









VICAD系统开发挑战 :缺乏来自真实场景的VICAD数据集。
3 DAIR-V2X 数据集
DAIR-V2X 采集来自真实场景的大规模、多模态、多视图数据集,带有 3D 标签注释,用于车辆-路边设施协同感知。
针对车辆和路边设施传感器之间的时间异步问题,提出了时间补偿后期融合(TCLF)方法用于车辆-路边设施协同 3D目标检测 (VIC3D)任务的后期融合框架,作为基于 DAIR-V2X 的benchmark。
数据采集设备由路边设施传感器和车辆传感器组成:
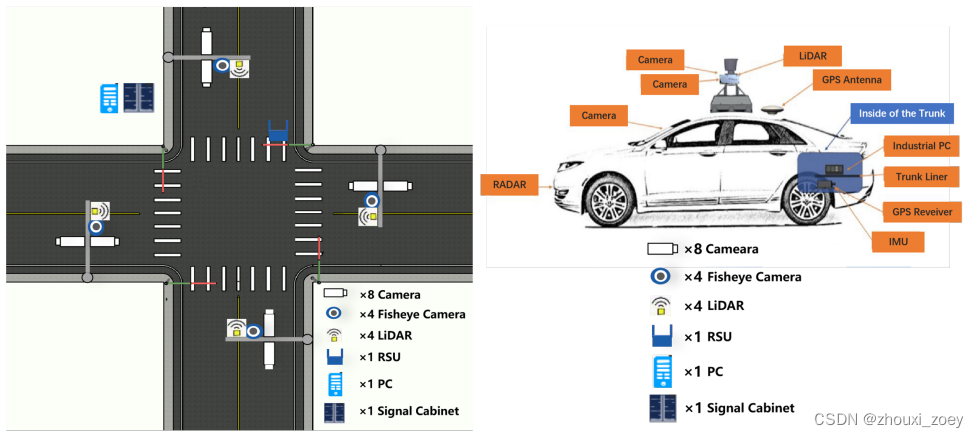
- 路边设施传感器:每个十字路口都部署了4组300光束激光雷达和高分辨率摄像头。DAIR-V2X 数据集只选择其中一组。
- 车辆传感器:一台 40 光束激光雷达和一台高品质前视摄像头安装在自动驾驶汽车的顶部。
DAIR-V2X有5种坐标系:LiDAR坐标、摄像头坐标、图像坐标、全局坐标和局部坐标。Lidar-to-Camera 转换是通过将 Lidar-to-World 和 World-Camera 转换相乘获得的。
DAIR-V2X 由 DAIR-V2X-C、DAIR-V2X-V 和 DAIR-V2X-I 组成:
 DAIR-V2X-C:手动选择100 个20 秒时长车辆通过十字路口的场景,以 10Hz 采样频率采样关键帧。
DAIR-V2X-C:手动选择100 个20 秒时长车辆通过十字路口的场景,以 10Hz 采样频率采样关键帧。
DAIR-V2X-V:从大约 350 个时长为 60 秒的仅含车辆的场景中采样 22K 帧。
DAIR-V2X-I:从大约 150 个仅有基础设施的场景片段中采样 10K 帧。
Label标注
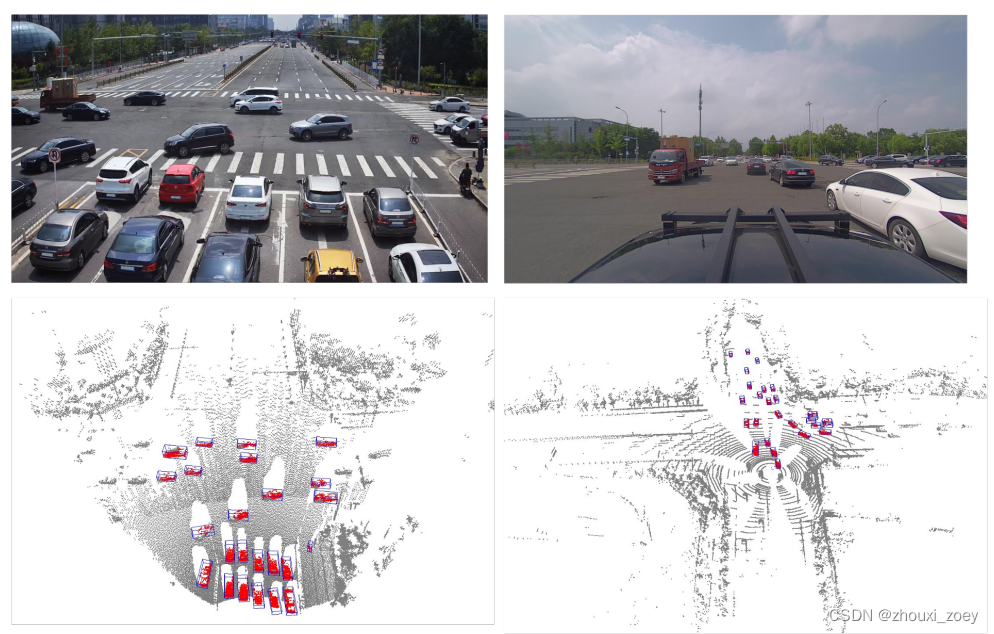
Annotators在每个图像和点云帧中,用其类别属性、遮挡状态、截断状态和 建模为(x,y,z,宽度,长度,高度,偏航角)的7 维长方体标记每个目标类别(共10个),包括车辆、行人、骑车人。还使用建模为( x,y,宽度,长度)的矩形边界框对图像中的目标进行标记。
vehicle-infrastructure cooperative (VIC) 3D 目标检测任务与传统的多传感器 3D 目标检测任务相比,VIC3D 目标检测具有以下特性:
传输成本:受限于物理通信条件,应减少从路边设施传输的数据,以减少带宽消耗,缓解时延,满足实时性要求。因此,VIC3D目标检测的解决方案需要在性能和传输成本之间进行权衡。
时间异步:来自车辆传感器和路边设施传感器的数据的时间戳不同,由于传输成本导致的异步触发和时间延迟,从而产生时空误差。因此,在求解 VIC3D 时应考虑时间同步。
• 车辆捕获帧Iv(tv):在时间tv捕获,相对位姿Mv(tv),其中Iv(·) 表示车辆传感器的捕获函数。
• 路边设施捕获帧Ii(ti):在时间ti捕获,相对位姿Mv(ti),其中Ii(·) 表示路边设施传感器的捕获函数。
考虑到物体在微小的时间间隔内移动,以至于可以忽略空间偏移,假设 |tv − ti | ≤ 10ms 作为同步情况(即 tv ≈ ti),|tv − ti | > 10ms 视为异步情况。
在 ti 基础设施捕获帧中的物体可能在 tv 移动到不同的位置,因此无法直接获取 tv 时刻路边设施捕获帧的 label 标签。
为 VIC3D 生成 ground truth:
VIC3D对应的ground truth是车辆传感器感知的ground truth和路边设施传感器感知的ground truth的融合结果。
• 异步情况:在 tv 上估计路边设施捕获帧中的目标对象的 3D 状态以生成ground truth。
• 同步情况:在车辆捕获帧 Iv(tv) 中的物体与它在路边设施捕获帧 Ii(ti) 中的空间位置相同。可以直接通过半自动标记获得的VIC3D 的ground truth:
1)从 DAIR-V2X-C 中选择一组同步的车辆捕获帧和路边设施捕获帧。
2)将路边设施捕获帧中的3D 边界框转换到车辆 LiDAR 坐标系,并融合车辆捕获帧和路边设施捕获帧中的相对应的标签。如果路边设施捕获帧中的3D框在车辆捕获帧找不到任何具有相同位置和类别的 3D 框,就把此3D 框添加到车辆捕获帧中,以此获得 VIC3D的ground truth。
4.2 评估指标
路边设施传输的数据可以是以下一种或多种形式的组合:
• 图像或点云等原始数据:包含完整的信息,但需要大量传输成本。
• 输出结果直接提供 3D 对象信息:传输效率很高,但可能丢失有价值的信息。
• 中间特征表示:需要较少的传输成本,同时保留有价值的信息,需要更复杂的设计来提取合适的中间特征。
VIC3D目标检测有两个主要目标:
1)更好的检测性能:AP(平均精度)评估3D目标检测器性能。
2)更少的传输成本:使用 AB(Average Byte)来评估传输成本。
5.1 后期融合的 LiDAR 检测
为了评估利用路边设施和车辆数据来进行3D目标检测的性能,执行了基于路边设施数据检测器和基于车辆数据检测器的后期融合框架。
1)分别使用路边设施捕获的点云帧和车辆捕获的点云帧数据训练PointPillars 3D目标检测器。
2)将基于路边设施数据的预测结果转换到车辆 LiDAR 坐标系中,然后将预测结果与基于欧几里得距离测量和匈牙利方法的匹配器合并以生成融合结果。
考虑到时间异步问题,提出了时间补偿后期融合(TCLF)框架。
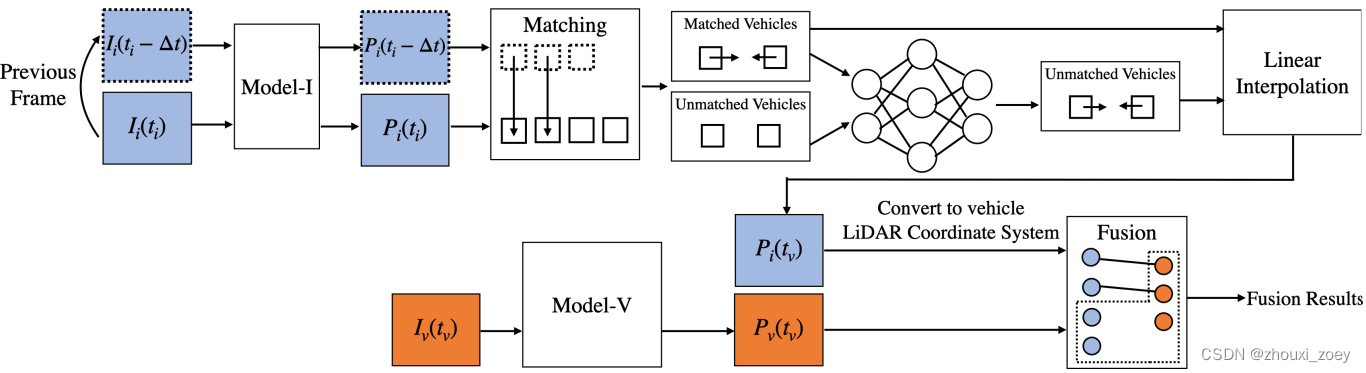
TCLF 主要由以下三部分组成:
- 使用两个相邻的路边设施捕获帧估计目标车辆的速度:1)预测边界框;2)对两个相邻帧的预测边界框进行匹配。对于匹配到的车辆直接计算它们的速度。对于不匹配的车辆,将当前场景的位置和运动信息输入 MLP 以预测它们的速度。
- 估计infrastructure objects在tv时刻的状态:根据获得的速度,通过线性插值来近似tv时刻路边设施捕获帧中对应车辆的位置。
- 按照LiDAR后期融合目标检测的方式,融合预测结果。
6 总结
1)DAIR-V2X是首个用于车路协同自动驾驶的大规模、多模态、多视图的真实数据集。
2)提出的时间补偿后期融合框架(TCLF)为检测模型提供了 VIC3D 基准,以及用于车辆视图和基础设施视图数据集的 3D 检测的广泛基准。结果表明,集成来自基础设施传感器的数据比单车 3D 检测平均高 15% 的 AP,并且 TCLF 可以缓解时间异步问题。
3)后期融合的图像VIC3D 目标检测,选择 ImvoxelNet 作为 3D 检测器,并分别训练基础设施检测器和车辆检测器。使用 跟LiDAR 检测后期融合一样的方法执行图像检测后期融合。
4)为了评估原始数据融合效果,使用 PointPillars 作为 3D 检测器实现了早期融合。首先将基础设施点云转换为车辆 LiDAR 坐标系,然后融合基础设施点云和车辆点云。然后,使用融合点云直接训练和评估检测器。
5)为单视图 (SV) 3D 检测任务提供了baseline。(ImvoxelNet、PointPillars、SECOND和 MVXNet)














 369
369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









