






下面是一个最基础的贝叶斯神经网络(BNN)回归示例,采用PyTorch实现,适合入门理解。
这个例子用BNN拟合 y = x + 噪声 的一维回归问题,输出均值和不确定性(方差)。
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
# 1. 生成数据
np.random.seed(0)
x = np.linspace(-3, 3, 100)
y = x + np.random.normal(0, 0.5, size=x.shape)
# 转为torch tensor
x_train = torch.tensor(x, dtype=torch.float32).unsqueeze(1)
y_train = torch.tensor(y, dtype=torch.float32).unsqueeze(1)
# 2. 定义贝叶斯回归网络(输出均值和log方差)
class BayesianRegressor(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(1, 32), nn.ReLU(),
nn.Linear(32, 32), nn.ReLU(),
nn.Linear(32, 2) # 输出均值和log方差
)
def forward(self, x):
out = self.net(x)
mean = out[:, 0:1]
logvar = out[:, 1:2]
return mean, logvar
# 3. 贝叶斯损失函数(负对数似然)
def bayesian_loss(mean, logvar, target):
# 对应N(y|mean, exp(logvar))
return (0.5 * torch.exp(-logvar) * (target - mean) ** 2 + 0.5 * logvar).mean()
# 4. 训练网络
model = BayesianRegressor()
optimizer = optim.Adam(model.parameters(), lr=0.01)
for epoch in range(2000):
mean, logvar = model(x_train)
loss = bayesian_loss(mean, logvar, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 200 == 0:
print(f"Epoch {epoch+1}, Loss: {loss.item():.4f}")
# 5. 预测与可视化
x_test = torch.linspace(-3, 3, 100).unsqueeze(1)
mean_pred, logvar_pred = model(x_test)
mean_pred = mean_pred.detach().numpy().flatten()
std_pred = torch.exp(0.5 * logvar_pred).detach().numpy().flatten()
plt.figure(figsize=(8, 5))
plt.scatter(x, y, label='Data', color='gray', s=10)
plt.plot(x, x, 'g--', label='True function')
plt.plot(x_test, mean_pred, 'b-', label='BNN mean')
plt.fill_between(x_test.flatten(), mean_pred-2*std_pred, mean_pred+2*std_pred, color='orange', alpha=0.3, label='BNN ±2std')
plt.legend()
plt.title("Simple Bayesian Neural Network Regression")
plt.show()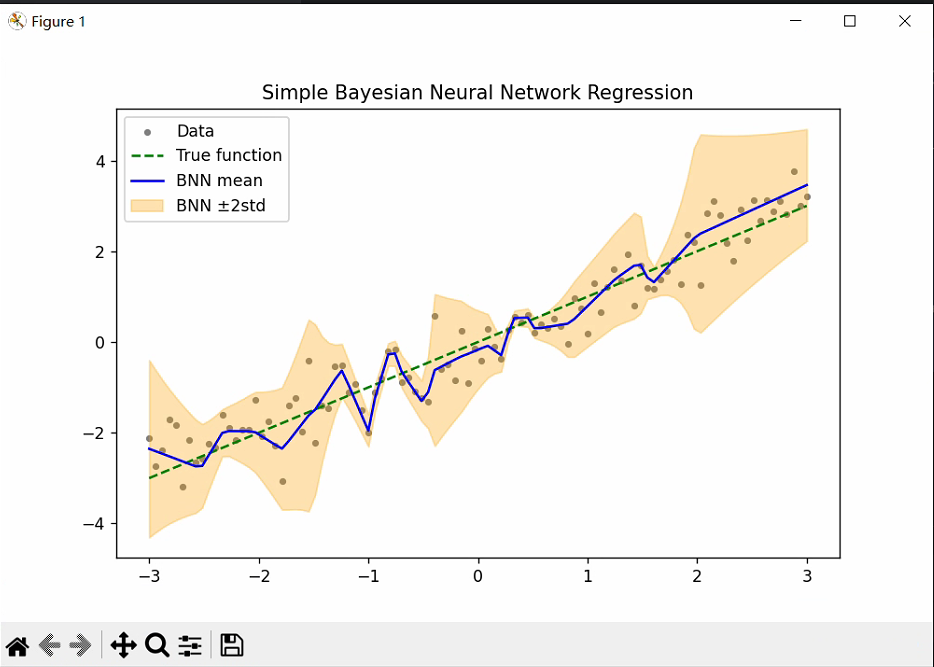


















 1782
1782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











