










森林图(Forest Plot)用于可视化比较多个研究结果的效应大小和置信区间,通常用于汇总和比较不同研究的结果,特别是在荟萃分析(Meta-Analysis)中。当然,我们之前构建过的Cox比例风险回归模型也可以用森林图展示结果。森林图提供了一种方式来呈现多个研究的数据,可以帮助我们更好地理解不同研究之间的一致性和差异性,以及整体效应的大小。
我们先介绍一下森林图,大家如果不需要的话,也可以跳过这部分直接去看代码实现部分哟!
森林图是什么
提到森林图(Forest Plot),很多人的第一反应就是**荟萃分析(Meta-Analysis)分析。实际上,除了Meta分析,森林图还有很多用处,比如我们之前构建过的Cox比例风险回归模型**也可以用森林图展示结果哟!
森林图主要用于可视化比较多个研究结果的效应大小和置信区间(Confidence Interval,CI),通常用于汇总和比较不同研究的结果,它可以更直观地反映出效应量(例如RR、OR、HR或WMD等)大小及其95%CI,帮助我们更好地理解不同研究之间的一致性和差异性。我们在前面的看完还不会来揍/找我 | 基于 LASSO 回归筛选变量以构建预测模型 | 附完整代码 + 注释中的用法讲解部分有提到,很多文章都会进行单因素Cox回归 + Lasso回归 + 多因素Cox回归等步骤去筛选潜在的预测因子用于构建临床预测模型(当然还有其他各种排列组合方式),通过这些步骤我们就可以得到需要的效应量指标,之后就可以使用森林图对结果进行可视化啦!
总的来说,森林图主要用于Meta分析和临床实验。
补充小知识:RR、OR、HR、WMD
RR、OR、HR、WMD,它们都是常用于描述疾病风险、效应量或差异的统计指标:
RR(Risk Ratio): 风险比,也称为相对风险(Relative Risk),用于比较两组人群中患病或经历某一事件的风险。它是两组中患病风险的比值,通常用于疫情研究和临床试验中。
公式:RR = (A / (A + B)) / (C / (C + D))
OR(Odds Ratio): 概率比,用于描述两组中某一事件发生的几率之比。OR通常用于回顾性研究或病例对照研究,特别是在疾病罕见的情况下。
公式:OR = (A / B) / (C / D)
HR(Hazard Ratio): 风险比率,通常用于生存分析(Survival Analysis)中,用于比较不同处理组或暴露组之间的事件(如死亡)发生风险的比率。HR衡量了不同组之间事件发生的速度或危险性。
HR的值小于1表示较低的危险,大于1表示较高的危险。
WMD(Weighted Mean Difference): 加权均值差异,用于比较两组之间连续变量的差异,例如,两种治疗方法对患者血压的影响。WMD考虑了每个研究的样本大小,通过对差异进行加权来计算平均差异。
公式:WMD = Σ (weight_i * (mean_i_group1 - mean_i_group2))
这些统计指标在不同类型的研究中用于衡量效应大小或风险关系。研究设计和数据类型将决定选择哪种指标以及如何解释其结果。RR和OR通常用于疫情和病例对照研究,HR用于生存分析,而WMD用于比较连续性变量的差异。
下图就是一张普普通通平平无奇的森林图!
在生存分析的森林图中,通常使用线段来表示每个回归系数的置信区间,以及点来表示估计的风险比,而线段的长度可以表示置信区间的宽度。这有助于直观地比较不同因素对生存分析结果的影响。
咱们在后面的代码实战与结果解读部分再对森林图进行详解解读好不好!
接下来,我们进入大家最最最喜爱的部分!代码实战 + 结果解读!
输入数据类型
要绘制多因素Cox回归的森林图,通常我们需要以下数据:
- 因素名称:每个因素的名称或标签,以便在图上标识。
- 风险比(Hazard Ratio):可以选择在森林图上显示每个因素的风险比,这是回归系数(Coefficient)的指数化。风险比表示相应因素的生存风险相对于参考水平的比率。
- 置信区间(Confidence Interval):对于每个回归系数,您需要知道其95%置信区间。这可以帮助我们确定估计的可信度范围。
- P值(P-value):虽然不是必需的,但通常在森林图上显示P值也是极其有用的。P值可以告诉我们每个因素是否显著影响了生存风险。
- 还有更多!不过这几个是最主要的!我们继续往后看!
代码实战
今天用到的数据,是咱们之前在看完还不会来揍/找我 | 构建 Cox 比例风险回归模型 | 绘制森林图 (forestplot) | 附完整代码 + 注释中得到的Cox回归结果,小伙伴们一定不想再苦哈哈跑前面的流程去获得数据对不啦!所以,我已经把直接可以用来进行今日份实战的数据上传到了GitHub,大家可以在公众号后台回复森林图,即可获得存放这些数据的链接。不过我在分享过程中也会把每一步的输入数据和输出结果进行展示,大家可以作为参考并调整自己的数据格式,然后直接用自己的数据跑,也是没有任何问题的!
############################ 森林图(Forest Plot)##############################
# 加载数据,咱们用的是之前多因素cox回归的结果
# 这是用于cox回归的临床数据
tcga_gbmlgg_cli <- readRDS("~/YaoKnow/R_Plot/forest_plot/data/tcga_gbmlgg_cli.rds")
head(tcga_gbmlgg_cli)
# # A tibble: 6 × 9
# Sample Time Status Gender Age IDH_status MGMT_promoter_status Stage Group
# <chr> <dbl> <dbl> <chr> <dbl> <chr> <chr> <chr> <chr>
# 1 TCGA-02-0047-01 448 1 Male 79 Wildtype Un-methylated WHO IV GBM
# 2 TCGA-02-0055-01 76 1 Female 62 Wildtype Un-methylated WHO IV GBM
# 3 TCGA-02-2483-01 691 1 Male 44 Mutant Methylated WHO IV GBM
# 4 TCGA-02-2485-01 1561 1 Male 53 Wildtype Un-methylated WHO IV GBM
# 5 TCGA-02-2486-01 618 1 Male 64 Wildtype Un-methylated WHO IV GBM
# 6 TCGA-06-0125-01 1448 1 Female 64 Wildtype Methylated WHO IV GBM
# 这是cox回归的结果
mul_cox <- readRDS("~/YaoKnow/R_Plot/forest_plot/data/mul_cox.rds")
summary(mul_cox)
# Call:
# coxph(formula = Surv(Time, Status) ~ Age + IDH_status + MGMT_promoter_status +
# Stage, data = tcga_gbmlgg_cli)
#
# n= 626, number of events= 214
# (48 observations deleted due to missingness)
#
# coef exp(coef) se(coef) z Pr(>|z|)
# Age 0.036496 1.037170 0.006141 5.943 2.79e-09 ***
# IDH_statusWildtype 1.104013 3.016247 0.230008 4.800 1.59e-06 ***
# MGMT_promoter_statusUn-methylated 0.281274 1.324817 0.168273 1.672 0.094616 .
# StageWHO III 0.774832 2.170227 0.209268 3.703 0.000213 ***
# StageWHO IV 1.402387 4.064890 0.270050 5.193 2.07e-07 ***
# ---
# Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#
# exp(coef) exp(-coef) lower .95 upper .95
# Age 1.037 0.9642 1.0248 1.050
# IDH_statusWildtype 3.016 0.3315 1.9217 4.734
# MGMT_promoter_statusUn-methylated 1.325 0.7548 0.9526 1.842
# StageWHO III 2.170 0.4608 1.4400 3.271
# StageWHO IV 4.065 0.2460 2.3943 6.901
#
# Concordance= 0.859 (se = 0.012 )
# Likelihood ratio test= 323.1 on 5 df, p=<2e-16
# Wald test = 292.6 on 5 df, p=<2e-16
# Score (logrank) test = 440.2 on 5 df, p=<2e-16
咱们解读一下Cox回归的结果:
- 模型公式:
Surv(Time, Status) ~ Age + IDH_status + MGMT_promoter_status + Stage,表示生存时间(Time)和事件状态(Status)与多个预测变量(Age、IDH_status、MGMT_promoter_status和Stage)之间的关系。想了解Cox回归详细步骤的小伙伴们,可以查看:看完还不会来揍/找我 | 构建 Cox 比例风险回归模型 | 绘制森林图 (forestplot) | 附完整代码 + 注释。 - 样本信息:总样本数(n=626),事件发生的数量(number of events=214),以及由于缺失数据而删除的48个观测。
- 模型系数:对于每个预测变量,包括年龄(Age)、IDH状态(IDH_status)、MGMT甲基化状态(MGMT_promoter_status)和分期(Stage),给出了它们的模型系数(coef)、模型系数的指数形式(exp(coef)),以及模型系数的标准误差(se(coef))。
- z值和p值:z值用于检验模型系数是否显著,p值则表示检验的显著性水平。在这里,z值较大,p值非常小,表明这些系数在统计上是显著的。
- Signif. codes:显著性水平,***表示非常显著,**表示显著,*表示显著性水平更低,.表示不显著。
- 模型系数指数形式的解释:给出了模型系数的指数形式(exp(coef)),表示风险比(Hazard Ratio,HR)。HR用于衡量不同预测变量对生存时间的影响。指数形式大于1表示增加风险,小于1表示降低风险。
- 95%置信区间:给出了模型系数指数形式的95%置信区间的下界(lower .95)和上界(upper .95),用于表示估计的不确定性范围。
- Concordance:这是模型的一种性能指标,用于衡量模型的预测准确性。0.859的Concordance表明模型对观测数据的预测能力相对较好。
- Likelihood ratio test、Wald test和Score (logrank) test:这些是不同的检验方法,用于评估模型的拟合质量。在这里,所有的检验都表明模型相对于空模型是非常显著的,也就是说,模型中的预测变量与生存时间之间存在显著关联。
这个Cox比例风险模型结果显示了多个预测变量(年龄、IDH状态、MGMT甲基化状态和分期)对生存时间的影响以及它们的显著性。模型的Concordance表明了其预测能力较好,而且所有的检验都支持模型的显著性。
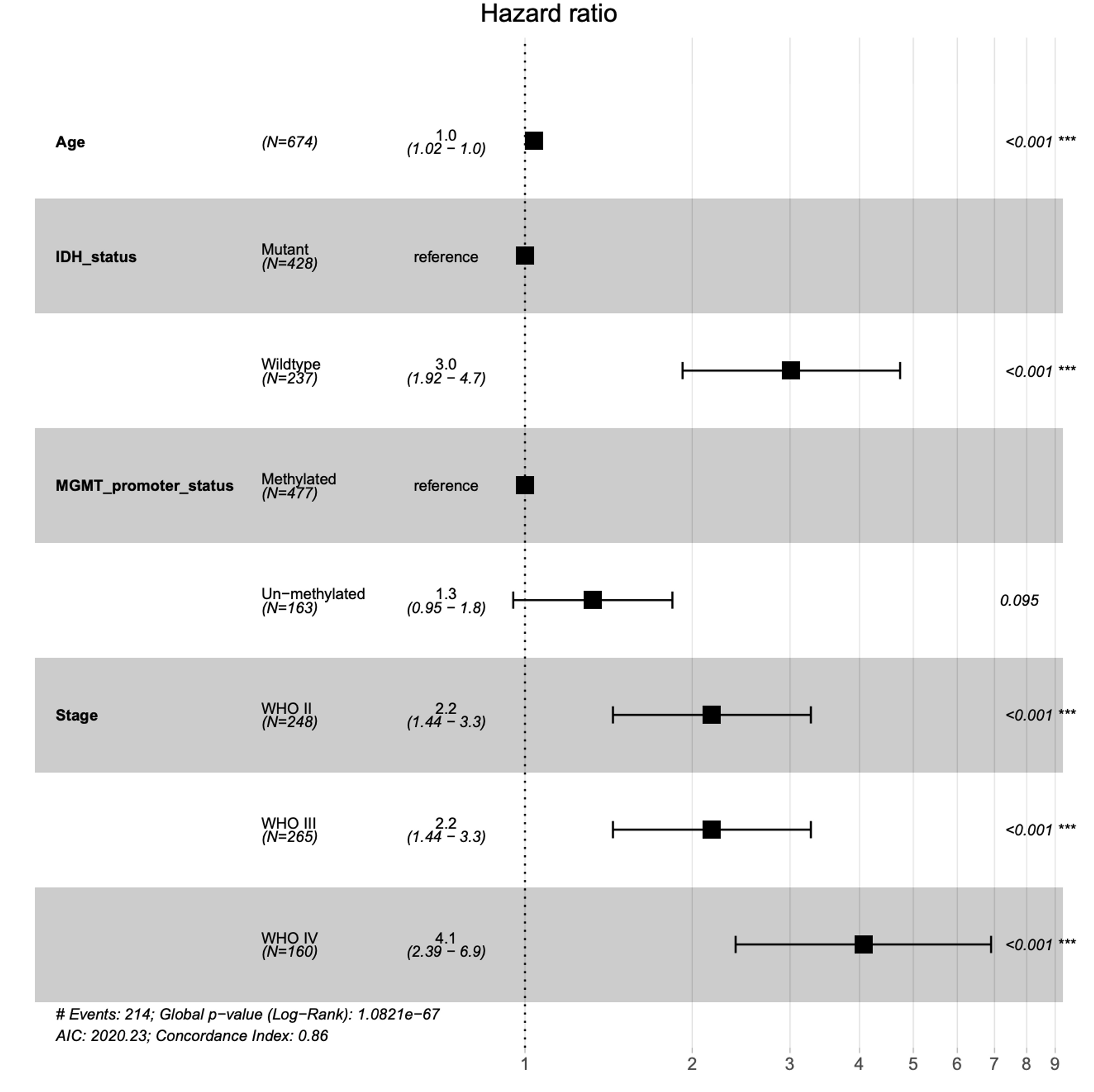
survminer包中的ggforest函数
在前面的看完还不会来揍/找我 | 构建 Cox 比例风险回归模型 | 绘制森林图 (forestplot) | 附完整代码 + 注释中,我们使用了survminer包中的ggforest函数绘制森林图,如下图所示。

这是个人认为最快捷绘制森林图的做法!它只需要输入模型拟合数据即可。不过ggforest主要用于绘制生存分析中的森林图,特别是 Cox 比例风险模型的结果,它可以直接处理 Cox 模型的结果。我们需要有一个生存分析的 Cox 模型对象,并且通常需要提供与每个因子(变量)相关的估计值、置信区间和P值等等。
当然,它还有其他参数,不过不多,我们在这里以下面这段代码为例,给大家解读一下ggforest的参数们:
ggforest(model = mul_cox, data = tcga_gbmlgg_cli,
cpositions = c(0.01, 0.1, 0.3),
refLabel = "Ref",
fontsize = 0.7,
noDigits = 2,
main = "Hazard Ratio")
model: 模型拟合数据,也就是我们前面得到的cox回归的结果。data: 包含用于模型的数据集的对象或数据框,就是临床信息,包含样本的每个因子(变量)的情况。cpositions: 指定森林图的前三列分别离最左侧有多远,0为最左侧,1为最右侧,设定负值,相当于隐藏。大家可以根据放入模型的变量的值标签的长度来自行定义。refLabel: 用于标识参照组的标签,默认为“reference”,这里我们假装设置为“Ref”,以便给大家展示这个参数作用。在Cox回归中,通常有一个作为参照组的基线组。fontsize: 用于调整森林图中字体大小的参数。这里我们把字体大小设置为0.7。noDigits: 用于控制显示在森林图中的数字的小数位数的参数。这里数字显示为2位小数。main: 这是森林图的标题,用于描述图的主题或目的,默认为"Hazard ratio",这里我给它设成了"Hazard Ratio"。
大家可以参照上面那张图,帮助理解各个参数的作用。
但是ggforest不够通用,如果我们想要绘制一般的森林图,或者想要按照自己的想法去修改森林图中要展示的内容,ggforest就不够用咯!这个时候,我们可以请出forestploter和forestplot这两个包!它们两个都提供了灵活的绘图功能,可以创建高度可自定义的森林图,帮助我们轻松地添加效应估计点、置信区间、研究名称等信息,并以可定制的方式呈现森林图。
forestplot包
包内置的数据很标准,所以示例代码就显得很容易,但由于多数情况下,大家都是想用回归分析后的结果去绘制森林图。那我们今天,就用Cox回归结果作为起始输入,从HR、95%CI、P值等的提取,到森林图的细节修改,一步一步来!
# 提取风险比、95%CI、P值等,构建森林图的基本表
# 第一种方法,在之前的cox回归介绍中,我们就是这么提取的!
x <- summary(mul_cox)
pvalue <- signif(as.matrix(x$coefficients)[ , 5], 2)
HR <- signif(as.matrix(x$coefficients)[ , 2], 2)
low <- signif(x$conf.int[ , 3], 2)
high <- signif(x$conf.int[ , 4], 2)
# 整合为数据框,部分调整是为了可视化效果,大家可以自行设定
res_mul_cox <- data.frame(p.value = pvalue, HR = HR, low = low, high = high, stringsAsFactors = F)
res_mul_cox
# p.value HR low high
# Age 2.8e-09 1.0 1.00 1.0
# IDH_statusWildtype 1.6e-06 3.0 1.90 4.7
# MGMT_promoter_statusUn-methylated 9.5e-02 1.3 0.95 1.8
# StageWHO III 2.1e-04 2.2 1.40 3.3
# StageWHO IV 2.1e-07 4.1 2.40 6.9
# 给它加一列 HR (95%CI)
res_mul_cox$`HR (95%CI)` = paste0(HR, " (", low, "-", high, ")", sep = "")
res_mul_cox
# p.value HR low high HR (95%CI)
# Age 2.8e-09 1.0 1.00 1.0 1 (1-1)
# IDH_statusWildtype 1.6e-06 3.0 1.90 4.7 3 (1.9-4.7)
# MGMT_promoter_statusUn-methylated 9.5e-02 1.3 0.95 1.8 1.3 (0.95-1.8)
# StageWHO III 2.1e-04 2.2 1.40 3.3 2.2 (1.4-3.3)
# StageWHO IV 2.1e-07 4.1 2.40 6.9 4.1 (2.4-6.9)
# 第二种方法,新学到的!
# 提取 变量+HR+95%CI+95%CI
x <- summary(mul_cox)
colnames(x$conf.int)
# [1] "exp(coef)" "exp(-coef)" "lower .95" "upper .95"
multi1 <- as.data.frame(round(x$conf.int[, c(1, 3, 4)], 2))
# 提取 HR(95%CI)和P值
# 导入tableone,这个包需要辛苦大家安装一下
library(tableone)
# 使用ShowRegTable函数生成多元Cox回归的结果表格
multi2 <- ShowRegTable(
mul_cox, # mul_cox是您的Cox回归模型对象
exp = TRUE, # exp = TRUE表示在表格中显示指数(hazard ratio)
digits = 2, # 小数点后显示的位数
pDigits = 3, # p值的小数点后显示的位数
printToggle = TRUE, # printToggle = TRUE表示打印结果表格
quote = FALSE, # quote = FALSE表示不对列名添加引号
ciFun = confint # ciFun = confint表示使用confint函数计算置信区间
)
# exp(coef) [confint] p
# Age 1.04 [1.02, 1.05] <0.001
# IDH_statusWildtype 3.02 [1.92, 4.73] <0.001
# MGMT_promoter_statusUn-methylated 1.32 [0.95, 1.84] 0.095
# StageWHO III 2.17 [1.44, 3.27] <0.001
# StageWHO IV 4.06 [2.39, 6.90] <0.001
# 将两次提取结果合并
result <- cbind(multi1, multi2)
result
# exp(coef) lower .95 upper .95 exp(coef) [confint] p
# Age 1.04 1.02 1.05 1.04 [1.02, 1.05] <0.001
# IDH_statusWildtype 3.02 1.92 4.73 3.02 [1.92, 4.73] <0.001
# MGMT_promoter_statusUn-methylated 1.32 0.95 1.84 1.32 [0.95, 1.84] 0.095
# StageWHO III 2.17 1.44 3.27 2.17 [1.44, 3.27] <0.001
# StageWHO IV 4.06 2.39 6.90 4.06 [2.39, 6.90] <0.001
# 行名转为表格第一列,并命名为"Characteristics"
result <- rownames_to_column(result, var = "Characteristics")
result
# Characteristics exp(coef) lower .95 upper .95 exp(coef) [confint] p
# 1 Age 1.04 1.02 1.05 1.04 [1.02, 1.05] <0.001
# 2 IDH_statusWildtype 3.02 1.92 4.73 3.02 [1.92, 4.73] <0.001
# 3 MGMT_promoter_statusUn-methylated 1.32 0.95 1.84 1.32 [0.95, 1.84] 0.095
# 4 StageWHO III 2.17 1.44 3.27 2.17 [1.44, 3.27] <0.001
# 5 StageWHO IV 4.06 2.39 6.90 4.06 [2.39, 6.90] <0.001
# 都可以都可以!第二种是我新学到的!想多试试!
# 所以后面的分析我就用第二种提取方法得到的结果啦!
现在我们已经构建好了绘制森林图的基本表,接下来,先来一个简单的基本森林图热热身!
################################ forestplot 包 #################################
library(forestplot)
# 简单的基本森林图
fig <- forestplot(
result[, c(1, 5, 6)], # 选择要在森林图中显示的数据列,第1、5、6列
mean = result[, 2], # 指定均值数据列(HR),它将显示为森林图的小方块
lower = result[, 3], # 指定95%置信区间的下限数据列
upper = result[, 4], # 指定95%置信区间的上限数据列,这些数据将显示为线段穿过方块
zero = 1, # 设置零线或参考线为HR=1,这是x轴的垂直线
boxsize = 0.1, # 设置小方块的大小
graph.pos = 2 # 指定森林图应该插入到图形中的位置,这里是第2列
)
fig
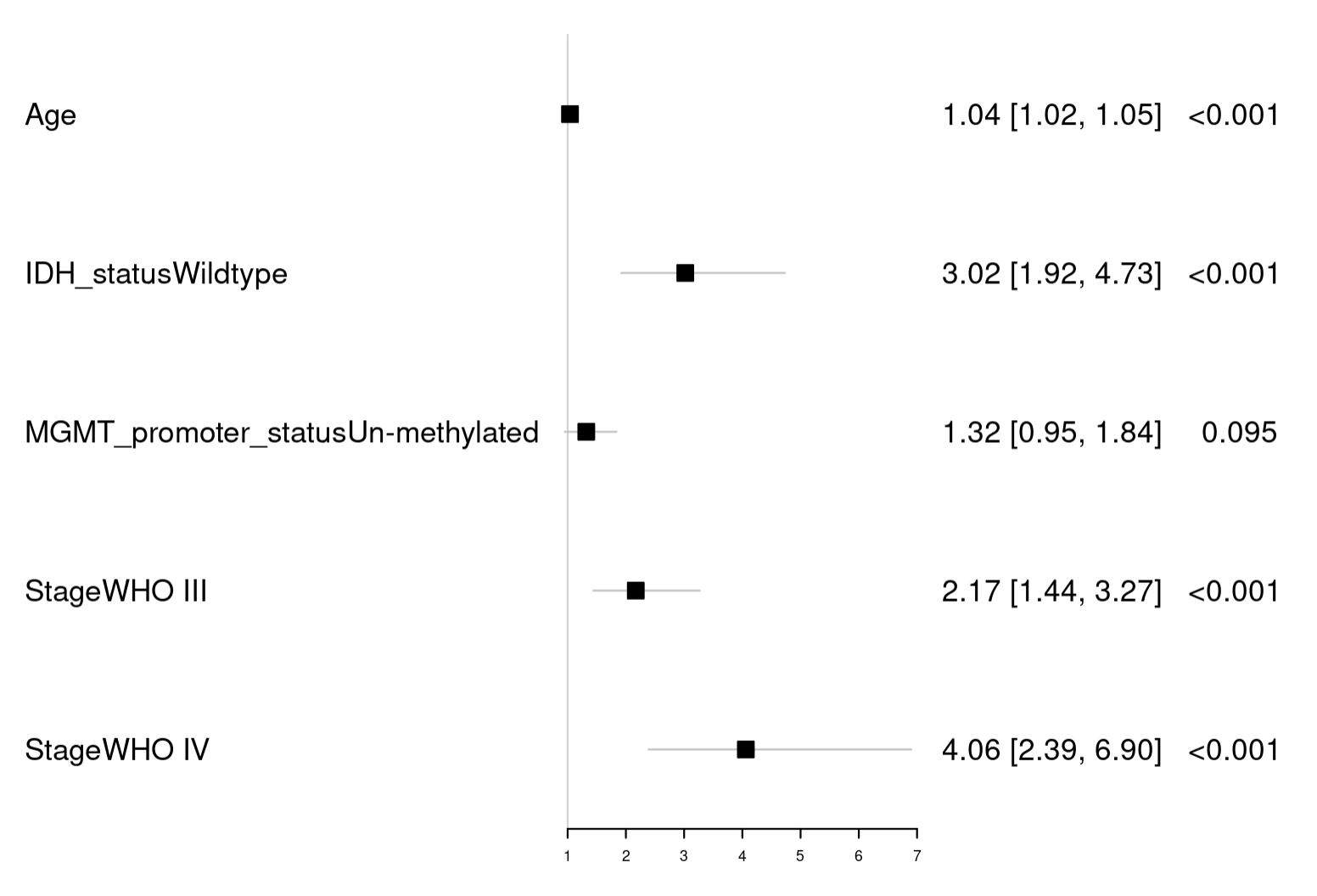
我们可以看到,一个森林图的雏形就出来啦!不过看起来是不是有点单调呐!咱们给它修饰一下!
# 开始修饰!
# 展示所有变量
# 首先我们可以看到分类变量的名称的显示有点问题,都是变量名+类别名
# 我们给它调整一下,比如 IDH_StatusWildtype 改为 Wildtype
result$Characteristics <- str_remove(result$Characteristics, "IDH_status|MGMT_promoter_status|Stage")
result$Characteristics
# [1] "Age" "Wildtype" "Un-methylated" "WHO III" "WHO IV"
#
# # 定义 ins 函数,接受一个向量 x 和插入行数 n,主要是为了插入空行
# ins <- function(x, n) {
# c(x, rep(NA, n))
# }
# 将第5和第6列转换为字符型
result[, 5:6] <- lapply(result[, 5:6], as.character)
# 创建新的 result,插入空行,为了使画出来的森林图更好看!
result <- rbind(
c("Characteristics", NA, NA, NA, "HR (95%CI)", "p"),
result[1, ],
c("IDH_status", NA, NA, NA, NA, NA),
c("Mutant", NA, NA, NA, NA, NA),
result[2, ],
c("MGMT_promoter_status", NA, NA, NA, NA, NA),
c("Methylated", NA, NA, NA, NA, NA),
result[3, ],
c("Stage", NA, NA, NA, NA, NA),
c("WHO II", NA, NA, NA, NA, NA),
result[4:5, ],
rep(NA, ncol(result)) # 插入全为 NA 的行
)
# 将第2,3,4列转换为数值型,注意一定要有这个步骤噢
# 因为我们要确保参与运算的变量都是数值型,否则绘图就可能失败
result[, 2:4] <- lapply(result[, 2:4], as.numeric)
# 我们来看看新表长啥样
result
# Characteristics exp(coef) lower .95 upper .95 exp(coef) [confint] p
# 1 Characteristics NA NA NA HR (95%CI) p
# 2 Age 1.04 1.02 1.05 1.04 [1.02, 1.05] <0.001
# 3 IDH_status NA NA NA <NA> <NA>
# 4 Mutant NA NA NA <NA> <NA>
# 21 Wildtype 3.02 1.92 4.73 3.02 [1.92, 4.73] <0.001
# 6 MGMT_promoter_status NA NA NA <NA> <NA>
# 7 Methylated NA NA NA <NA> <NA>
# 31 Un-methylated 1.32 0.95 1.84 1.32 [0.95, 1.84] 0.095
# 9 Stage NA NA NA <NA> <NA>
# 10 WHO II NA NA NA <NA> <NA>
# 41 WHO III 2.17 1.44 3.27 2.17 [1.44, 3.27] <0.001
# 5 WHO IV 4.06 2.39 6.90 4.06 [2.39, 6.90] <0.001
# 13 <NA> NA NA NA <NA> <NA>
# 咱们用这个新表画个森林图试试
fig <- forestplot(
result[, c(1, 5, 6)], # 选择要在森林图中显示的数据列,第1、5、6列
mean = result[, 2], # 指定均值数据列(HR),它将显示为森林图的小方块
lower = result[, 3], # 指定95%置信区间的下限数据列
upper = result[, 4], # 指定95%置信区间的上限数据列,这些数据将显示为线段穿过方块
zero = 1, # 设置零线或参考线为HR=1,这是x轴的垂直线
boxsize = 0.1, # 设置小方块的大小
graph.pos = 2 # 指定森林图应该插入到图形中的位置,这里是第2列
)
fig
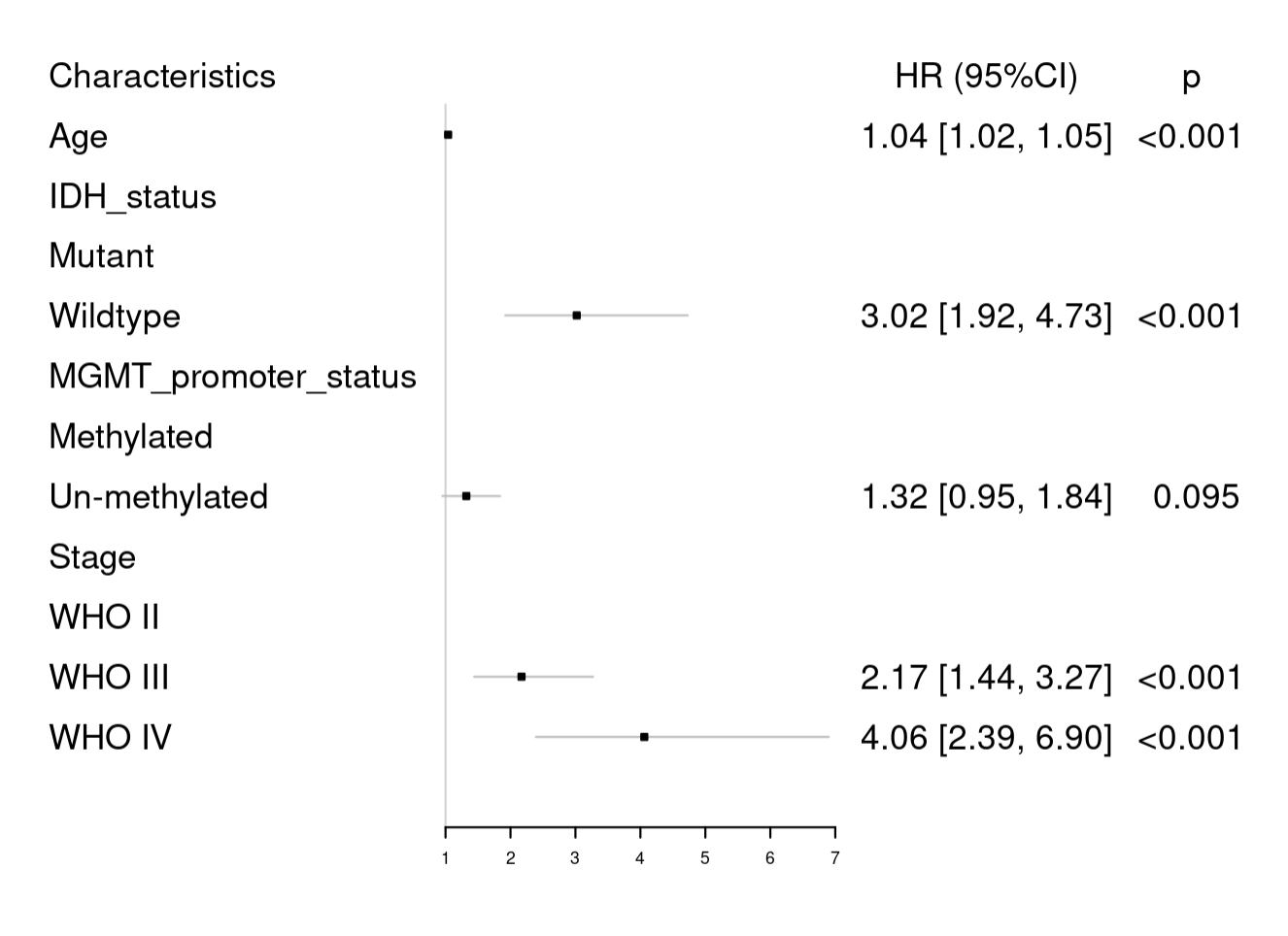
这张图图是不是比之前那个详细一丢丢,它把所有变量(包括分类变量的类别名)都展示出来啦!
我们还可以展示每个组的患者数量。
# 展示每个变量类别的患者数量
# 还是需要这个包帮助我们
library(tableone)
# 这是所有变量,按自己的数据修改
myVars <- c("Age","IDH_status","MGMT_promoter_status","Stage")
# 这是所有分类变量,按自己的数据修改
catVars <- c("IDH_status","MGMT_promoter_status","Stage")
# 创建汇总统计表
table1 <- print(CreateTableOne(
vars = myVars,
data = tcga_gbmlgg_cli,
factorVars = catVars),
showAllLevels = TRUE) # 此处设置showAllLevels参数以显示所有级别
# Registered S3 methods overwritten by 'proxy':
# method from
# print.registry_field registry
# print.registry_entry registry
#
# level Overall
# n 674
# Age (mean (SD)) 47.06 (15.24)
# IDH_status (%) Mutant 428 (64.4)
# Wildtype 237 (35.6)
# MGMT_promoter_status (%) Methylated 477 (74.5)
# Un-methylated 163 (25.5)
# Stage (%) WHO II 248 (36.8)
# WHO III 265 (39.4)
# WHO IV 160 (23.8)
# level: 这一列显示了不同的数据变量或特征。
# Overall: 这一列显示了与每个变量或特征相关的总体统计信息,
# 包括样本数目、均值(mean)和标准差(SD)。
这是关于数据的汇总统计信息,描述了样本特征和变量的分布情况。我们解读一下:
- level: 这一列显示了不同的数据变量或特征。
- Overall: 这一列显示了与每个变量或特征相关的总体统计信息,包括样本数目、均值(mean)和标准差(SD)。具体来说:
- n: 这是样本的总数,也就是在分析中考虑的总样本数量。
- Age (mean (SD)): 这是一个关于年龄的变量的描述,均值为 47.06,标准差为 15.24。这意味着在分析中涉及的样本的平均年龄约为 47.06 岁,标准差表示年龄的分散度。
- IDH_status (%): 这个变量描述了 IDH 突变状态,分为 “Mutant”(突变)和 “Wildtype”(野生型)。在分析中,突变型占总体的 64.4%,而野生型占 35.6%。
- MGMT_promoter_status (%): 这个变量描述了 MGMT 甲基化状态,分为 “Methylated”(甲基化)和 “Un-methylated”(非甲基化)。在分析中,甲基化占总体的 74.5%,而非甲基化占 25.5%。
- Stage (%): 这个变量描述了肿瘤分期情况,分为 WHO II、WHO III 和 WHO IV。在分析中,WHO II 占总体的 36.8%,WHO III 占 39.4%,而 WHO IV 占 23.8%。
# 基线表table1里插入空行,使它的行数和变量与result一致
N <- rbind(c(NA,NA),
table1[2, ],
c(NA, NA),
table1[3:4,],
c(NA,NA),
table1[5:6,],
c(NA,NA),
table1[7:9,],
c(NA, NA))
N <- N[,-1]
# 现在N里面存储的就是患者数量信息
N <- data.frame(N)
head(N)
N
# 1 <NA>
# 2 47.06 (15.24)
# 3 <NA>
# 4 428 (64.4)
# 5 237 (35.6)
# 6 <NA>
# 合并result和N
result1 <- cbind(result, N)
# 调整一下顺序,把患者数量调至第二列,为了森林图图好看
result1 <- result1[ , c(1, 7, 2:6)]
# 给第一行重命名,这行是要显示在未来的森林图中的哟!
result1[1, ] <- c("Characteristics", "Number (%)", NA, NA, NA, "HR (95%CI)", "P.value")
# 查看我们最终得到的result1
result1
# Characteristics N exp(coef) lower .95 upper .95 exp(coef) [confint] p
# 1 Characteristics Number (%) <NA> <NA> <NA> HR (95%CI) P.value
# 2 Age 47.06 (15.24) 1.04 1.02 1.05 1.04 [1.02, 1.05] <0.001
# 3 IDH_status <NA> <NA> <NA> <NA> <NA> <NA>
# 4 Mutant 428 (64.4) <NA> <NA> <NA> <NA> <NA>
# 21 Wildtype 237 (35.6) 3.02 1.92 4.73 3.02 [1.92, 4.73] <0.001
# 6 MGMT_promoter_status <NA> <NA> <NA> <NA> <NA> <NA>
# 7 Methylated 477 (74.5) <NA> <NA> <NA> <NA> <NA>
# 31 Un-methylated 163 (25.5) 1.32 0.95 1.84 1.32 [0.95, 1.84] 0.095
# 9 Stage <NA> <NA> <NA> <NA> <NA> <NA>
# 10 WHO II 248 (36.8) <NA> <NA> <NA> <NA> <NA>
# 41 WHO III 265 (39.4) 2.17 1.44 3.27 2.17 [1.44, 3.27] <0.001
# 5 WHO IV 160 (23.8) 4.06 2.39 6.9 4.06 [2.39, 6.90] <0.001
# 13 <NA> <NA> <NA> <NA> <NA> <NA> <NA>
# 将第3,4,5列转换为数值型,注意一定要有这个步骤噢
# 因为我们要确保参与运算的变量都是数值型,否则绘图就可能失败
result1[, 3:5] <- lapply(result1[, 3:5], as.numeric)
# 咱们画一下森林图,看看有什么变化,注意这里,result1表中列数有变化,所以要记得小小修改一下绘图代码
fig <- forestplot(
result1[, c(1, 2, 6, 7)], # 这里要改哟!选择要在森林图中显示的数据列,第1、5、6列
mean = result1[, 3], # 这里要改哟!指定均值数据列(HR),它将显示为森林图的小方块
lower = result1[, 4], # 这里要改哟!指定95%置信区间的下限数据列
upper = result1[, 5], # 这里要改哟!指定95%置信区间的上限数据列,这些数据将显示为线段穿过方块
zero = 1, # 设置零线或参考线为HR=1,这是x轴的垂直线
boxsize = 0.1, # 设置小方块的大小
graph.pos = 3 # 这里要改哟!指定森林图应该插入到图形中的位置,这里是第2列
)
fig

看起来还是没那么炫酷!咱们再更细节地优化一波!顺便给大家介绍几种参数的使用!
# 更细节地优化一波
# 创建森林图 (forest plot) 并存储在 fig3_1 变量中
fig <- forestplot(
result1[, c(1, 2, 6, 7)], # 需要显示在森林图中的列
mean = result1[, 3], # 均值列(HR),它将显示为森林图的小方块或其他形状哈哈哈哈哈
lower = result1[, 4], # 95%置信区间的下限数据列
upper = result1[, 5], # 95%置信区间的上限数据列
zero = 1, # 均值为1时的参考线,也就是零线
boxsize = 0.3, # 方框的大小
graph.pos = "right", # 森林图在右侧显示
hrzl_lines = list( # 水平线样式的设置
"1" = gpar(lty = 1, lwd = 2), # 均值线
"2" = gpar(lty = 2), # 下限和上限之间的虚线
"14" = gpar(lwd = 2, lty = 1, columns = c(1:4)) # 下限和上限线
),
graphwidth = unit(.25, "npc"), # 森林图的宽度
xlab = "\n 插播一条广告!\n 要知道出品,必属精品!", # x轴标签
xticks = c(-0.5, 1, 3, 5, 7, 9), # x轴刻度
# 判断是否为汇总行,汇总行就是连续变量或者分类变量名所在的行,可以加粗让它显眼一点,好看的!
is.summary = c(T, F, T, F, F, T, F, F, T, F, F, F),
txt_gp = fpTxtGp( # 文本样式的设置
label = gpar(cex = 0.8), # 标签的大小
ticks = gpar(cex = 1), # 刻度标记的大小
xlab = gpar(cex = 0.9), # x轴标签的大小
title = gpar(cex = 1.2) # 标题的大小
),
lwd.zero = 1, # 均值线的宽度
lwd.ci = 1.5, # 置信区间线的宽度
lwd.xaxis = 2, # x轴线的宽度
lty.ci = 1.5, # 置信区间线的样式
ci.vertices = T, # 是否显示置信区间的顶点
ci.vertices.height = 0.2, # 置信区间顶点的高度
clip = c(0.1, 8), # x轴的截断范围
ineheight = unit(8, 'mm'), # 森林图内线的高度
line.margin = unit(8, 'mm'), # 森林图线的边距
colgap = unit(6, 'mm'), # 森林图中方框的间距
fn.ci_norm = "fpDrawDiamondCI", # 置信区间的形状(这里是钻石形)
title = "多因素Cox回归森林图", # 森林图的标题
col = fpColors( # 颜色设置
box = "blue4", # 方框颜色
lines = "blue4", # 线条颜色
zero = "black" # 均值为0时的颜色
)
)
fig

完美!咱们再来看看另一个包的用法!
forestploter包
forestploter包和forestplot包一样,提供了灵活的绘图功能,可以创建高度可自定义的森林图,帮助我们轻松地添加效应估计点、置信区间、研究名称等信息,并以可定制的方式呈现森林图(以防遗忘,反复提及)。
############################### forestploter 包 ################################
library(forestploter)
# 那,我们还是用前面的数据好不好
result2 <- result1
result2
# Characteristics N exp(coef) lower .95 upper .95 exp(coef) [confint] p
# 1 Characteristics Number (%) <NA> <NA> <NA> HR (95%CI) P.value
# 2 Age 47.06 (15.24) 1.04 1.02 1.05 1.04 [1.02, 1.05] <0.001
# 3 IDH_status <NA> <NA> <NA> <NA> <NA> <NA>
# 4 Mutant 428 (64.4) <NA> <NA> <NA> <NA> <NA>
# 21 Wildtype 237 (35.6) 3.02 1.92 4.73 3.02 [1.92, 4.73] <0.001
# 6 MGMT_promoter_status <NA> <NA> <NA> <NA> <NA> <NA>
# 7 Methylated 477 (74.5) <NA> <NA> <NA> <NA> <NA>
# 31 Un-methylated 163 (25.5) 1.32 0.95 1.84 1.32 [0.95, 1.84] 0.095
# 9 Stage <NA> <NA> <NA> <NA> <NA> <NA>
# 10 WHO II 248 (36.8) <NA> <NA> <NA> <NA> <NA>
# 41 WHO III 265 (39.4) 2.17 1.44 3.27 2.17 [1.44, 3.27] <0.001
# 5 WHO IV 160 (23.8) 4.06 2.39 6.9 4.06 [2.39, 6.90] <0.001
# 13 <NA> <NA> <NA> <NA> <NA> <NA> <NA>
# 就它了!不过我们需要调整一下格式,毕竟这个包那个包,包包不一样!
# 先改一下列名
colnames(result2) <- result2[1, ]
result2 <- result2[-1, ]
# 把分类变量的类别缩进一下,更好看!
# 咱们前面其实也可以这么做!不过我到这里才想起来嘿嘿嘿,不过咱前面加粗了,大差不差的效果!
result2$Characteristics <- ifelse(is.na(result2$`Number (%)`),
result2$Characteristics,
paste0(" ", result2$Characteristics))
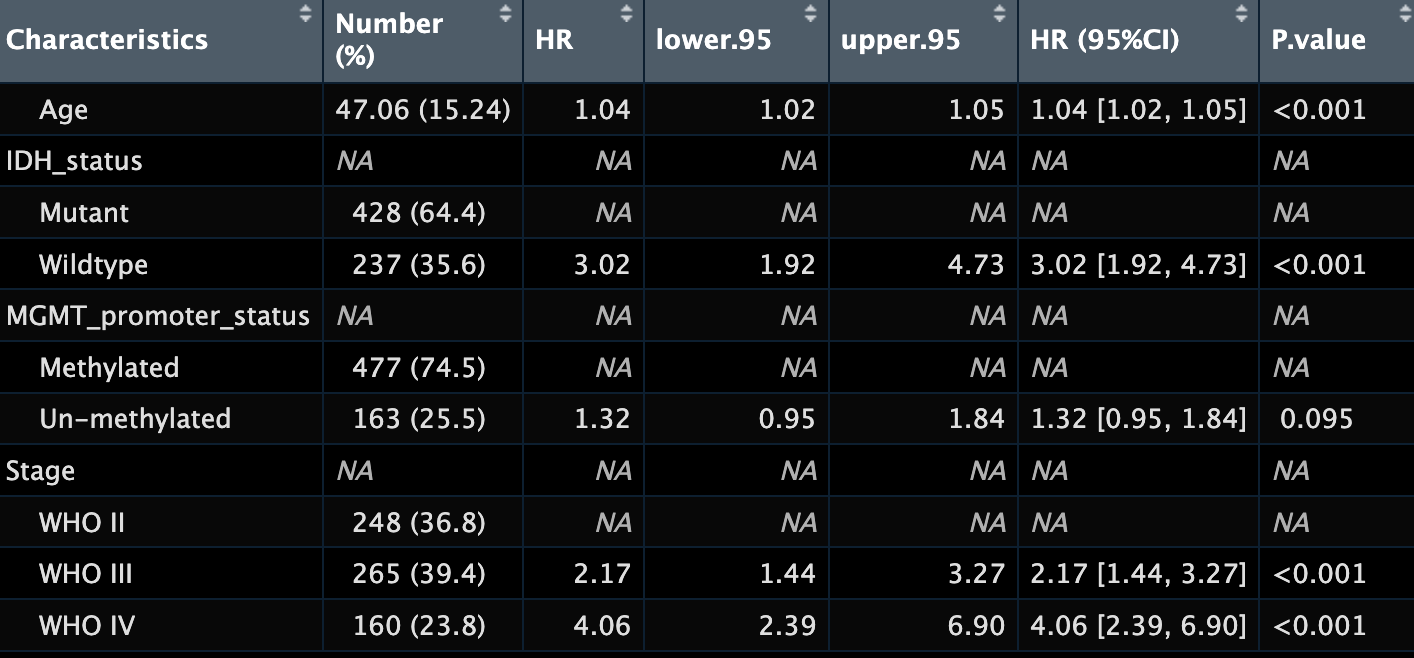
是不是好看很多!已经想象到最终的图图有多优雅了!
# 把NA替换为空字符串
result2$`Number (%)` <- ifelse(is.na(result2$`Number (%)`), "", result2$`Number (%)`)
# 计算标准误差(SE),它在绘图的时候会表示正方形的大小
result2$se <- (log(result2$upper.95) - log(result2$HR))/1.96
# 为森林图添加空白列,为了产生一个绘图区间,用于显示CI
result2$` ` <- paste(rep(" ", 12), collapse = " ")
# 准备完毕!开始画图!

现在的表变成了这个样子!大家可以看到,最后多了一个空的列。准备完毕!开始画图!
# 定义一个简单的主题,大家可以随意发挥自己的审美!
tm <- forest_theme(base_size = 10, # 设置基础字体大小
refline_col = "red4", # 设置参考线颜色为红色
arrow_type = "closed", # 设置箭头类型为闭合箭头
footnote_col = "blue4") # 设置脚注文字颜色为蓝色
# 绘制森林图
p <- forest(result2[,c(1, 2, 9, 6)], # 选择要在森林图中使用的数据列,这里包括变量名列、患者数量列、绘图要用的空白列和HR(95%CI)列
est = result2$HR, # 效应值,也就是HR列
lower = result2$lower.95, # 置信区间下限
upper = result2$upper.95, # 置信区间上限
sizes = result2$se, # 黑框框的大小
ci_column = 3, # 在第3列(可信区间列)绘制森林图
ref_line = 1, # 添加参考线
arrow_lab = c("Low risk", "High Risk"), # 箭头标签,用来表示效应方向,如何设置取决于你的样本情况
xlim = c(-1, 10), # 设置x轴范围
ticks_at = c(-0.5, 1, 3, 5, 7), # 在指定位置添加刻度
theme = tm, # 添加自定义主题
footnote = "This is the demo data. Please feel free to change\nanything you want.") # 添加脚注信息
p
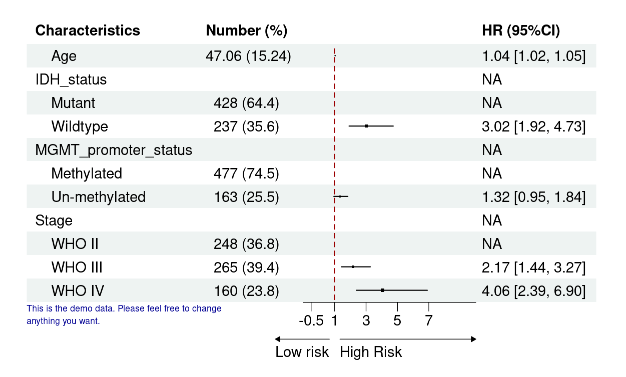
漂亮!大家可以看到有些值NA,不用担心!那是因为我从Cox提取出来的数据问题,如果你们的数据类似于包内自带的数据样式,就不会出现这种情况啦!给大家展示一下它自带数据的样式!
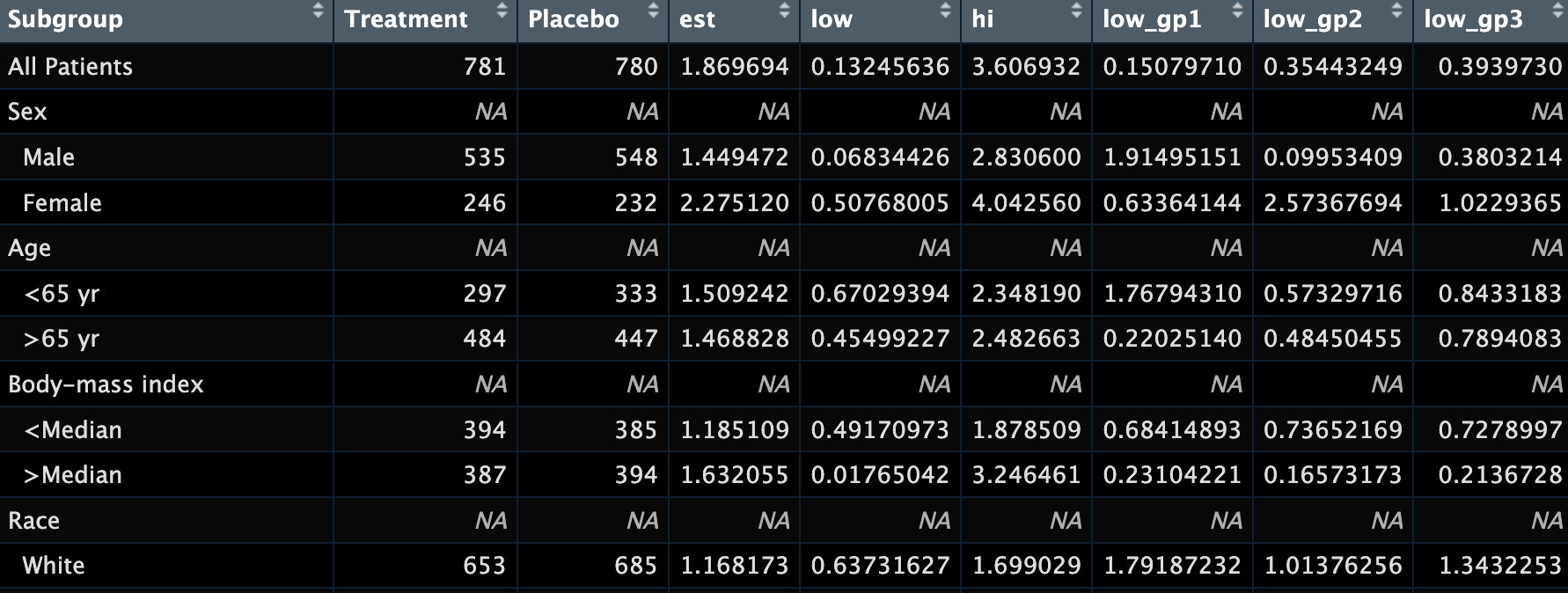
就像这样,它甚至可以画出多组森林图!后面给大家展示一下!
咦,咱们的森林图怎么没有P值?咱给它加上!
# 加列P值
p <- forest(result2[,c(1, 2, 9, 6, 7)], # 加了P值列哟!选择要在森林图中使用的数据列,这里包括变量名列、患者数量列、绘图要用的空白列和HR(95%CI)列
est = result2$HR, # 效应值,也就是HR列
lower = result2$lower.95, # 置信区间下限
upper = result2$upper.95, # 置信区间上限
sizes = result2$se, # 黑框框的大小
ci_column = 3, # 在第3列(可信区间列)绘制森林图
ref_line = 1, # 添加参考线
arrow_lab = c("Low risk", "High Risk"), # 箭头标签,用来表示效应方向,如何设置取决于你的样本情况
xlim = c(-1, 10), # 设置x轴范围
ticks_at = c(-0.5, 1, 3, 5, 7), # 在指定位置添加刻度
theme = tm, # 添加自定义主题
footnote = "This is the demo data. Please feel free to change\nanything you want.") # 添加脚注信息
p

我们可以使用forest_theme函数可以对森林图细节进行调整,下面主要给大家介绍一个各参数的用法。
# forest_theme函数可以对森林图细节进行调整
tm <- forest_theme(
base_size = 10, # 设置文本的基础大小
# 设置可信区间的外观
ci_pch = 15, # 可信区间点的形状
ci_col = "blue4", # 可信区间的边框颜色
ci_fill = "blue4", # 可信区间的填充颜色
ci_alpha = 0.8, # 可信区间的透明度
ci_lty = 1, # 可信区间的线型
ci_lwd = 1.5, # 可信区间的线宽
ci_Theight = 0.2, # 设置T字在可信区间末端的高度,默认是NULL
# 设置参考线的外观
refline_lwd = 1, # 参考线的线宽
refline_lty = "dashed", # 参考线的线型
refline_col = "grey20", # 参考线的颜色
# 设置垂直线的外观
vertline_lwd = 1, # 垂直线的线宽,可以添加一条额外的垂直线,如果没有就不显示
vertline_lty = "dashed", # 垂直线的线型
vertline_col = "grey20", # 垂直线的颜色
# 设置脚注的字体大小、字体样式和颜色
footnote_cex = 0.6, # 脚注字体大小
footnote_fontface = "italic", # 脚注字体样式
footnote_col = "red4" # 脚注文本的颜色
)
p <- forest(result2[,c(1, 2, 9, 6, 7)], # 选择要在森林图中使用的数据列,这里包括变量名列、患者数量列、绘图要用的空白列和HR(95%CI)列
est = result2$HR, # 效应值,也就是HR列
lower = result2$lower.95, # 置信区间下限
upper = result2$upper.95, # 置信区间上限
sizes = result2$se, # 黑框框的大小
ci_column = 3, # 在第3列(可信区间列)绘制森林图
ref_line = 1, # 添加参考线
arrow_lab = c("Low risk", "High Risk"), # 箭头标签,用来表示效应方向,如何设置取决于你的样本情况
xlim = c(-1, 10), # 设置x轴范围
ticks_at = c(-0.5, 1, 3, 5, 7), # 在指定位置添加刻度
theme = tm, # 添加自定义主题
footnote = "This is the demo data. Please feel free to change\nanything you want.") # 添加脚注信息
p

我们还可以对图片细节进行修改,比如我们想把第十行变成红色。
# 把第十行变成红色
pp <- edit_plot(p, row = 10, gp = gpar(col = "red4", fontface = "italic"))
pp
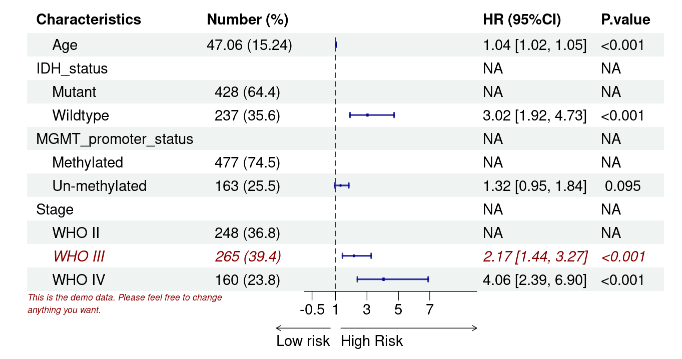
把第四和七行小方块及长条的颜色变为绿色。
# 把第四和七行小方块及长条的颜色变为绿色
pp <- edit_plot(pp,
row = c(4, 7),
col = 3,
which = "ci",
gp = gpar(col = "green4"))
pp

把第三行的文本变成粗体。
# 把第三行的文本变成粗体
pp <- edit_plot(pp,
row = 3,
gp = gpar(fontface = "bold"))
pp
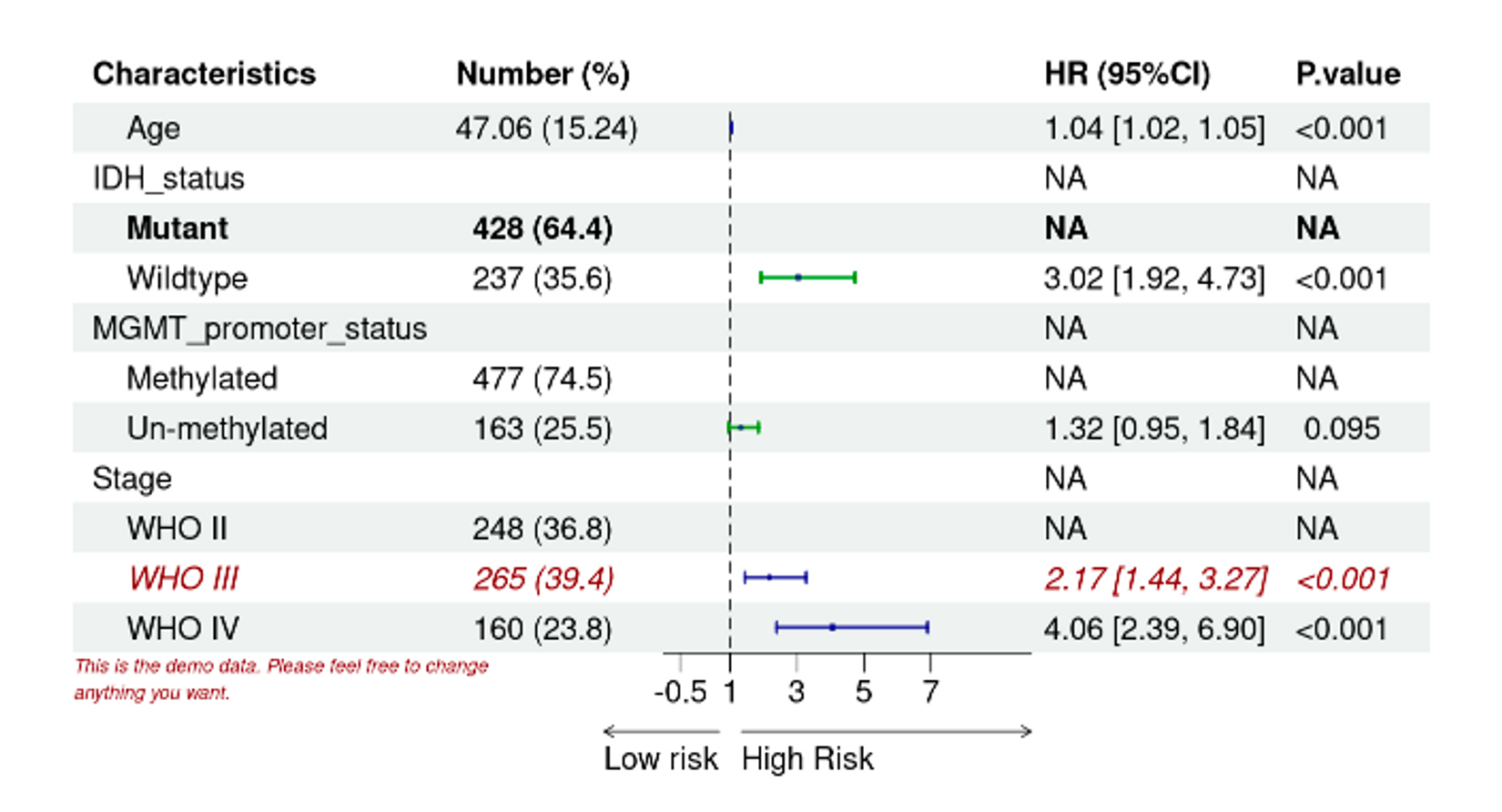
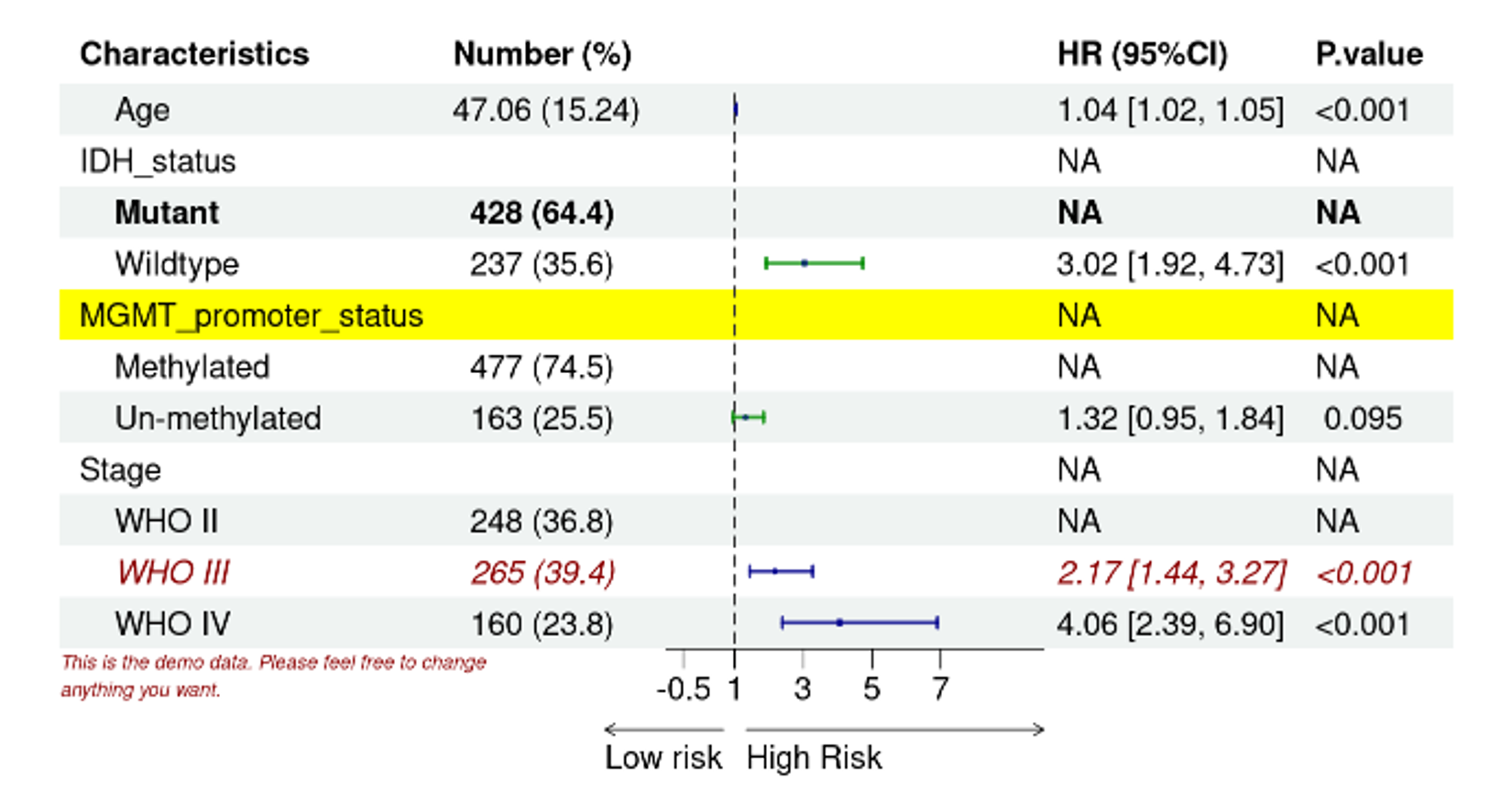
把第五行的背景改黄色。
# 把第五行的背景改黄色
pp <- edit_plot(pp, row = 5, which = "background",
gp = gpar(fill = "yellow"))
pp
在顶部插入文本。
# 在顶部插入文本
pp <- insert_text(pp,
text = "插入内容",
col = 1:2,
part = "header",
gp = gpar(fontface = "bold"))
pp

在标题下方加黑线,当然上下左右都可以。
# 在标题下方加黑线,当然上下左右都可以
pp <- add_border(pp, part = "header", where = "bottom")
pp

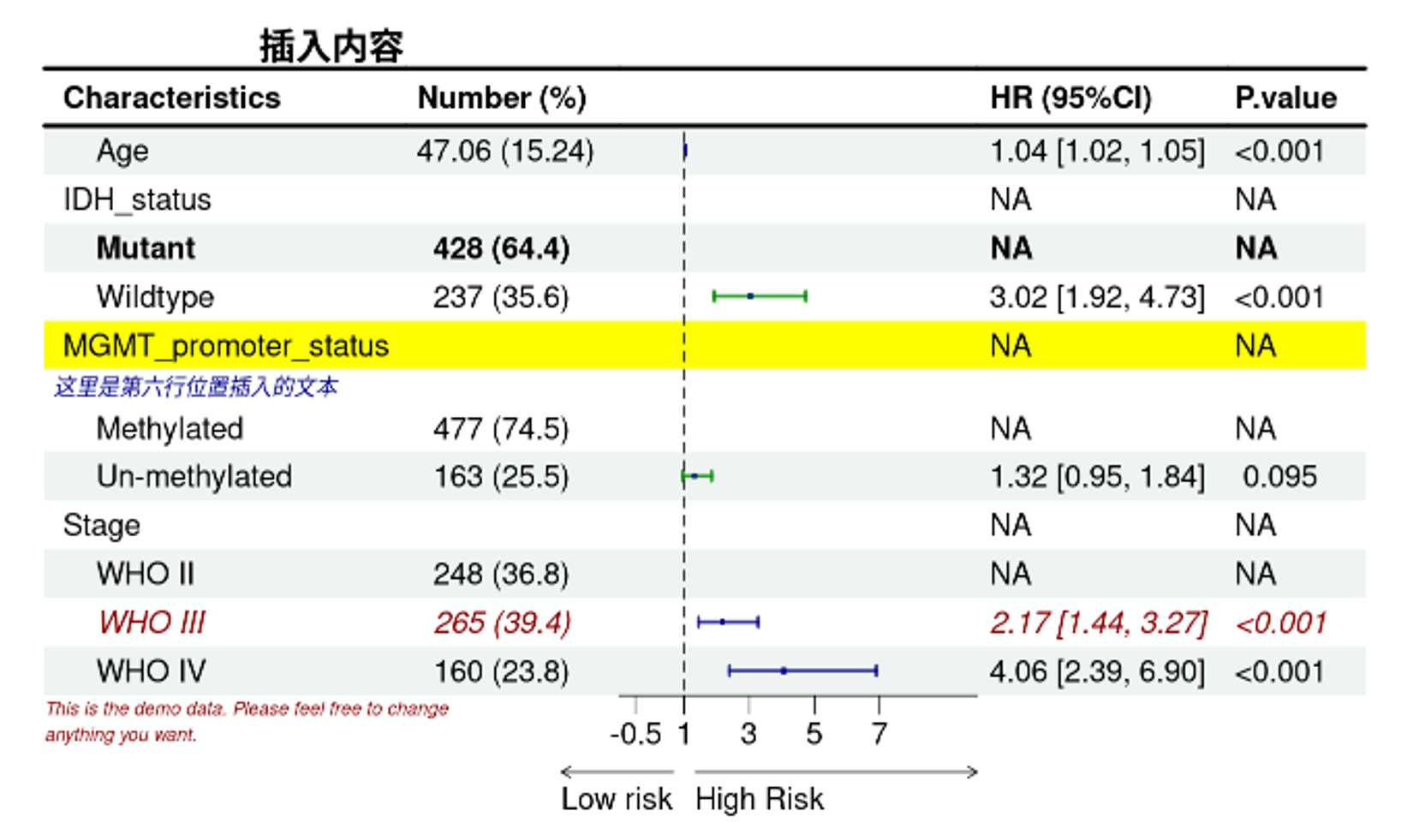
在第六行位置插入文本。
# 在第六行位置插入文本
pp <- insert_text(pp,
text = "这里是第六行位置插入的文本",
row = 6,
just = "left",
gp = gpar(cex = 0.6, col = "blue4", fontface = "italic"))
pp
多组森林图
接下来,我们来介绍一下多组森林图的绘制,因为是多组森林图,我自己的数据就不合适啦,所以我们这里使用forestploter包自带的数据,咱们开始吧!
# 多组森林图绘制
# 简单绘制
# 导入包自带的数据
dt <- read.csv(system.file("extdata", "example_data.csv", package = "forestploter"))
head(dt)[1:8, 1:10]
# Subgroup Treatment Placebo est low hi low_gp1 low_gp2 low_gp3 low_gp4
# 1 All Patients 781 780 1.869694 0.13245636 3.606932 0.1507971 0.35443249 0.3939730 1.1515801
# 2 Sex NA NA NA NA NA NA NA NA NA
# 3 Male 535 548 1.449472 0.06834426 2.830600 1.9149515 0.09953409 0.3803214 0.3213258
# 4 Female 246 232 2.275120 0.50768005 4.042560 0.6336414 2.57367694 1.0229365 0.3510777
# 5 Age NA NA NA NA NA NA NA NA NA
# 6 <65 yr 297 333 1.509242 0.67029394 2.348190 1.7679431 0.57329716 0.8433183 2.1637576
# NA <NA> NA NA NA NA NA NA NA NA NA
# NA.1 <NA> NA NA NA NA NA NA NA NA NA
# 可以看到,它有多个不同的置信区间数据
# 下面的数据处理方式和前面的几乎一样
# 如果Placebo列中不是NA,缩进子组
dt$Subgroup <- ifelse(is.na(dt$Placebo),
dt$Subgroup,
paste0(" ", dt$Subgroup))
# 将NA值转换为空字符串或对应的字符
dt$n1 <- ifelse(is.na(dt$Treatment), "", dt$Treatment)
dt$n2 <- ifelse(is.na(dt$Placebo), "", dt$Placebo)
# 为CI添加两个空白列
dt$`这个结果` <- paste(rep(" ", 20), collapse = " ")
dt$`那个结果` <- paste(rep(" ", 20), collapse = " ")
# 设置森林图主题
tm <- forest_theme(
base_size = 10, # 设置基础文本大小
refline_lty = "solid", # 参考线的线型
ci_pch = c(15, 18), # 可信区间点的形状
ci_col = c("blue4", "green4"), # 可信区间的颜色
footnote_col = "blue4", # 脚注文本颜色
legend_name = "Group", # 图例标题
legend_value = c("Trt 1", "Trt 2"), # 图例值
vertline_lty = c("dashed", "dotted"), # 垂直线的线型
vertline_col = c("red4", "purple4") # 垂直线的颜色
)
# 绘制森林图
p <- forest(
dt[,c(1, 19, 21, 20, 22)], # 选择要在森林图中使用的数据列
est = list(
dt$est_gp1,
dt$est_gp2,
dt$est_gp3,
dt$est_gp4),
lower = list(
dt$low_gp1,
dt$low_gp2,
dt$low_gp3,
dt$low_gp4),
upper = list(
dt$hi_gp1,
dt$hi_gp2,
dt$hi_gp3,
dt$hi_gp4),
ci_column = c(3, 5), # 指定CI列
ref_line = 1, # 添加参考线
vert_line = c(0.5, 2), # 添加垂直线
nudge_y = 0.2, # 垂直调整标签位置
theme = tm) # 应用自定义主题
p

也可以对不同的列进行不同的设置。
# 不同列进行不同设置
# 为 HR (95% CI) 列创建标签
dt$`HR (95% CI)` <- ifelse(is.na(dt$est_gp1), "",
sprintf("%.2f (%.2f to %.2f)",
dt$est_gp1, dt$low_gp1, dt$hi_gp1))
# 为 Beta (95% CI) 列创建标签
dt$`Beta (95% CI)` <- ifelse(is.na(dt$est_gp2), "",
sprintf("%.2f (%.2f to %.2f)",
dt$est_gp2, dt$low_gp2, dt$hi_gp2))
# 设置主题
tm <- forest_theme(
arrow_type = "closed", # 设置箭头类型为闭合箭头
arrow_label_just = "end" # 设置箭头标签对齐方式为末尾
)
# 绘制森林图
p <- forest(
dt[,c(1, 21, 23, 22, 24)], # 选择要在森林图中使用的数据列
est = list(
dt$est_gp1,
dt$est_gp2
),
lower = list(
dt$low_gp1,
dt$low_gp2
),
upper = list(
dt$hi_gp1,
dt$hi_gp2
),
ci_column = c(2, 4), # 指定CI列
ref_line = c(1, 0), # 添加参考线
vert_line = list(c(0.3, 1.4), c(0.6, 2)), # 添加垂直线
x_trans = c("log", "none"), # 设置x轴的转换方式
arrow_lab = list(c("L1", "R1"), c("L2", "R2")), # 设置箭头标签
xlim = list(c(0, 3), c(-1, 3)), # 设置x轴的范围
ticks_at = list(c(0.1, 0.5, 1, 2.5), c(-1, 0, 2)), # 设置刻度位置
xlab = c("OR", "Beta"), # 设置x轴标签
nudge_y = 0.2, # 垂直调整标签位置
theme = tm) # 应用自定义主题
p

相信大家经过这波学习,一定已经可以靠自己绘制出一幅独属于你的森林图啦!那如果对Cox回归还不太了解的小伙伴们,可以查看:看完还不会来揍/找我 | 构建 Cox 比例风险回归模型 | 绘制森林图 (forestplot) | 附完整代码 + 注释。
我们下期再见哟!
如果我的分享对你有用的话,欢迎关注点赞在看转发分享阿巴阿巴阿巴阿巴巴巴!这可是我的第一原动力!
蟹蟹你们的喜欢和支持!!!
参考资料
- https://zhuanlan.zhihu.com/p/471693247
- https://www.jianshu.com/p/52232599fc3b
- https://blog.csdn.net/dege857/article/details/127859291
- https://www.jianshu.com/p/1930b7acf222


















 806
806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











