










论文标题:Learning Distilled Collaboration Graph for Multi-Agent Perception
发表期刊/会议:NeurIPS 2021
开源代码:https://github.com/ai4ce/DiscoNet
数据集:V2X-Sim 1.0(https://ai4ce.github.io/V2X-Sim/)中的LiDAR-based V2V scenario。
任务:假设一个场景中的多个车辆可以通过广播通信来相互协作,每个车辆都有准确的pose,并且感知的测量值是同步的。在给定的通信带宽下,目标是设计一个协同感知系统使每个车辆的感知能力最大化,实现基于LiDAR的3D目标检测。
挑战:特征融合方式可以将有代表性的信息压缩成紧凑的特征,这种方法有可能同时实现通信带宽效率和提升感知能力;然而,协作策略设计不当可能会在特征提取和融合过程中造成信息损失,导致感知能力提升有限。
2 Distilled Collaboration Graph多车感知系统
DiscoGraph(Distilled Collaboration Graph):模拟车辆之间的协作,每个节点是具有实时pose信息的车辆,每条边反映了两个车辆之间的成对协作。
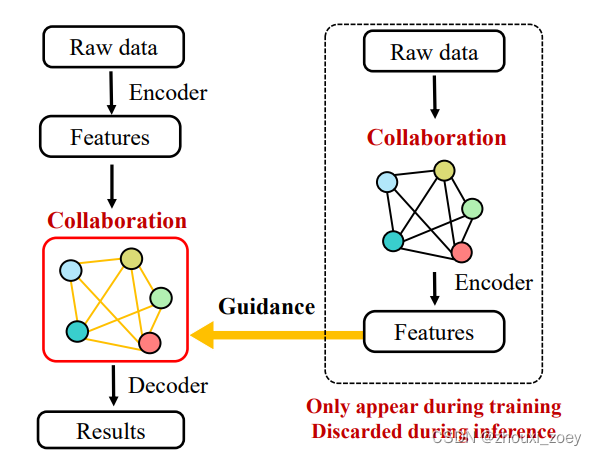
提出了teacher-student训练框架,其结合了早期和中期协作的优势。利用早期协作模型(教师)来引导中期协作模型(学生)使其协作后的特征图与早期协作模型(教师)提取到的特征图中的对应关系相匹配。早期协作模型只用于训练,在推理过程中只需要中期协作模型(学生)。
Knowledge Distillation:是模型压缩的一种方法,利用已经训练好的一个较复杂的Teacher模型 指导一个较轻量的Student模型训练,从而在减小模型大小和计算资源的同时,尽量保持原Teacher模型的准确率的方法。(参考:Distilling the Knowledge in a Neural Network)
所有车辆共享同一个teacher模型来指导student模型;每个车辆以自己的位姿提供输入,teacher和student模型的输入在空间上是对齐的。
2.1 Student:通过graphs进行中期协作
特征编码器:每个车辆将收集的3D点云量化为规则的体素并将其转换为2D伪图像,其高度对应于图像通道,得到鸟瞰图(BEV),然后经过4个由2D卷积、批量归一化和ReLU激活函数组成的模块进行下采样,得到特征图。
特征压缩:为了节省通信带宽,每个车辆在传输前使用1×1卷积自动编码器沿着通道维度压缩其特征图。
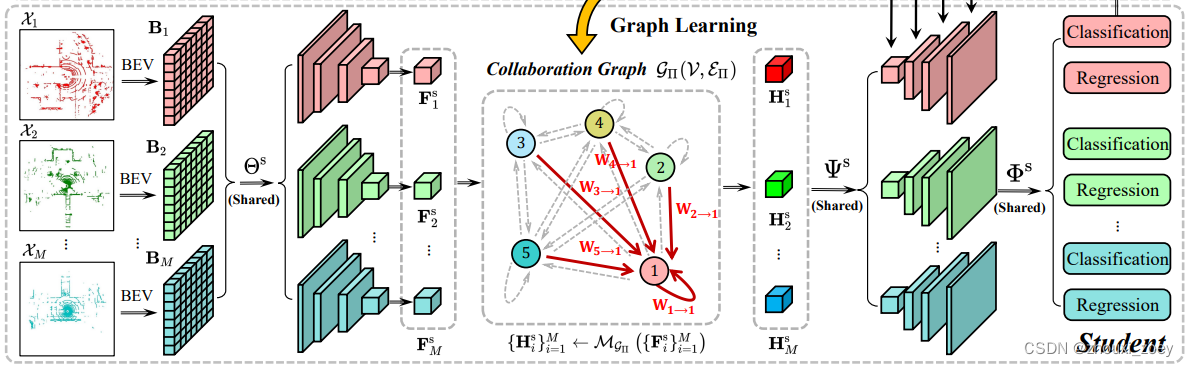
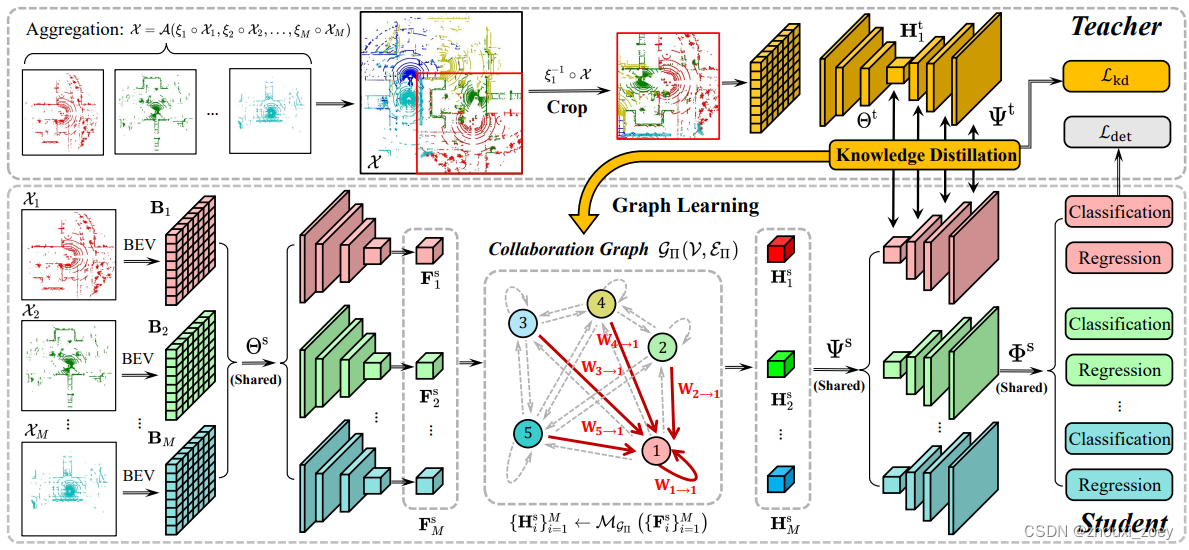
Collaboration graph process:每个车辆通过车辆间的数据传输来更新各自的特征图,车辆协作过程有三个阶段:
1.特征信息传输阶段:每个车辆将其压缩后的特征图传输给其他车辆。
2.特征信息关注阶段:1)每个车辆收到其他车辆发送的特征信息,将发送车辆的特征图转换到接收车辆坐标系中,使其空间对齐;2)沿着通道维度将2个特征图拼接,使用4个1×1卷积层将通道数量逐渐减少到1,在特征图中的每个单元格上进行softmax操作,获得多个车辆的边缘权重矩阵。权重矩阵的每个元素对应于BEV中的一个特定的空间区域,反映了该区域的空间注意力。
3. 特征信息聚合阶段:接收到的所有特征图在通道维度上点乘相应的边缘权重矩阵,并将它们聚合以得到协作后的特征图。
解码器和检测头:每个车辆对协作后的特征图进行解码。 解码器逐步对特征图进行四层上采样,在每层中,首先将前一个特征图与编码器中相应的特征图拼接起来,然后使用1×1卷积运算将通道数量减半。最后,检测头使用两个卷积层分支对目标进行分类和回归边界框。
2.2 Teacher:早期合作

特征编码器:将全局坐标系中所有协作车辆的原始点云数据进行聚合,并根据pose信息将全局视角的点云转换到自车坐标系中。然后,将点云转换为BEV图,并对齐进行裁剪以确保它与学生模型中的BEV图具有相同的空间范围和分辨率,然后使用2D卷积进行下采样来获得特征图。
解码器和检测头:与学生模型中的解码器和检测头一样,采用同样的方式获得解码的基于BEV的特征图,以及对目标进行分类和回归边界框。
Teacher training scheme:通过最小化教师模型分类和回归损失来单独训练教师模型。采用二元交叉熵损失函数来监督分类,并采用 smooth L1损失函数来监督边界框回归。
2.3 System training with knowledge distillation
给定一个训练好的教师模型,使用检测损失Ldet和knowledge distillation损失Lkd 来监督学生模型的训练
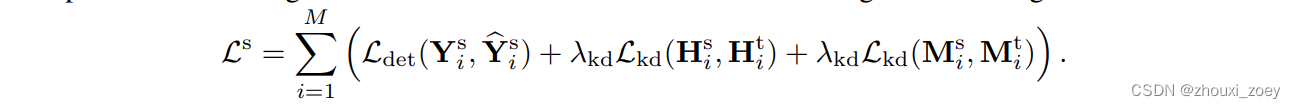
检测损失 Ldet 包括分类损失和边界框回归损失,第二和第三项为knowledge distillation损失,用于正则化学生模型以生成与教师模型相似的特征图。Hi是车辆协作后经过压缩的特征图,Mi 是解压后的特征图,超参数 λkd 是控制knowledge distillation损失 Lkd 的权重。
knowledge distillation损失 Lkd :
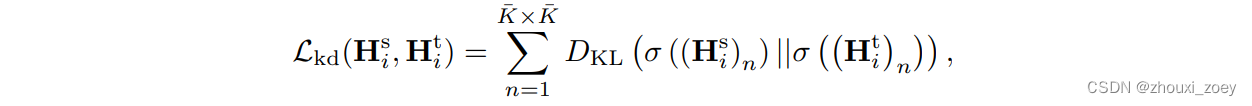
其中DKL( p(x) || q(x) )表示分布q(x)与分布p(x)的Kullback-Leibler(KL)散度,σ(-)表示特征向量沿通道维度的softmax操作,(Hsi)n和(H ti)n分别表示学生模型和教师模型中第i个车辆的特征图的第n个单元格的特征向量。同样,可以引入解码特征图上的损失Lkd(M si ,M ti )来加强正则化。
总结
-
采用knowledge distillation模型压缩方法,将teacher模型提取的特征图 视为 student模型的特征图的期望输出,通过knowledge distillation来约束student模型提取的特征图使其与teacher模型特征图的对应关系相匹配,促进更好的特征提取和聚合。从而在减小通信传输成本同时,使所提出的DiscoNet能够保持原Teacher模型的感知准确率。
-
引入了可训练的边缘权重矩阵,每个元素代表了特定空间区域的车辆到车辆(V2V)的attention,使车辆能够自适应地突出信息区域,并战略性地选择适当的合作伙伴来请求补充信息。
DiscoNet局限性:假设每个车辆都有准确的位姿信息,并且假设所有车辆传输信息都是时间同步的。

















 164
164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









