






尝试在 vLLM 里预测大模型的最小显存占用
- Author: Mingbo Li, mingboli@outlook.com
- Supervised by: Di Chen, chendi@microsoft.com
- Date: 2024-09-29
引言
在自然语言处理领域,大模型的推理需要大量的显存。为了在显存有限的设备上运行大模型,我们需要对模型的显存占用进行预测。在本文中,我们提出了一种基于 vLLM 的方法,用于预测大模型的最小显存占用。在这篇文章中,我们将深入探讨大模型的世界。首先,我们会简要介绍大模型的基本概念及其运行原理,尤其是它的推理过程,帮助大家建立起对这一前沿技术的基本认识。接下来,我们将引入 vLLM 框架,展示如何将大模型转变为可供服务使用的工具。在掌握 vLLM 框架的基础上,我们会分享如何高效地利用它,并进一步探讨 vLLM 在性能与限制之间的矛盾。这一矛盾的理解将为我们应用机器学习方法预测模型的最小内存占用提供重要背景。最后,我们还将分享我在vLLM领域的一些其他探索,希望能为大家带来启发和思考。
大模型:是什么和怎么样的
什么是大模型
按照 A Survey of Large Language Models 的定义,“ large language models (LLMs) refer to Transformer language models that contain hundreds of billions (or more) of parameters, which are trained on massive text data”,即大型语言模型(LLM)是指包含数千亿(或更多)参数的 Transformer 语言模型,这些模型是在海量文本数据上进行训练的。
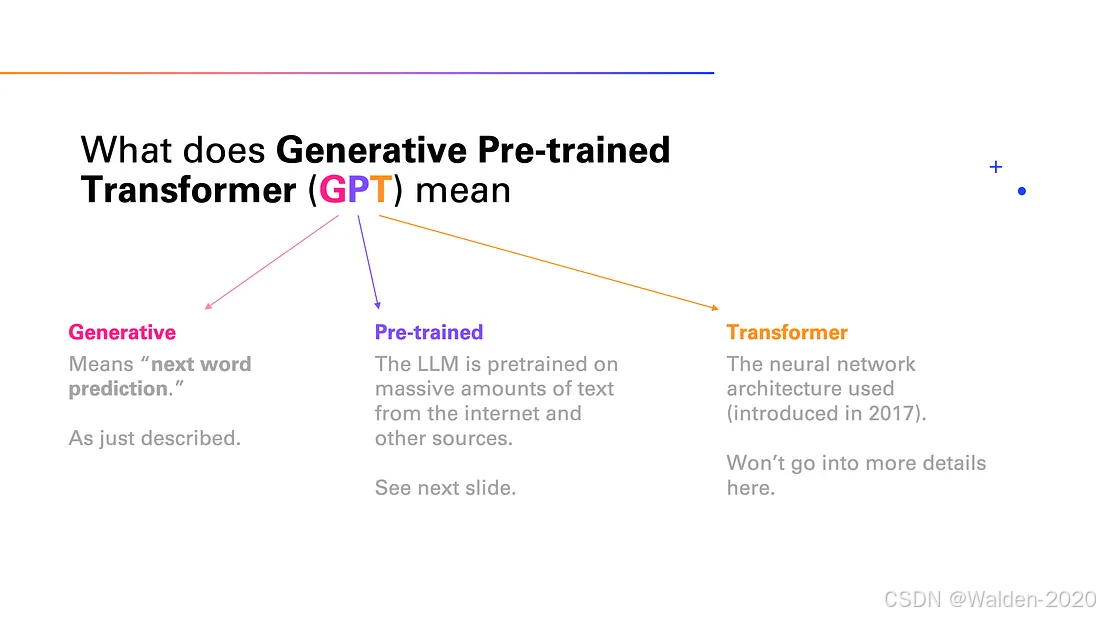
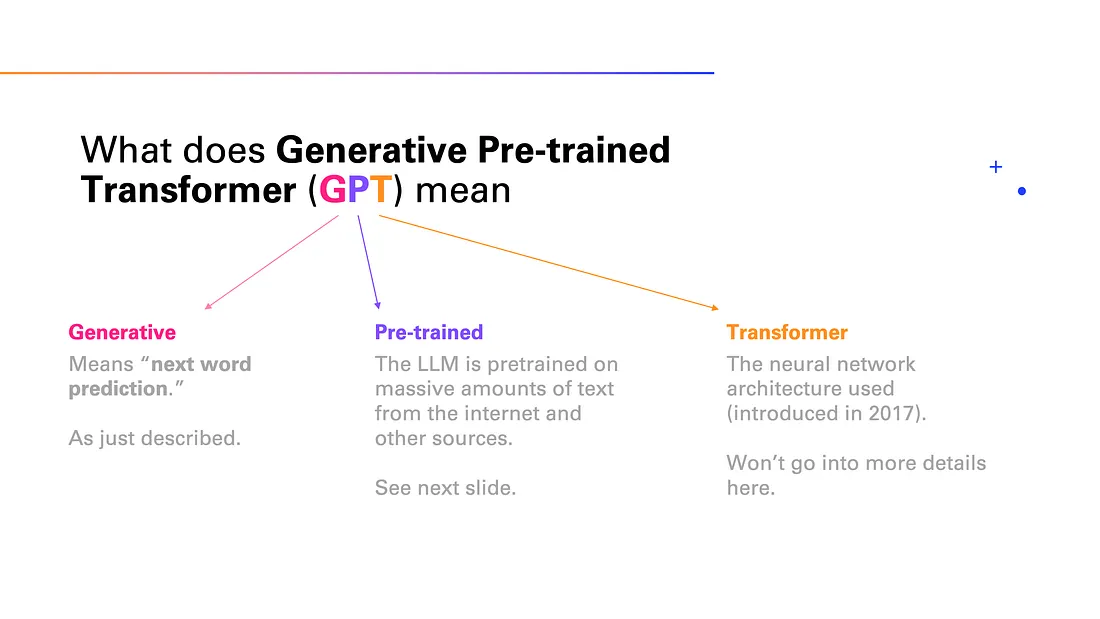
对于大模型,我们非常熟悉的便是 ChatGPT, 既然我们是从零开始认识 LLM 的,那么我们就从 ChatGPT 开始。对于 ChatGPT 来说,Chat 是聊天的意思,指代它的应用场景,GPT 是 Generative Pre-trained Transformer 的缩写,指代它的模型结构。
图片来源: https://miro.medium.com/v2/resize:fit:1100/format:webp/1*KBtpzU-6fYjyhyYmj4APIw.png
这里我们展开介绍GPT所对应的三个单词的含义:
- Generative:生成式,指的是模型的主要任务是生成文本,本质上是一种生成式模型。
- Pre-trained:预训练,指的是模型在大规模文本数据上进行了预训练。
- Transformer:指的是模型的基本结构,Transformer 是一种基于注意力机制的深度学习模型,由 Vaswani 等人于 2017 年提出。
理解大模型
生成式
大语言模型是一种生成式模型,是指它通过一种自回归的方式生成文本。自回归是指模型在生成每个词时,都会考虑前面生成的词,然后根据这些词生成下一个词。这种生成方式使得模型能够生成连贯的文本,而不是简单地复制训练数据中的文本,所以生成过程实际上是一个一步一步进行分类预测的过程。
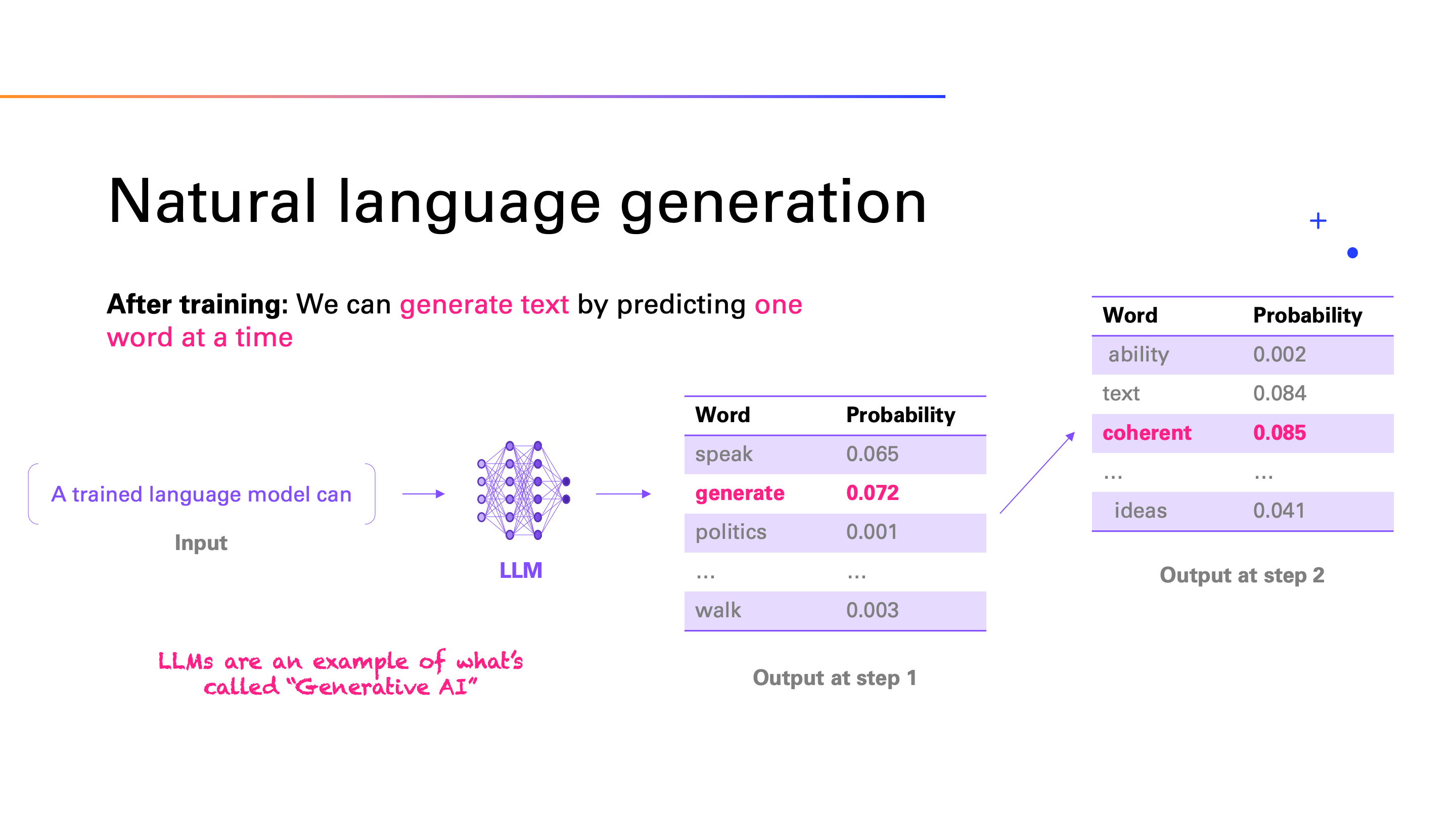
图片来源: https://miro.medium.com/1*faLf-OAINgRAyMyCLyZLvg.png
预训练
因为我们的模型所学习的能力实际上是预测当前文本的下一个词,这是一种非常通用的任务。那么当我们为模型提供大量的文本数据时,模型就可以学习到很多关于语言的知识。这种预训练的方式使得模型可以在各种各样的任务上表现出色,因为它已经学习到了很多关于语言的知识。这个过程就是预训练。

图片来源: https://miro.medium.com/1*dKWfZr1R8R55eIPvCV-PzQ.png
Transformer
Transformer 是一种基于注意力机制的深度学习模型,由 Vaswani 等人于 2017 年提出。Transformer 模型的核心是自注意力机制,它可以在不同位置的词之间建立联系,从而更好地捕捉文本中的长距离依赖关系。这种结构使得 Transformer 模型在处理自然语言处理任务时表现出色,因此被广泛应用于大型语言模型中。
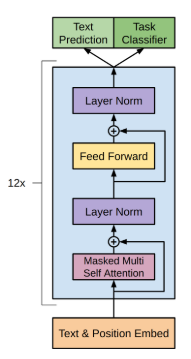
GPT 的基本结构如下图所示:
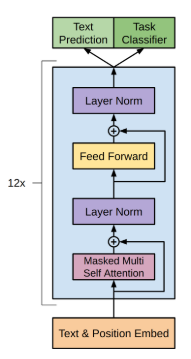
图片来源: https://amaarora.github.io/images/gpt-architecture.PNG
可以看到,它的主要结构是一个 Transformer 解码器,它由多个 Transformer block 组成。每个 Transformer block 包含一个多头自注意力层和一个前馈神经网络层。这种结构使得 GPT 能够在生成文本时更好地捕捉文本中的长距离依赖关系,从而生成更加连贯的文本。
那么对于同一类的模型,比如 GPT2,它的参数规模大小的不同的区别主要在于模型的深度和宽度。模型的深度指的是模型中 Transformer block 的数量,而模型的宽度指的是每个 Transformer block 中的隐藏层的维度。这两个参数的不同组合会导致模型的参数规模大小的不同,从而影响模型的性能和效果。

图片来源: https://jalammar.github.io/images/gpt2/gpt2-sizes.png
对于 Transformer block 来说,它主要包括以下几个部分:
- Query、Key、Value 矩阵:用于计算注意力分数。
- Self-Attention:自注意力机制,用于计算每个词与其他词之间的关系。
- Feed-Forward Neural Network:前馈神经网络,用于对每个位置的词进行非线性变换。
对于这部分的详细介绍,可以参考 transformer explainer。
此处不再赘述。
大模型的推理过程
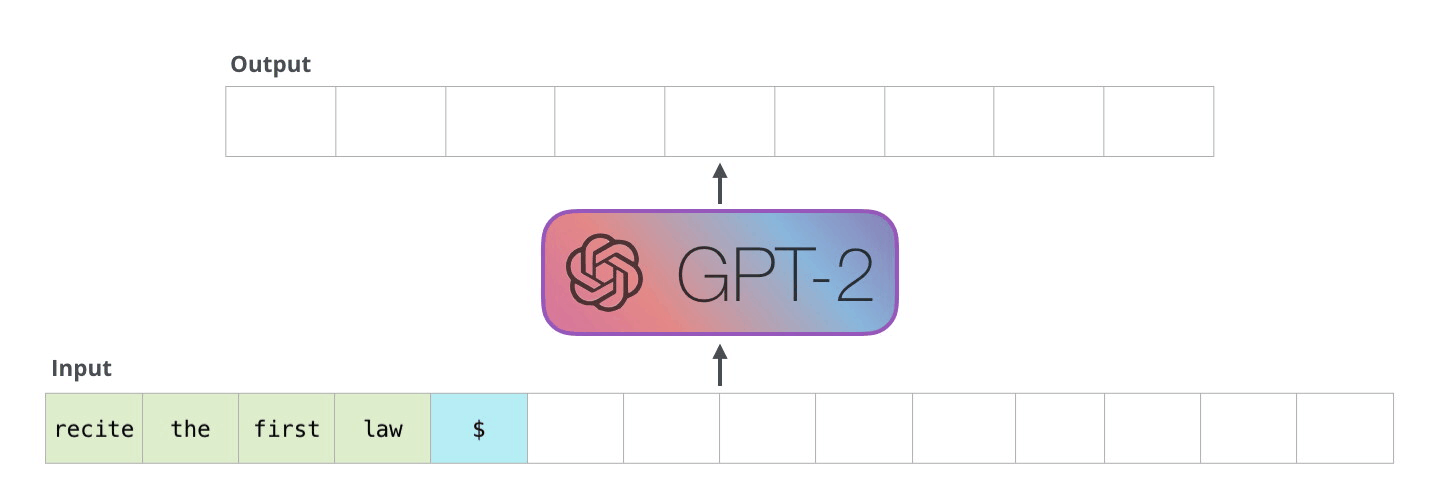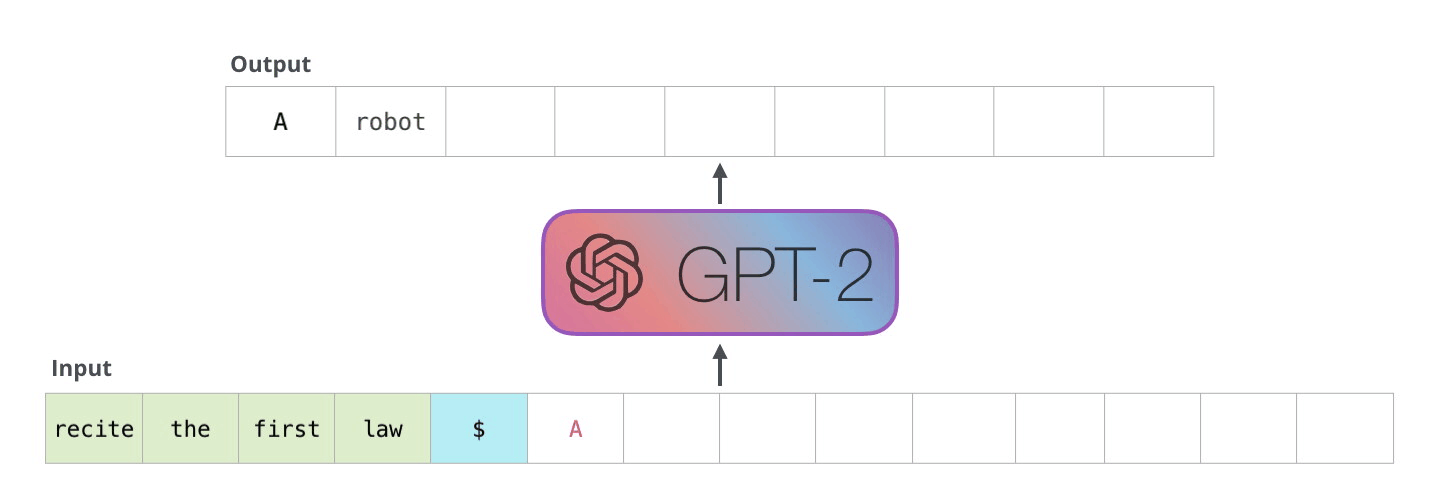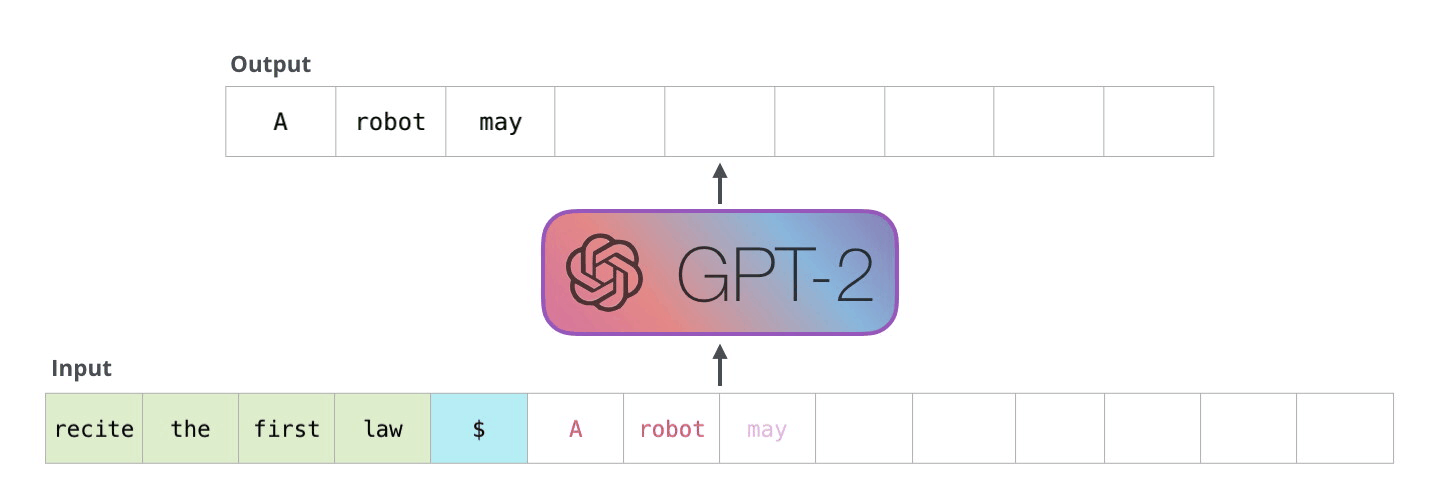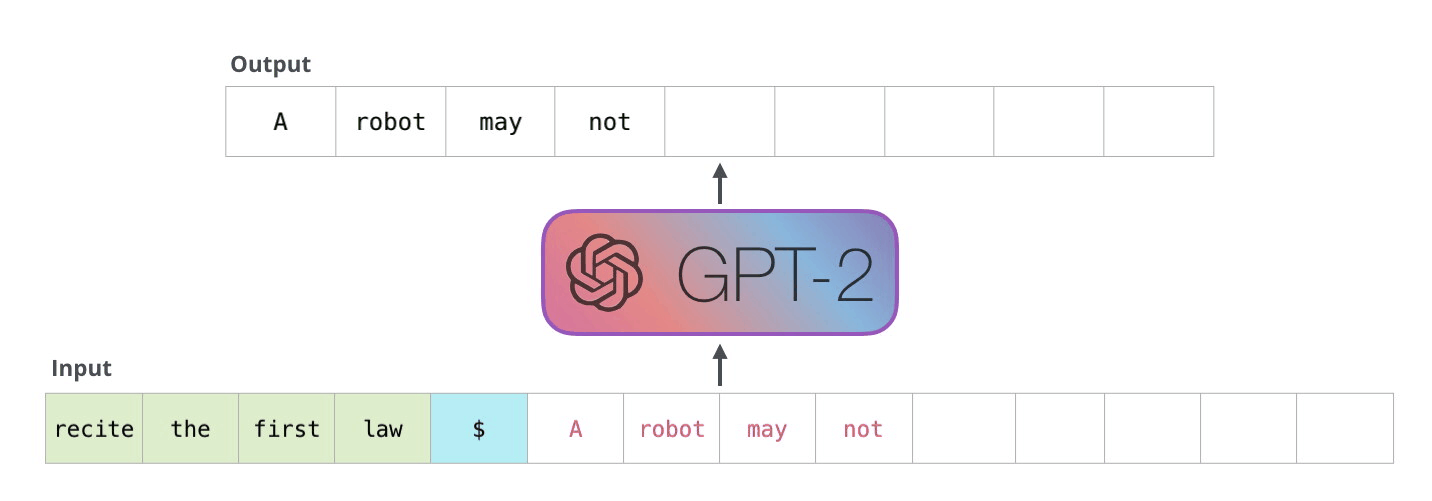
如前所述,大模型的推理过程是一个自回归的过程,即模型在生成每个词时,都会考虑前面生成的词,然后根据这些词生成下一个词
 图片来源: https://jalammar.github.io/images/gpt3/04-gpt3-generate-tokens-output.gif
图片来源: https://jalammar.github.io/images/gpt3/04-gpt3-generate-tokens-output.gif
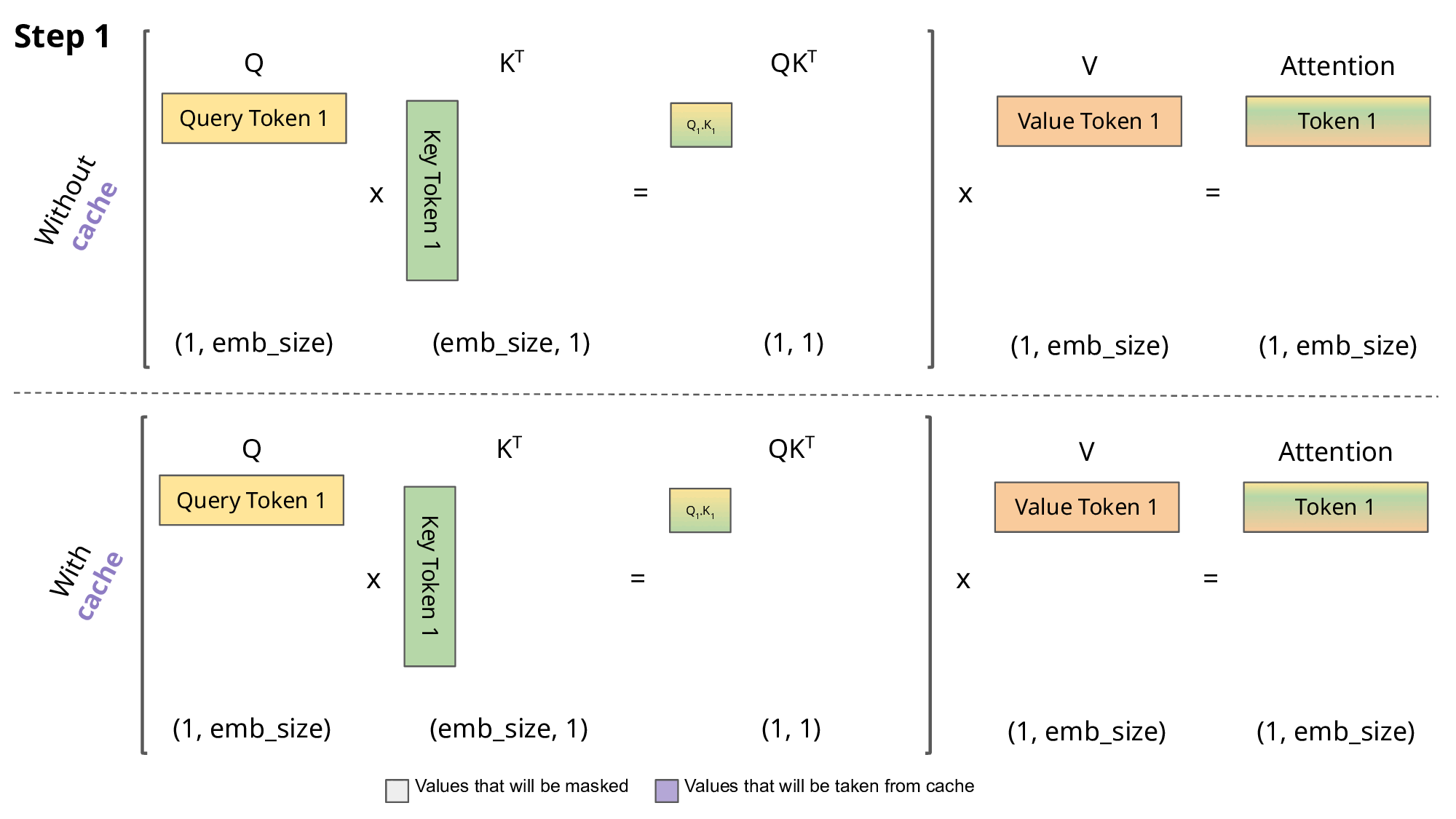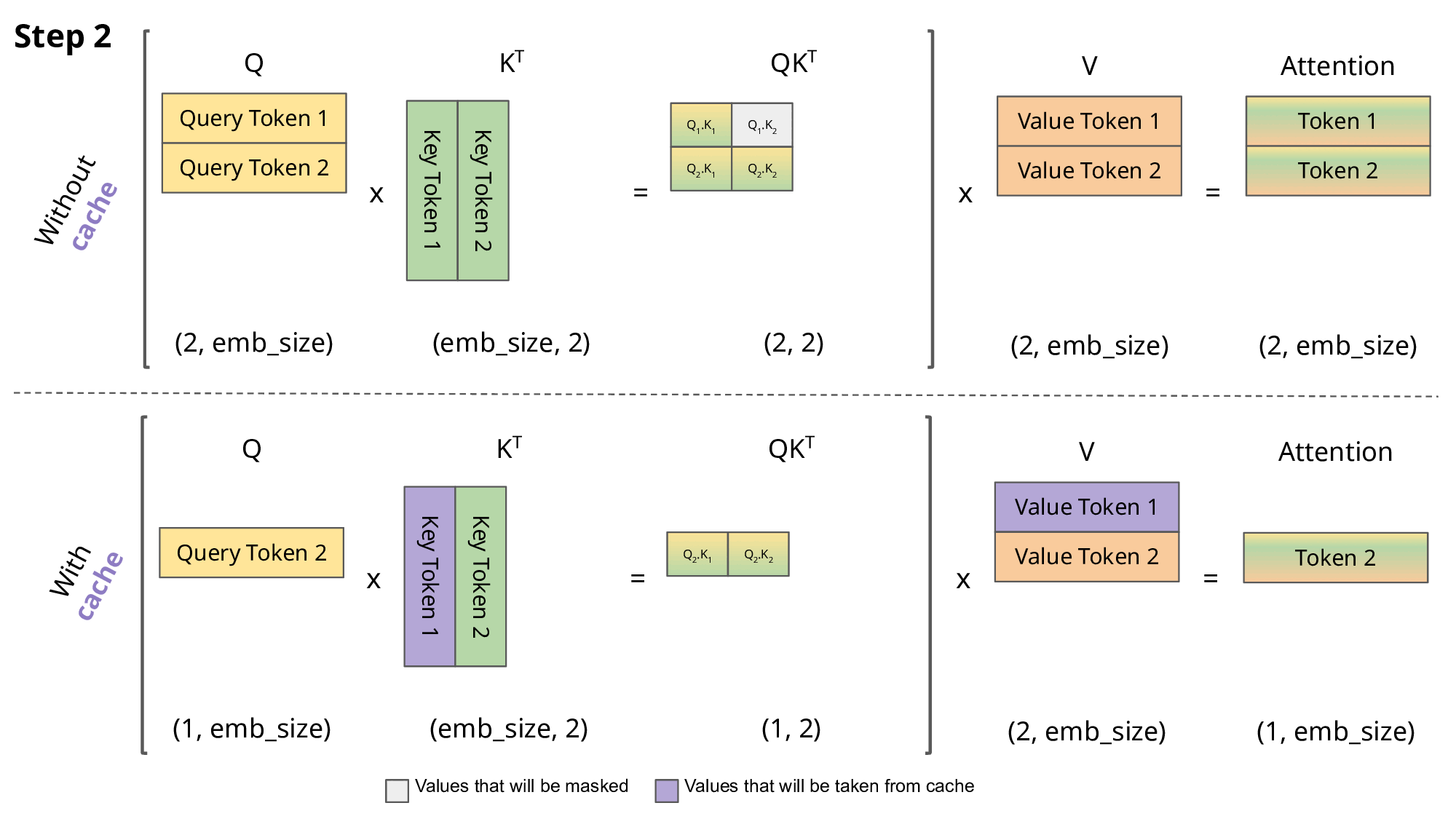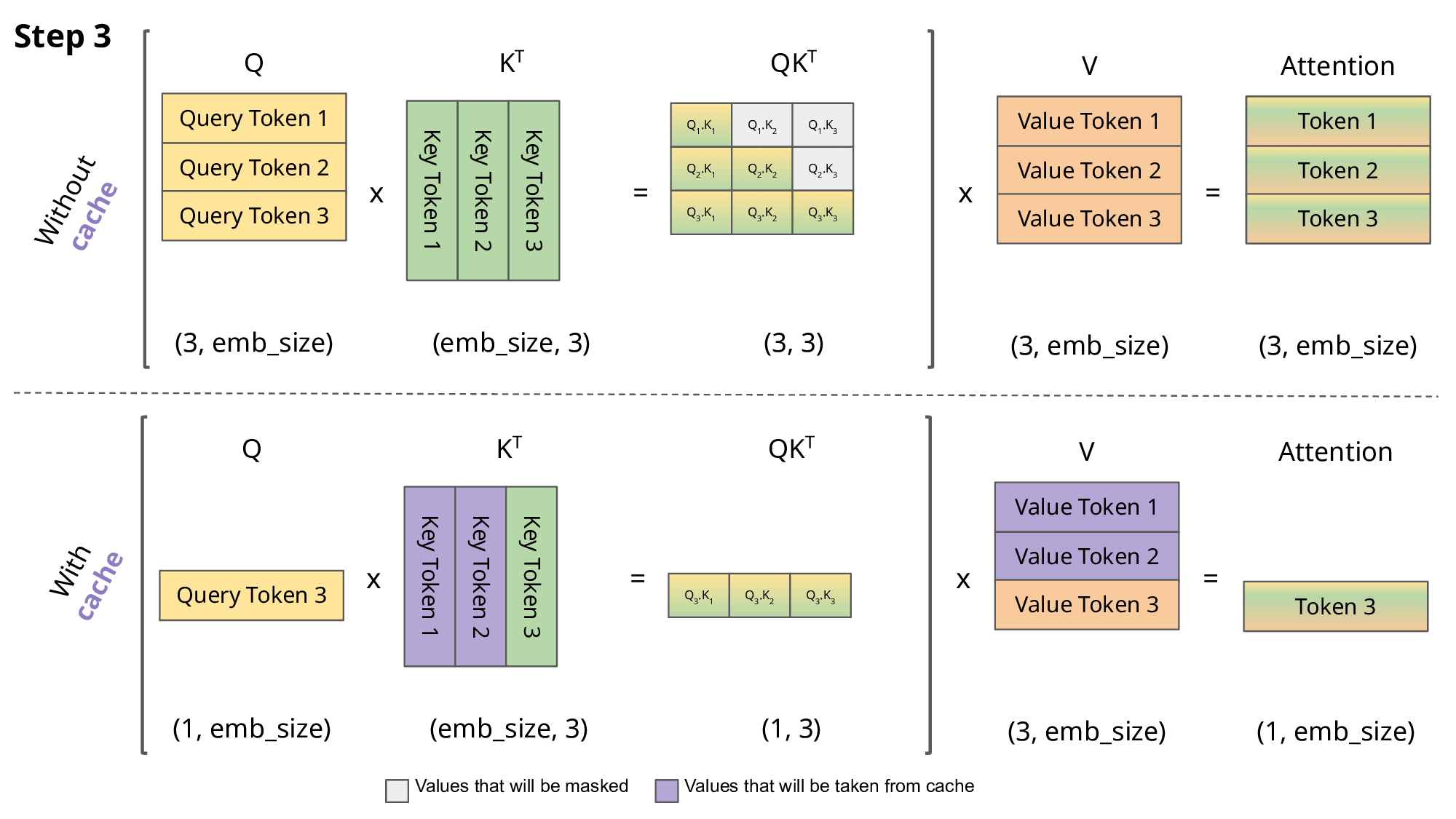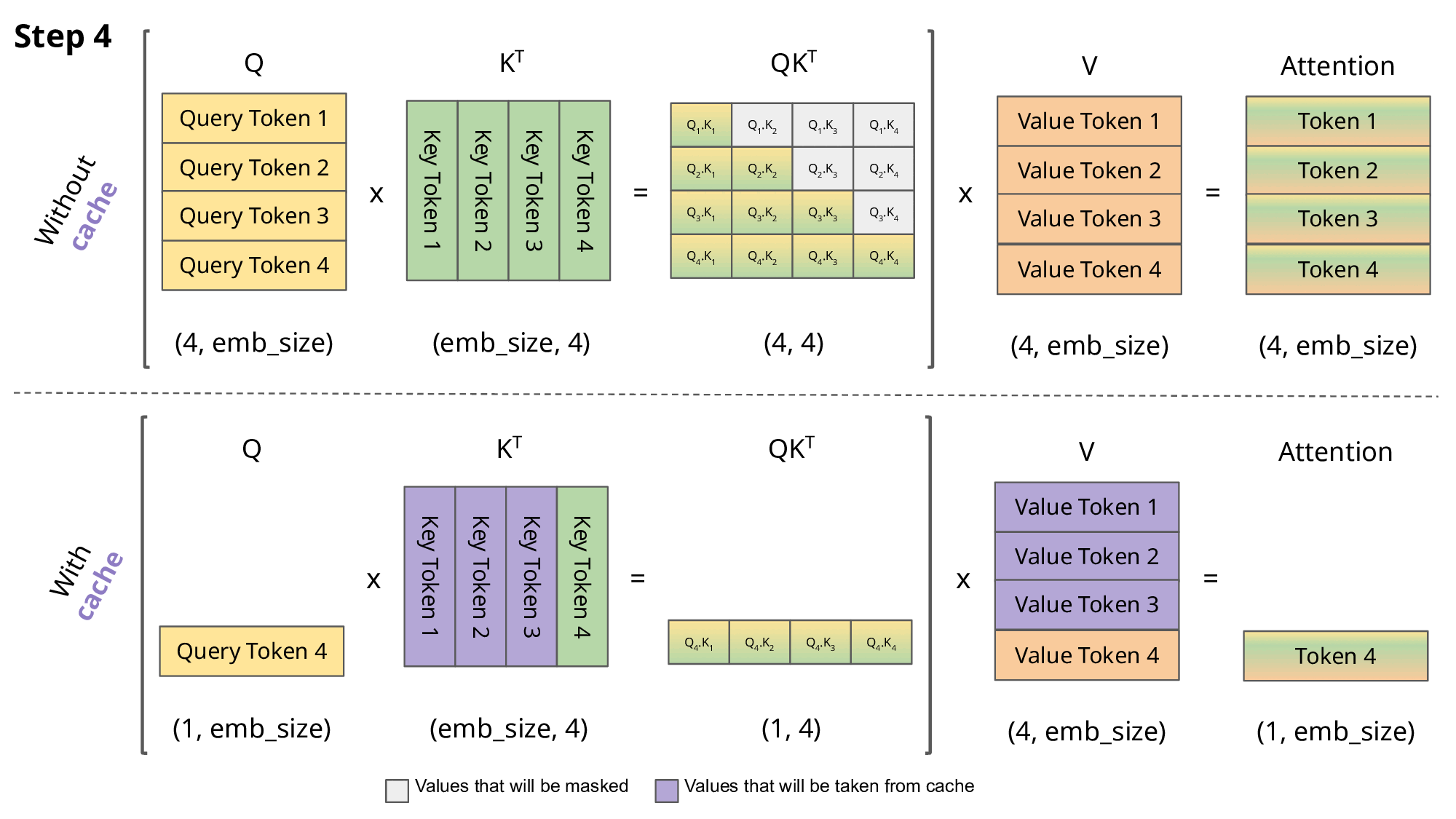
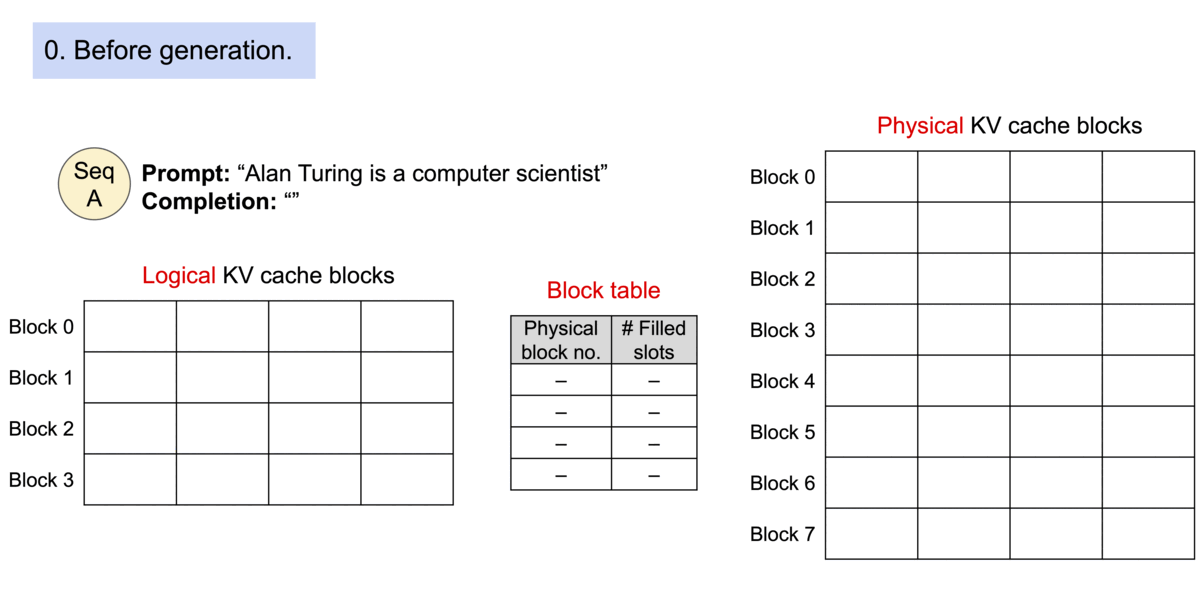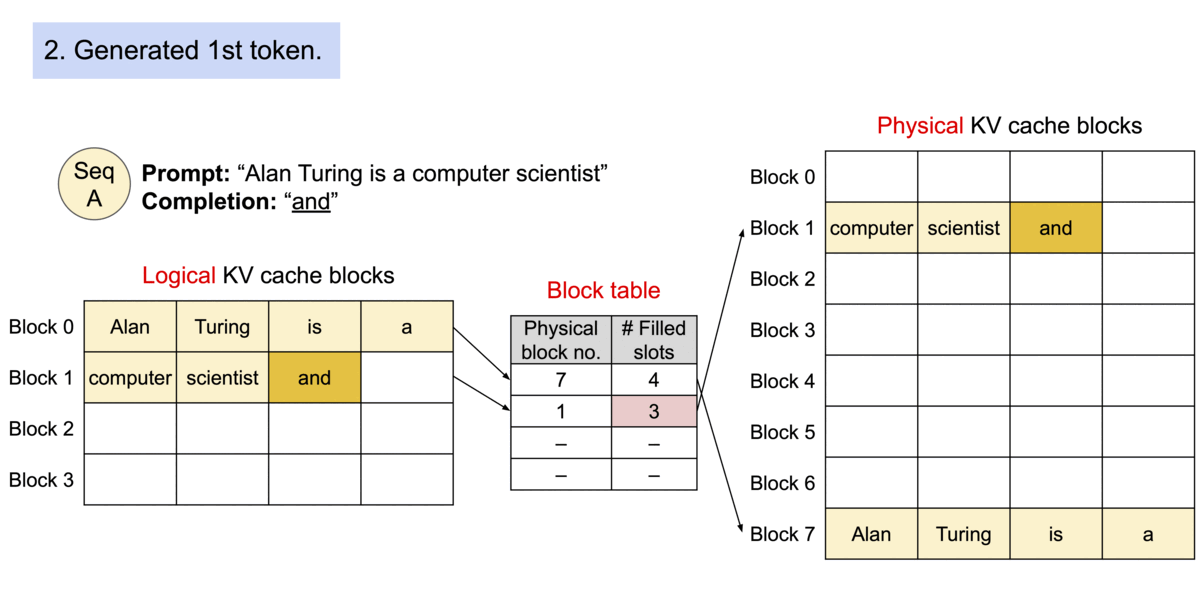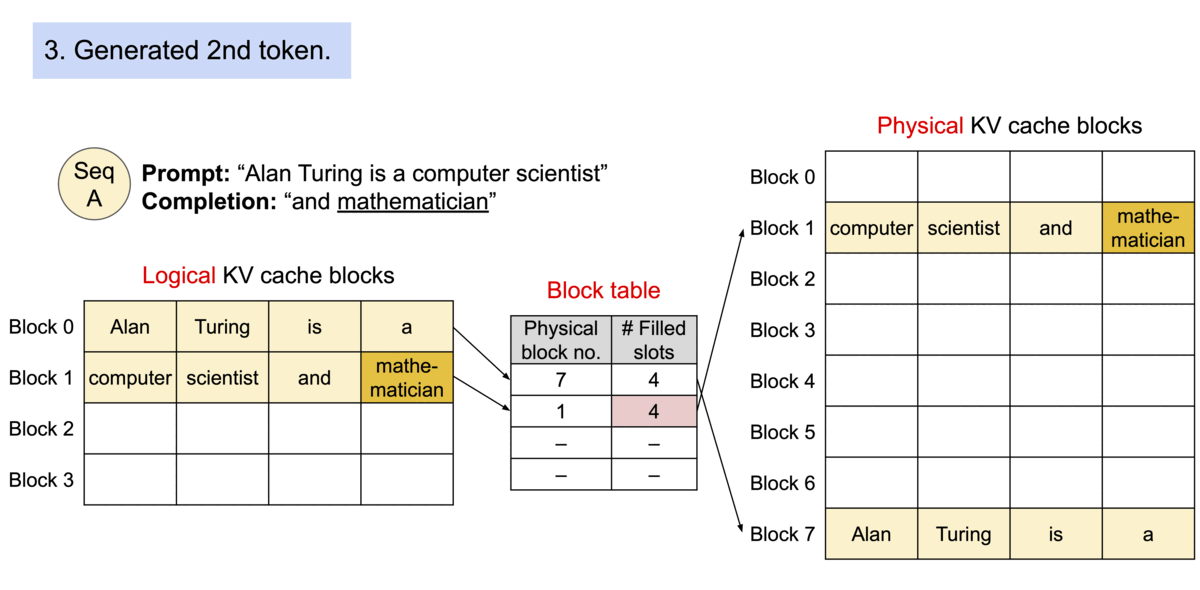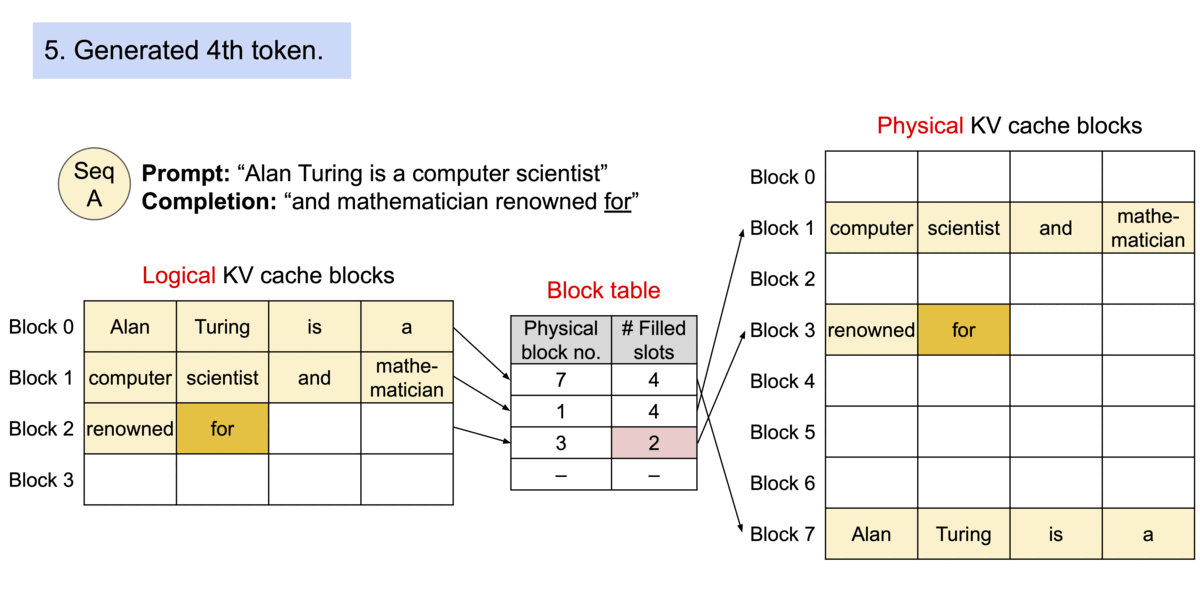
由前面对于Query、Key、Value 矩阵、Self-Attention 的介绍可知,模型在生成每个词时,需要计算前面词元的Key、Value 矩阵。从实现来说,可以在每次生成词元时,每一次都计算一次,但是这样会带来重复计算的问题,因此可以将前面词元的Key、Value 矩阵缓存下来,这样可以减少计算量,提高效率。这些缓存的Key、Value 矩阵就是KV Cache。
KV cache 通过缓存前面词元的 Key、Value 矩阵,可以减少计算量,提高效率。但是 KV cache 也会占用一定的显存,因此需要对其进行管理,以保证模型的显存占用在可接受的范围内。
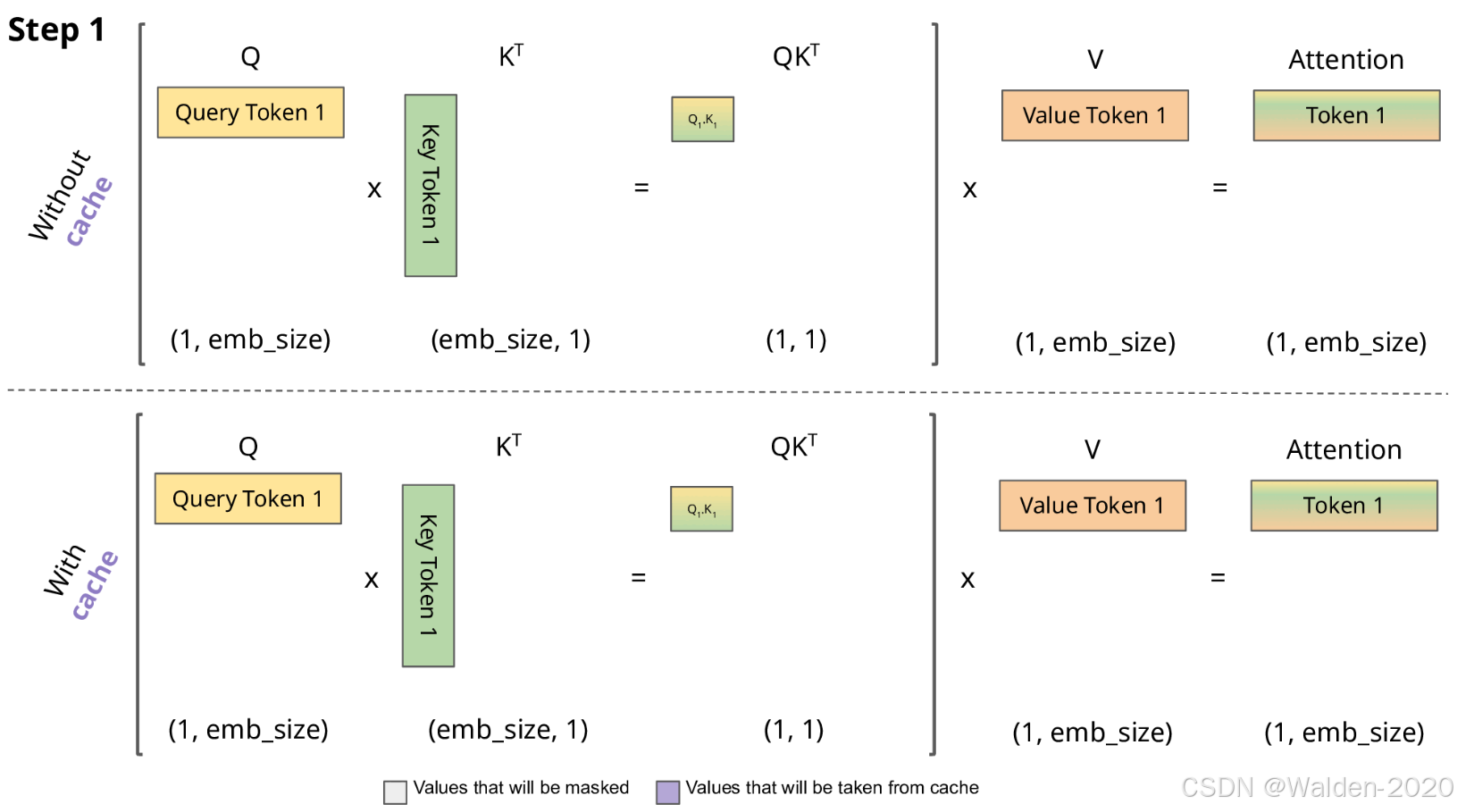
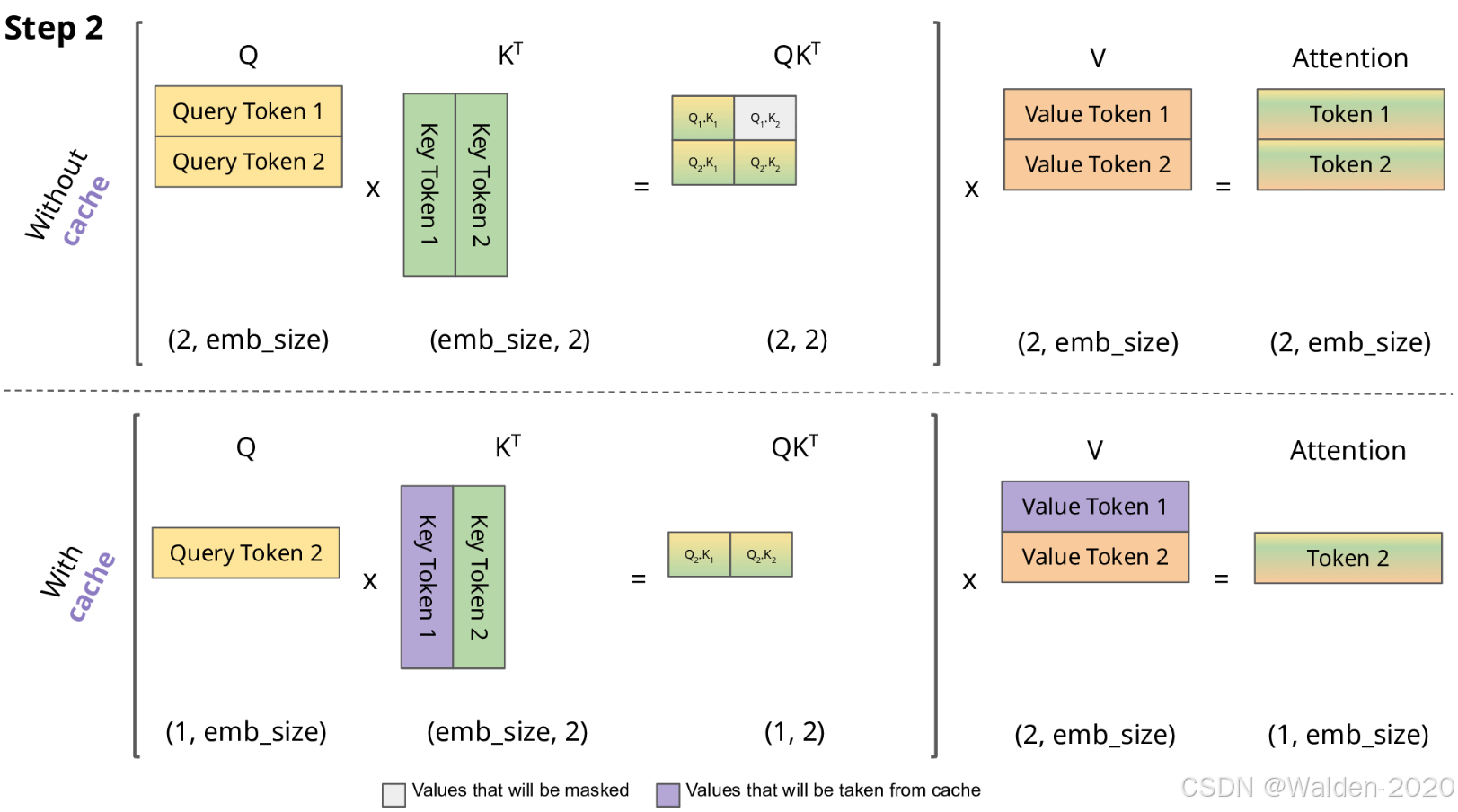
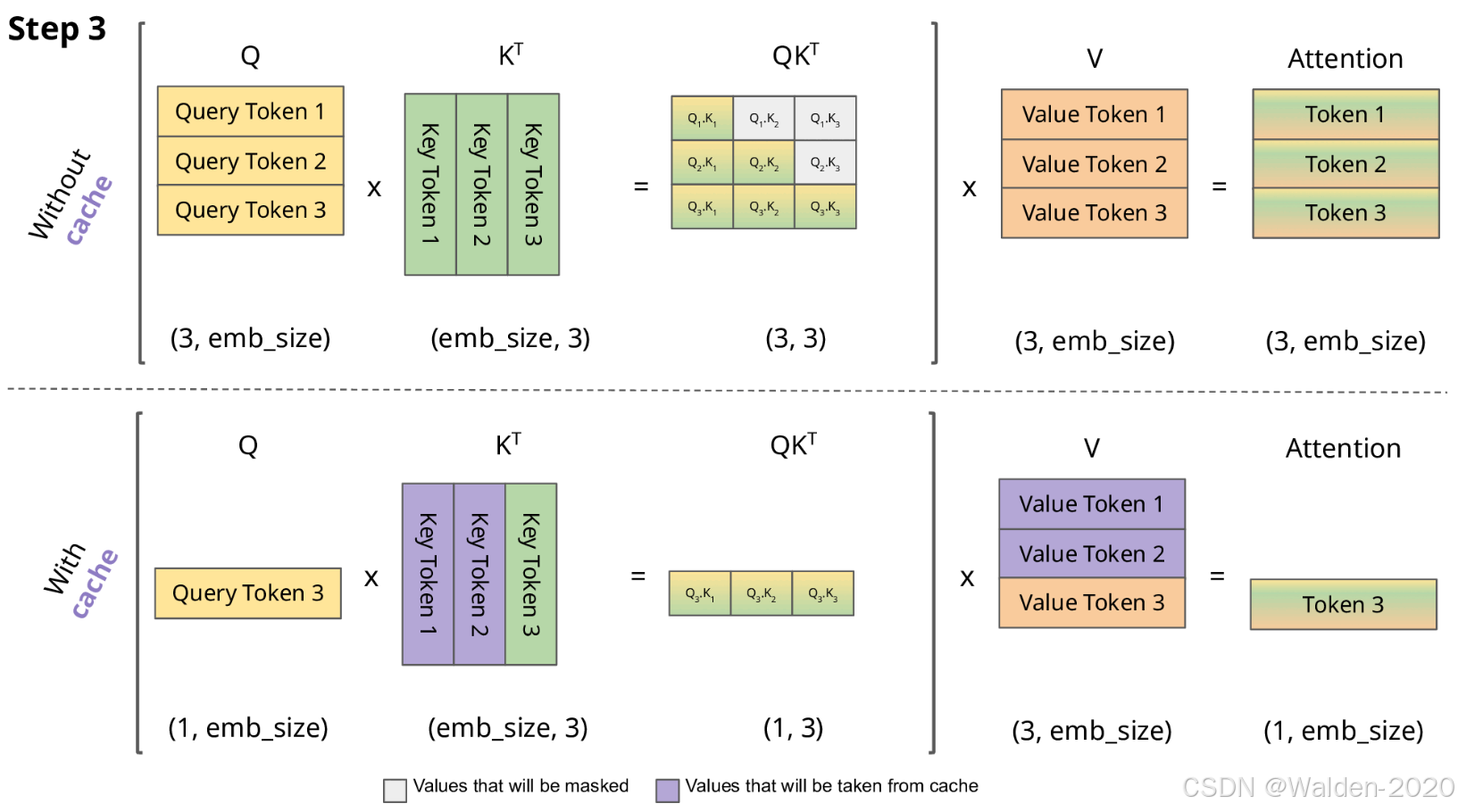
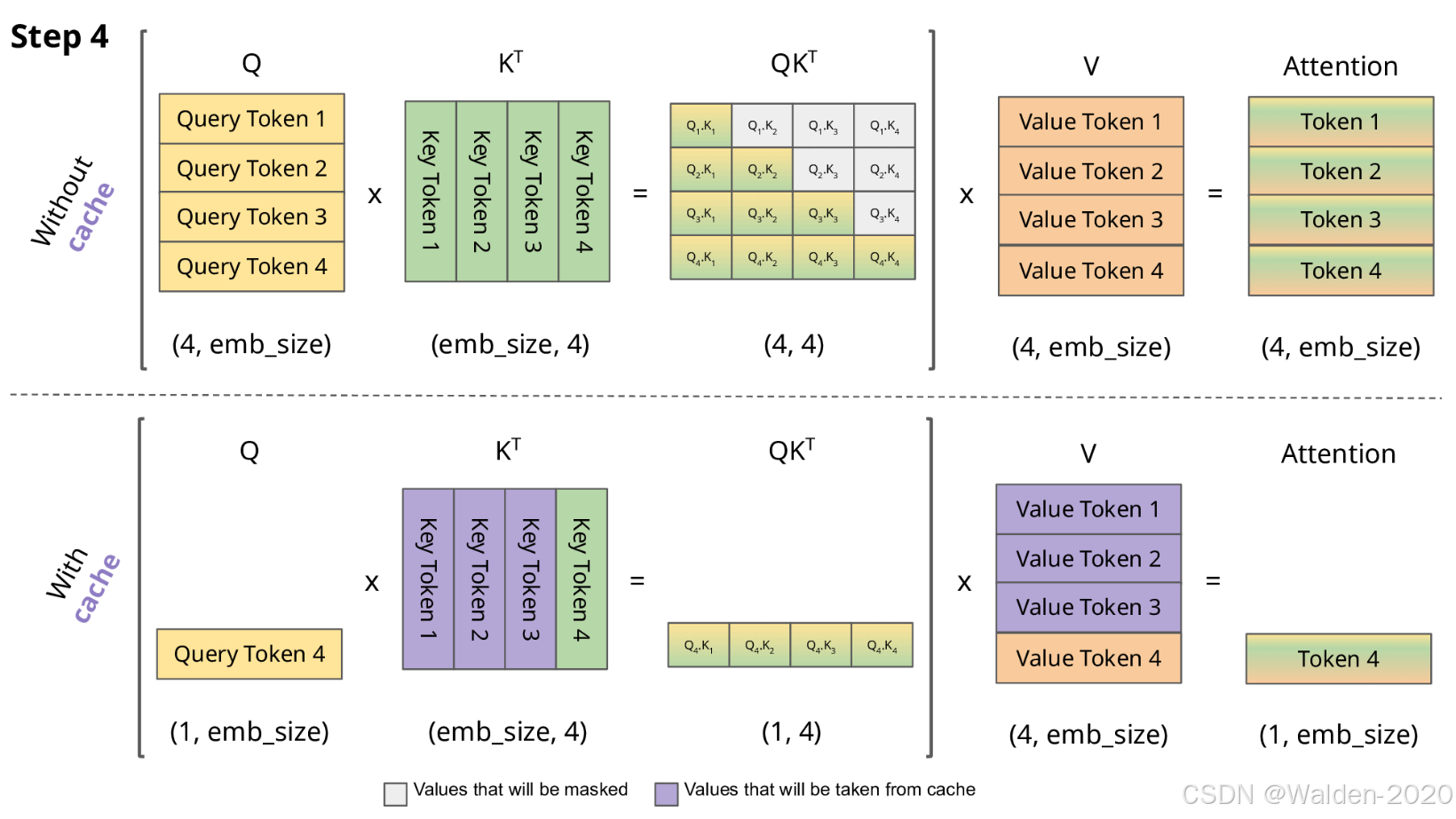
图片来源: https://miro.medium.com/1*uyuyOW1VBqmF5Gtv225XHQ.gif
对于KV cache 更加全面的介绍,可以参考 博客Transformers KV Caching Explained。
部署大模型:vLLM
部署模型所面对的挑战
当我们的大模型训练好以后,我们需要将其部署到生产环境中,以提供服务:Model as a Service(MaaS)。
图片来源: https://shopup.me/-cms/wp-content/uploads/2023/09/Data-Solutions-intro-1024x585.png
如前所述,KV cache 是模型推理过程中需要克服的一个挑战,但是它还不是唯一的挑战。在部署大模型时,我们还需要考虑以下几个方面:
- 多样化的硬件
- 多样化的模型架构
- 推理优化技术
- 模型版本管理
- 分布式模型部署
那面对这么多的问题,如果我们手动去解决,那么就会非常复杂,因此我们需要一个框架来帮助我们解决这些问题。这就是 vLLM。
vLLM 介绍
根据 vLLM 的官方文档描述:“vLLM is a fast and easy-to-use library for LLM inference and serving.”
vLLM 是一个快速、易于使用的库,用于 LLM 推理和服务。它提供了一种简单的方式来部署大型语言模型,以提供服务。vLLM 支持多样化硬件、多样化模型架构、推理优化技术,帮助用户快速、高效地部署大型语言模型。
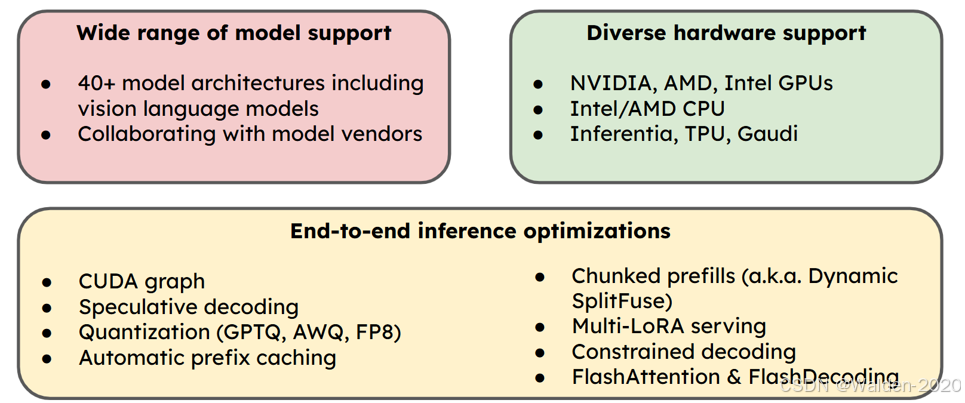
为什么使用 vLLM
在介绍为什么使用 vLLM 之前,我们先来深入看一下 模型部署所需要面对的挑战:
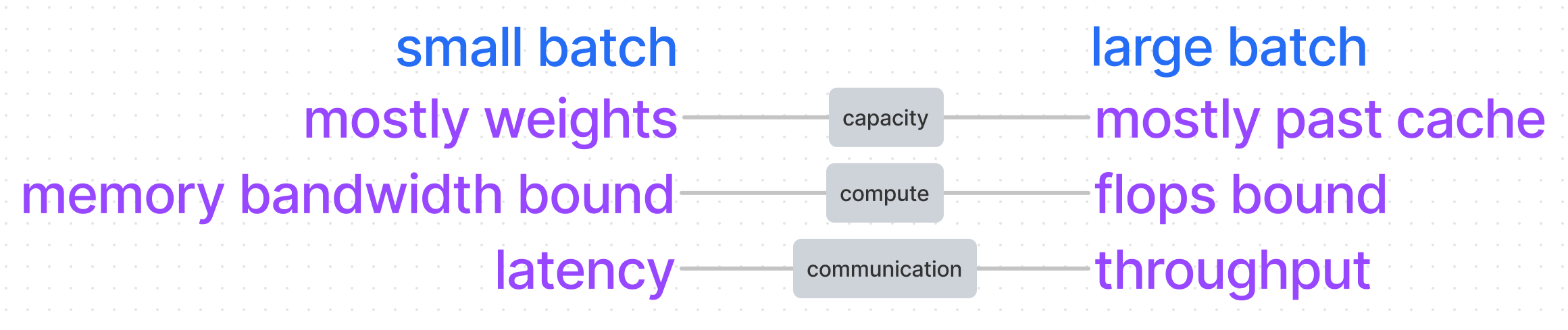
限制模型实际部署时能否成功和性能表现的因素有很多,其中最重要的因素包括:比如GPU的计算能力,GPU 的显存大小以及GPU 之间的通信速度等等。这些因素会分别带来 Compute-bound , Memory-bound 和 Network-bound 的问题。
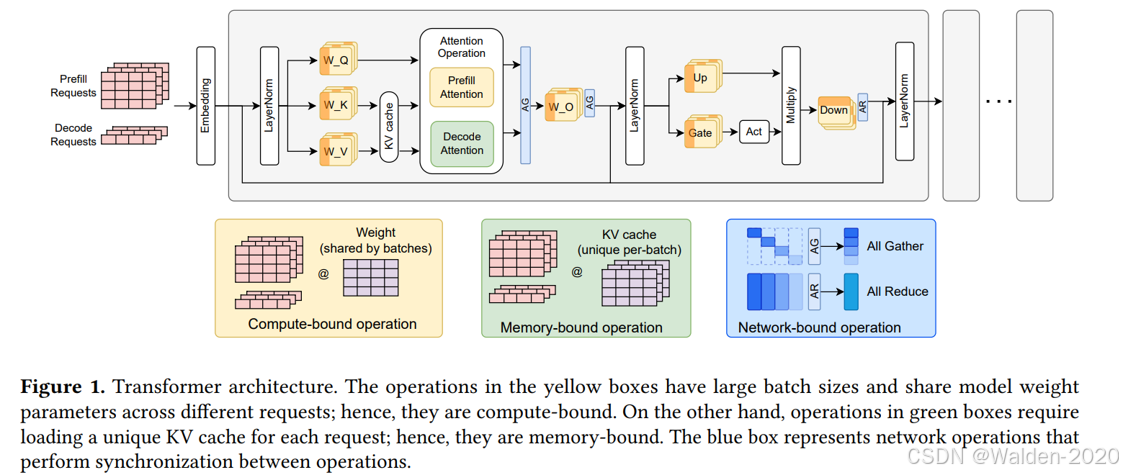
图片来源: https://arxiv.org/pdf/2408.12757
为了简化问题,我们不考虑网络通信的问题,那么我们可以将模型部署的问题简化为两个问题:Compute-bound 和 Memory-bound。Compute-bound 主要影响模型的计算速度,也就是性能,而在资源受限的设备上运行大模型时,Memory-bound 是更需要被考虑的问题,所以我们在这里主要讨论 Memory-bound 的问题。
回顾模型推理过程
如前所述,模型是一种自回归的方式生成文本,对于生成的每一个词元(token),都需要对它进行存储,如图所示
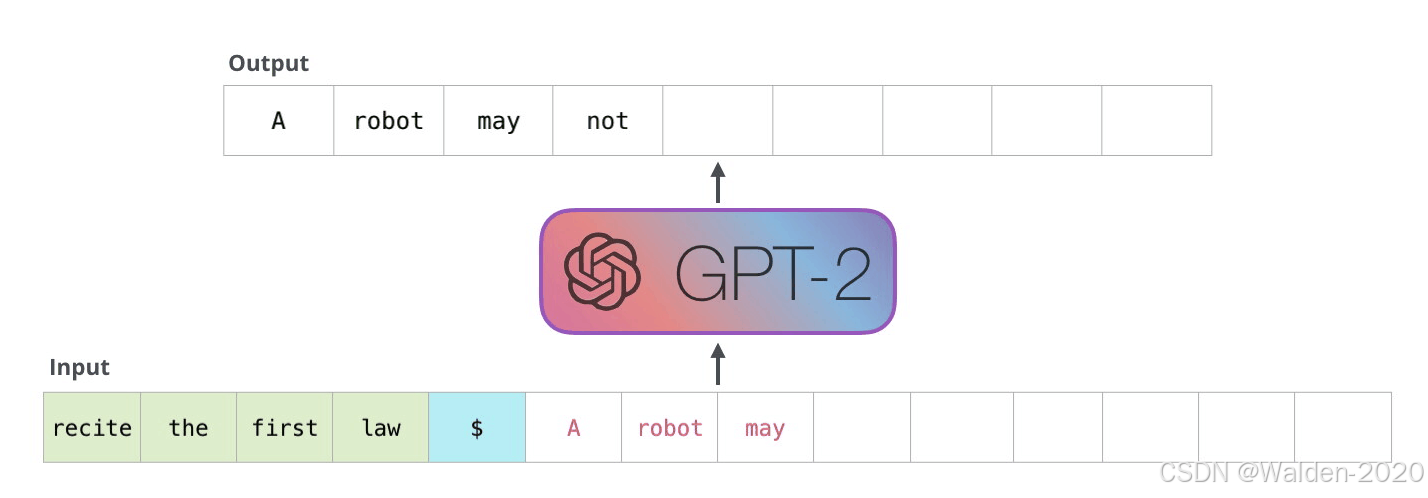
图片来源: https://jalammar.github.io/images/xlnet/gpt-2-autoregression-2.gif
这个过程,其实类似于我们对于一张线性表进行填充,每次填充一个元素,我们就需要将这个元素存储到内存中。那么对应的,就操作系统中对于线性表存在不同的实现方式,比如我们可以使用链表,也可以使用数组。由我们所熟知的数据结构知识,数组和链表在内存中的存储方式是不同的,数组是连续存储,而链表是不连续存储。
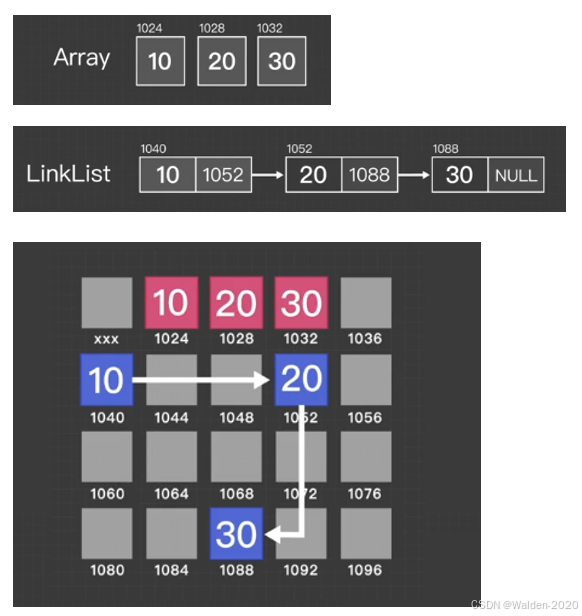
图片来源: https://www.douyin.com/video/7318587193046387977
对于数组和链表的内存管理来说,会不可避免地存在内碎片和外碎片的问题。与此类似,对于模型推理过程中的内存管理来说,也会存在内碎片和外碎片的问题。
相似的问题
首先,我们来看一下操作系统里的内碎片和外碎片的概念。
对于内存管理而言,如果我们以固定大小的块来分配内存,那么就会存在内碎片的问题。内碎片是指分配给进程的内存块中有一部分没有被利用,这部分空间就是内碎片。而外碎片是指已分配的内存块之间的空闲空间,这部分空间因为容量不足而无法分配给进程,这部分空间就是外碎片。内碎片和外碎片都会影响内存的利用率。
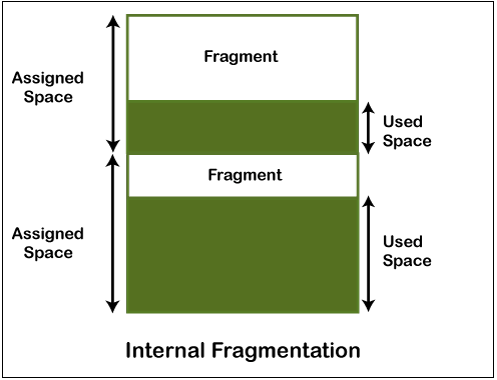
图片来源: https://d2jdgazzki9vjm.cloudfront.net/operating-system/images/internal-vs-external-fragmentation2.png
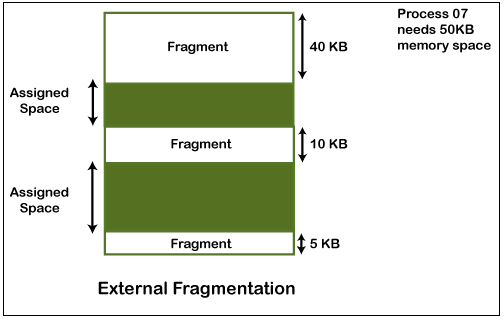
图片来源: https://d2jdgazzki9vjm.cloudfront.net/operating-system/images/internal-vs-external-fragmentation3.png
接着我们来看一下模型推理过程中的显存管理的内碎片和外碎片的问题。
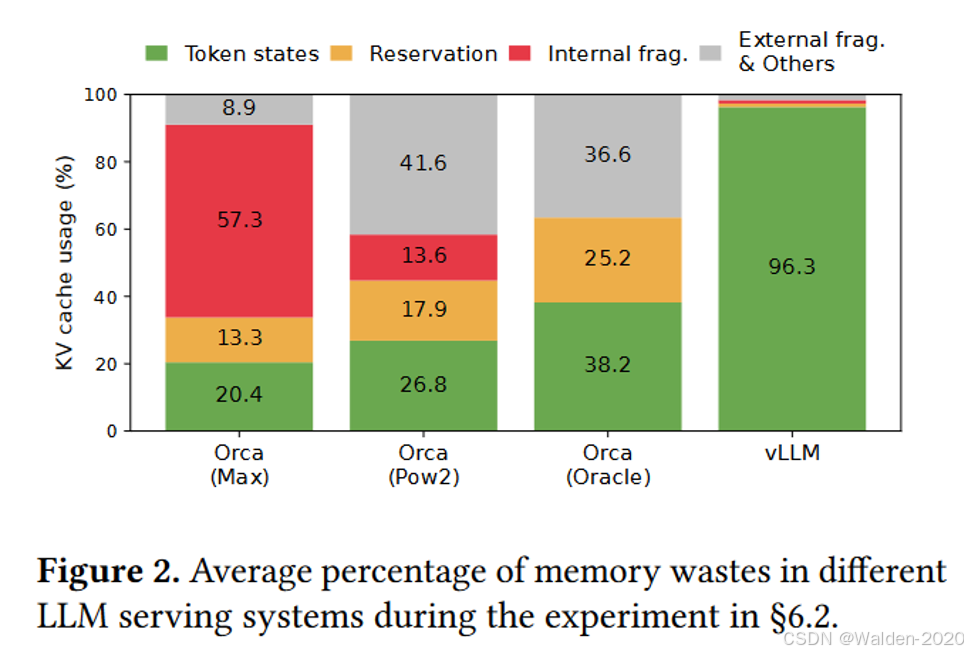
还是我们前面提到的,模型推理过程中,词是一个一个生成的,所以输出文本最后的长度是不确定的,同时输入的文本也是不确定的。不管输入长度是多少,输出长度是多少,之前的系统都需要按照最大序列长度来静态分配显存,这样就会导致三种显存的浪费:
- 预保留部分:请求的生命周期内,整块内存被保留,其他较短的请求无法利用当前未使用的内存部分。
- 内碎片部分:请求的实际长度往往远短于最大长度,导致内存中存在大量的内碎片。
- 外碎片部分:每个请求的预分配大小可能不同,导致内存中存在大量的外碎片。
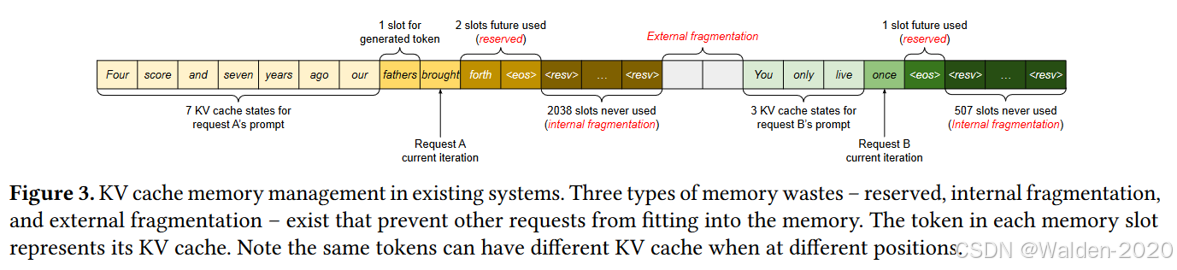
图片来源: https://arxiv.org/abs/2309.06180
相似的解决方案
对于操作系统中的内碎片和外碎片的问题,一种比较经典的解决方案是页式内存管理。页式内存管理是指将内存分为固定大小的页,然后将进程的地址空间分为固定大小的页框,这样就可以将进程的地址空间映射到物理内存中的页框上。这种方式可以减少内碎片和外碎片的问题,提高内存的利用率。 那么同样的,我们可以将模型推理过程中的显存管理问题类比为页式内存管理,通过页式内存管理的方式来解决显存管理中的内碎片和外碎片的问题,这就是PagedAttention 的核心思想。
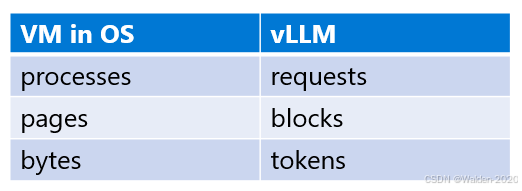
具体来说,我们可以将操作系统里虚拟内存的概念和模型推理过程中的概念进行类比
- 操作系统里的进程对应于模型推理过程中的请求
- 操作系统里的页对应于vLLM 系统的块
- 操作系统里的字节对应于模型推理过程中的词元
这样,PagedAttention 将每个序列的KV cache 划分为KV block。每个 block 包含固定数量令牌的键和值向量, 我们就通过 PageAttention 实现了在不连续的内存空间中存储连续的键和值。
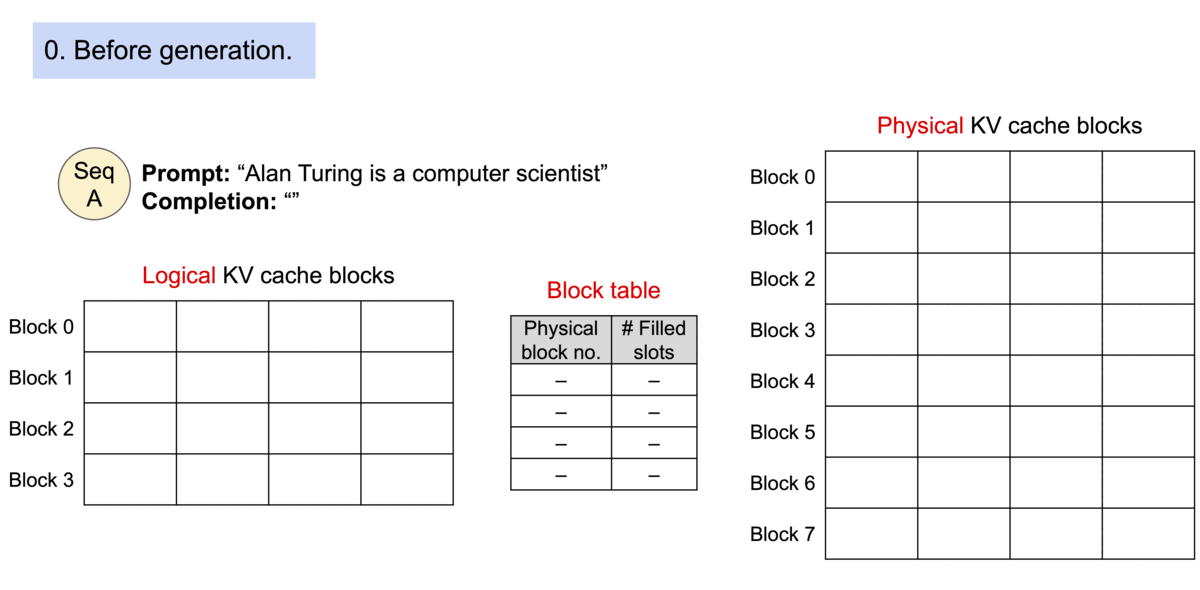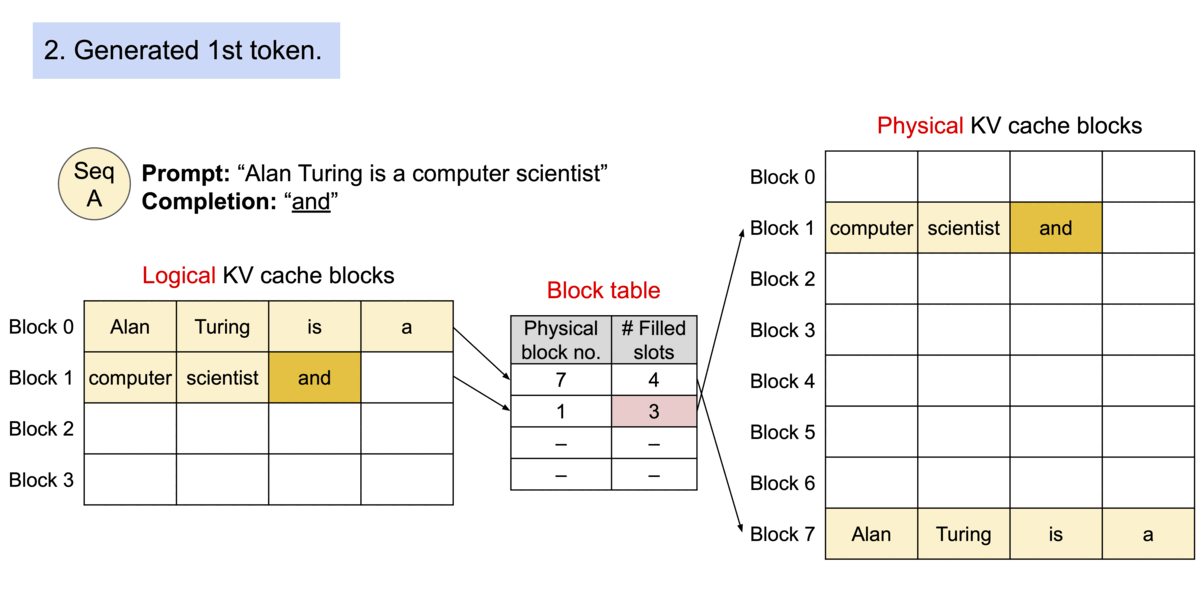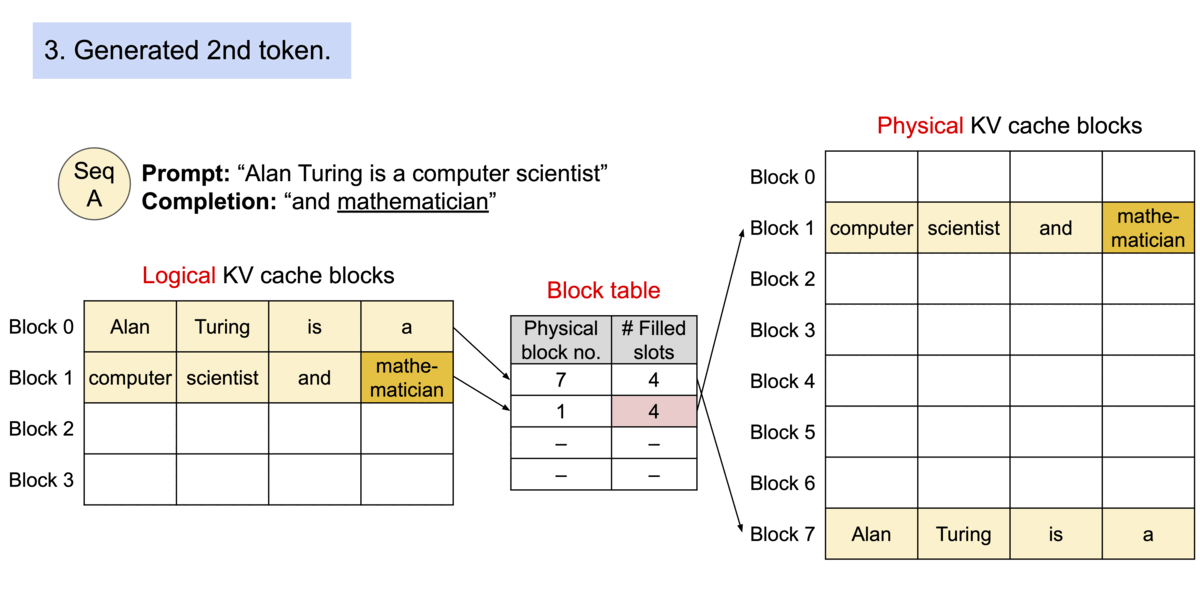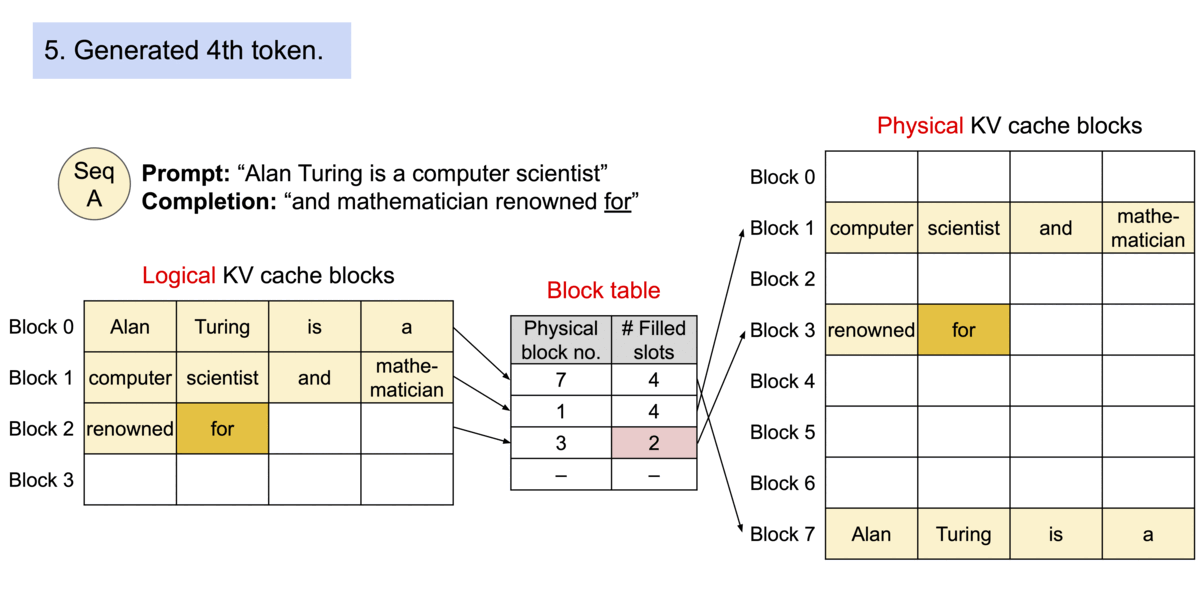
图片来源: https://blog.vllm.ai/assets/figures/annimation1.gif
vLLM 通过 PagedAttention 的方式来解决显存管理中的内碎片和外碎片的问题,最终显著提高了显存的利用率,这也是我们使用 vLLM 的原因之一。
图片来源: https://arxiv.org/pdf/2309.06180
怎么使用 vLLM
快速部署
对于 vLLM 的使用,我们可以参考官方文档 vLLM Documentation。在这里,我们主要介绍在Docker 环境和 Kubernetes 环境下如何使用 vLLM。
对于 Docker 环境,我们可以通过官方文档 vLLM Docker 来快速在 Docker 环境下部署 vLLM。
docker run --runtime nvidia --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--env "HUGGING_FACE_HUB_TOKEN=<secret>" \
-p 8000:8000 \
--ipc=host \
vllm/vllm-openai:latest \
--model mistralai/Mistral-7B-v0.1
对于 kubernetes,我们可以通过在 pod 的配置文件里使用类似的参数,来实现部署 vLLM。
apiVersion: v1
kind: Pod
metadata:
name: vllm-pod
spec:
containers:
- name: vllm-container
image: vllm/vllm-openai:latest
ports:
- containerPort: 8000
env:
- name: HUGGING_FACE_HUB_TOKEN
valueFrom:
secretKeyRef:
name: huggingface-secret
key: HUGGING_FACE_HUB_TOKEN
resources:
limits:
nvidia.com/gpu: 1
args: ["--model", "mistralai/Mistral-7B-v0.1"]
但是,通过参数的控制,我们可以实现对模型部署更加精确的控制。
参数列表
vLLM 文档 提供了详细的参数列表
usage: vllm serve [-h] [--model MODEL] [--tokenizer TOKENIZER]
[--skip-tokenizer-init] [--revision REVISION]
[--code-revision CODE_REVISION]
[--tokenizer-revision TOKENIZER_REVISION]
[--tokenizer-mode {auto,slow,mistral}] [--trust-remote-code]
[--download-dir DOWNLOAD_DIR]
[--load-format {auto,pt,safetensors,npcache,dummy,tensorizer,sharded_state,gguf,bitsandbytes,mistral}]
[--config-format {auto,hf,mistral}]
[--dtype {auto,half,float16,bfloat16,float,float32}]
[--kv-cache-dtype {auto,fp8,fp8_e5m2,fp8_e4m3}]
[--quantization-param-path QUANTIZATION_PARAM_PATH]
[--max-model-len MAX_MODEL_LEN]
[--guided-decoding-backend {outlines,lm-format-enforcer}]
[--distributed-executor-backend {ray,mp}] [--worker-use-ray]
[--pipeline-parallel-size PIPELINE_PARALLEL_SIZE]
[--tensor-parallel-size TENSOR_PARALLEL_SIZE]
[--max-parallel-loading-workers MAX_PARALLEL_LOADING_WORKERS]
[--ray-workers-use-nsight] [--block-size {8,16,32}]
[--enable-prefix-caching] [--disable-sliding-window]
[--use-v2-block-manager]
[--num-lookahead-slots NUM_LOOKAHEAD_SLOTS] [--seed SEED]
[--swap-space SWAP_SPACE] [--cpu-offload-gb CPU_OFFLOAD_GB]
[--gpu-memory-utilization GPU_MEMORY_UTILIZATION]
[--num-gpu-blocks-override NUM_GPU_BLOCKS_OVERRIDE]
[--max-num-batched-tokens MAX_NUM_BATCHED_TOKENS]
[--max-num-seqs MAX_NUM_SEQS] [--max-logprobs MAX_LOGPROBS]
[--disable-log-stats]
[--quantization {aqlm,awq,deepspeedfp,tpu_int8,fp8,fbgemm_fp8,modelopt,marlin,gguf,gptq_marlin_24,gptq_marlin,awq_marlin,gptq,compressed-tensors,bitsandbytes,qqq,experts_int8,neuron_quant,None}]
[--rope-scaling ROPE_SCALING] [--rope-theta ROPE_THETA]
[--enforce-eager]
[--max-context-len-to-capture MAX_CONTEXT_LEN_TO_CAPTURE]
[--max-seq-len-to-capture MAX_SEQ_LEN_TO_CAPTURE]
[--disable-custom-all-reduce]
[--tokenizer-pool-size TOKENIZER_POOL_SIZE]
[--tokenizer-pool-type TOKENIZER_POOL_TYPE]
[--tokenizer-pool-extra-config TOKENIZER_POOL_EXTRA_CONFIG]
[--limit-mm-per-prompt LIMIT_MM_PER_PROMPT]
[--mm-processor-kwargs MM_PROCESSOR_KWARGS] [--enable-lora]
[--max-loras MAX_LORAS] [--max-lora-rank MAX_LORA_RANK]
[--lora-extra-vocab-size LORA_EXTRA_VOCAB_SIZE]
[--lora-dtype {auto,float16,bfloat16,float32}]
[--long-lora-scaling-factors LONG_LORA_SCALING_FACTORS]
[--max-cpu-loras MAX_CPU_LORAS] [--fully-sharded-loras]
[--enable-prompt-adapter]
[--max-prompt-adapters MAX_PROMPT_ADAPTERS]
[--max-prompt-adapter-token MAX_PROMPT_ADAPTER_TOKEN]
[--device {auto,cuda,neuron,cpu,openvino,tpu,xpu}]
[--num-scheduler-steps NUM_SCHEDULER_STEPS]
[--multi-step-stream-outputs]
[--scheduler-delay-factor SCHEDULER_DELAY_FACTOR]
[--enable-chunked-prefill [ENABLE_CHUNKED_PREFILL]]
[--speculative-model SPECULATIVE_MODEL]
[--speculative-model-quantization {aqlm,awq,deepspeedfp,tpu_int8,fp8,fbgemm_fp8,modelopt,marlin,gguf,gptq_marlin_24,gptq_marlin,awq_marlin,gptq,compressed-tensors,bitsandbytes,qqq,experts_int8,neuron_quant,None}]
[--num-speculative-tokens NUM_SPECULATIVE_TOKENS]
[--speculative-draft-tensor-parallel-size SPECULATIVE_DRAFT_TENSOR_PARALLEL_SIZE]
[--speculative-max-model-len SPECULATIVE_MAX_MODEL_LEN]
[--speculative-disable-by-batch-size SPECULATIVE_DISABLE_BY_BATCH_SIZE]
[--ngram-prompt-lookup-max NGRAM_PROMPT_LOOKUP_MAX]
[--ngram-prompt-lookup-min NGRAM_PROMPT_LOOKUP_MIN]
[--spec-decoding-acceptance-method {rejection_sampler,typical_acceptance_sampler}]
[--typical-acceptance-sampler-posterior-threshold TYPICAL_ACCEPTANCE_SAMPLER_POSTERIOR_THRESHOLD]
[--typical-acceptance-sampler-posterior-alpha TYPICAL_ACCEPTANCE_SAMPLER_POSTERIOR_ALPHA]
[--disable-logprobs-during-spec-decoding [DISABLE_LOGPROBS_DURING_SPEC_DECODING]]
[--model-loader-extra-config MODEL_LOADER_EXTRA_CONFIG]
[--ignore-patterns IGNORE_PATTERNS]
[--preemption-mode PREEMPTION_MODE]
[--served-model-name SERVED_MODEL_NAME [SERVED_MODEL_NAME ...]]
[--qlora-adapter-name-or-path QLORA_ADAPTER_NAME_OR_PATH]
[--otlp-traces-endpoint OTLP_TRACES_ENDPOINT]
[--collect-detailed-traces COLLECT_DETAILED_TRACES]
[--disable-async-output-proc]
[--override-neuron-config OVERRIDE_NEURON_CONFIG]
这些参数也可以在 Docker 环境和 Kubernetes 环境下使用,通过参数的控制,我们可以实现对模型部署更加精确的控制。
此处以 --trust-remote-code 为例,建议部署的时候使用这个参数,因为这个参数可以让 vLLM 信任远程代码,从而回避因为代码不被信任而导致代码部署的问题: [Usage]: Running Phi-3-small-128k-instruct with v0.4.3 without --trust-remote-code
当我们需要加入--trust-remote-code参数时,我们可以在 Docker 环境和 Kubernetes 环境下使用类似的参数,来实现部署 vLLM。
对于 Docker 环境,我们可以在命令行中加入 --trust-remote-code 参数
docker run --runtime nvidia --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--env "HUGGING_FACE_HUB_TOKEN=<secret>" \
-p 8000:8000 \
--ipc=host \
vllm/vllm-openai:latest \
--model mistralai/Mistral-7B-v0.1 \
--trust-remote-code
对于 kubernetes,我们可以在 pod 的配置文件里使用类似的参数,来实现部署 vLLM。
apiVersion: v1
kind: Pod
metadata:
name: vllm-pod
spec:
containers:
- name: vllm-container
image: vllm/vllm-openai:latest
ports:
- containerPort: 8000
env:
- name: HUGGING_FACE_HUB_TOKEN
valueFrom:
secretKeyRef:
name: huggingface-secret
key: HUGGING_FACE_HUB_TOKEN
resources:
limits:
nvidia.com/gpu: 1
args: ["--model", "mistralai/Mistral-7B-v0.1", "--trust-remote-code"]
那通过参数列表可知,vLLM 提供了丰富的参数,可以帮助我们更好地控制模型的部署,提高模型的性能。
因为我们主要考虑的是显存的问题,所以我们此处只有限地讨论几个显著影响显存的参数:
- –model: Name or path of the huggingface model to use.
- –max-model-len: Model context length. If unspecified, will be automatically derived from the model config.
- –cpu-offload-gb: The space in GiB to offload to CPU, per GPU. Default is 0, which means no offloading. Intuitively, this argument can be seen as a virtual way to increase the GPU memory size. Default: 0
- –gpu-memory-utilization: The fraction of GPU memory to be used for the model executor, which can range from 0 to 1. Default: 0.9
- –max-num-seqs: Maximum number of sequences per iteration. Default: 256
- –enforce-eager: Always use eager-mode PyTorch. If False, will use eager mode and CUDA graph in hybrid for maximal performance and flexibility.
影响显存的参数
- –model 参数是指模型的名称或路径,不同的模型会占用不同的显存。对于大模型来说,显存占用会更大,因此我们需要根据实际情况选择合适的模型。
图片来源: https://arxiv.org/pdf/2402.06196
- –max-model-len 参数是指模型的最大长度,如果不指定,将从模型配置中自动推导出。模型的最大长度会影响显存的占用,因此我们需要根据实际情况选择合适的模型长度。

- –cpu-offload-gb 参数是指每个 GPU 要卸载到 CPU 的空间,单位为 GiB。默认值为 0,表示不卸载。直观地说,这个参数可以看作是一种虚拟的方式来增加 GPU 的内存大小。通过这个参数,我们可以将一部分显存卸载到 CPU,从而减少 GPU 的显存占用。例如,如果您拥有一块24 GB的GPU,并将该值设置为10,从虚拟上来看,可以将其视为一块34 GB的GPU。这样,您可以加载一个13B的模型,使用BF16权重,而该模型至少需要26 GB的GPU内存。请注意,这需要快速的CPU-GPU互连,因为模型的一部分在每次前向传播中都是动态地从CPU内存加载到GPU内存的。默认值:0
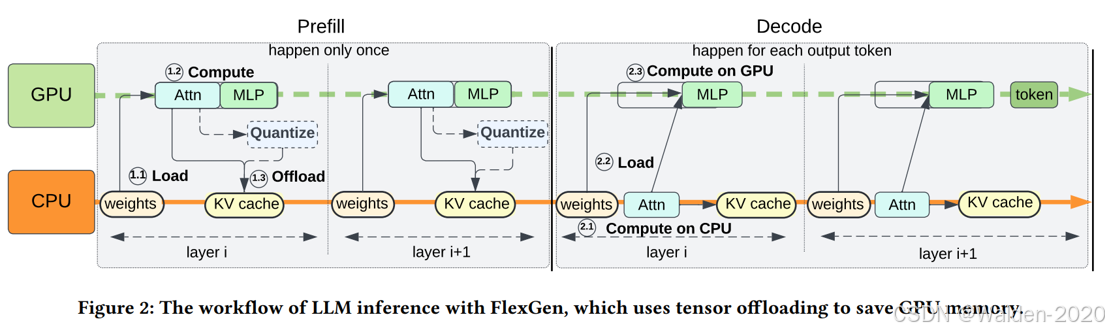
图片来源: https://pasalabs.org/papers/2024/llm_offload_2024.pdf 本图仅作示意,不意指 vLLM 的实现方式
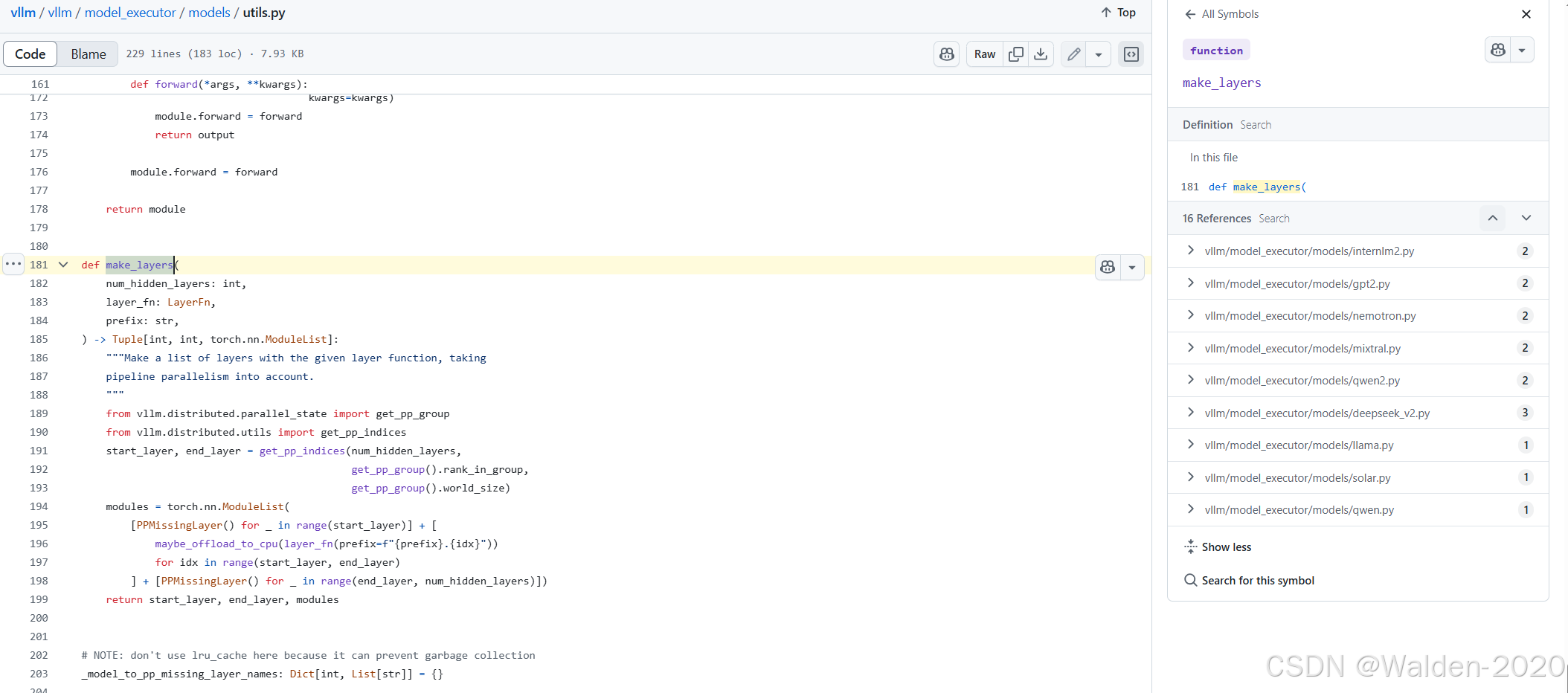
实际上,cpu-offload-gb 只分担了模型的参数部分,并且这一个功能仅支持部分特定结构的模型;具体支持哪些模型,可以查看 models/utils.py#L181 处所定义的 make_layers 函数, 被哪些模型所调用。
- –gpu-memory-utilization 参数是指要用于模型执行器的 空闲 GPU 内存的比率,范围从 0 到 1。默认值为 0.9。通过这个参数,我们可以控制 GPU 内存的使用率,从而提高 GPU 的利用率。
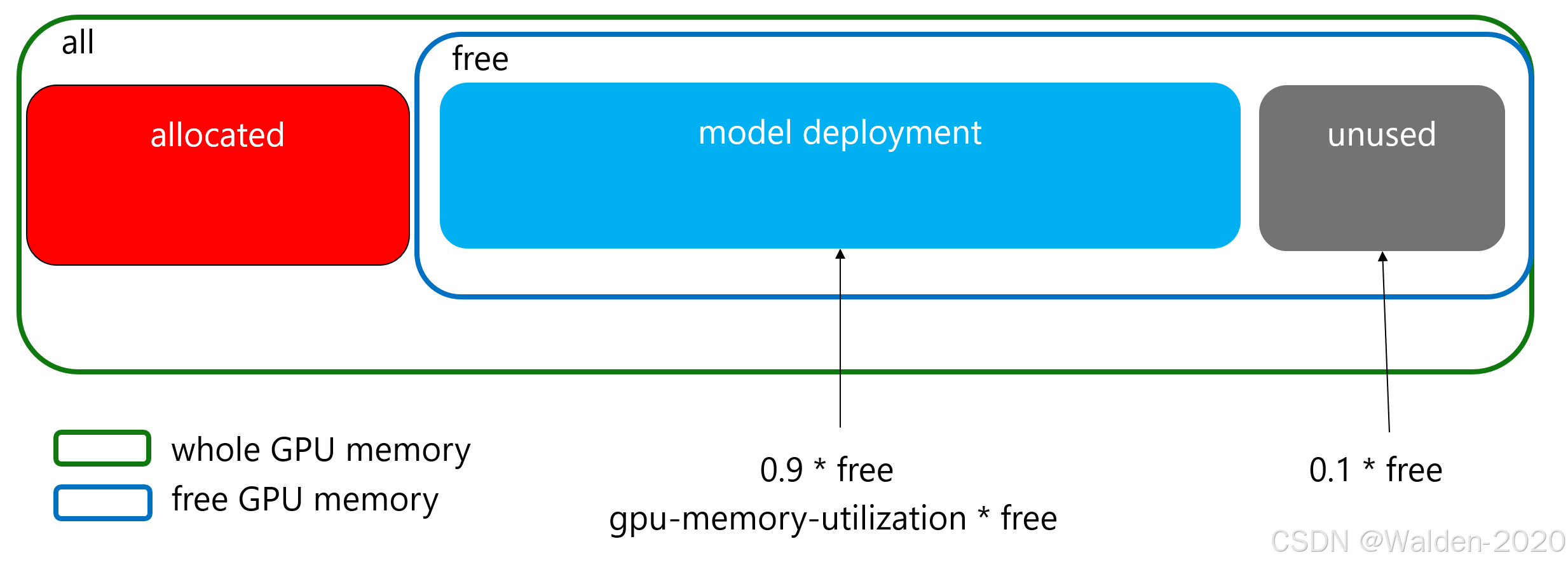
具体来说,当我们需要部署模型时,GPU上的显存分布可能是这样的,包括两部分:
- Allocated(已分配): 这一部分用红色表示,它显示了已经被使用的GPU内存,这部分的取值也有可能是 0, 代表没有被使用的GPU内存。
- Free(空闲): 用蓝色框表示的是当前未被使用的GPU内存。
模型部署只能使用 Free 部分的 GPU 内存,但是是否是需要全部使用 Free 部分的 GPU 内存,这就需要根据实际情况来决定。通过调整 --gpu-memory-utilization 参数,我们可以控制 GPU 内存的使用率,从而提高 GPU 的利用率。
所以在模型部署后,GPU上的显存分布可能是这样的,包括三部分:
-
Allocated(已分配): 这一部分用红色表示,它显示了已经被使用的GPU内存,这部分的取值也有可能是 0, 代表没有被使用的GPU内存。
-
Model Deployment(模型部署): 这一部分代表了未来可能用于模型部署的内存。
-
Unused(未使用): 用灰色表示,是完全未被利用的内存。这部分的取值也有可能是 0, 代表没有被剩余的GPU内存。
-
–max-num-seqs 参数是指每次迭代的最大序列数。默认值为 256。通过这个参数,我们可以控制每次迭代的序列数,从而提高 GPU 的利用率。同时增加这个参数的值,也会使得显存的占用更大。
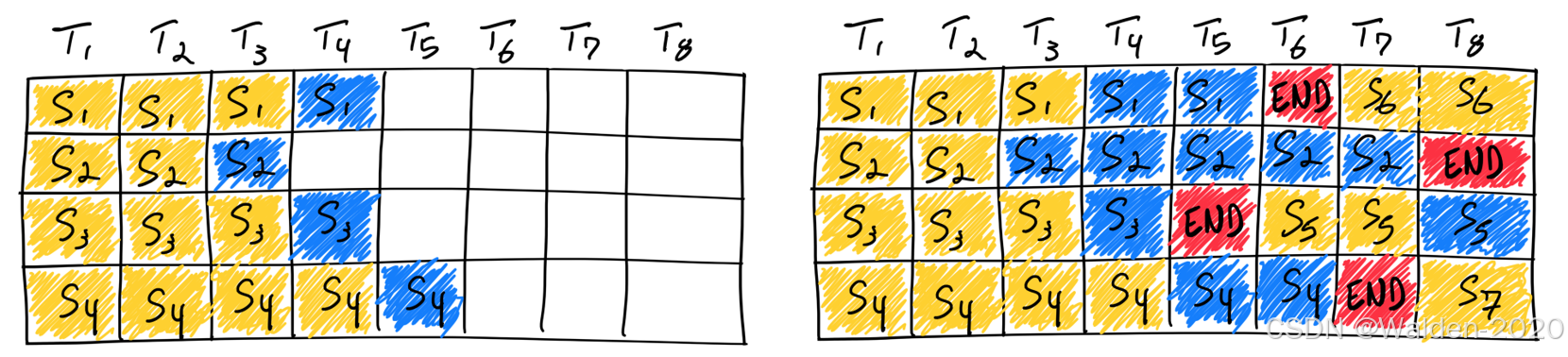
图片来源: https://www.anyscale.com/blog/continuous-batching-llm-inference
- –enforce-eager 参数是指始终使用 PyTorch 的 eager 模式。如果为 False,则将使用 eager 模式和混合模式的 CUDA 图形以获得最大性能和灵活性。CUDA graph 是一种用于优化 GPU 计算的技术,通过花费一些额外的显存来提高模型的性能。

图片来源: https://pytorch.org/blog/accelerating-pytorch-with-cuda-graphs
所以通过这些参数的控制,我们可以更好地控制模型的部署,提高模型的性能。
vLLM中的性能与限制
吞吐量和延迟是衡量模型部署性能的两个重要指标。吞吐量是指单位时间内处理的请求数量,延迟是指处理一个请求所需的时间。在模型部署中,我们通常会关注这两个指标,以评估模型的性能。延迟和吞吐量无法同时实现。增加最大序列数(批量大小)可以提高服务的吞吐量并减少总时间消耗,但平均延迟也会随之增加。换句话说,越是限制模型的资源消耗,模型的性能就会不可避免地受到损害。

图片来源: https://kipp.ly/img/arithmetic_transformers/batchsize.png
在此引入一篇博客:vLLM 框架:时延与吞吐的研究 的实验:
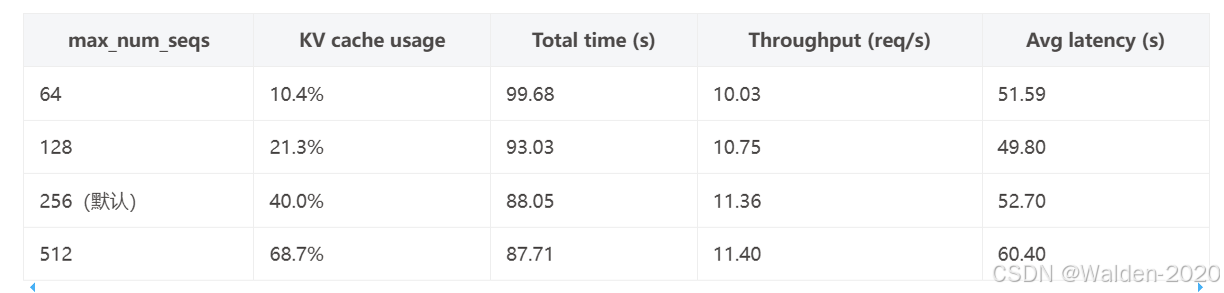
根据表中的数据,我们可以看到:
- 当序列数从64增加到512时,KV缓存的使用率从10.4%增加到68.7%。
- 总时间随着序列数的增加而减少,说明处理更多序列的效率更高。
- 吞吐量随着序列数的增加而提高,这表明系统能够更高效地处理更多的请求。
- 平均延迟时间从64序列的51.59秒增加到了512序列的60.40秒。
从这些数据可以分析出,随着处理的序列数量的增加,系统可以更有效率地使用KV缓存,并且提高处理请求的吞吐量,但同时会导致每个请求的平均延迟略微增加。
所以,我们看出,吞吐量和延迟是相互制约的,尤其是在模型受到资源的限制时,所以在这样的前提下,我们就可以讨论预测模型部署的最低显存了。
在vLLM中使用机器学习预测最小内存占用
为什么我们需要预测最小内存占用?
在内存不足的 GPU 上部署大型模型会导致内存溢出(OOM)问题。通过收集少量数据点,可以预测在特定设置下的最小内存需求,从而提高部署成功率并减少内存浪费。
vLLM是如何确定内存使用量的?

当我们通过容器部署vLLM时,我们通过一些外部测量工具来确定内存使用量。但是,这种方法并不能告诉我们为什么是这样的一个值,所以我们需要深入到容器的内部,来了解 vLLM 是如何确定内存使用量的。深入到容器的内部,实际上就是深入到vLLM的源代码中,来了解 vLLM 是如何确定内存使用量的。
来自源代码的结论
通过阅读vLLM的源代码:
- worker.py#L173 处的
determine_num_available_blocks函数,我们可以看到vLLM 是怎么计算num_gpu_blocks的。 - worker.py#L437 处的
determine_max_num_seqs函数,我们可以看到 num_gpu_blocks 不能无限制的小,而是有一个最小值的。
所以,以公式的形式,我们可以得到:
由于
- (total * utilization - peak) / cache_block_size = num_gpu_block
- num_gpu_block * block_size = max_seq_len >= max_model_len
则可得
(total * utilization - peak )/ cache_block_size >= max_model_len / block_size
所以可得
total * utilization >= (max_model_len*cache_block_size ) / block_size + peak
所以 (max_model_len*cache_block_size ) / block_size + peak 即为所需显存的最小值
也就是如下图所示
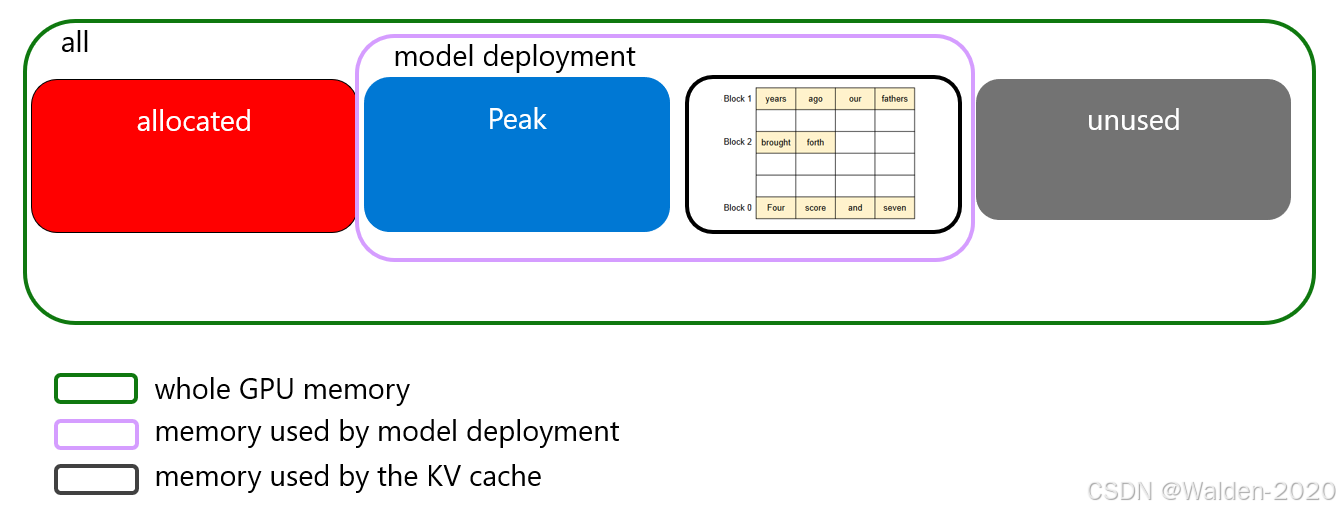
GPU内存被分为三个主要区域:
-
Allocated (已分配): 红色区域表示已经被分配出去且正在使用的GPU内存。
-
Model Deployment (模型部署): 蓝色区域表示被用于模型部署的内存。它主要包括模型部署时的Peak 部分占用的内存 和KV cache 所占用的内存。
-
Unused (未使用): 灰色区域表示当前未被使用的GPU内存。
更进一步,我们分析 模型部署部分的内存:
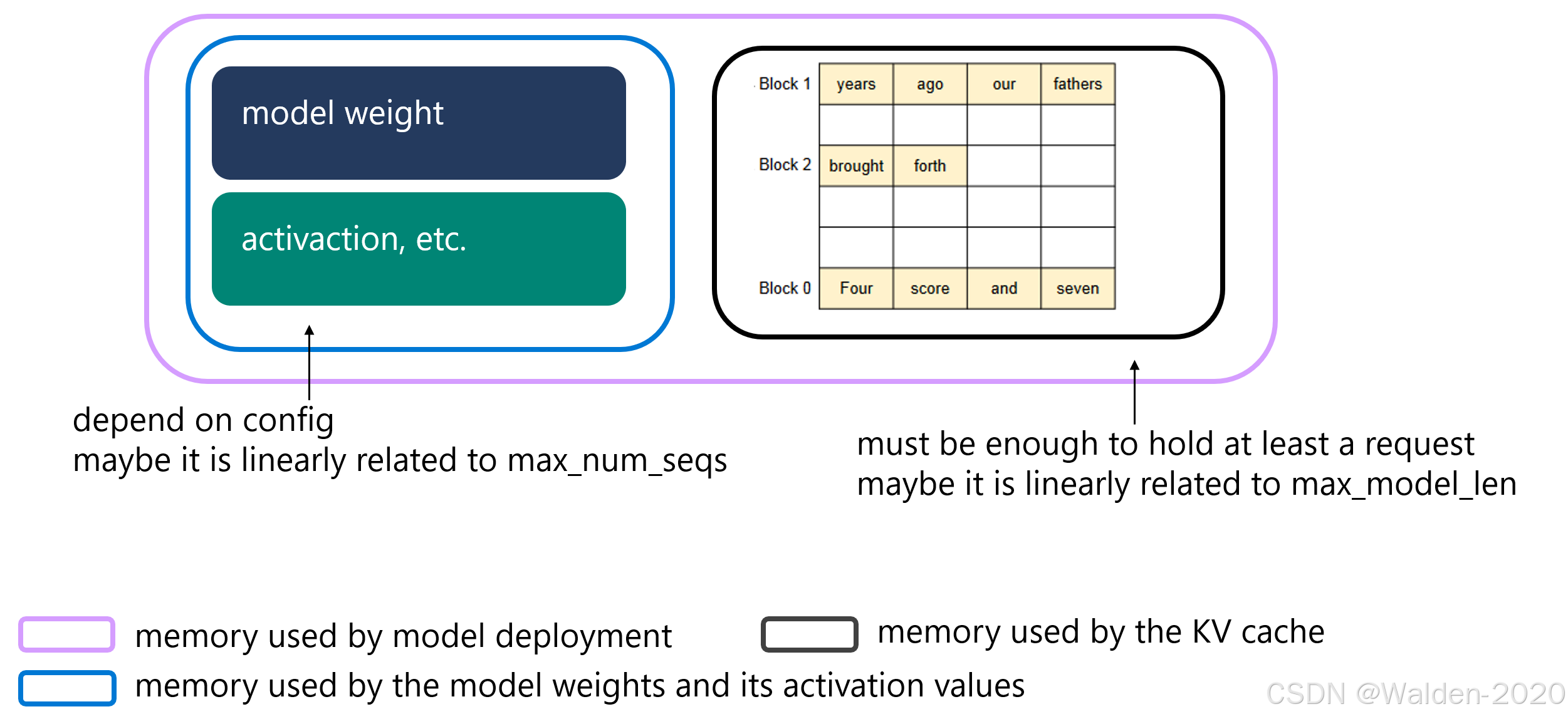
我们可以看到Peak值可以被拆解为两部分,所以模型部署的显存占用可以细分为三部分:
-
模型权重 (model weight): 这一部分用深蓝色表示,展示了分配给模型权重的内存,这部分是相对固定的。
-
激活等 (activation, etc.): 用绿色表示的是除了模型权重之外的其他内容,比如激活值(模型推理时的中间结果)等。这部分内存的大小可能根据配置(config)而有所不同,并且可能与最大序列数(max_num_seqs)成线性关系。
-
KV缓存内存使用情况 (memory used by the KV cache): 用灰色表示的是为KV键值缓存保留的内存。KV缓存用于快速存取模型在推断过程中产生的中间数据,以加速后续的计算过程。这部分内存应该足够存放至少一个请求的信息,并且其大小可能与模型的最大长度(max_model_len)成线性关系。
所以我们猜想,模型部署的显存可以表示为一个线性函数
Min_mem = A * max_num_seqs + B * max_model_len + C
A, B, C 是常数,可以通过实验来确定,其中 C 是一个依赖于部署模型其他配置的常数。
预测特定设置下的内存需求
当我们得到了这个线性函数之后,我们需要确定,调节 max_num_seqs 和 max_model_len 在实际部署时,是有必要的吗?答案是肯定的。
- 如果我们只是一个用户部署模型,那么 max_num_seqs 实际上是不需要非常大的,因为我们只是一个用户,我们不需要处理大量的请求。
- 在一些特定的情况下,长文本可能是没必要的,比如询问大模型 1+1 的结果,这时候 max_model_len 可以设置的很小。
所以我们可以通过预测特定设置下的内存需求,来提高部署成功率并减少内存浪费。
线性关系的检验
在我们根据源代码分析并猜想 Min_mem 与 max_num_seqs 和 max_model_len 之间的线性关系之后,我们需要通过实验来验证我们的猜想。
- max_num_seqs
以facebook/opt-125m 模型为例,通过对数据点采样,可视化数据点,我们可以看到 max_num_seqs 与 Min_mem 之间并不是线性关系,而是一个非线性关系。
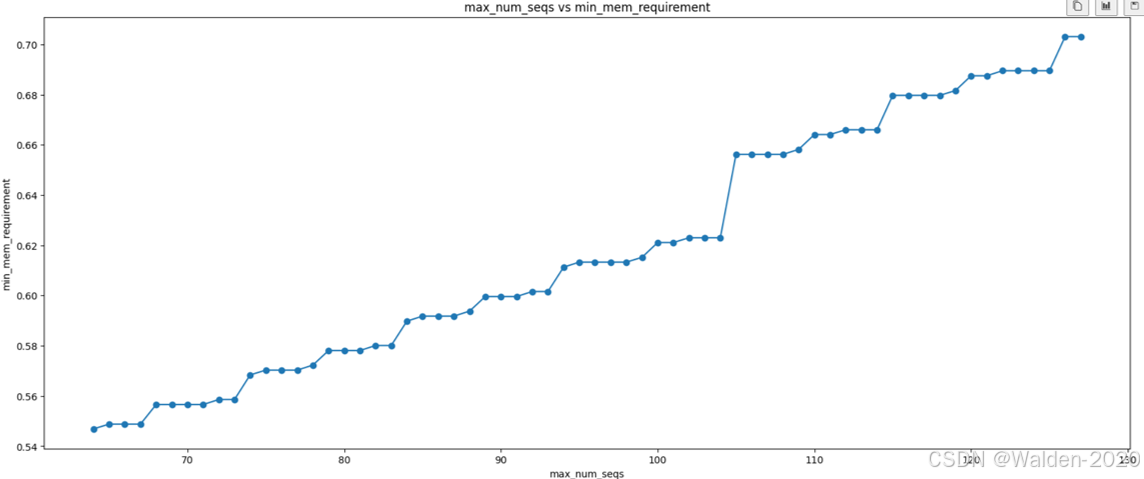
至于 为什么 max_num_seqs 与 Min_mem 之间不是线性关系,考虑到时间的原因和代码的复杂性,我们没有进一步深入研究。
- max_model_len
以facebook/opt-125m 模型为例,通过对数据点采样,可视化数据点,我们可以看到 max_model_len 与 Min_mem 之间是一个线性关系。
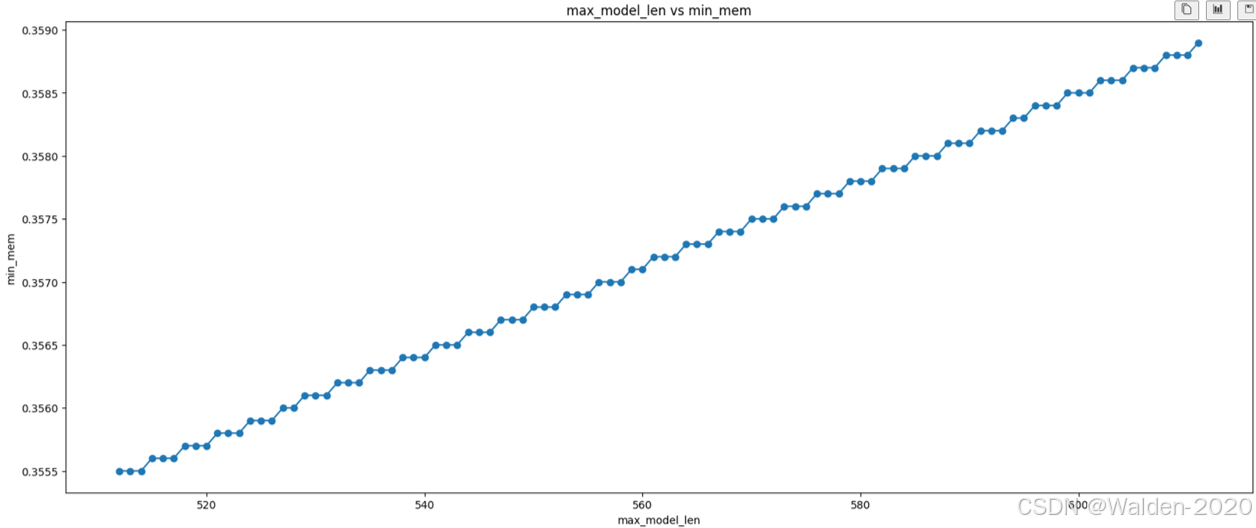
可以看到,max_model_len 与 Min_mem 之间基本是一个线性关系,这与我们的猜想是一致的。
所以我们可进一步把 max_num_seqs 也统一纳入与配置相关的一个常数项,即 Min_mem = A * max_num_seqs + B * max_model_len + C 可以简化为 Min_mem = A * max_model_len + B, 这样我们就得到了一个可以建模的线性关系。
更多的示例
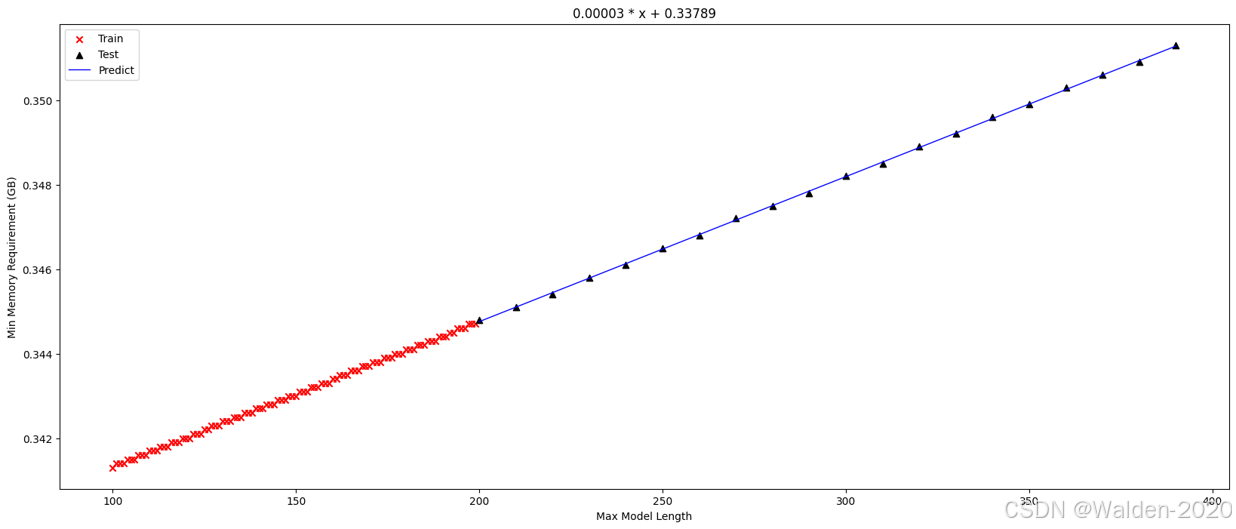
基于我们的猜想,我们也检验了其他模型是否也基本符合这样的线性关系:
-
facebook/opt-125m
-
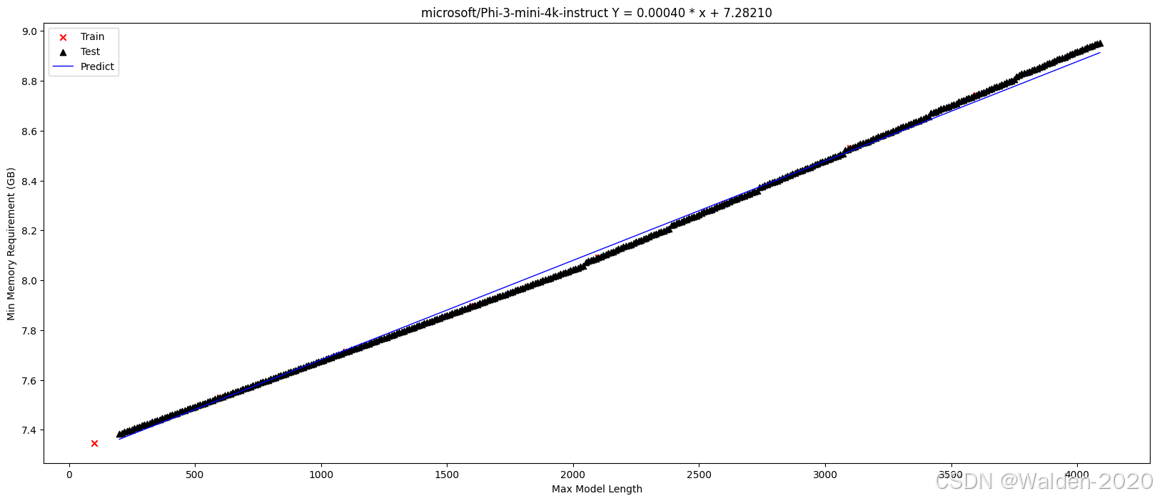
microsoft/Phi-3-mini-4k-instruct
-
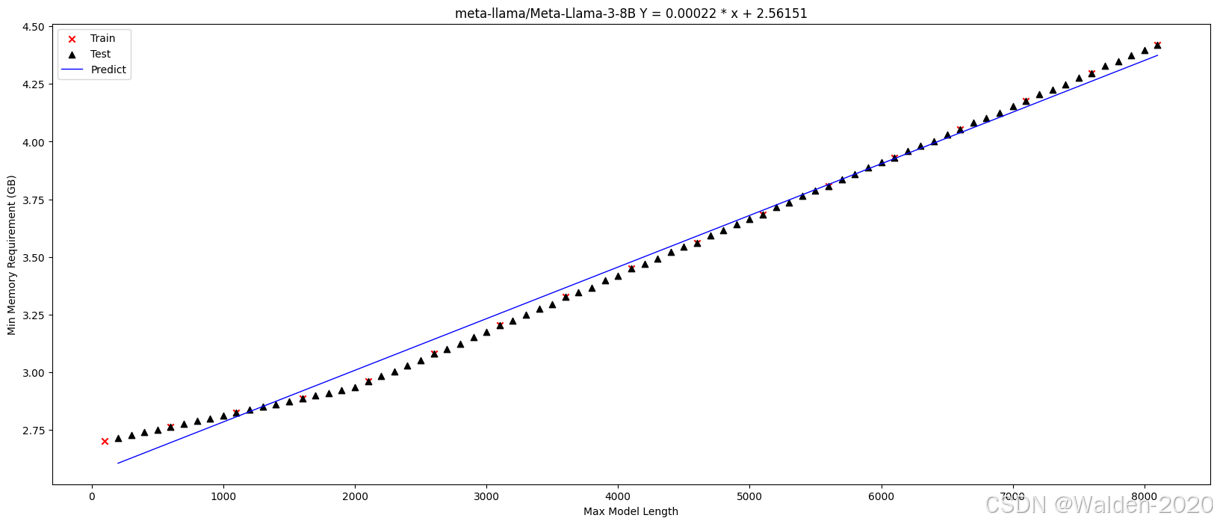
meta-llama/Meta-Llama-3-8B
-
Qwen/Qwen-7B
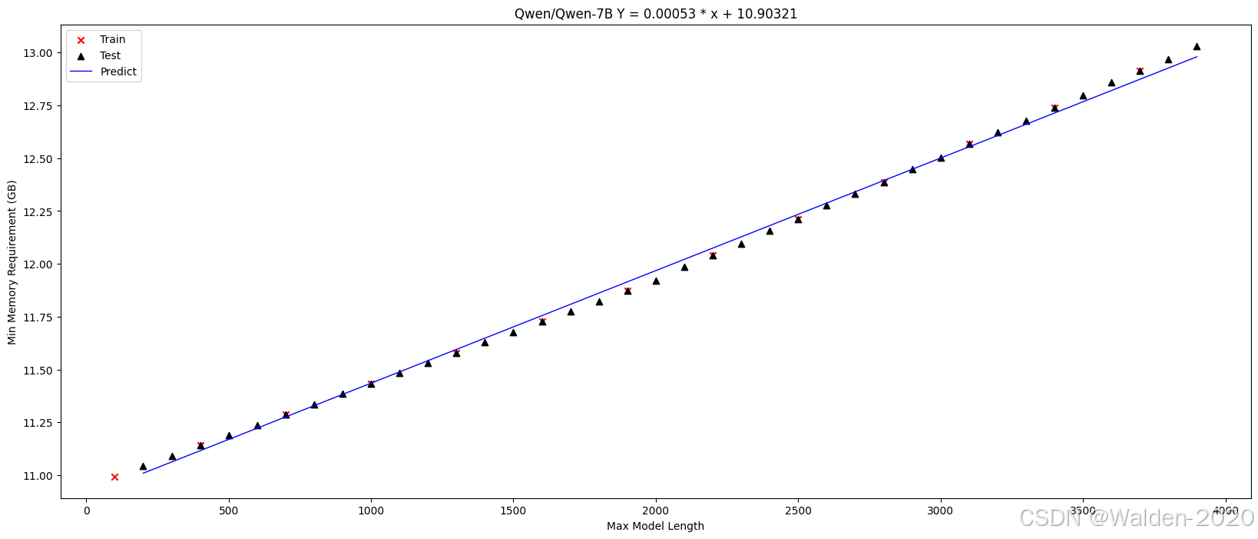
可以看到,我们通过少量的采样,就可以得到一个线性关系模型,并且这个模型可以很好地拟合实际数据,所以我们可以通过这个模型来预测特定设置下的内存需求。
Demo: Memory Solver
架构
基于我们的结论,那我们就可以通过实现一个 demo 来预测特定设置下的内存需求。我们可以通过这个 demo 来预测特定设置下的内存需求,从而提高部署成功率并减少内存浪费,这个 demo 就是 Memory Solver。
Memory Solver 的基本架构如下:
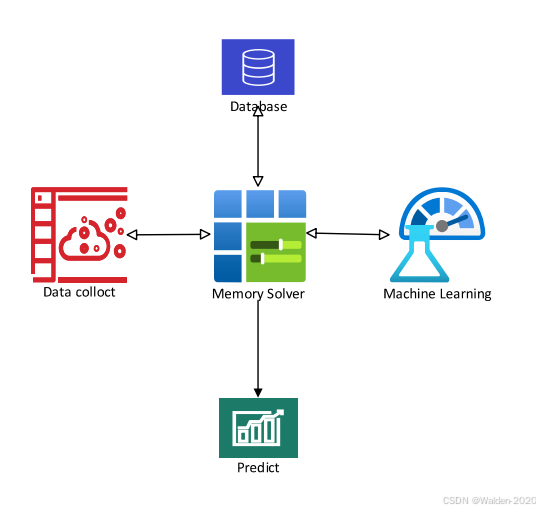
各个模块的功能如下:
- MemorySolver:demo 的主要模块,负责整体控制。
- Data Collect:负责在特定配置下收集模型的数据点的模块。
- Machine Learning:负责使用收集的数据点拟合线性模型的模块。
- Database:负责存储不同模型线性模型参数的模块,在本demo中为一个JSON文件。
- Predict:负责预测不同模型在不同max_model_len设置下的GPU内存使用量的模块。
预测
假如我们在某一特定配置下,得到 microsoft/Phi-3-mini-128k-instruct 的模型为 y = 0.0004504672754481875 * x + 0.8294199391218413 ,那么我们可以通过这个模型来预测不同 max_model_len 设置下的GPU内存使用量。
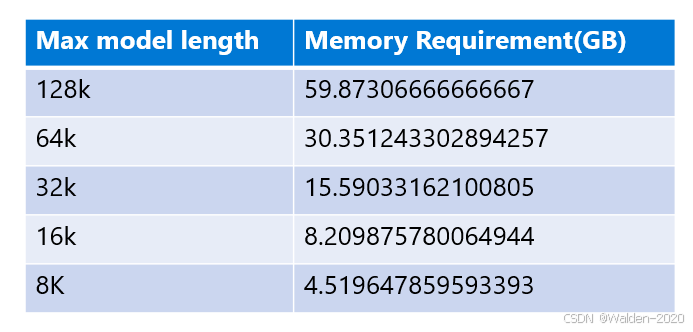
假如我们只有一张 NVIDIA RTX 4090 显卡,那么我们可以通过这个模型来预测多大的 max_model_len 是可以部署成功的。
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
图片来源: https://www.techpowerup.com/gpu-specs/geforce-rtx-4090.c3889
关于 vLLM 的碎碎念
硬件平台
在不同的硬件平台上部署vLLM时,需要考虑硬件平台的兼容性,vLLM 支持的硬件平台有:NVIDIA GPUs, AMD CPUs and GPUs, Intel CPUs and GPUs, PowerPC CPUs, TPU, and AWS Neuron.
以常见的 NVIDIA GPUs 为例,它的要求为:
- OS: Linux
- Python: 3.8 – 3.12
- GPU: compute capability 7.0 or higher (e.g., V100, T4, RTX20xx, A100, L4, H100, etc.)
以常见的X86 CPU 为例,它的要求为:
- OS: Linux
- Compiler: gcc/g++>=12.3.0 (optional, recommended)
- Instruction set architecture (ISA) requirement: AVX512 (optional, recommended)
当我们部署量化模型时,尤其需要考虑硬件平台。该表展示了在vLLM中,各种量化实现与不同硬件平台的兼容性。

图片来源: https://docs.vllm.ai/en/stable/quantization/supported_hardware.html
可以看到,即使对于NVIDIA GPUs,不同架构的GPU对于量化模型的支持也是不同的,那么怎么简化对硬件平台的兼容性的考虑呢?
我们可以考虑使用 compute capability。设备的 compute capability 由一个版本号表示,有时也称为 “SM版本”。这个版本号标识了GPU硬件所支持的特性,并在运行时被应用程序用于确定当前GPU上可用的硬件特性和/或指令。由CUDA and Architecture Matrix 可知,新的架构一般有较高的 compute capability,并且新的架构一般支持旧的 compute capability。所以我们可以通过 compute capability 来简化对硬件平台的兼容性的考虑。
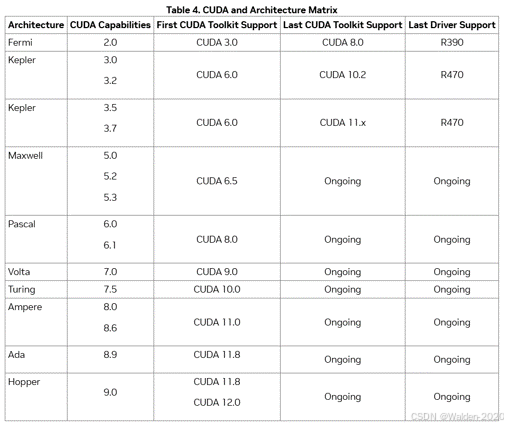
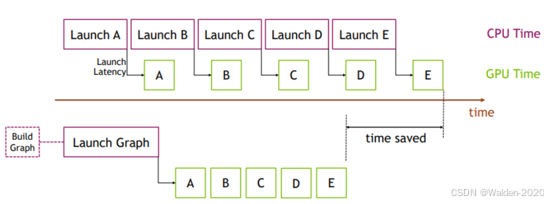
CUDA graph
关于 CUDA graph 的详细介绍,我们可以参考博客。
CUDA图(CUDA Graphs)在CUDA 10中首次亮相,它允许将一系列CUDA内核定义并封装为一个单独的单位,即一个操作图,而不是单个启动操作的序列。它提供了一种通过单个CPU操作启动多个GPU操作的机制,从而减少了启动开销。vLLM的Collaborator 对此的评论是:CUDA graph 在编译时会占用一些内存和时间,但可以提高性能。
参考文献
- vllm repo: https://github.com/vllm-project/vllm
- vllm paper: https://arxiv.org/pdf/2309.06180
- vllm blog: https://blog.vllm.ai/2023/06/20/vllm.html
- The Illustrated GPT-2: https://jalammar.github.io/illustrated-gpt2/
- How GPT3 Works: https://jalammar.github.io/how-gpt3-works-visualizations-animations/
- Transformers KV Caching Explained: https://medium.com/@joaolages/kv-caching-explained-276520203249
- Transformer Explainer: https://poloclub.github.io/transformer-explainer/
- How Large Language Models work: https://medium.com/data-science-at-microsoft/how-large-language-models-work-91c362f5b78f
- A Survey of Large Language Models: https://arxiv.org/pdf/2303.18223
- 大语言模型: https://llmbook-zh.github.io/LLMBook.pdf
- Accelerating PyTorch with CUDA Graphs: https://pytorch.org/blog/accelerating-pytorch-with-cuda-graphs/
- LM-Offload: Performance Model-Guided Generative Inference of Large Language Models with Parallelism Control:https://pasalabs.org/papers/2024/llm_offload_2024.pdf

















 3116
3116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}