j}^l )\times M_{i,j}^l))^2
Ldis(S,T)=l=1∑Lk=1∑Ci=1∑Hj=1∑W(Tk,i,jl−G(falign(Sk,i,jl)×Mi,jl))2
其中L为蒸馏层数和,C,H,W为特征映射的形状。S和T分别表示学生和教师的特征。
总损失
利用提出的MGD损失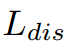 ,我们用总损失训练所有模型如下:
,我们用总损失训练所有模型如下:
L
a
l
l
=
L
o
r
i
g
i
n
a
l
+
α
×
L
d
i
s
L_{all} = L_{original} + \alpha \times L_{dis}
Lall=Loriginal+α×Ldis
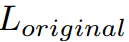 是所有任务重模型的原始损失,
是所有任务重模型的原始损失,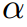 为平衡损失的超参数。MGD是一种简单有效的蒸馏方法,可方便地应用于各种任务。算法1总结了我们方法的过程
为平衡损失的超参数。MGD是一种简单有效的蒸馏方法,可方便地应用于各种任务。算法1总结了我们方法的过程
















 669
669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









