










标签:Pose Error;Communication Delay;Intermediate Fusion;V2X
论文标题:V2X-ViT: Vehicle-to-Everything Cooperative Perception with Vision Transformer
发表期刊/会议:ECCV 2022
开源代码:https://github.com/DerrickXuNu/v2x-vit
数据集:V2XSet (https://drive.google.com/drive/folders/1r5sPiBEvo8Xby-nMaWUTnJIPK6WhY1B6)
任务:基于LiDAR的3D目标检测
挑战:V2V协同感知忽略了路边智能设施,安装在高处的路边设施具有更广泛的视线,能减少遮挡;V2X协同感知将路边智能设施加入来提高车辆的感知精度,但也面临一些挑战:
1.路边设施和无人车的传感器配置存在很大差异(类型、噪音水平、安装高度,传感器属性和模式),这些异构性使得V2X感知系统的设计具有挑战性。
2.GPS定位误差以及 agent之间传输信息延迟会导致坐标转换不准确和感知信息滞后,将严重影响系统的感知精度。
3 V2X协同感知系统
假设V2X场景中一辆无人车为ego车辆 (接收车辆):
1)元数据共享:每个 agent 通过无线通信互相分享元数据,如pose、外在特征和 agent 类型(路边设施或车辆)。这里元数据共享延迟很小可以忽略不计,每个agent可以在实时收到 ego车辆的pose信息。当每个合作车辆和路边设施收到ego车辆的pose信息后,会将自己的LiDAR点云投影到ego车辆的坐标系上。
2)特征提取:利用anchor-based PointPillar方法从点云中提取视觉特征。
3)压缩和共享:为了减少传输带宽,利用一系列1×1的卷积沿通道维度逐步压缩特征图,减少通道数,然后传送给ego车辆,在ego车辆上使用1×1的卷积再将特征图解压。
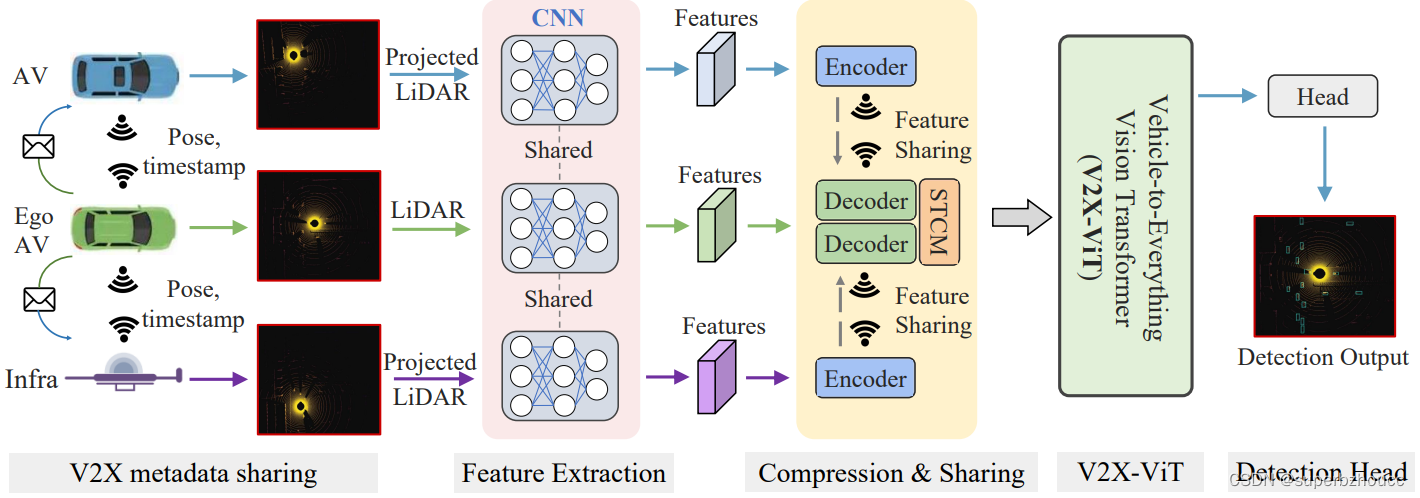
由于在发送车辆采集LiDAR数据到ego车辆收到压缩特征之间存在一定的时间延迟,因此,ego车辆接收到的特征与ego车辆自己捕获的特征在时间上不一致,导致空间错位。 在特征解压后,利用spatial-temporal correction module (STCM)通过微分变换和 sampling operator将特征图转换到ego车辆的当前位姿下。
4)V2X-ViT:将所有接收到的中间特征,通过V2X-ViT利用self-attention机制进行特征融合。
5)检测头:利用最终融合的特征图,通过两个1×1的卷积层进行边界框回归和分类。
3.2 V2X-ViT
(a) delay-aware positional encoding (DPE):编码延迟时间信息,根据不同的延迟时间,直接进行余弦编码,然后加到输入特征中,再传给HMSA。
(b)Heterogeneous multi-agent self-attention (HMSA) :捕捉路边设施和车辆之间的异构性(构建一个V2X graph,其中每个节点是车辆或路边设施,每条边代表定向V2X通信通道。假设同一类别的agent之间的传感器设置是相同的,就有两种类型的节点和四种类型的边。),HMSA根据节点和边缘类型来学习不同类型的agent之间的关系,同时进行特征融合,融合后的特征再传给MSwin。
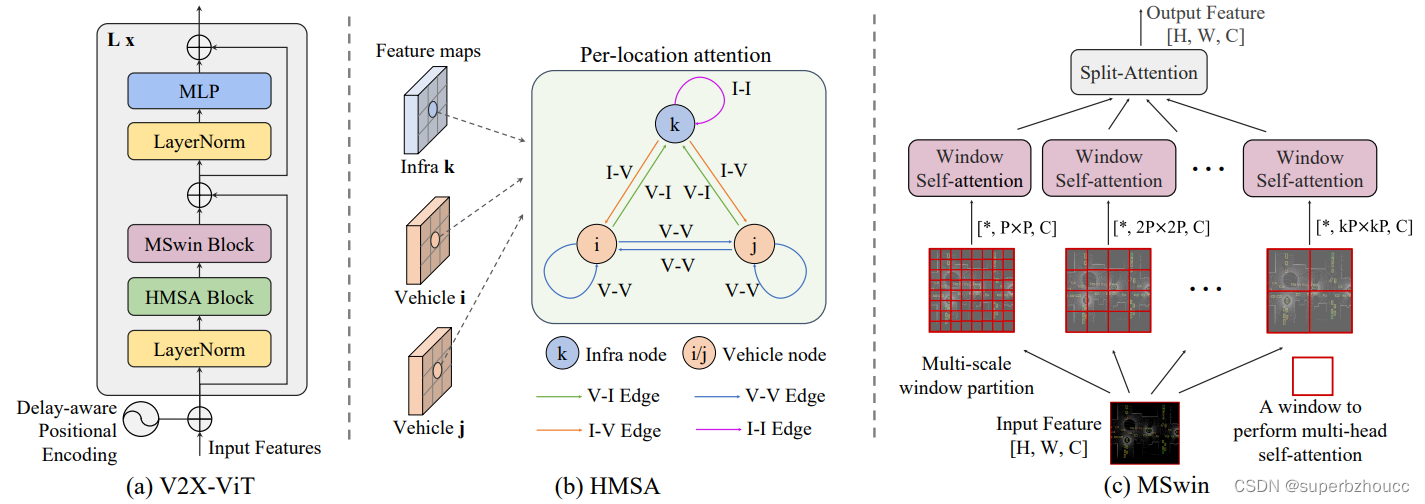
(c)Multi-scale window attention (MSwin):使用不同大小的窗口,每个窗口都有不同的attention范围,通过捕捉多尺度long-range interactions来聚合空间信息,以帮助消除GPS定位误差。
将这两个attention模块合起来组成V2X-ViT,然后将一系列的V2X-ViT模块堆叠起来,迭代地学习agent之间的关联关系和每个agent的空间注意力,从而获得融合特征用于最终的目标检测。
3.2.3 Delay-aware位置编码
考虑在滞后时间内由物体运动引起的错位,采用DPE对延迟时间信息编码。
- 基于延迟时间Δti和通道数c∈[1, C],用正弦/余弦函数对其进行初始化:
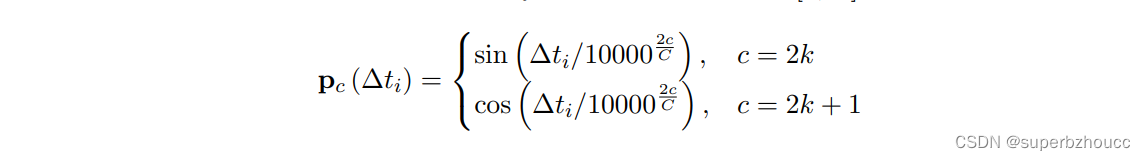
- 经过线性projection f 获得编码,将其添加到输入特征Hi中:
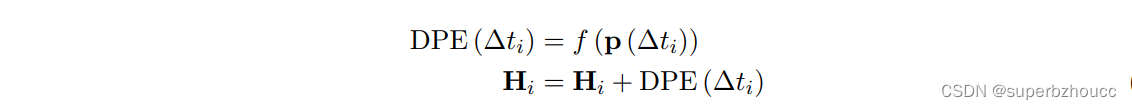
3.2.1 HMSA
将注意力权重ATT 与 聚合的特征信息 MSG 进行点乘,再经过线性聚合Denseci (一组以节点类型为索引的线性projection,聚合了 multi-head 信息),获得新的一个融合特征:
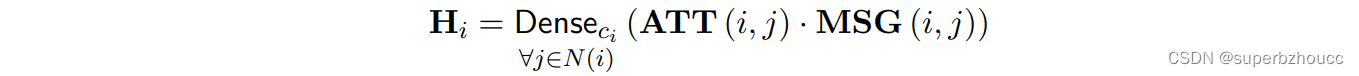
- ATT注意力权重估计,基于节点类型和边类型计算一对节点之间的相关性权重。
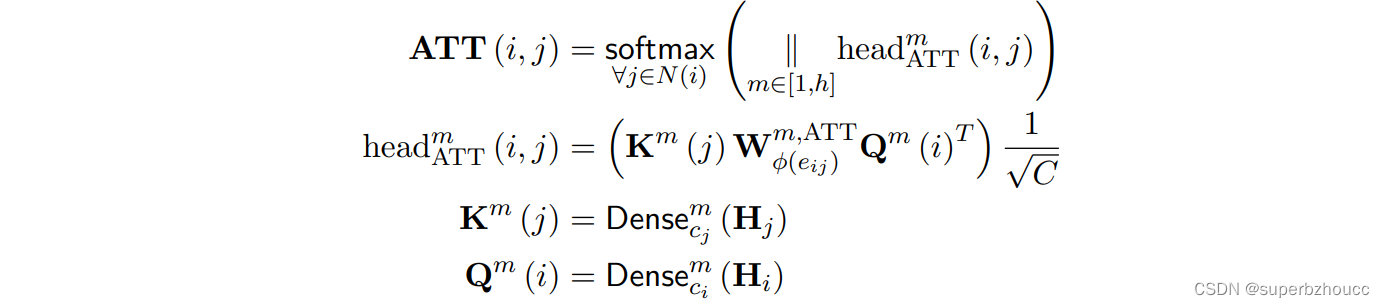
将输入的融合特征Hi 通过2个不同的Dense得到2个不同的Q和K(把不同类型节点的特征提取出来),2个不同的Q、K分别拼接在一起。为了纳入边类型的语义信息,通过边权重矩阵Wφ(eij) m,ATT (可训练的embedding)来加权Q和K的点积。然后将 multi-head 信息 拼接,经过softmax,得到注意力权重。 - MSG信息聚合
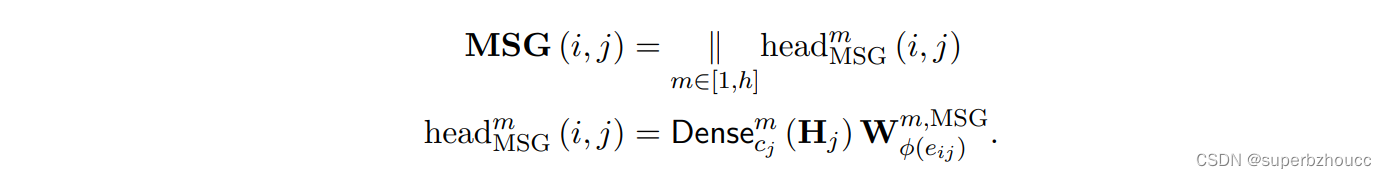
将输入的融合特征Hi 通过2个不同的Dense,分别提取路边设施和车辆节点的特征,矩阵Wφ(eij) m,MSG被用于根据发送节点和接收节点之间的边类型来加权特征,然后将 multi-head 输出拼接,得到聚合特征信息。
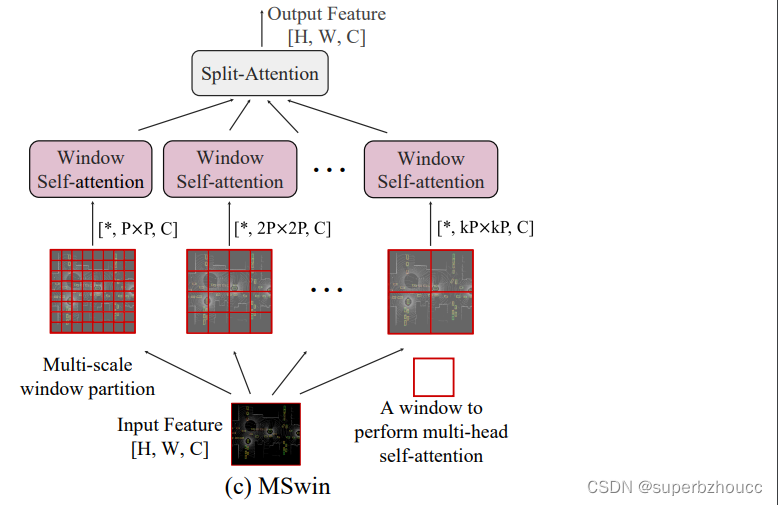
3.2.2 MSwin
为了解决定位误差,需要对融合特征进行long-range注意力交互,使用全局交互运算量大,所以采用MSwin,用不同的窗口大小分割输入特征图,每个像素点只与同一窗口的其他像素点进行交互;当使用较大的窗口尺寸时,逐步减少head的数量以节省内存的使用。最后,用split-attention模块将不同大小窗口self-attention分支的信息融合一起,形成最后的融合特征。
数据集V2XSet
V2X感知的数据集,用于研究V2X面临的定位错误和传输时间延迟问题。采用CARLA和OpenCDA来生成数据集,CARLA负责现实环境的渲染和传感器的建模,OpenCDA提供方便的同时控制多个AV和嵌入式车辆网络通信协议。将传感器安装在每辆无人车的顶部,只在拥挤的交通场景(十字路口、街区中段和入口坡道)上高度为14英尺处部署路边设施传感器。以10Hz频率记录LiDAR点云,并保存相应的位置数据和时间戳。总共有11,447个帧(对于同一场景中每个agent的帧,则有33,081个样本),训练/验证/测试的分界线分别为6,694/1,920/2,833。V2XSet包含了V2X协同和不同道路类型的现实噪音模拟。
数据样本:
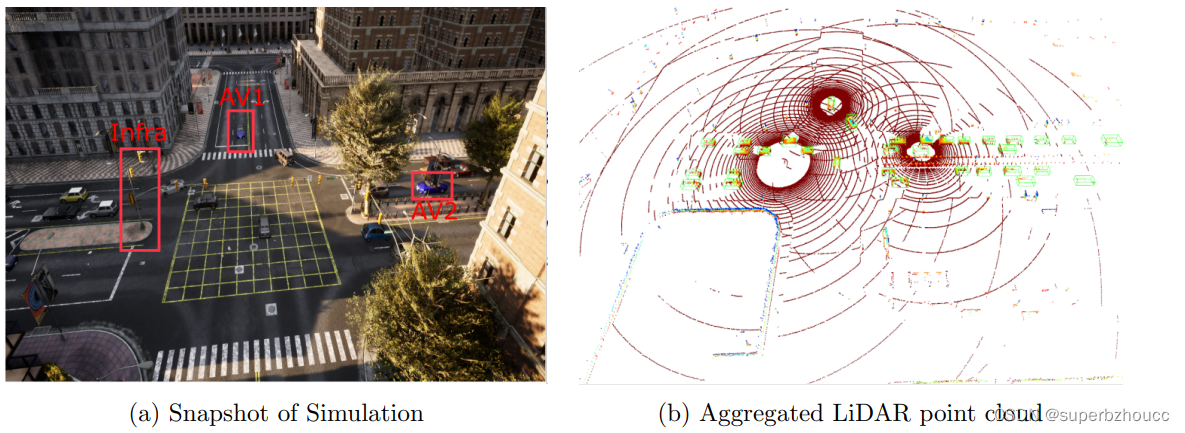
(a) 在CARLA中的模拟场景,两个自动驾驶汽车和基础设施位于一个繁忙的十字路口的不同侧面。(b) 这三个代理的LiDAR点云的汇总。
总结
- 提出了首个用于V2X感知的transformer架构(V2X-ViT),可以捕捉到V2X系统的异质性,对各种噪声具有很强的鲁棒性。
- 为自适应融合异构的agent的信息,提出了一种 heterogeneous multi-agent attention(HMSA)模块。
- 提出了一个multi-scale window attention(MSWin)模块,使用multiresolution windows 并行处理定位错误,可以同时捕捉到局部和全局的空间特征之间的相关性。
- 构建了一个用于V2X协同感知的大规模开放仿真数据集V2XSet。














 1111
1111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









