









论文标题:Cooperative Perception with Deep Reinforcement Learning for Connected Vehicles
发表期刊/会议:IEEE Intelligent Vehicles Symposium (IV2020)
数据集:V2V协同仿真平台CIVS( https://github.com/BlueScottie/SUMOCarla-integration)
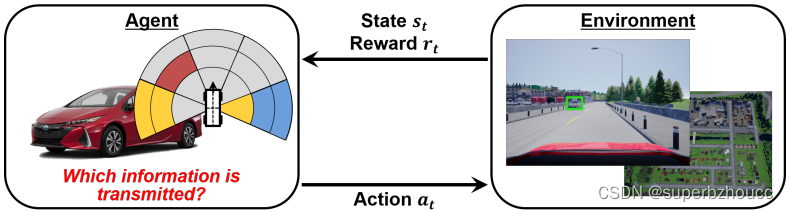
协同感知中的信息选择问题:协同感知严重依赖V2V通信,当道路上有许多无人车造成拥堵时,多辆车可能会重复发送关于同一物体的冗余信息。由于网络资源是有限的,当车辆将所有感知数据纳入协同感知信息时,一些信息可能会由于严重的信道拥堵而丢失。 为了保持网络的可靠性,车辆需要智能地选择要传输的数据,以节省网络资源,将资源分配给重要的数据包。
强化学习
对每辆车使用深度强化学习根据本地车载传感器捕捉到的周围环境,来智能地识别值得传输的感知数据片段,以决定每辆车辆需要传输哪些信息:
State:描述了agent的当前情况;Action:agent在每个状态下可以做的事情;Reward:描述了agent所采取的行动从环境中得到的积极或消极反馈。强化学习的总体目标是学习以获得一个使总奖励最大化的深度学习模型。
方法
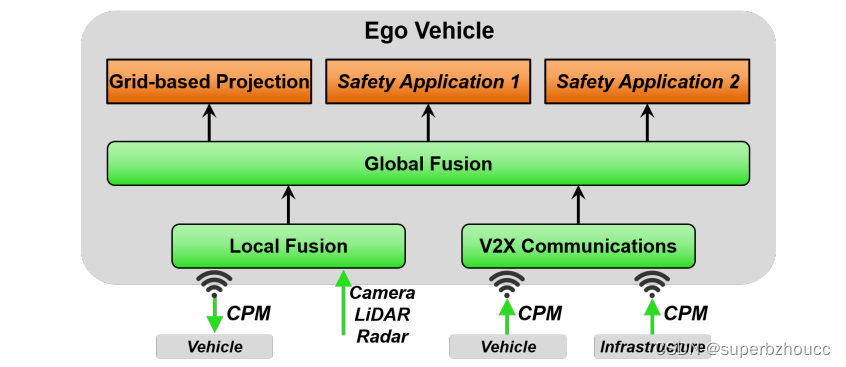
1)每个车辆通过V2X通信从相邻的车辆/路边设施接收合同感知信息(CPM),并融合自身多个车载传感器的信息(如摄像头、LiDAR和雷达)。
2)ego车辆将收到的感知数据进行全局融合。
3)将全局融合后的信息投影到用于强化学习的grid-based container中,表示当前时刻的状态st。
每个网联车辆都使用基本安全信息(BSM)和协同感知信息(CPM)进行V2V通信。BSM包含自车的位置、速度、加速度和方向。CPM包含检测到的物体的相对位置、方向和物体类型。
Deep Q-network(深度强化学习中一种价值学习的方法)
采用一个神经网络Q(s,a;w) 计算agent在某一时刻的状态下s (s∈S),可能采取动作 a (a∈A)能够获得的收益Q值。
在Deep Q-Network中,输入是agent的状态,输出是该状态下采取的行动的Q值。在训练期间,不断计算和更新Q值,agent选择最佳行动以最大化奖励:
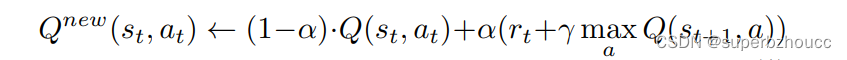
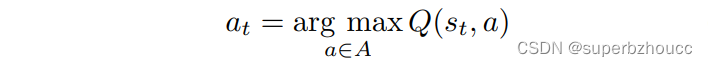
其中,α是学习率,rt是奖励,γ是折扣系数,max Q(st+1, a)是下一个行动的估计奖励。
由于状态和行动的数量,Q表的大小可能变得巨大,因此在DeepQ-Network中使用CNN,而不是Q-表。采用的CNN是由3个卷积层和2个全连接层组成。
Deep Q-Learning and Network Model
1)确定用于Deep Q-Learning 的协同感知的状态、行动和奖励:
状态state: 基于圆形投影和网络拥堵程度来确定。
圆形投影:视场(FoV)被分割成5×3个网格。每个网格为13种投影类型中的一种:

局部感知:
(i) 当网格中没有移动/静态物体时,网格被标记为空。
(ii) 当网格中存在由本地车载传感器检测到的物体时,网格被标记为被占用。
(iii) 当网格中存在物体被遮挡时,网格被标记为被遮挡。
基本安全信息BSM传输(自车的位置、速度、加速度和方向):所有车辆都会按照标准规定将其作为安全信标进行传输。
协同感知信息CPM传输(检测到的物体的相对位置、方向和物体类型):网络负载ψ作为状态st的一部分。
行动action:A={传输,丢弃},当行动为传输时,agent就会广播CPM;当行动为丢弃时,agent就不会发送CPM。行动是由deep-Q 网络(CNN)的输出Q值所决定的。
奖励/收益 reward:奖励机制rt,ω,α,β,其中有1个奖励和3个惩罚。rt,ω,α,β是在时间t给出的奖励,用于从发送agent α到接收agent β的通信中的检测目标对象ω。
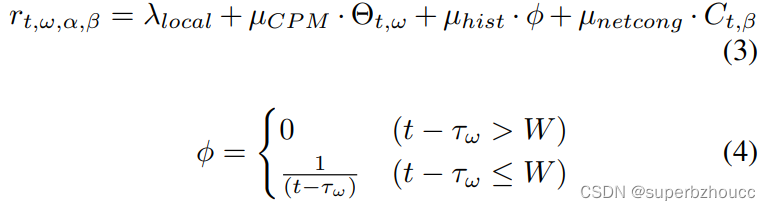
首先,λlocal是一个二进制奖励,当目标对象ω没有被接收车辆检测到时,它就变成1。
µCPM、µhist和µnetcong是负常数,是惩罚措施。Θt,ω表示在时间t 纳入了检测目标对象ω信息的CPM的数量。 τω是接收车辆β的局部感知检测到的物体ω的最新时间戳。Ct,β是接收车辆β在网络拥堵程度。
总结
1)提出了一种用于协同感知的深度强化学习方法,以减轻网络负荷。
2)设计和开发了一个协同智能车仿真(CIVS)平台,其整合了多个软件组件,以评估traffic模型、车辆模型、通信模型和物体分类模型。

















 224
224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









