







PS1: 以下代码使用py3.7执行,原书出版于2013年(大概是),示例代码都是10年和11年写的, 使用的是py2的语法, 有许多不能执行,如:
- dict_keys.keys()[*]
- dict.iteritems()
- 等
PS2:所有代码均在Jupyter Notebook上测试, 所需包及版本如下
- numpy :1.16.5
- matplotlib :3.1.1
第二章 k-近邻算法(kNN)
创建数据,其中group为四组数据点,labels分别为四个数据点对应的标签
from numpy import *
# import operator
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return (group, labels)
group,labels = createDataSet()
group
array([[1. , 1.1],
[1. , 1. ],
[0. , 0. ],
[0. , 0.1]])
labels
['A', 'A', 'B', 'B']
def classify0(inX, dataSet, labels, k):
# 距离计算
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
# 求距离的平方
sqDiffMat = diffMat**2
# 求数组每一行的和
sqDistances = sqDiffMat.sum(axis=1)
# 取平方根 ,即距离
distances = sqDistances**0.5
# 由小到大排序 argsort()返回每个元素的"名次"
sortedDistIndicies = distances.argsort()
# 选择距离最小的k个点
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
# 记录出现次数
classCount[voteIlabel] = classCount.get(voteIlabel,0)+1
# 降序排序
sortedClassCount = sorted(classCount.items(), reverse = True )
# 返回出现最多次数的标签
return sortedClassCount[0][0]
print('结果:',classify0([0,0], group, labels, 3))
结果: B
示例1: 使用k-近邻算法改进约会网站配对效果
文件转为矩阵函数
import numpy as np
def file2matrix(filename):
fr = open(filename)
arrayOLines = fr.readlines()
# 得到文件的行数
numberOfLines = len(arrayOLines)
# 初始化矩阵
returnMat = np.zeros((numberOfLines, 3))
classLabelVector = []
index = 0
for line in arrayOLines:
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index+=1
return returnMat,classLabelVector
datingDataMat, datingLabels = file2matrix('I:\迅雷下载\MLiA_SourceCode\machinelearninginaction\Ch02\datingTestSet2.txt')
datingDataMat
array([[4.0920000e+04, 8.3269760e+00, 9.5395200e-01],
[1.4488000e+04, 7.1534690e+00, 1.6739040e+00],
[2.6052000e+04, 1.4418710e+00, 8.0512400e-01],
...,
[2.6575000e+04, 1.0650102e+01, 8.6662700e-01],
[4.8111000e+04, 9.1345280e+00, 7.2804500e-01],
[4.3757000e+04, 7.8826010e+00, 1.3324460e+00]])
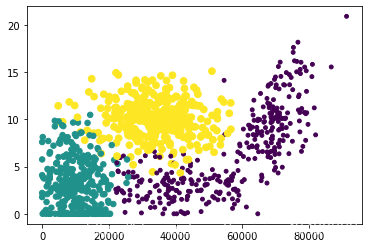
import matplotlib
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.scatter(datingDataMat[:, 0], datingDataMat[:, 1], 15*array(datingLabels),15*array(datingLabels),)
plt.show()
归一化函数
def autoNorm(dataSet):
minVals = dataSet.min(axis=0)
maxVals = dataSet.max(axis=0)
ranges = maxVals - minVals
normDataset = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1))
return normDataSet, ranges, minVals
normMat, ranges, minVals = autoNorm(datingDataMat)
normMat
array([[0.44832535, 0.39805139, 0.56233353],
[0.15873259, 0.34195467, 0.98724416],
[0.28542943, 0.06892523, 0.47449629],
...,
[0.29115949, 0.50910294, 0.51079493],
[0.52711097, 0.43665451, 0.4290048 ],
[0.47940793, 0.3768091 , 0.78571804]])
测试代码
def datingClassTest():
hoRatio = 0.1
datingDataMat, datingLabels = file2matrix('I:\迅雷下载\MLiA_SourceCode\machinelearninginaction\Ch02\datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:], normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3 )
if(classifierResult != datingLabels[i]):
errorCount+=1
print(classifierResult," " ,datingLabels[i]," ","False")
else:
print(classifierResult," " ,datingLabels[i]," ","Right")
print("The Total error rate is: %f" % (errorCount/numTestVecs))
datingClassTest()
3 3 Right
3 2 False
1 1 Right
1 1 Right
1 1 Right
1 1 Right
3 3 Right
3 3 Right
1 1 Right
3 3 Right
......
......
3 3 Right
3 3 Right
3 2 False
2 1 False
3 1 False
The Total error rate is: 0.120000
示例2: 手写识别系统
将图像转换为测试向量函数
def img2vector(filename):
returnVector = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVector[0,32*i+j] = int(lineStr[j])
return returnVector
testVector = img2vector(r'I:\迅雷下载\MLiA_SourceCode\machinelearninginaction\Ch02\digits\testDigits\0_13.txt')
testVector
array([[0., 0., 0., ..., 0., 0., 0.]])
locate =r'I:/迅雷下载/MLiA_SourceCode/machinelearninginaction/Ch02/digits/'
测试算法
from os import listdir
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir(locate + "/trainingDigits")
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector(locate + "/trainingDigits/" + fileNameStr)
testFileList = listdir(locate + "/testDigits")
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector(locate+'/testDigits/'+fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print ("the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr))
if (classifierResult != classNumStr): errorCount += 1.0
print ("\nthe total number of errors is: %d" % errorCount)
print ("\nthe total error rate is: %f" % (errorCount/float(mTest)))
handwritingClassTest()
the classifier came back with: 0, the real answer is: 0
the classifier came back with: 0, the real answer is: 0
the classifier came back with: 0, the real answer is: 0
the classifier came back with: 0, the real answer is: 0
the classifier came back with: 0, the real answer is: 0
the classifier came back with: 0, the real answer is: 0
the classifier came back with: 0, the real answer is: 0
the classifier came back with: 0, the real answer is: 0
......
......
the total number of errors is: 23
the total error rate is: 0.024313
–未完待续–















 384
384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









