







文章目录
一:车道线检测应用背景

解释一堆,不如图片来的直观。顾名思义,就是利用深度学习算法,检测出图片中的车道线。不同于传统算法,深度学习检测算法EndtoEnd,效果也好出许多。
二:训练数据集介绍

选用比较经典的车道线检测数据集CULane,重点是made in beijing!! 那必须得用用了啊。
三:网络模型

本篇文章的参考模型选自CVPR2021的Ultra Fast Structure-aware Deep Lane Detection,网络简单,实时性强的同时效果也很好。
如图可见,该模型由两部分组成,主分支和辅助分支。有一定了解的同学应该知道,辅助分支就是主流的一种解决车道线检测的图像分割算法,但作者实际上只是用图像分割来辅助训练,提高网络学习的性能。
训练的时候是两个分支一起训练,从不同角度训练网络,提升其整体性能,但是测试时,网络只保留主分支,提高了模型运行速度。这就是论文作者的一大创新点,一个字“贪”,但确实有效啊,思想值得学习。
接下来,我将分模块分析主分支的网络结构。
Part1:Row-anchor和Gridding-cell的引入
主分支的核心思想就是row anchor的引入,什么意思呢?传统的算法是就每一个像素点进行图像分割后分类,但是往往计算量巨大,不能满足实际运用时的实时性。所以作者从训练集上,取出了18组行先验框。
举个例子,图像时300×2000,那么我们在列上取18个像素[100,103,135,200,…],一个列像素对应的一行就是一个row anchor了,一个框里包含了3000个像素。接下来,作者又将一个行先验框中的3000个像素划分成了200个gridding cells,最后预测的时候只预测cell,这样大大减少了计算量。

Part2: 训练标签的标注
由part1可见,原先的像素单元其实都转换成了cell单元。那么自然,做标注时,只需要看每一条车道线在哪儿一行anchor的哪儿一个cell上。这些操作,实际上就是为了大大提高网络模型速度。计算量的缩减由下图可见:

Part3:损失函数的设计
该模型之所以能够在大量减少计算量的同时,还能保持较高的效果,离不开损失函数的精妙设计,让我们一起来欣赏欣赏:
① 分类损失
分类损失函数选用了Focal Loss:
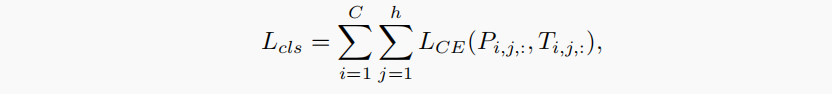
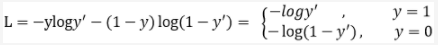
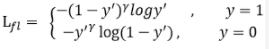
Focal Loss和传统的交叉熵损失十分相似,但是引入了损失权重系数γ,主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题。该损失函数降低了大量简单负样本在训练中所占的权重,也可理解为一种困难样本挖掘。对于容易训练的数据给予小权重,对于难以分辨的数据给予相对大的权重。这样做,可以更有针对性地训练我们的网络。
② 相似损失
一般的损失函数有上面的就够了,但作者又同时从结构方面考虑了损失。先看损失函数公式:
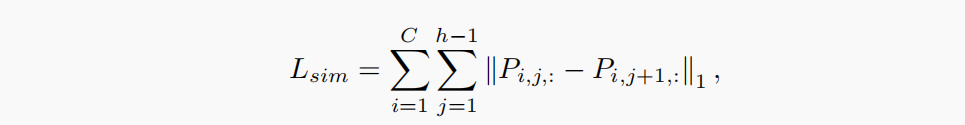
这里的两个P值其实就是同一条车道线上紧挨着的两个实际cell的概率值,两者相减取L1,目的很简单,就是希望每条车道线上相邻的点能够概率近似,也就有了一种结构近似的感觉。
③ 结构损失
这个损失函数的提出,才是真正的妙笔生花。先看计算公式:
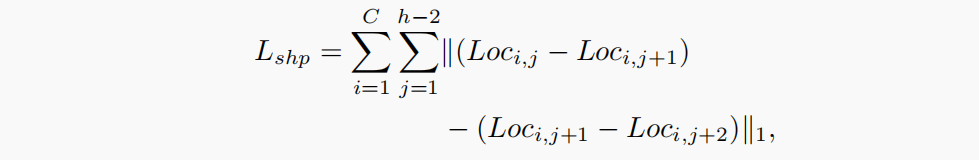
这里的
L
o
c
Loc
Loc 指每一条车道线在每一个anchor上对应的cell位置,这里的cell位置不是标签上对应的cell,而是利用训练出的数据计算出的,计算公式见下图:
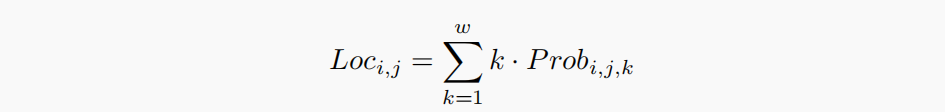
没有使用传统的
a
r
g
m
a
x
argmax
argmax 公式求取每一个anchor框内的概率最大值对应的cell作为
L
o
c
Loc
Loc,原因有两点:首先,
a
r
g
m
a
x
argmax
argmax 公式不可导,也就是无法学习。其次,该公式无法体现出同一个anchor中cell间的关系。所以,采用了期望值求取的方式,完美解决了上面的两个弊端。
最后回到这个损失函数,实际上表示着相邻的两组cell间的距离越相等越好。可以理解为最后训练出的cell连接后形成的车道线,更能像条直的。
四:小结
至此,我针对这篇论文进行了简单分析,希望对大家有所帮助。有不懂的地方或者建议,欢迎大家在下方留言评论。
我是努力在CV泥潭中摸爬滚打的江南咸鱼,我们一起努力,不留遗憾!















 8661
8661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









