







Yolo系列
概述
Yolo系列复习来自知乎:科技猛兽系列文章
本文目的是用尽量浅显易懂的语言让零基础小白能够理解什么是YOLO系列模型,以及他们的设计思想和改进思路分别是什么。我不会把YOLO的论文给你用软件翻译一遍,这样做毫无意义;也不会使用太专业晦涩的名词和表达,对于每一个新的概念都会解释得尽量通俗一些,目的是使得你能像看故事一样学习YOLO模型,我觉得这样的学习方式才是知乎博客的意义所在。
为了使本文尽量生动有趣,我用葫芦娃作为例子展示YOLO的过程(真的是尽力了。。。)。

同时,会对YOLO v1和YOLOv5的代码进行解读,其他的版本就只介绍改进了。
1 先从一款强大的app说起
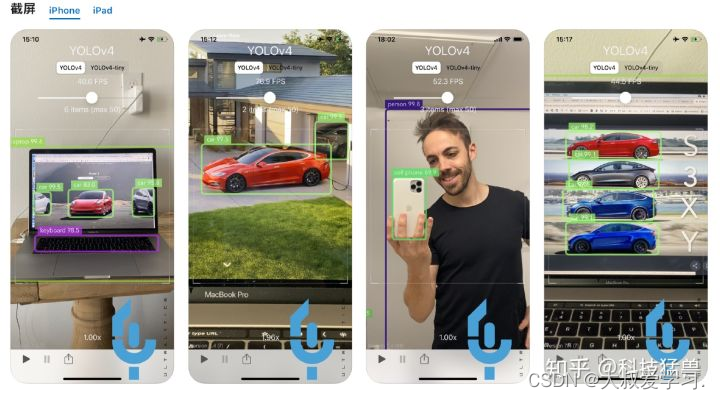
YOLO v5其实一开始是以一款app进入人们的视野的,就是上图的这个,叫:i detection(图上标的是YOLO v4,但其实算法是YOLO v5),使用iOS系列的小伙伴呢,就可以立刻点赞后关掉我这篇文章,去下载这个app玩一玩。在任何场景下(工业场景,生活场景等等)都可以试试这个app和这个算法,这个app中间还有一个button,来调节app使用的模型的大小,更大的模型实时性差但精度高,更小的模型实时性好但精度差。
值得一提的是,这款app就是YOLO v5的作者亲自完成的。而且,我写这篇文章的时候YOLO v5的论文还没有出来,还在实验中,等论文出来应该是2020年底或者2021年初了。
读到这里,你觉得YOLO v5的最大特点是什么?
答案就是:一个字:快,应用于移动端,模型小,速度快。
首先我个人觉得任何一个模型都有下面3部分组成:
- 前向传播部分:90%
- 损失函数部分
- 反向传播部分
其中前向传播部分占用的时间应该在90%左右,即搞清楚前向传播部分也就搞清楚了这模型的实现流程和细节。本着这一原则,我们开始YOLO系列模型的解读:
2 不得不谈的分类模型
在进入目标检测任务之前首先得学会图像分类任务,这个任务的特点是输入一张图片,输出是它的类别。
对于输入图片,我们一般用一个矩阵表示。
对于输出结果,我们一般用一个one-hot vector表示: ,哪一维是1,就代表图片属于哪一类。
所以,在设计神经网络时,结构大致应该长这样:
img cbrp16 cbrp32 cbrp64 cbrp128 … fc256-fc[10]
这里的cbrp指的是conv,bn,relu,pooling的串联。
由于输入要是one-hot形式,所以最后我们设计了2个fc层(fully connencted layer),我们称之为“分类头”或者“决策层”。
3 YOLO系列思想的雏形:YOLO v0
有了上面的分类器,我们能不能用它来做检测呢?
要回答这个问题,首先得看看检测器和分类器的输入输出有什么不一样。首先他们的输入都是image,但是分类器的输出是一个one-hot vector,而检测器的输出是一个框(Bounding Box)。
框,该怎么表示?
在一个图片里面表示一个框,有很多种方法,比如:

x,y,w,h(如上图)
p1,p2,p3,p4(4个点坐标)
cx,cy,w,h(cx,cy为中心点坐标)
x,y,w,h,angle(还有的目标是有角度的,这时叫做Rotated Bounding Box)
…
所以表示的方法不是一成不变的,但你会发现:不管你用什么形式去表达这个Bounding Box,你模型输出的结果一定是一个vector,那这个vector和分类模型输出的vector本质上有什么区别吗?
答案是:没有,都是向量而已,只是分类模型输出是one-hot向量,检测模型输出是我们标注的结果。
所以你应该会发现,检测的方法呼之欲出了。那分类模型可以用来做检测吗?
当然可以,这时,你可以把检测的任务当做是遍历性的分类任务。
如何遍历?
我们的目标是一个个框,那就用这个框去遍历所有的位置,所有的大小。
比如下面这张图片,我需要你检测葫芦娃的脸,如图1所示:

你先预设一个框的大小,然后在图片上遍历这个框,比如第一行全都不是头。第4个框只有一部分目标在,也不算。第5号框算是一个头,我们记住它的位置。这样不断地滑动,就是遍历性地分类。
接下来要遍历框的大小:因为你刚才是预设一个框的大小,但葫芦娃的头有大有小,你还得遍历框的大小,如下图2所示:
还没有结束,刚才滑窗时是挨个滑,但其实没有遍历所有的位置,更精确的遍历方法应该如下图3所示:


那这种方法如何训练呢?
本质上还是训练一个二分类器。这个二分类器的输入是一个框的内容,输出是(前景/背景)。
第1个问题:
框有不同的大小,对于不同大小的框,输入到相同的二分类器中吗?
是的。要先把不同大小的input归一化到统一的大小。
第2个问题:
背景图片很多,前景图片很少:二分类样本不均衡。
确实是这样,你看看一张图片有多少框对应的是背景,有多少框才是葫芦娃的头。
以上就是传统检测方法的主要思路:
耗时。
操作复杂,需要手动生成大量的样本。
到现在为止,我们用分类的算法设计了一个检测器,它存在着各种各样的问题,现在是优化的时候了(接下来正式进入YOLO系列方法了):
YOLO的作者当时是这么想的:你分类器输出一个one-hot vector,那我把它换成(x,y,w,h,c),c表示confidence置信度,把问题转化成一个回归问题,直接回归出Bounding Box的位置不就好了吗?


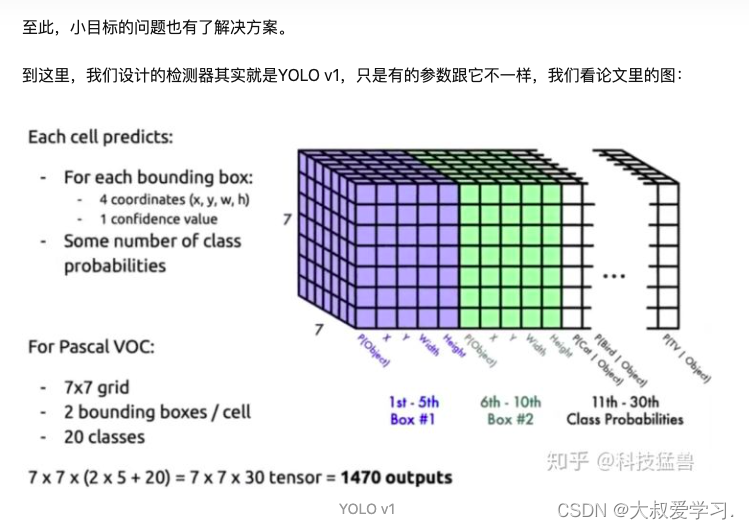
Yolo v1
YOLO v1终于诞生
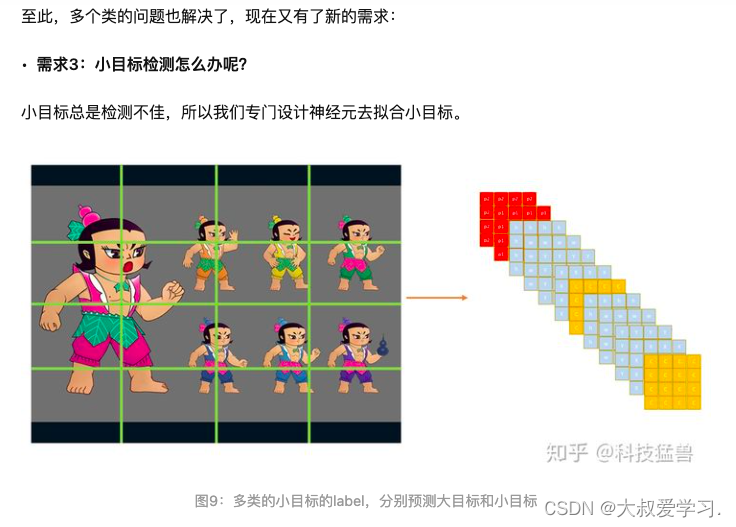
需求1:YOLO v0只能输出一个目标,那比如下图4的多个目标怎么办呢?

你可能会回答:我输出N个向量不就行了吗?但具体输出多少个合适呢?图4有7个目标,那有的图片有几百个目标,你这个N又该如何调整呢?
答:为了保证所有目标都被检测到,我们应该输出尽量多的目标。

但这种方法也不是最优的,最优的应该是下图这样:
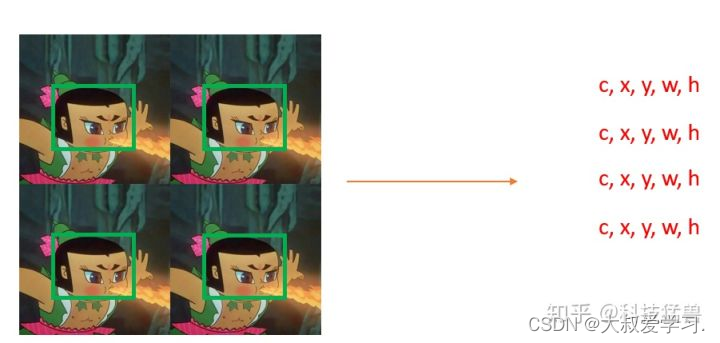
如图5所示:用一个(c,x,y,w,h)去负责image某个区域的目标。
比如说图片设置为16个区域,每个区域用1个(c,x,y,w,h)去负责:
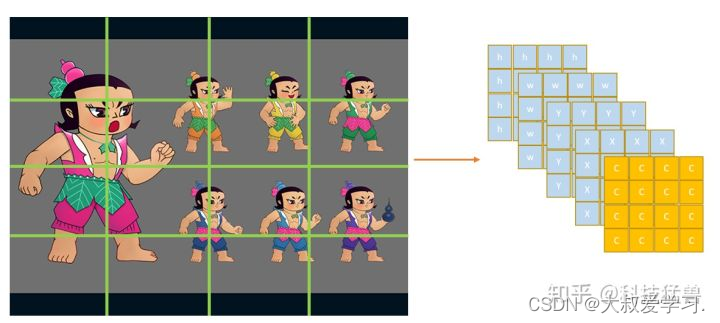
就可以一次输出16个框,每个框是1个(c,x,y,w,h),如图6所示。
为什么这样子更优?因为conv操作是位置强相关的,就是原来的目标在哪里,你conv之后的feature map上还在哪里,所以图片划分为16个区域,结果也应该分布在16个区域上,所以我们的结果(Tensor)的维度size是:(5,4,4)。
那现在你可能会问:c的真值该怎么设置呢?
答:看葫芦娃的大娃,他的脸跨了4个区域(grid),但只能某一个grid的c=1,其他的c=0。那么该让哪一个grid的c=1呢?就看他的脸的中心落在了哪个grid里面。根据这一原则,c的真值为下图7所示:
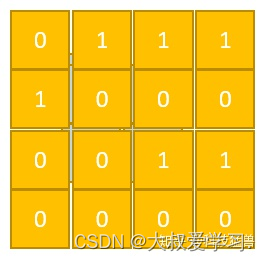
但是你发现7个葫芦娃只有6个1,原因是某一个grid里面有2个目标,确实如此,第三行第三列的grid既有水娃又有隐身娃。这种一个区域有多个目标的情况我们目前没法解决,因为我们的模型现在能力就这么大,只能在一个区域中检测出一个目标,如何改进我们马上就讨论,你可以现在先自己想一想。
总之现在我们设计出了模型的输出结果,那距离完成模型的设计还差一个损失函数,那Loss咋设计呢?看下面的伪代码:
loss = 0
for img in img_all:
for i in range(4):
for j in range(4):
loss_ij = lamda_1*(c_pred-c_label)**2 + c_label*(x_pred-x_label)**2 +\
c_label*(y_pred-y_label)**2 + c_label*(w_pred-w_label)**2 + \
c_label*(h_pred-h_label)**2
loss += loss_ij
loss.backward()
遍历所有图片,遍历所有位置,计算loss。
好现在模型设计完了,回到刚才的问题:模型现在能力就这么大,只能在一个区域中检测出一个目标,如何改进?



loss = 0
for img in img_all:
for i in range(3):
for j in range(4):
c_loss = lamda_1*(c_pred-c_label)**2
geo_loss = c_label*(x_pred-x_label)**2 +\
c_label*(y_pred-y_label)**2 + c_label*(w_pred-w_label)**2 + \
c_label*(h_pred-h_label)**2
class_loss = 1/m * mse_loss(p_pred, p_label)
loss_ij =c_loss + geo_loss + class_loss
loss += loss_ij
loss.backward()
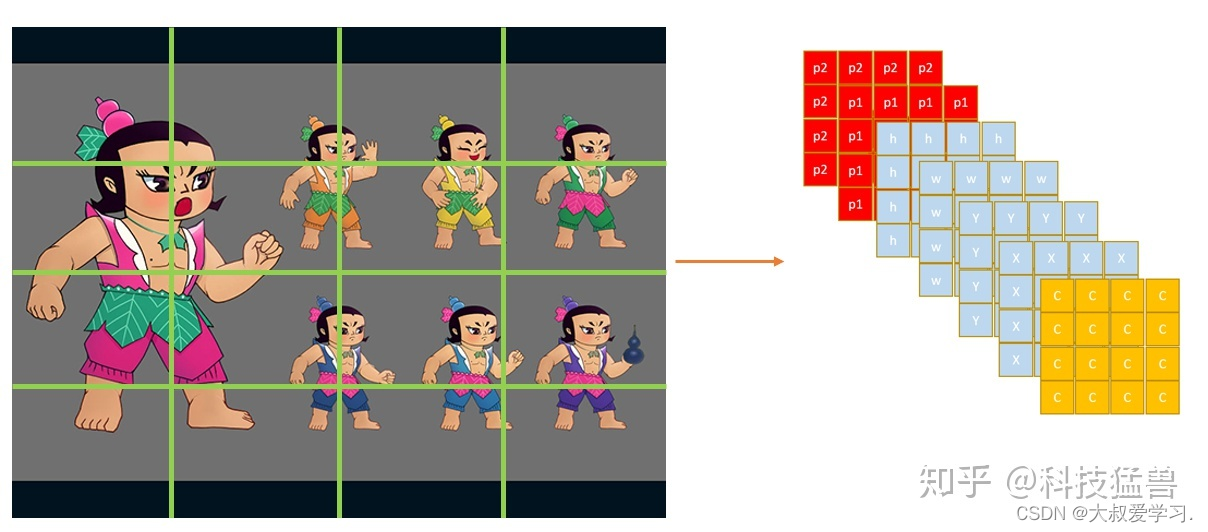
对于每个区域,我们用2个五元组(c,x,y,w,h),一个负责回归大目标,一个负责回归小目标,同样添加one-hot vector,one-hot就是[0,1],[1,0]这样子,来表示属于哪一类(葫芦娃的头or葫芦娃的葫芦)。
伪代码变为了:
loss = 0
for img in img_all:
for i in range(3):
for j in range(4):
c_loss = lamda_1*(c_pred-c_label)**2
geo_loss = c_label_big*(x_big_pred-x_big_label)**2 +\
c_label_big*(y_big_pred-y_big_label)**2 + c_label_big*(w_big_pred-w_big_label)**2 + \
c_label_big*(h_big_pred-h_big_label)**2 +\
c_label_small*(x_small_pred-x_small_label)**2 +\
c_label_small*(y_small_pred-y_small_label)**2 + c_label_small*(w_small_pred-w_small_label)**2 + \
c_label_small*(h_small_pred-h_small_label)**2
class_loss = 1/m * mse_loss(p_pred, p_label)
loss_ij =c_loss + geo_loss + class_loss
loss += loss_ij
loss.backward()




class VGG(nn.Module):
def __init__(self):
super(VGG,self).__init__()
# the vgg's layers
#self.features = features
cfg = [64,64,'M',128,128,'M',256,256,256,'M',512,512,512,'M',512,512,512,'M']
layers= []
batch_norm = False
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2,stride = 2)]
else:
conv2d = nn.Conv2d(in_channels,v,kernel_size=3,padding = 1)
if batch_norm:
layers += [conv2d,nn.Batchnorm2d(v),nn.ReLU(inplace=True)]
else:
layers += [conv2d,nn.ReLU(inplace=True)]
in_channels = v
# use the vgg layers to get the feature
self.features = nn.Sequential(*layers)
# 全局池化
self.avgpool = nn.AdaptiveAvgPool2d((7,7))
# 决策层:分类层
self.classifier = nn.Sequential(
nn.Linear(512*7*7,4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096,4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096,1000),
)
for m in self.modules():
if isinstance(m,nn.Conv2d):
nn.init.kaiming_normal_(m.weight,mode='fan_out',nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias,0)
elif isinstance(m,nn.BatchNorm2d):
nn.init.constant_(m.weight,1)
nn.init.constant_(m.bias,1)
elif isinstance(m,nn.Linear):
nn.init.normal_(m.weight,0,0.01)
nn.init.constant_(m.bias,0)
def forward(self,x):
x = self.features(x)
x_fea = x
x = self.avgpool(x)
x_avg = x
x = x.view(x.size(0),-1)
x = self.classifier(x)
return x,x_fea,x_avg
def extractor(self,x):
x = self.features(x)
return x
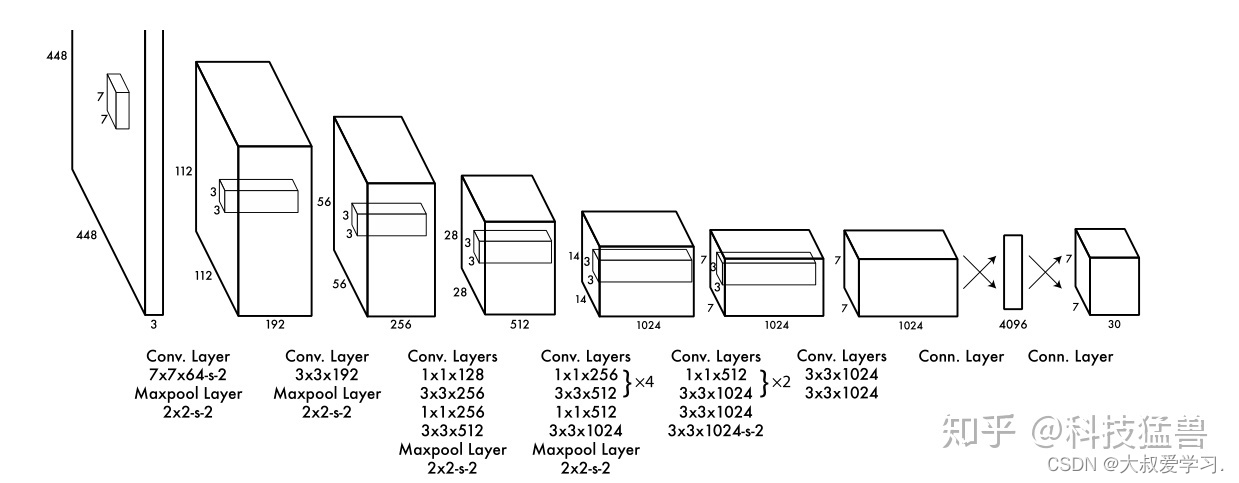
定义检测头:
self.detector = nn.Sequential(
nn.Linear(512*7*7,4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096,1470),
)
整体模型:
class YOLOV1(nn.Module):
def __init__(self):
super(YOLOV1,self).__init__()
vgg = VGG()
self.extractor = vgg.extractor
self.avgpool = nn.AdaptiveAvgPool2d((7,7))
# 决策层:检测层
self.detector = nn.Sequential(
nn.Linear(512*7*7,4096),
nn.ReLU(True),
nn.Dropout(),
#nn.Linear(4096,1470),
nn.Linear(4096,245),
#nn.Linear(4096,5),
)
for m in self.modules():
if isinstance(m,nn.Conv2d):
nn.init.kaiming_normal_(m.weight,mode='fan_out',nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias,0)
elif isinstance(m,nn.BatchNorm2d):
nn.init.constant_(m.weight,1)
nn.init.constant_(m.bias,1)
elif isinstance(m,nn.Linear):
nn.init.normal_(m.weight,0,0.01)
nn.init.constant_(m.bias,0)
def forward(self,x):
x = self.extractor(x)
#import pdb
#pdb.set_trace()
x = self.avgpool(x)
x = x.view(x.size(0),-1)
x = self.detector(x)
b,_ = x.shape
#x = x.view(b,7,7,30)
x = x.view(b,7,7,5)
#x = x.view(b,1,1,5)
return x
主函数:
if __name__ == '__main__':
vgg = VGG()
x = torch.randn(1,3,512,512)
feature,x_fea,x_avg = vgg(x)
print(feature.shape)
print(x_fea.shape)
print(x_avg.shape)
yolov1 = YOLOV1()
feature = yolov1(x)
# feature_size b*7*7*30
print(feature.shape)
2.模型训练:
主函数:
if __name__ == "__main__":
train()
下面看train()函数:
def train():
for epoch in range(epochs):
ts = time.time()
for iter, batch in enumerate(train_loader):
optimizer.zero_grad()
# 取图片
inputs = input_process(batch)
# 取标注
labels = target_process(batch)
# 获取得到输出
outputs = yolov1_model(inputs)
#import pdb
#pdb.set_trace()
#loss = criterion(outputs, labels)
loss,lm,glm,clm = lossfunc_details(outputs,labels)
loss.backward()
optimizer.step()
#print(torch.cat([outputs.detach().view(1,5),labels.view(1,5)],0).view(2,5))
if iter % 10 == 0:
# print(torch.cat([outputs.detach().view(1,5),labels.view(1,5)],0).view(2,5))
print("epoch{}, iter{}, loss: {}, lr: {}".format(epoch, iter, loss.data.item(),optimizer.state_dict()['param_groups'][0]['lr']))
#print("Finish epoch {}, time elapsed {}".format(epoch, time.time() - ts))
#print("*"*30)
#val(epoch)
scheduler.step()
训练过程比较常规,先取1个batch的训练数据,分别得到inputs和labels,依次计算loss,反传,step等。
下面说下2个训练集的数据处理函数:
input_process:
def input_process(batch):
#import pdb
#pdb.set_trace()
batch_size=len(batch[0])
input_batch= torch.zeros(batch_size,3,448,448)
for i in range(batch_size):
inputs_tmp = Variable(batch[0][i])
inputs_tmp1=cv2.resize(inputs_tmp.permute([1,2,0]).numpy(),(448,448))
inputs_tmp2=torch.tensor(inputs_tmp1).permute([2,0,1])
input_batch[i:i+1,:,:,:]= torch.unsqueeze(inputs_tmp2,0)
return input_batch

def target_process(batch,grid_number=7):
# batch[1]表示label
# batch[0]表示image
batch_size=len(batch[0])
target_batch= torch.zeros(batch_size,grid_number,grid_number,30)
#import pdb
#pdb.set_trace()
for i in range(batch_size):
labels = batch[1]
batch_labels = labels[i]
#import pdb
#pdb.set_trace()
number_box = len(batch_labels['boxes'])
for wi in range(grid_number):
for hi in range(grid_number):
# 遍历每个标注的框
for bi in range(number_box):
bbox=batch_labels['boxes'][bi]
_,himg,wimg = batch[0][i].numpy().shape
bbox = bbox/ torch.tensor([wimg,himg,wimg,himg])
#import pdb
#pdb.set_trace()
center_x= (bbox[0]+bbox[2])*0.5
center_y= (bbox[1]+bbox[3])*0.5
#print("[%s,%s,%s],[%s,%s,%s]"%(wi/grid_number,center_x,(wi+1)/grid_number,hi/grid_number,center_y,(hi+1)/grid_number))
if center_x<=(wi+1)/grid_number and center_x>=wi/grid_number and center_y<=(hi+1)/grid_number and center_y>= hi/grid_number:
#pdb.set_trace()
cbbox = torch.cat([torch.ones(1),bbox])
# 中心点落在grid内,
target_batch[i:i+1,wi:wi+1,hi:hi+1,:] = torch.unsqueeze(cbbox,0)
#else:
#cbbox = torch.cat([torch.zeros(1),bbox])
#import pdb
#pdb.set_trace()
#rint(target_batch[i:i+1,wi:wi+1,hi:hi+1,:])
#target_batch[i:i+1,wi:wi+1,hi:hi+1,:] = torch.unsqueeze(cbbox,0)
return target_batch

def lossfunc_details(outputs,labels):
# 判断维度
assert ( outputs.shape == labels.shape),"outputs shape[%s] not equal labels shape[%s]"%(outputs.shape,labels.shape)
#import pdb
#pdb.set_trace()
b,w,h,c = outputs.shape
loss = 0
#import pdb
#pdb.set_trace()
conf_loss_matrix = torch.zeros(b,w,h)
geo_loss_matrix = torch.zeros(b,w,h)
loss_matrix = torch.zeros(b,w,h)
for bi in range(b):
for wi in range(w):
for hi in range(h):
#import pdb
#pdb.set_trace()
# detect_vector=[confidence,x,y,w,h]
detect_vector = outputs[bi,wi,hi]
gt_dv = labels[bi,wi,hi]
conf_pred = detect_vector[0]
conf_gt = gt_dv[0]
x_pred = detect_vector[1]
x_gt = gt_dv[1]
y_pred = detect_vector[2]
y_gt = gt_dv[2]
w_pred = detect_vector[3]
w_gt = gt_dv[3]
h_pred = detect_vector[4]
h_gt = gt_dv[4]
loss_confidence = (conf_pred-conf_gt)**2
#loss_geo = (x_pred-x_gt)**2 + (y_pred-y_gt)**2 + (w_pred**0.5-w_gt**0.5)**2 + (h_pred**0.5-h_gt**0.5)**2
loss_geo = (x_pred-x_gt)**2 + (y_pred-y_gt)**2 + (w_pred-w_gt)**2 + (h_pred-h_gt)**2
loss_geo = conf_gt*loss_geo
loss_tmp = loss_confidence + 0.3*loss_geo
#print("loss[%s,%s] = %s,%s"%(wi,hi,loss_confidence.item(),loss_geo.item()))
loss += loss_tmp
conf_loss_matrix[bi,wi,hi]=loss_confidence
geo_loss_matrix[bi,wi,hi]=loss_geo
loss_matrix[bi,wi,hi]=loss_tmp
#打印出batch中每张片的位置loss,和置信度输出
print(geo_loss_matrix)
print(outputs[0,:,:,0]>0.5)
return loss,loss_matrix,geo_loss_matrix,conf_loss_matrix

Yolo v2
检测头的改进:
YOLO v1虽然快,但是预测的框不准确,很多目标找不到:
预测的框不准确:准确度不足。
很多目标找不到:recall不足。
我们一个问题一个问题解决,首先第1个:
问题1:预测的框不准确:
当时别人是怎么做的?
同时代的检测器有R-CNN,人家预测的是偏移量。
什么是偏移量?
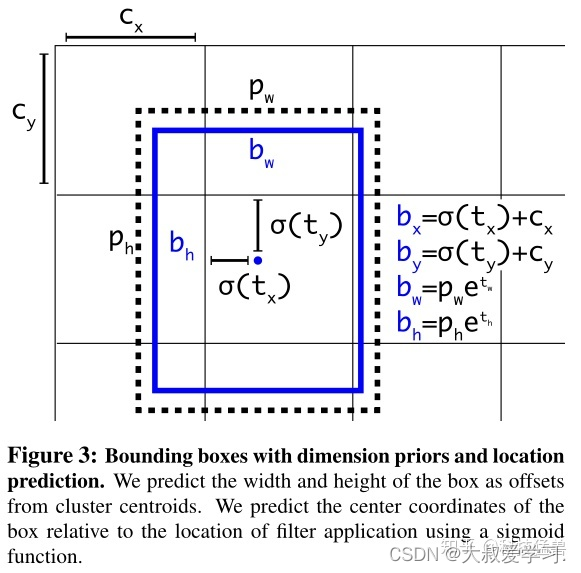
之前YOLO v1直接预测x,y,w,h,范围比较大,现在我们想预测一个稍微小一点的值,来增加准确度。
不得不先介绍2个新概念:基于grid的偏移量和基于anchor的偏移量。什么意思呢?
基于anchor的偏移量的意思是,anchor的位置是固定的,偏移量=目标位置-anchor的位置。
基于grid的偏移量的意思是,grid的位置是固定的,偏移量=目标位置-grid的位置。



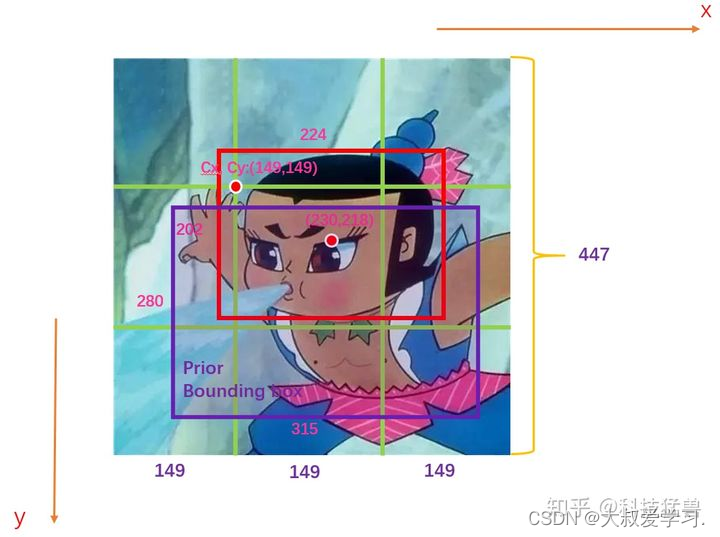
如图1所示,假设此图分为9个grid,GT如红色的框所示,Anchor如紫色的框所示。图中的数字为image的真实信息。
我们首先会对这些值归一化,结果如下图2所示:
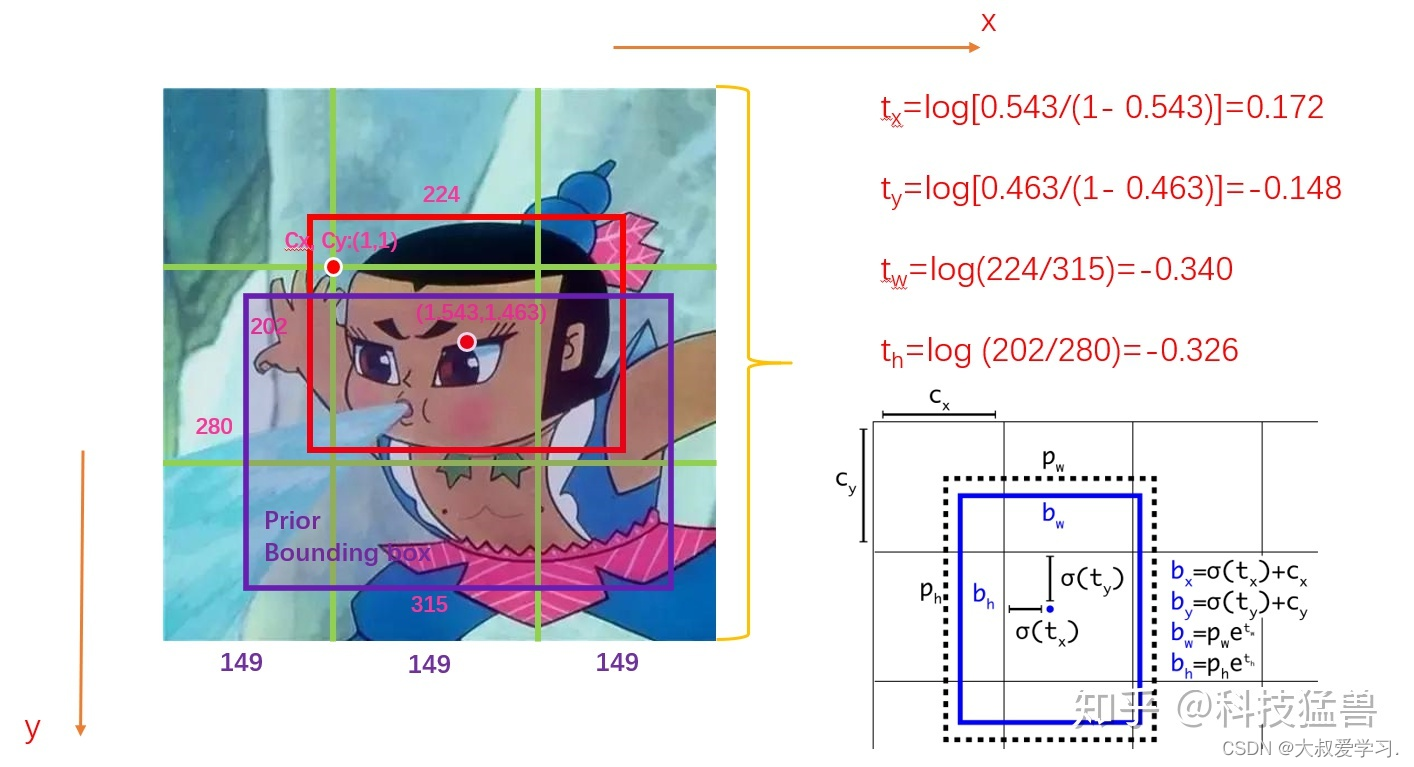
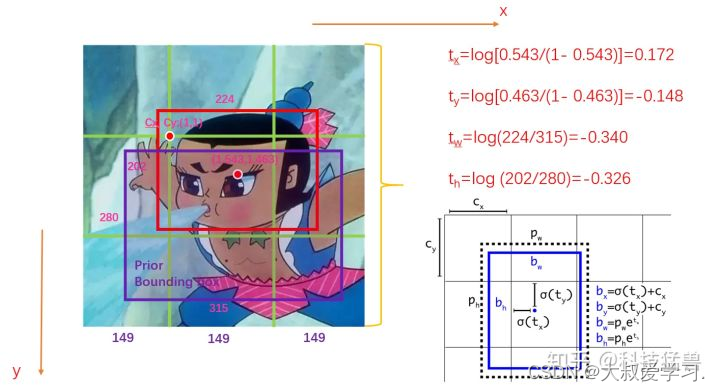
如图1所示,假设此图分为9个grid,GT如红色的框所示,Anchor如紫色的框所示。图中的数字为image的真实信息。
我们首先会对这些值归一化,结果如下图2所示:



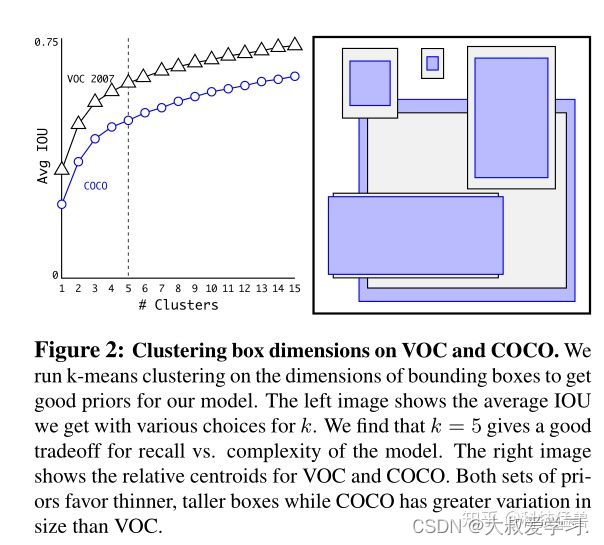


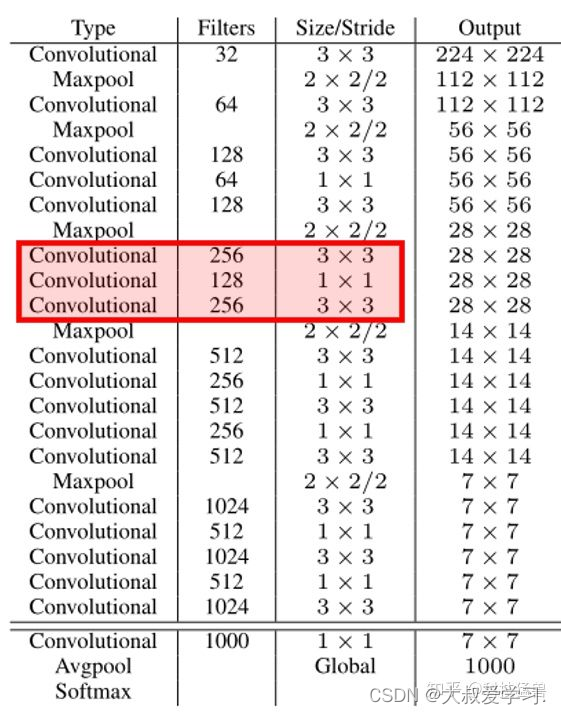
为了进一步提升性能,YOLO v2重新训练了一个darknet-19,如下图4所示:


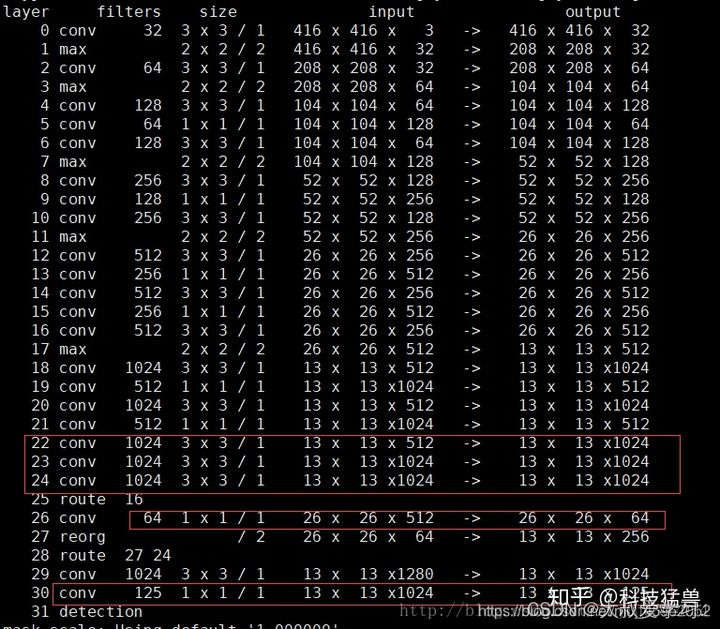


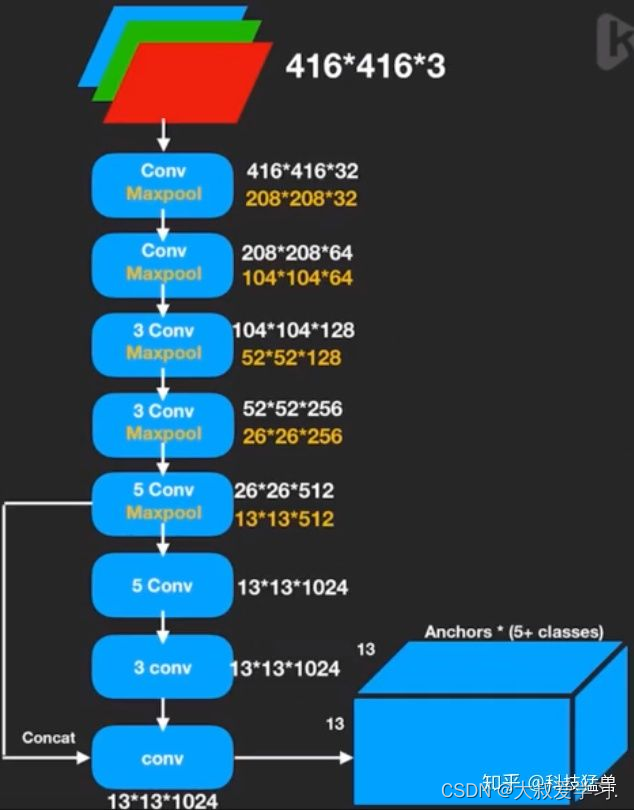




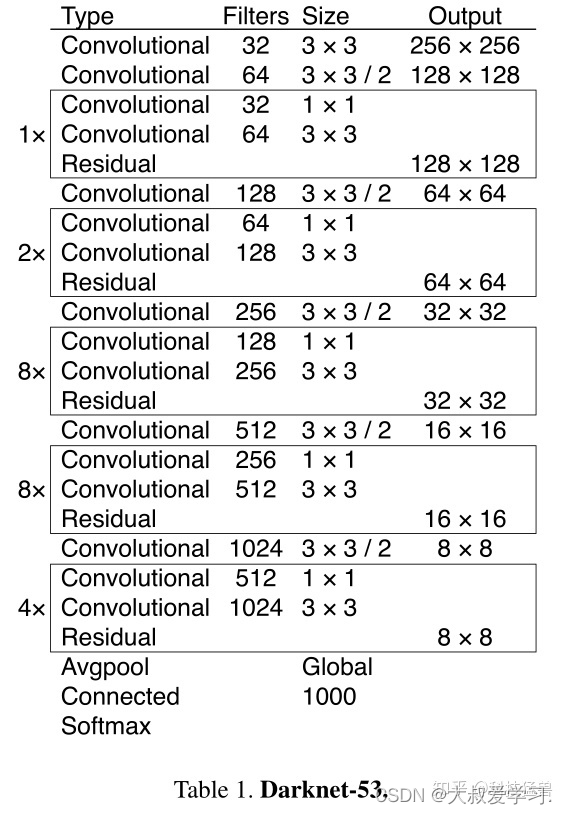
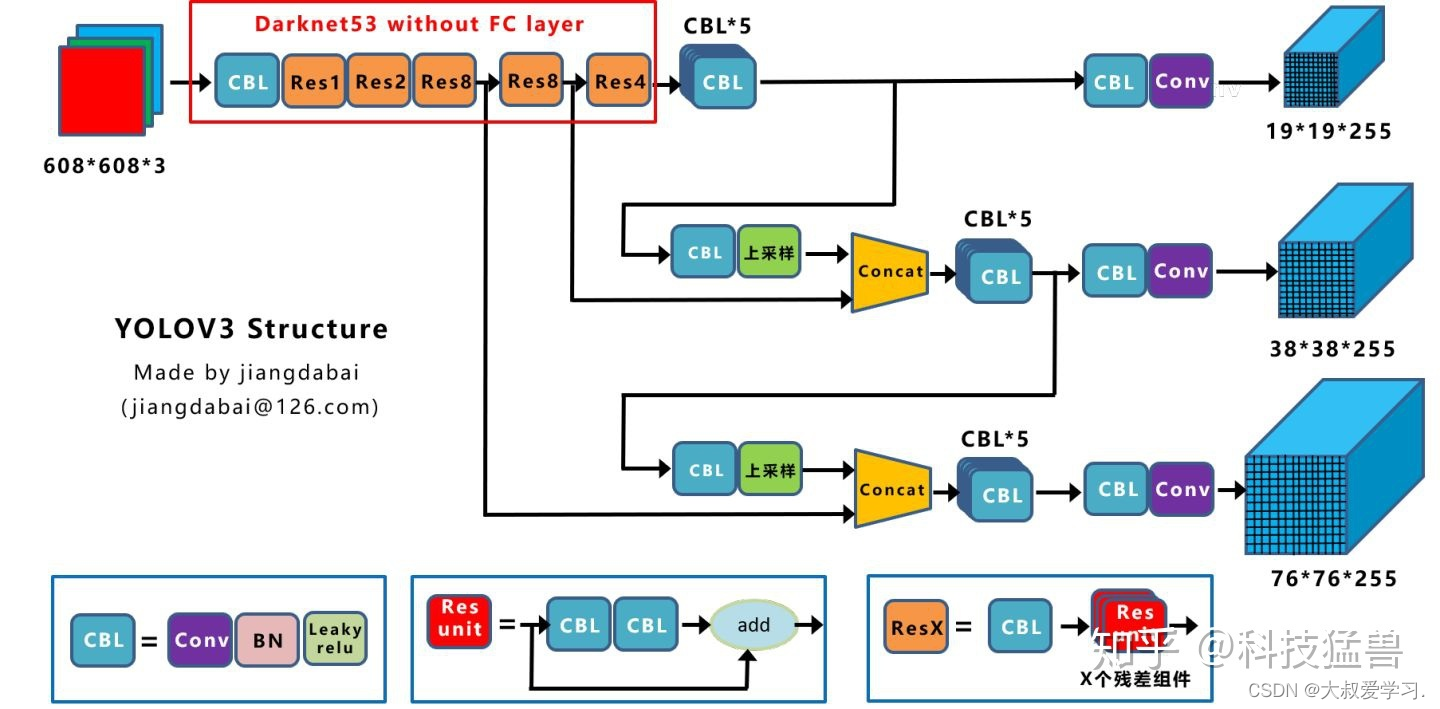
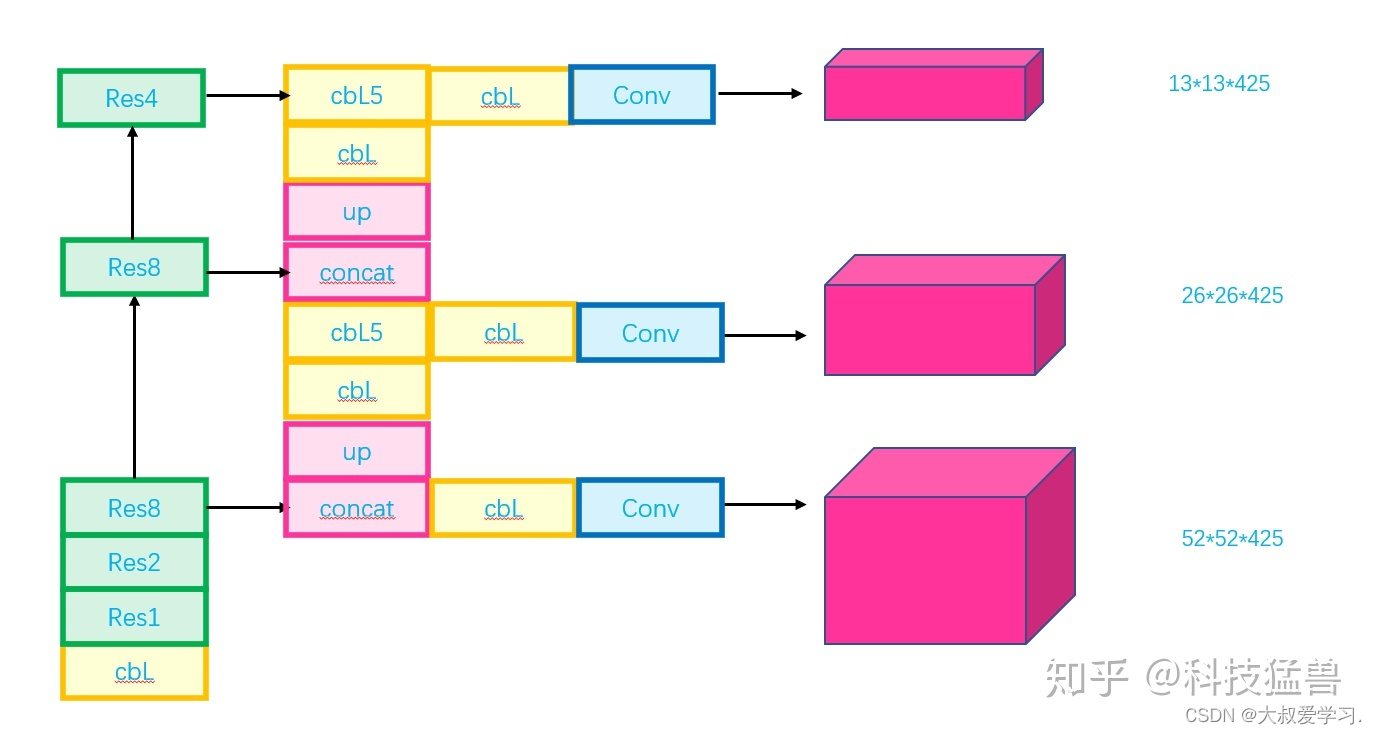
 ## Yolo v3
## Yolo v3
之前在说小目标检测仍然是YOLO v2的痛,YOLO v3是如何改进的呢?如下图所示。
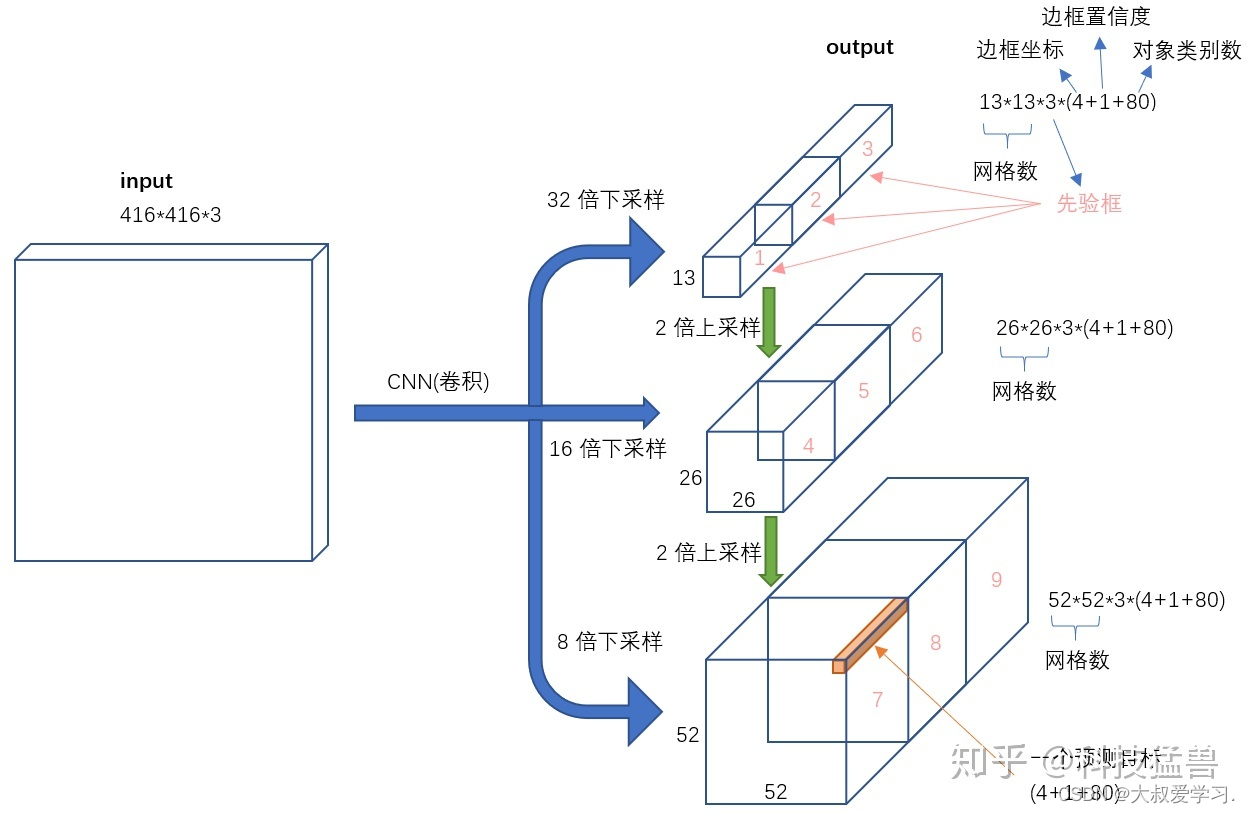



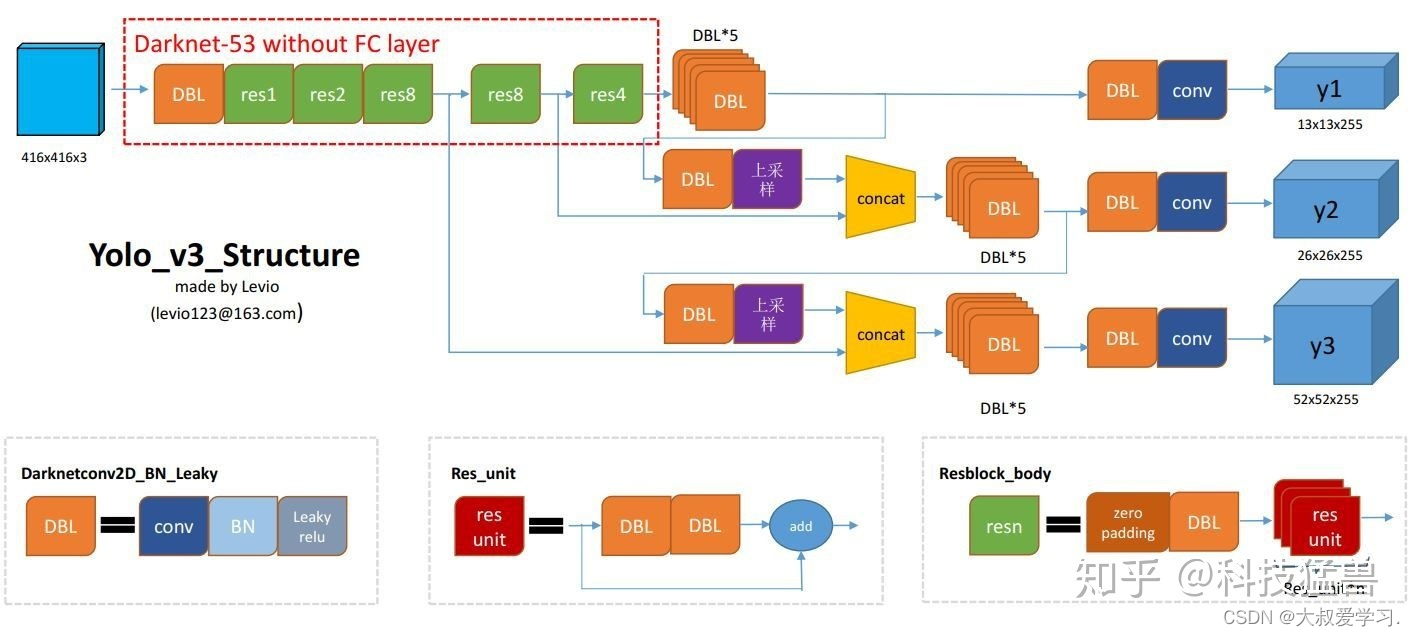
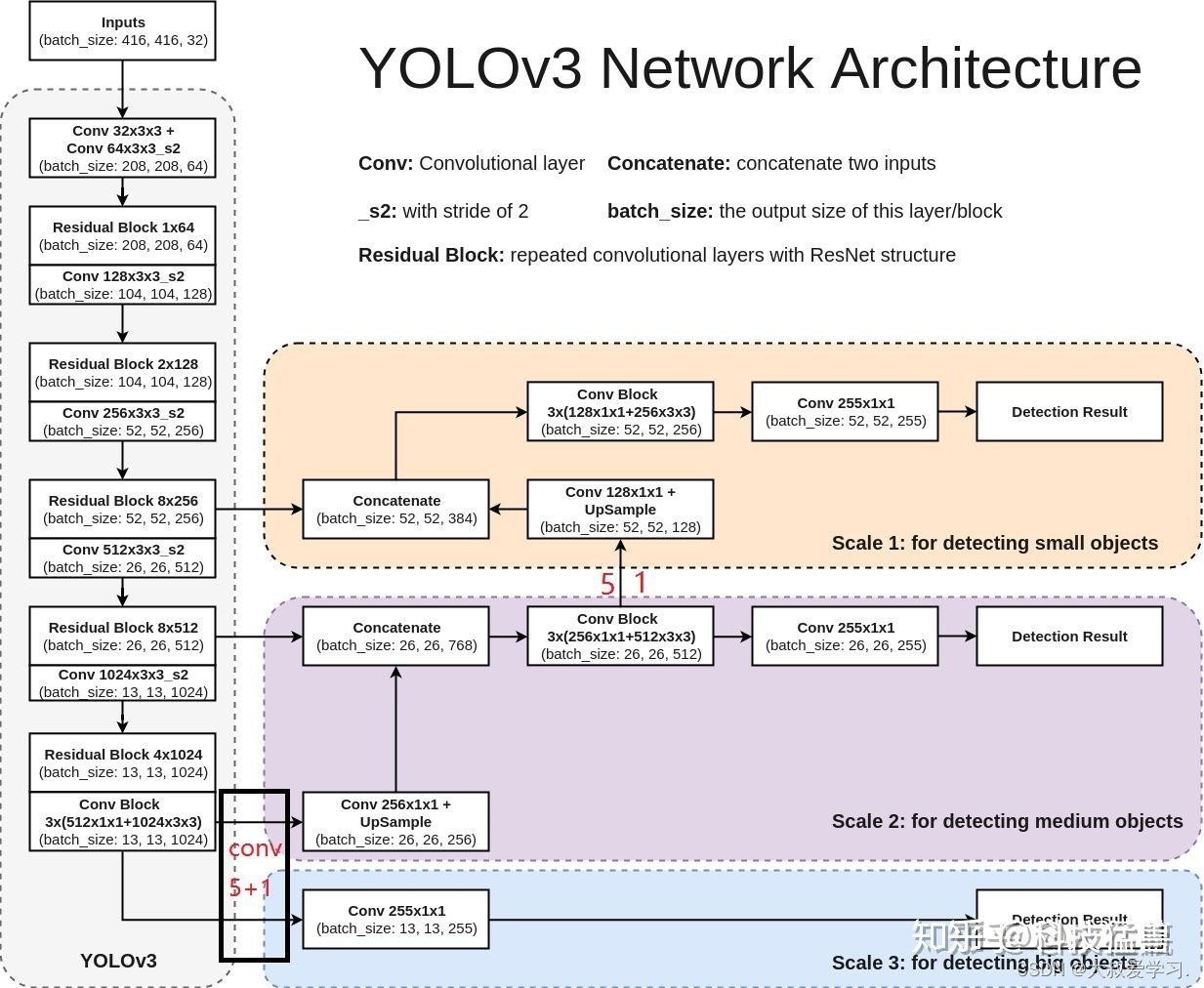



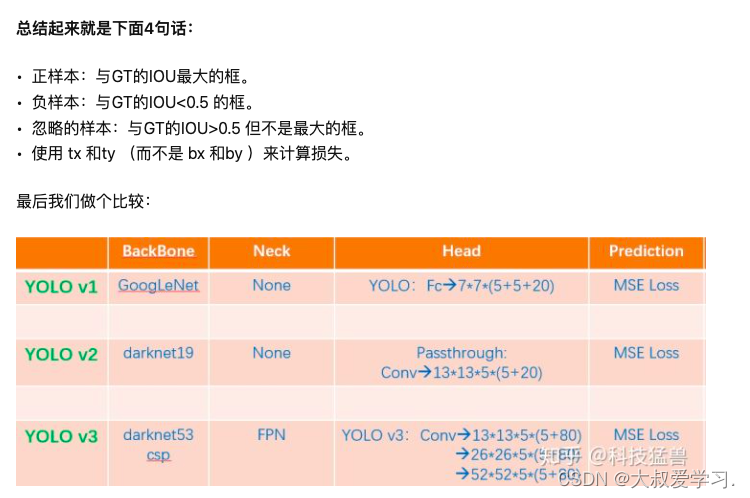


















 2386
2386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









