










V2VNet:使用V2V通信提高自动驾驶车辆的感知和运动预测
任务: 感知和motion预测,SDV需要对3D场景进行推理,识别其他车辆/行人,并预测他们未来可能如何行动。
在一个深度网络模型中联合执行3D目标检测和motion预测可提高准确性和稳健性,且两个任务的共享计算实现了高效的内存使用和快速的推理时间。
挑战: 严重遮挡的物体或距离较远的物体会导致稀疏的观察结果,对现代计算机视觉系统构成挑战。
网联SDV可通过汇总从多个附近辆车收到的信息,以从不同的视角观察同一场景,能够实现检测被遮挡的物体和远距离的物体。
SDV可以选择传送三种类型的信息:
(i)原始传感器数据:可以最大限度地减少信息损失,但它们需要更多的带宽,此外,接收车辆需要处理所有收到的额外的传感器数据,这可能使它无法满足实时推理的要求。
(ii)目标检测和预测轨迹结果:传输P&P系统的输出在带宽方面是非常好的,因为只有少数数字需要被广播,但可能会失去有价值的场景背景和不确定性信息,而这些信息对于更好地融合信息可能是非常重要的。
(iii)P&P系统的中间特征:首先每辆车处理自己的传感器数据并计算其中间特征表示,压缩后传送给附近的SDVs;经过深度网络提取的特征可以很容易地被压缩且为下游任务保留了重要信息;并且计算开销很低,因为来自其他车辆的传感器数据已经被预处理过了。
希望在最大限度地提高P&P精度的同时,尽量减少信息量以利用廉价、低带宽、分散的通信设备。发送经过压缩的深度特征图的方法在满足通信带宽要求的同时可实现高精确度目标检测。
3 V2VNet
提出了一个新的感知预测(P&P)模型V2VNet,其利用一个空间感知图神经网络(GNN)来聚合从所有附近的SDVs收到的信息以智能地结合来自场景中不同时间点和视角的信息。
LiDAR卷积块: 处理原始传感器数据,从LiDAR数据中提取特征并将其转化为鸟瞰图(BEV)。将过去的五个LiDAR点云扫描划分为15.6cm3的体素,经过几个卷积层输出空间特征图。
压缩: 每个车辆在传输中间特征前,采用Variational image compression算法来压缩空间特征,然后进行无损编码;经过压缩后的特征信息将传送给其他附近的SDV。
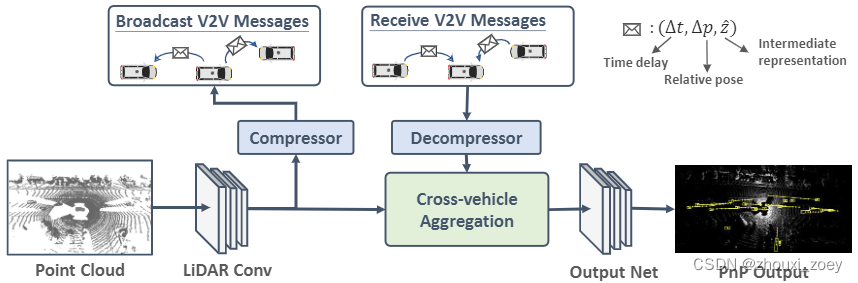
Cross-vehicle Aggregation:SDV接收到附近其他SDV发送的特征信息后,将对其进行解码,应用一个CNN解码器来提取解压后的特征图;然后,将自车的信息和从其他SDV收到的信息聚合起来,产生一个新的中间特征。经过输出网络计算出最终的P&P结果。
输出网络:在进行消息传播后,应用一组四个 Inception-like 的卷积网络模块来捕获多尺度context 。最后,基于特征图采用两个网络分支分别输出目标检测和motion预测结果。目标检测的输出是(x,y,w,h,θ),表示目标物体的位置、大小和方向。motion预测的输出为(xt,yt),表示目标物体在未来时间步 t 的位置。
3.1 空间聚合模块
在V2V环境中,接收方车辆应从任意数量的发送方车辆中收集和汇总信息用于下游推理,因此V2VNet利用GNNs来聚合来自其他车辆的信息。
不同的SDV位于不同的空间位置且观察到同一目标的时间点也可能不同,设计了一个GNN来对收到的信息进行时间和空间上的对齐,以使得发送车辆的信息与接收车辆的坐标系匹配。
使用一个全连接的图神经网络(GNN)作为聚合模块,其中GNN的每个节点都是场景中一辆SDV的状态表示,节点之间互相分享信息,并使用神经网络汇总收到的信息以更新节点状态。(GNN计算由SDV在本地完成)
在SDV进行信息交流后,每个接收SDV对接收到的信息进行时间延迟补偿,GNN对空间信息进行汇总,计算出最终的中间表征。
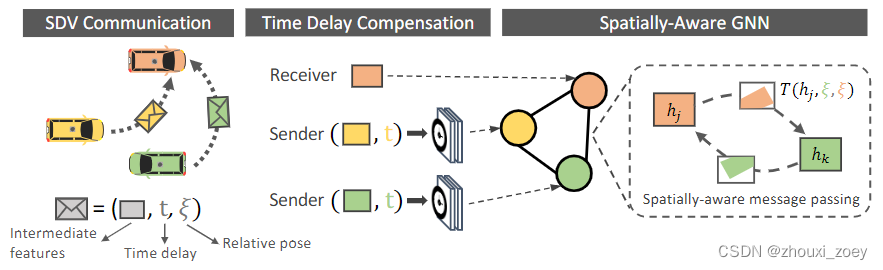
接收车辆所执行的聚合过程:
对于每个SDV节点i,Cross-vehicle Aggregation的输入为:a)接收到的特征表示ˆzi ;b)接收和发送SDV之间的相对pose信息∆pi ;c)相对于接收车辆传感器时间的延迟时间∆ti→k 。

第2-4行
为每个节点创建一个初始状态。representation通过一个CNN进行时间延迟补偿后,与0拼接以增加节点状态的容量,从而汇总从其他车辆收到的信息。
第5-9行
第7行:首先通过双线性插值(T)对发送节点的特征状态进行空间转换和重采样,其中ξi→k 是一个相对空间变换用来转换第i个节点的中间特征,使其与第k个节点空间对齐。然后,使用一个CNN对两个节点的空间对齐的特征图进行融合。Mi→k用于屏蔽掉非重叠区域,确保了只考虑重叠的视场。
第8行:在每个节点上通过mask-aware permutation-invariant(置换不变)函数ϕM聚集接收到的所有信息(ϕM是平均运算符),并通过ConvGRU更新节点状态(门控机制能够根据接收SDV的当前所需对累积的接收信息进行选择),其中j∈N(i)是节点i的网络中的相邻节点。
第11行
一个多层感知器MLP基于所有的特征状态计算输出最终的中间representation。
4 V2V-Sim数据集
采用一个高保真LiDAR模拟器Lidarsim来模拟给定交通场景的真实LiDAR点云。通过使用从现实世界中记录的相同的场景布局和车辆轨迹(本文利用真实的ATG4D数据集),可以在LiDARsim的虚拟环境中复制真实的交通场景;LiDARsim应用射线投影,采用深度神经网络为场景中的每一帧生成从不同的候选车辆看到的LiDAR点云,从而构建模拟有多辆SDV行驶的场景。

候选车辆:自车通信范围内的其他行驶车辆。V2V-SIM平均有10辆候选车辆可能在每个样本的V2V网络中,最多63辆,方差为7,体现了其交通多样性;且候选车辆的占比随着通信范围的扩大而线性增加。
5 总结
- V2VNet是一个联合架构以执行感知和预测任务,主要协助SDV完成以下工作:(1)处理原始传感器数据;(2)发送处理后的数据;(3)聚合从附近其他SDV收到的信息;(4)生成所有交通参与者在3D空间中的最终估计值和预测他们的未来轨迹。
- 提出了一个V2V仿真数据集V2V-Sim以评估所提出的V2VNet。

















 2225
2225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









