







目标检测的评价指标P,R,mAP
1 基本概念
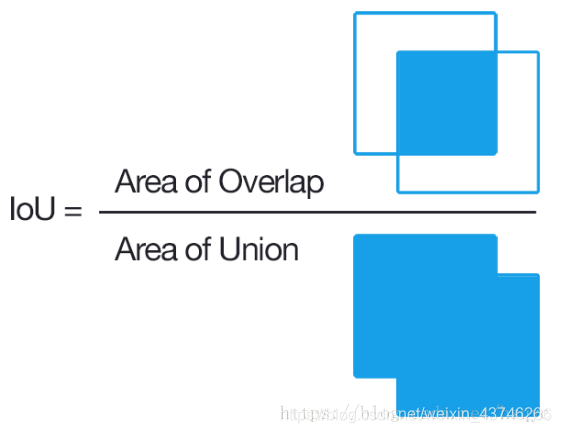
1.1 IOU(Intersection over Union)
交集除以并集,这样可以更好的表示两个框的重合程度
1.2 TP TN FP FN
TP(Truth Positive):预测对的正类,我说他对,而且他本来也是对的
TN(Truth Negative):预测对的负类,我说他错,而且他本来也是错的
FP(False Positive):预测错的正类,我说他对,但是他错了
FN(False Negative):预测错的负类,我说他对,但是他是对的
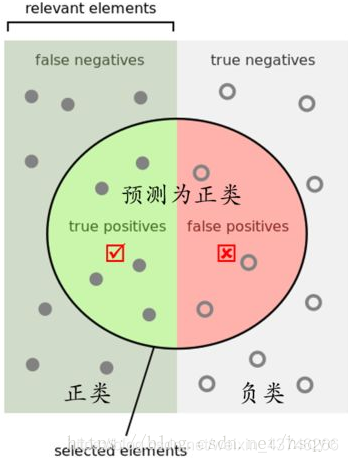
总结:猜对就是T,猜错就是F,猜是啥看PN
2. 各种率
- Accuracy:这个可以翻译成准确率,就是对于就是 ( T P + T N ) / ( P + N ) (TP+TN)/(P+N) (TP+TN)/(P+N),这个指标在样本比例差异较大时,容易失效,因为只要将全部预测成比例多的那种即可得到很高的准确率
- Precision:这个有翻译成精确率,不过我觉得翻译成查准率更合适,预测的正类中对了几个 T P / ( T P + F P ) TP/(TP+FP) TP/(TP+FP),你猜的全部正类中,查得多对
- Recall:这个有的翻译成召回率,不过有的翻译成查全率,全部正类中你猜对了几个 T P / ( T P + F N ) TP/(TP+FN) TP/(TP+FN),理解成正类中召回了多少,查得多全
- F1 SCORE:查全率和查准率的调和平均, 1 / F 1 = 1 / 2 ∗ ( 1 / P + 1 / R ) 1/F_1 = 1/2*(1/P+1/R) 1/F1=1/2∗(1/P+1/R),综合考虑两个指标,并且受小的影响比较大
2.1 根据IOU计算Precision、Recall
在利用IOU计算PR需要给定预测框的置信度阈值,然后根据IOU是否大于0.5来确定是TP还是FP【如果在一个groundtruth附近预测多个相同的框,有助于准确率!!】,
以下图为例子,绿色是预测的,蓝色为ground truth,图中的红色的数字代表置信度,
例如我们阈值取0.8,则不用考虑置信度在0.8以下的【注意区别置信度和IOU】
- 第一个预测框的置信度0.9,考虑,IOU>0.5是TP
- 第二个预测框的置信度0.8,考虑,IOU<0.5是FP
- 第三个预测框的置信度0.7,不考虑
P r e c i s i o n = T P / ( T P + F P ) = 1 / 2 Precision=TP/(TP+FP)=1/2 Precision=TP/(TP+FP)=1/2
R e c a l l = T P / ( g r o u n d t r u t h 的 数 目 ) = 1 / 3 Recall=TP/(ground truth的数目)=1/3 Recall=TP/(groundtruth的数目)=1/3

图片来源:https://blog.csdn.net/hsqyc/article/details/81702437?spm=1001.2014.3001.5502
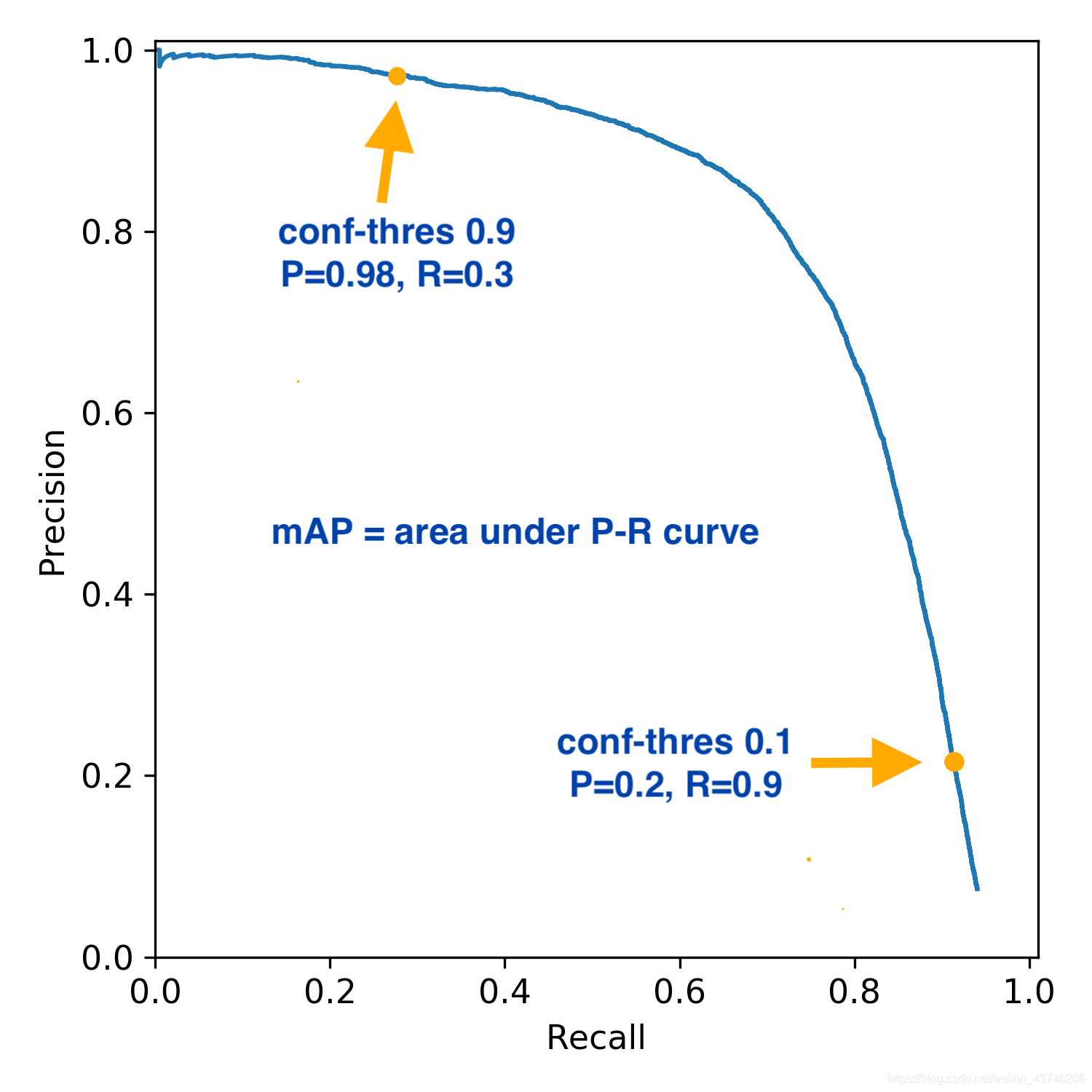
3. PR曲线
PR就是选择不同的置信度阈值,得到的不同组合的P,R,以R为横坐标,P为纵坐标绘制而成【ROC曲线还没有了解,参考的博客说PR曲线能在正负样本比例相差较大的情况下反应分类器的性能】
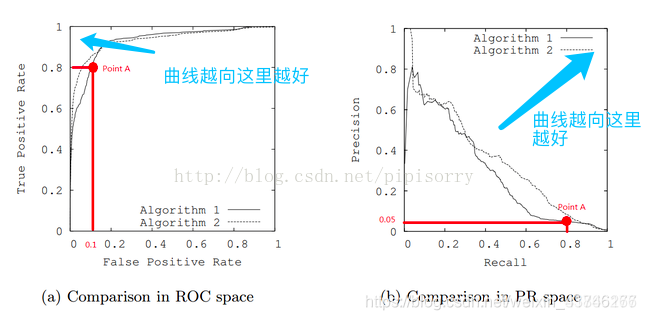
图片来源:https://blog.csdn.net/weixin_31866177/article/details/88776718
4. mAP的计算
4.1 AP的计算
AP是指PR曲线与坐标轴所夹的面积,有不同的计算方式,一般采用整数逼近的方法,划分的间隔决定了精度,连续计算相当于积分,比较难。
下面这种就是稍微粗糙点,我们可以划分得细腻一点。
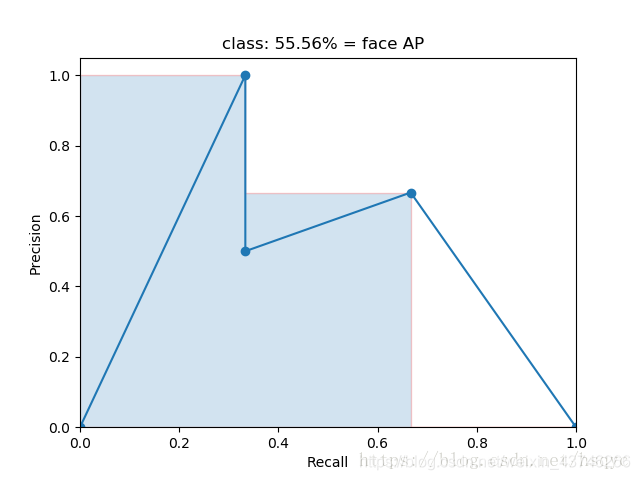
4.2 mAP
就是对不同类别的AP取平均。
4.3 mAP@0.5和mAP@0.5:0.95
- mAP@0.5就是计算IOU=0.5的PR曲线与坐标轴所包围的面积
- mAP@0.5:0.95就是在不同IoU(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP。
参考链接:
[1]:主要参考教程
[2]:mAP0.5与mAP[0.5:0.95]的区别
[3]:PRC曲线
[4]某个代码对mAP计算的讨论

















 2268
2268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









