






zynq 真双端口block ram仿真:
在准备进行ZYNQ ps和pl大量数据通信的时候,采用block ram进行数据交互,其中部分区域用于读,部分区域用于写。为了分解项目难度,先在PL端例化了block ram ip核,并且写了两个读写模块,用于测试仿真相关读写逻辑。但是在寻址的时候遇到了问题,已经找到问题并解决,在此记录一下。
问题描述
分别对block ram的两个端口写了互相读写的两个读写模块,其中一个模块在某地址中只写,另一个则只读,仿真的时候故意时序不同步模拟PS和PL的异步读写。出现的问题是,在仿真的时候:端口0对地址28-540分别写入32bit数据1、2、3、4…,对地址554-1052分别读出数据,对地址1056-1560分别写入32bit数据101、102、103、104…,对地址1564-2076分别读出数据;另一个端口正好相反,端口1对地址28-540分别读出数据,对地址554-1052分别写入32bit数据1、2、3、4…,对地址1056-1560分别读出数据,对地址1564-2076分别写入32bit数据101、102、103、104…。也就是一个读一个写,如图所示:
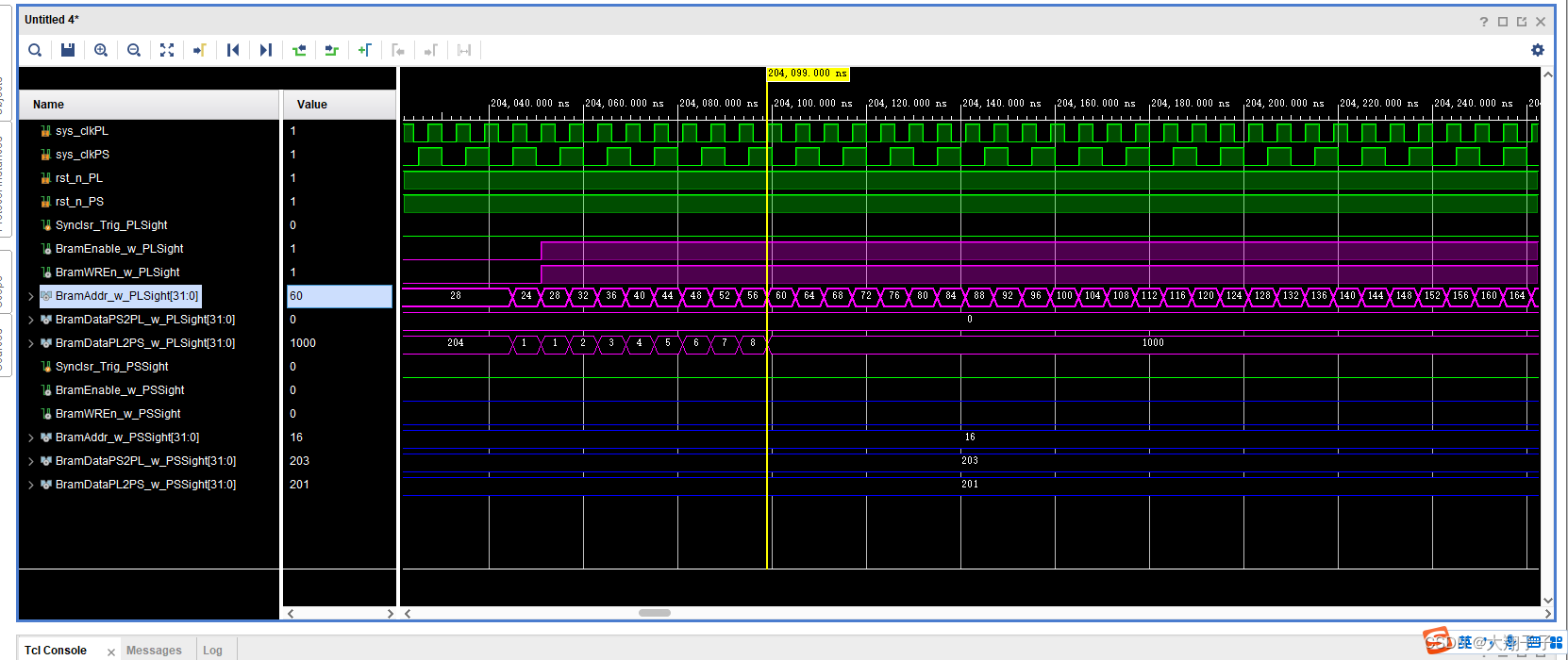
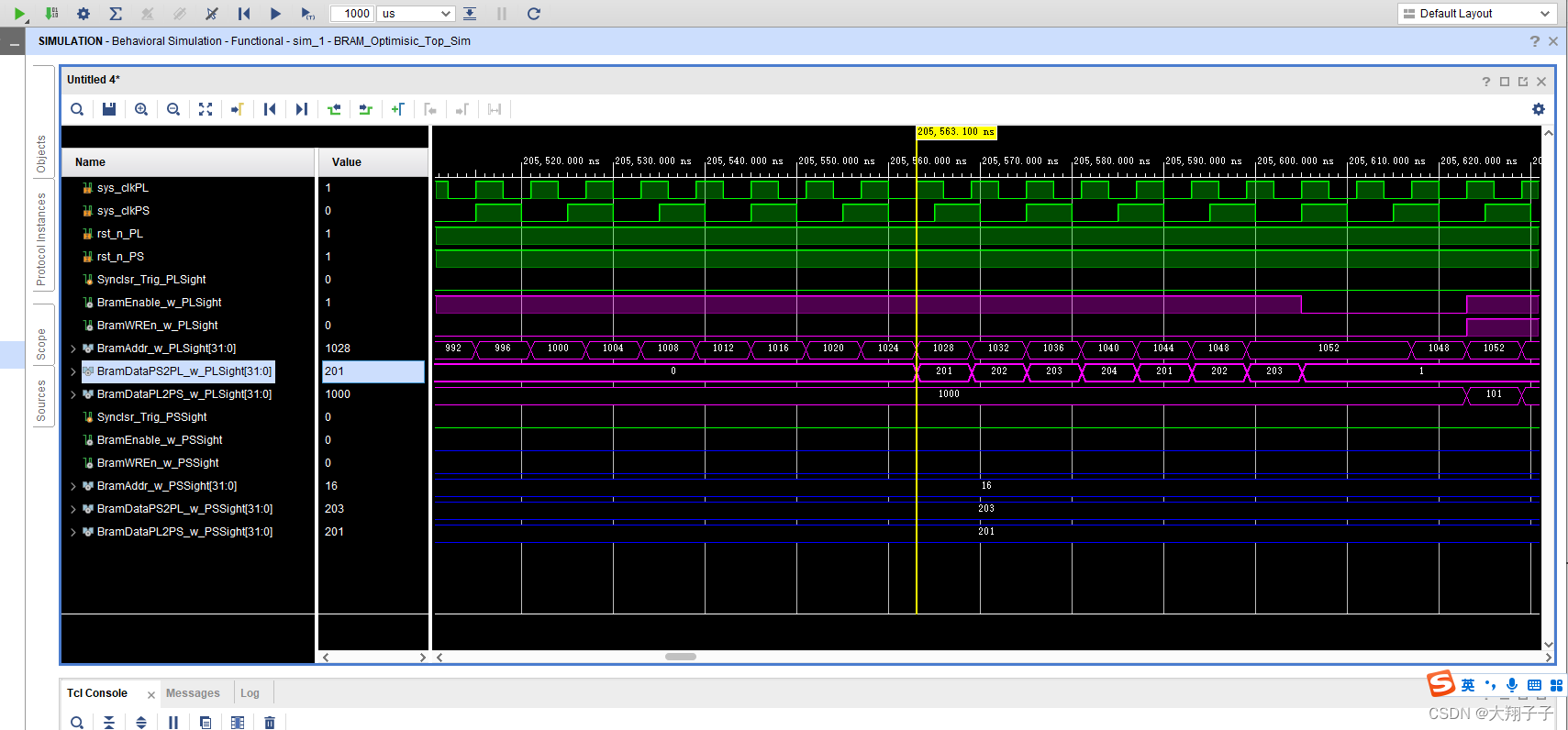
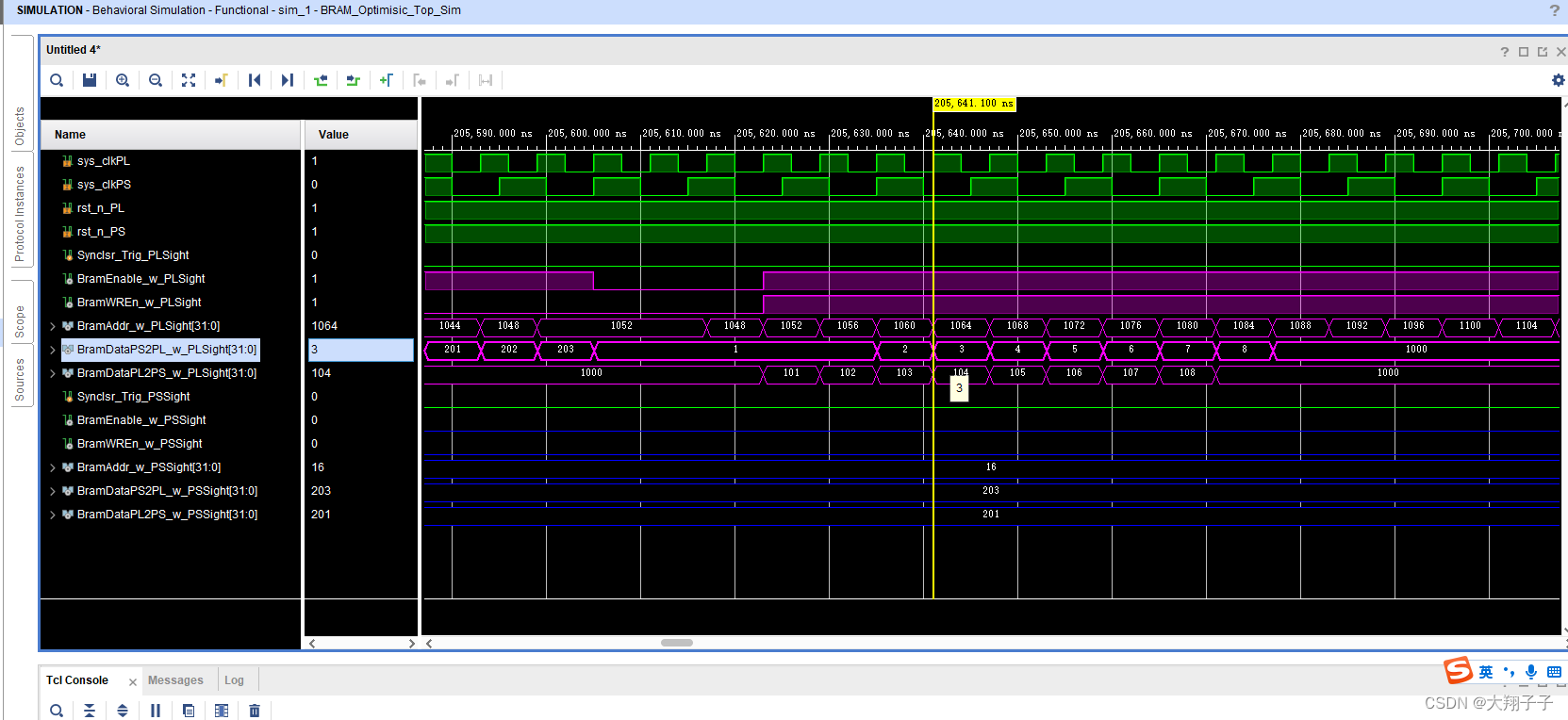
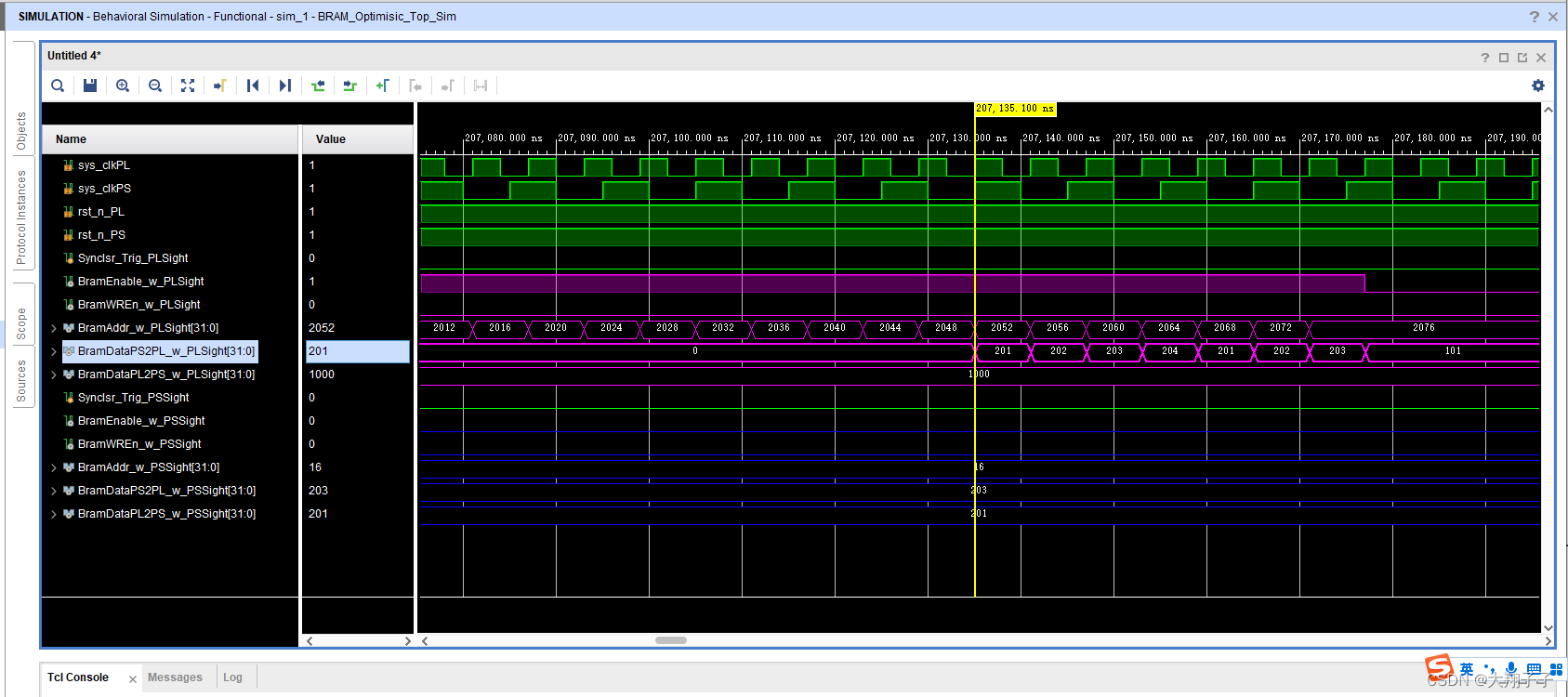

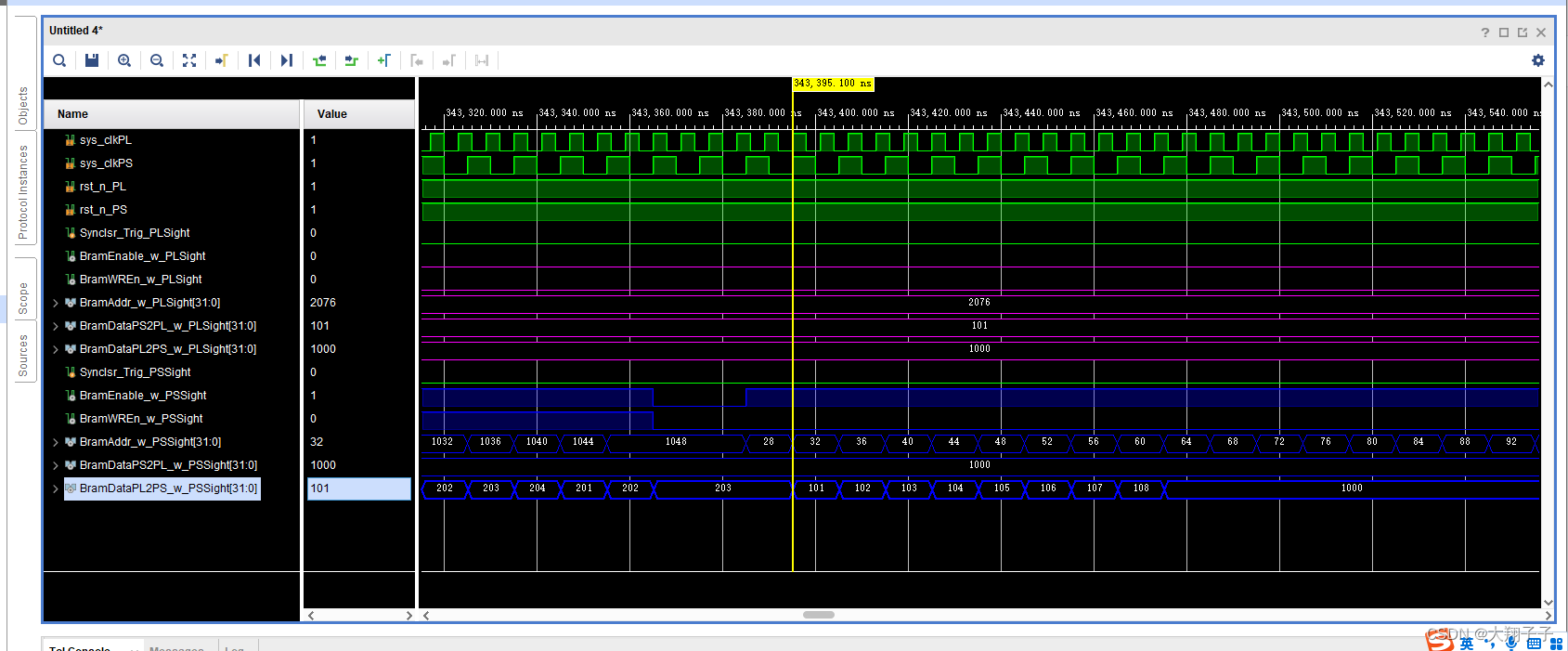
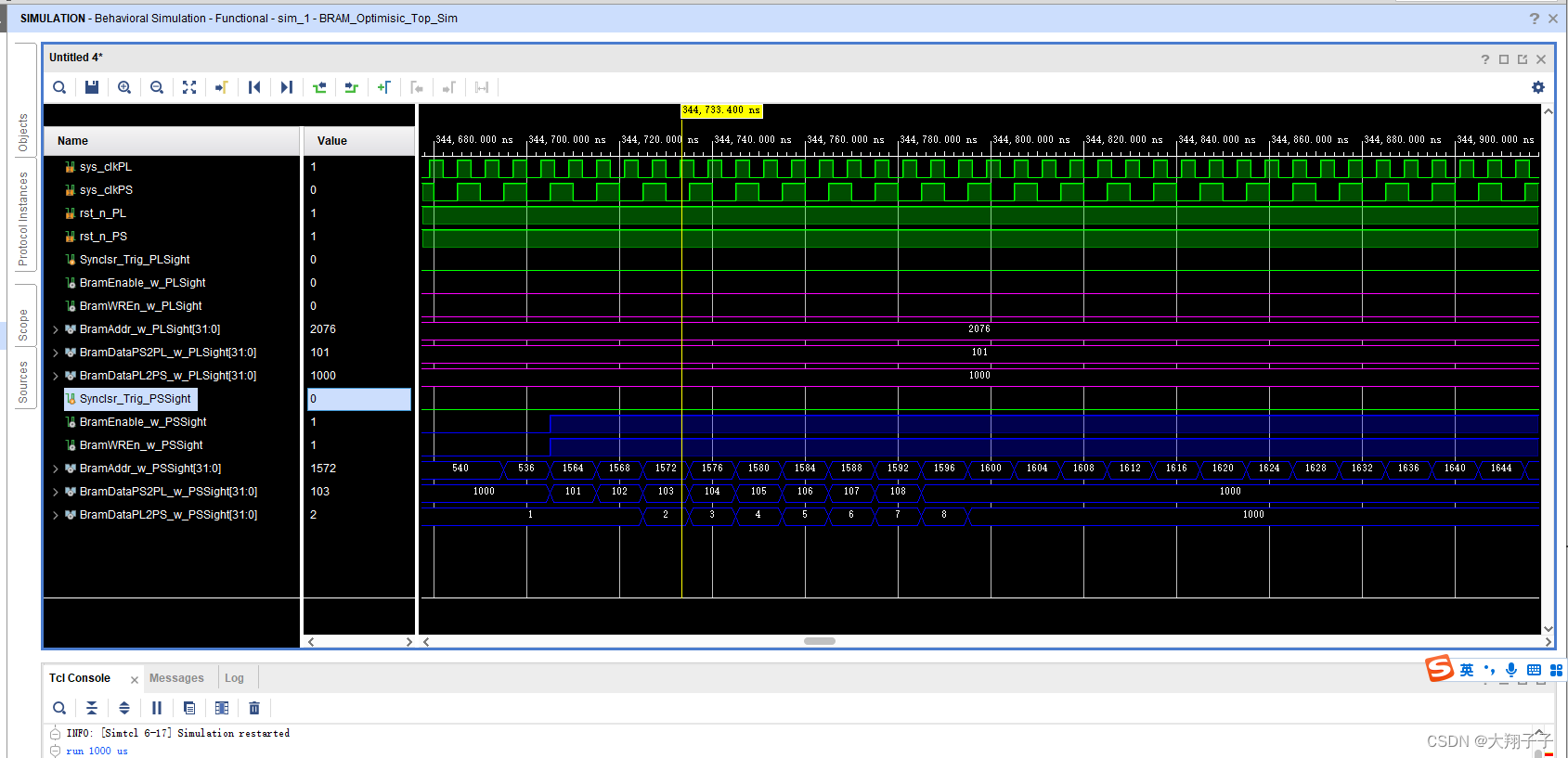
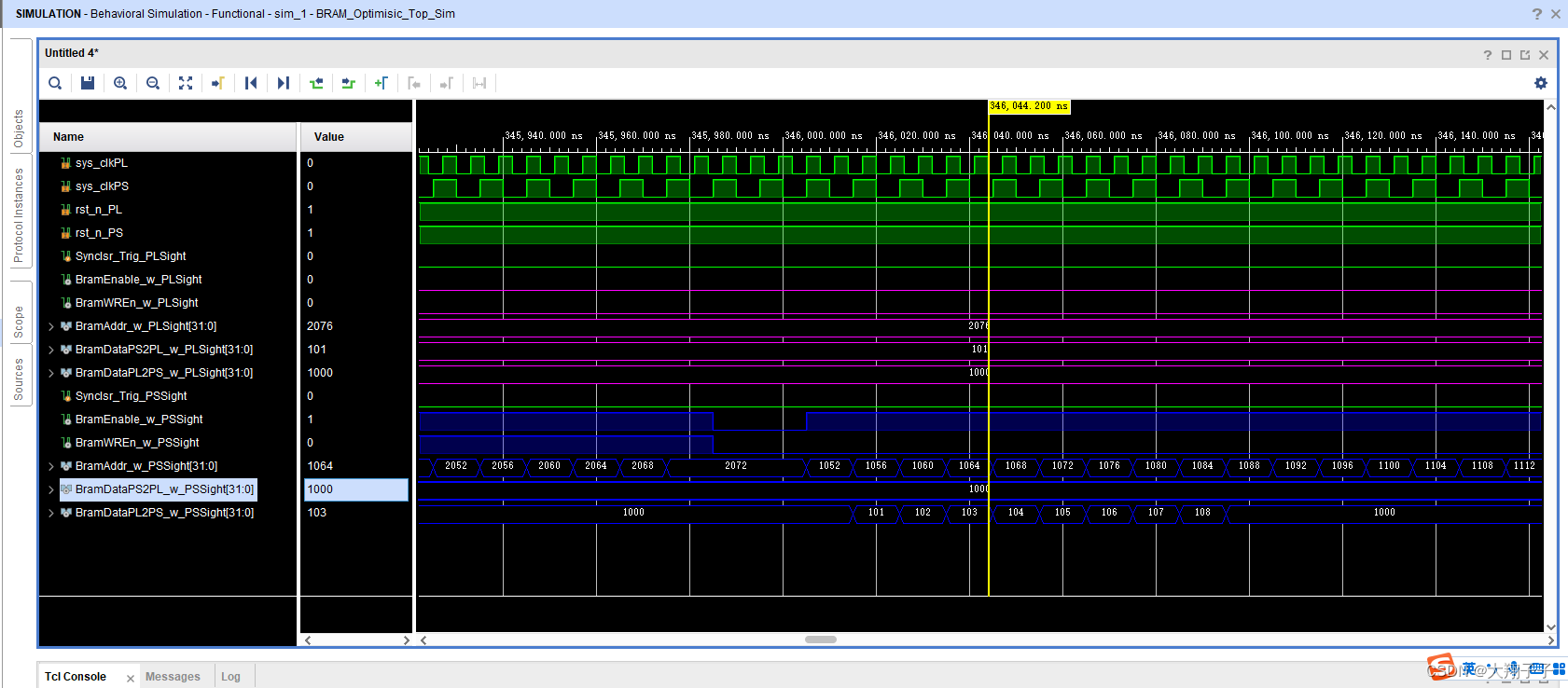
理论上讲,端口0对554-1052分别读出的数据应该是1、2、3、4…,对地址1564-2076分别读出数据101、102、103、104…;另一个端口正好相反,端口1对地址28-540分别读出数据1、2、3、4…,对地址1056-1560分别读出数据101、102、103、104…。但是实际上无论那个端口,读出的数据都是101、102、103、104…。
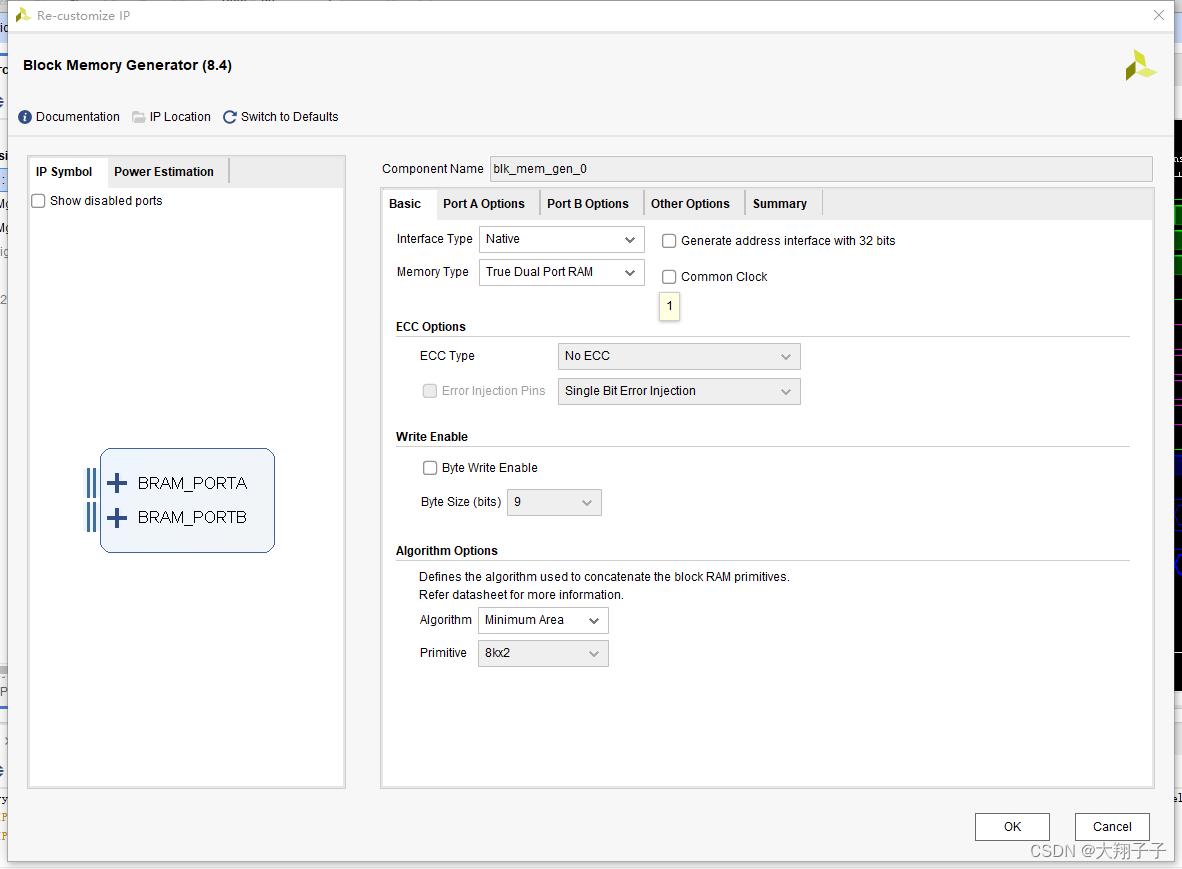
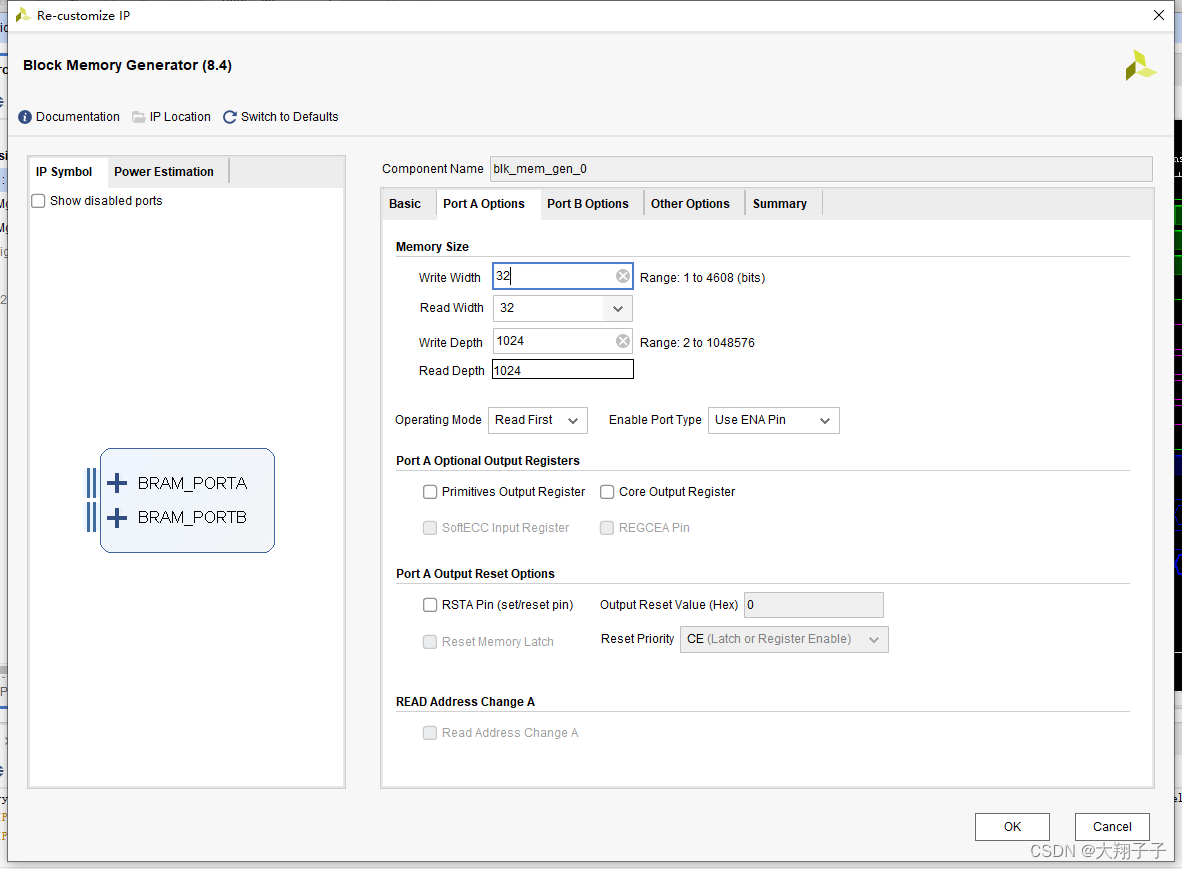
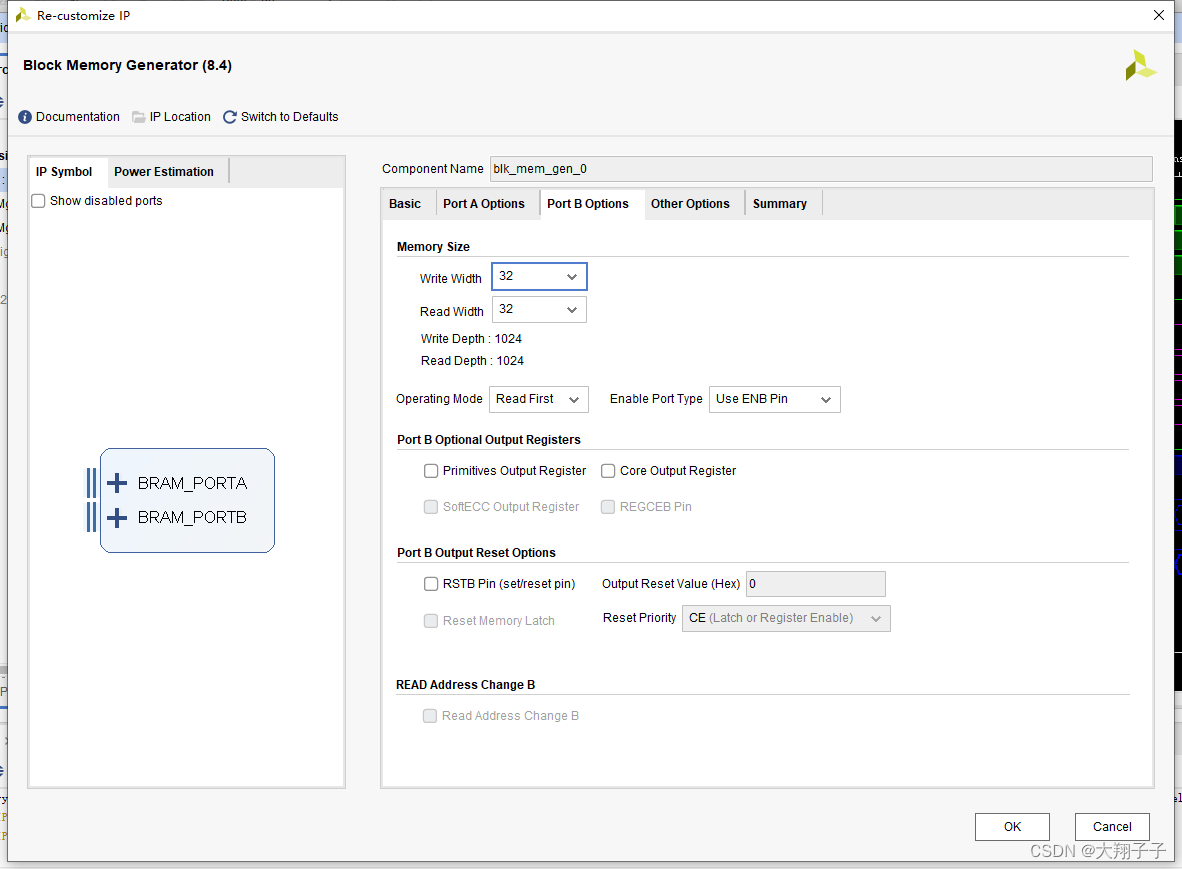
Block Ram相关IP核的配置如图所示:
—
原因分析:
网上查找相关资料后发现,应该是由于IP核配置的时候,下图所示标签没有勾选。
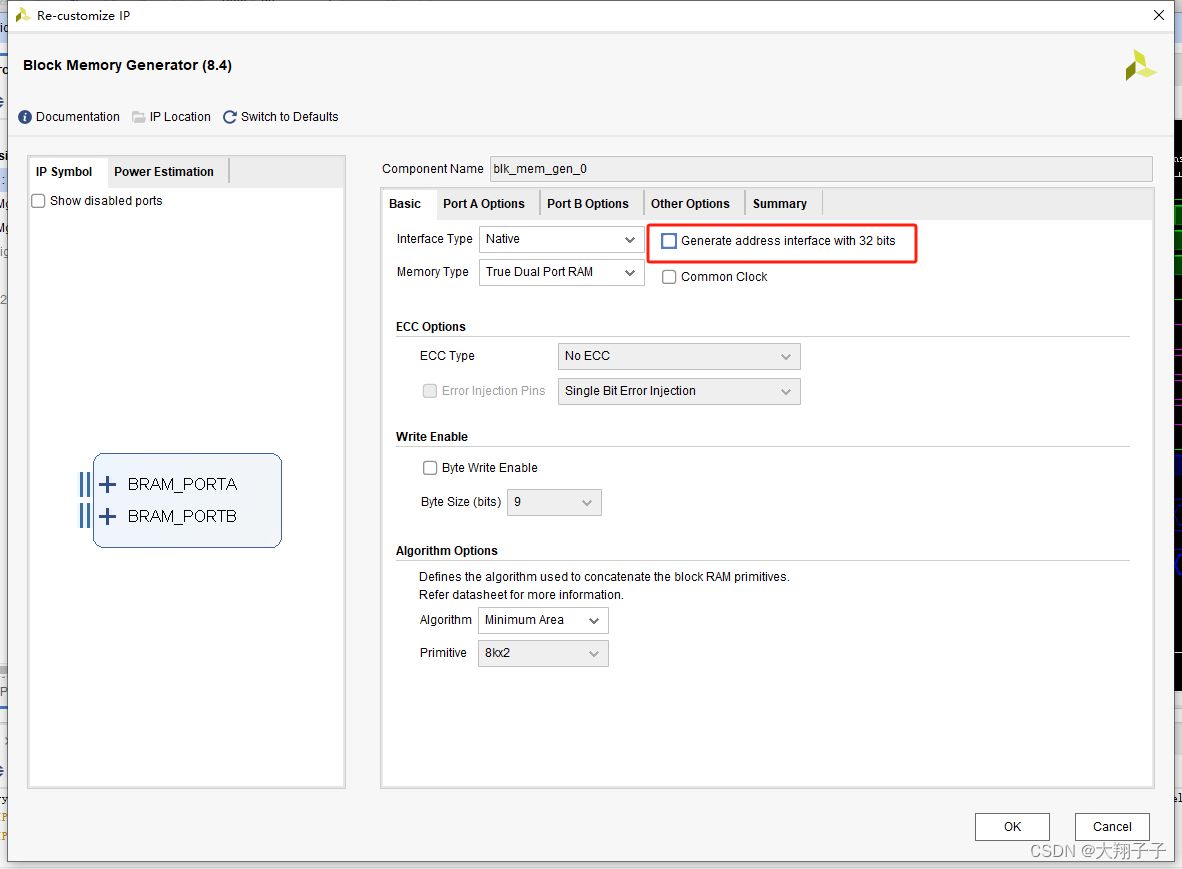
这个标签不勾选,地址的偏移就会按照配置的端口宽度进行,比如端口的write width配置为32bit,则地址每次增加1表示一个32bit。而这里我下意识的认为地址应该按照byte偏移(因为在block中例化block ram的时候,如果选择bram控制器模式则默认会把这个标签勾选从而按照byte寻址),比如地址0-3表示一个32bit,地址4-7表示另一个32bit,并且我的端口深度配置为1024,所以在读写模块中寻址的时候最大回到1564,已经超过1024的寻址范围,因此我猜测如果超出地址寻址范围则会绕回到0地址重新写,从而导致一直写入的是101、102、103、104这样的数据。端口宽度和深度配置如下图所示:
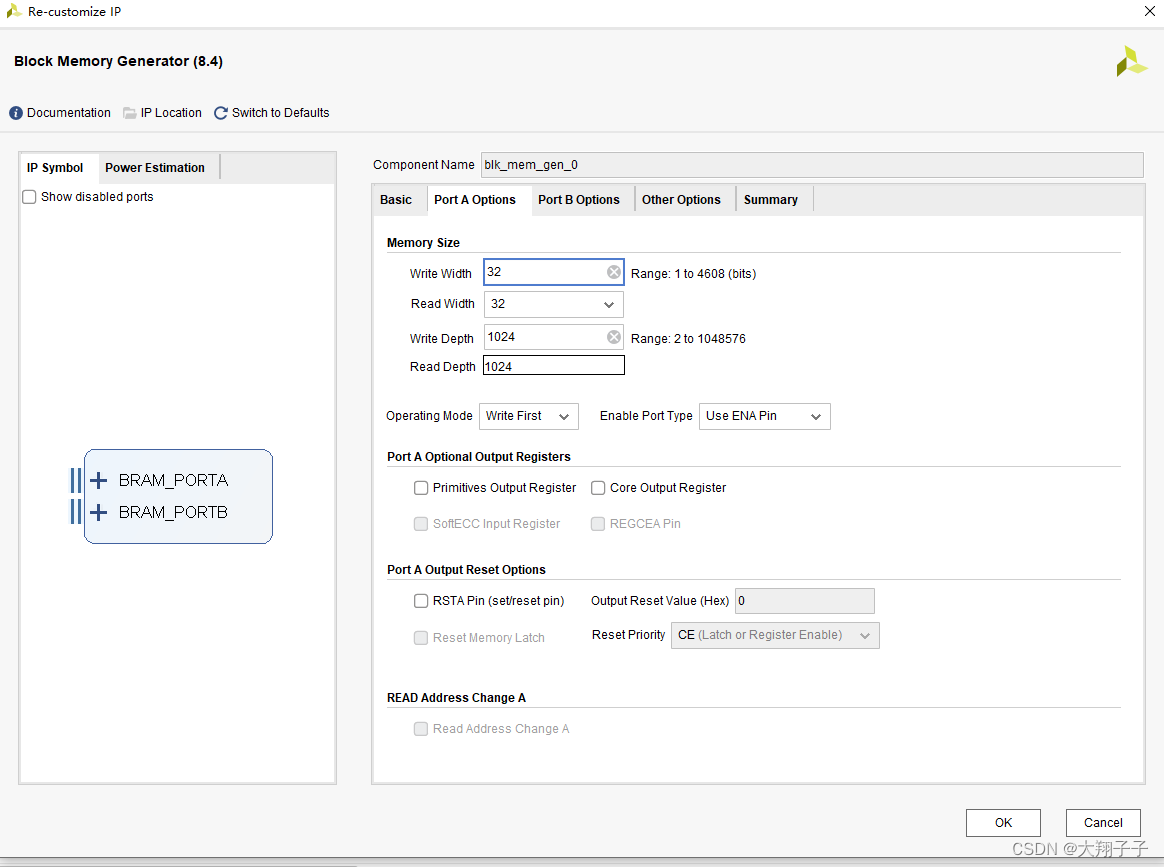
解决方案:
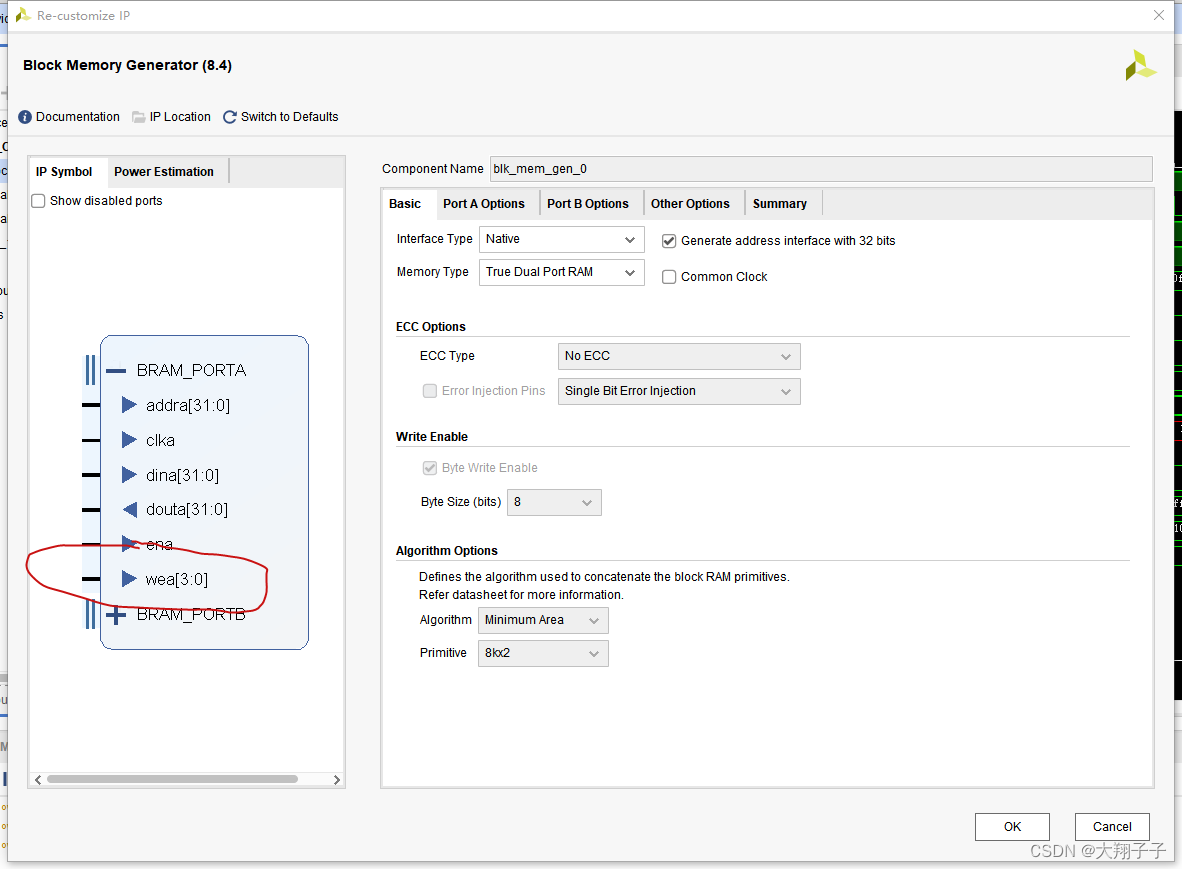
这里参考了这篇文章Block Memory Generator之TDPRAM应用知识点记录。将Generate address interface 32bit进行勾选,就能够正常按照byte进行寻址了。但是另外要注意的是如果将Generate address interface 32bit进行勾选,则wea写使能信号变成了4bit,每个bit对应一个字节的读写控制操作。如下图所示:



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











