







 本文概述了多个针对地面机器人和无人驾驶的多传感器数据集,如M2DGR(地面机器人SLAM)、UrbanLoco(城市定位)等,介绍了它们的传感器配置、标定方法、场景多样性和验证实验。这些数据集旨在解决特定环境下的定位和导航挑战,推动SLAM和自主驾驶技术的发展。
本文概述了多个针对地面机器人和无人驾驶的多传感器数据集,如M2DGR(地面机器人SLAM)、UrbanLoco(城市定位)等,介绍了它们的传感器配置、标定方法、场景多样性和验证实验。这些数据集旨在解决特定环境下的定位和导航挑战,推动SLAM和自主驾驶技术的发展。
一、M2DGR
该数据集主要针对的是地面机器人,文章正文提到,现在许多机器人在进行定位时,其视角以及移动速度与车或者无人机有着较大的差异,这一差异导致在地面机器人完成SLAM任务时并不能直接套用类似的数据集。针对这一问题该团队设计了这样的一个包含了多传感器、多场景的数据集。
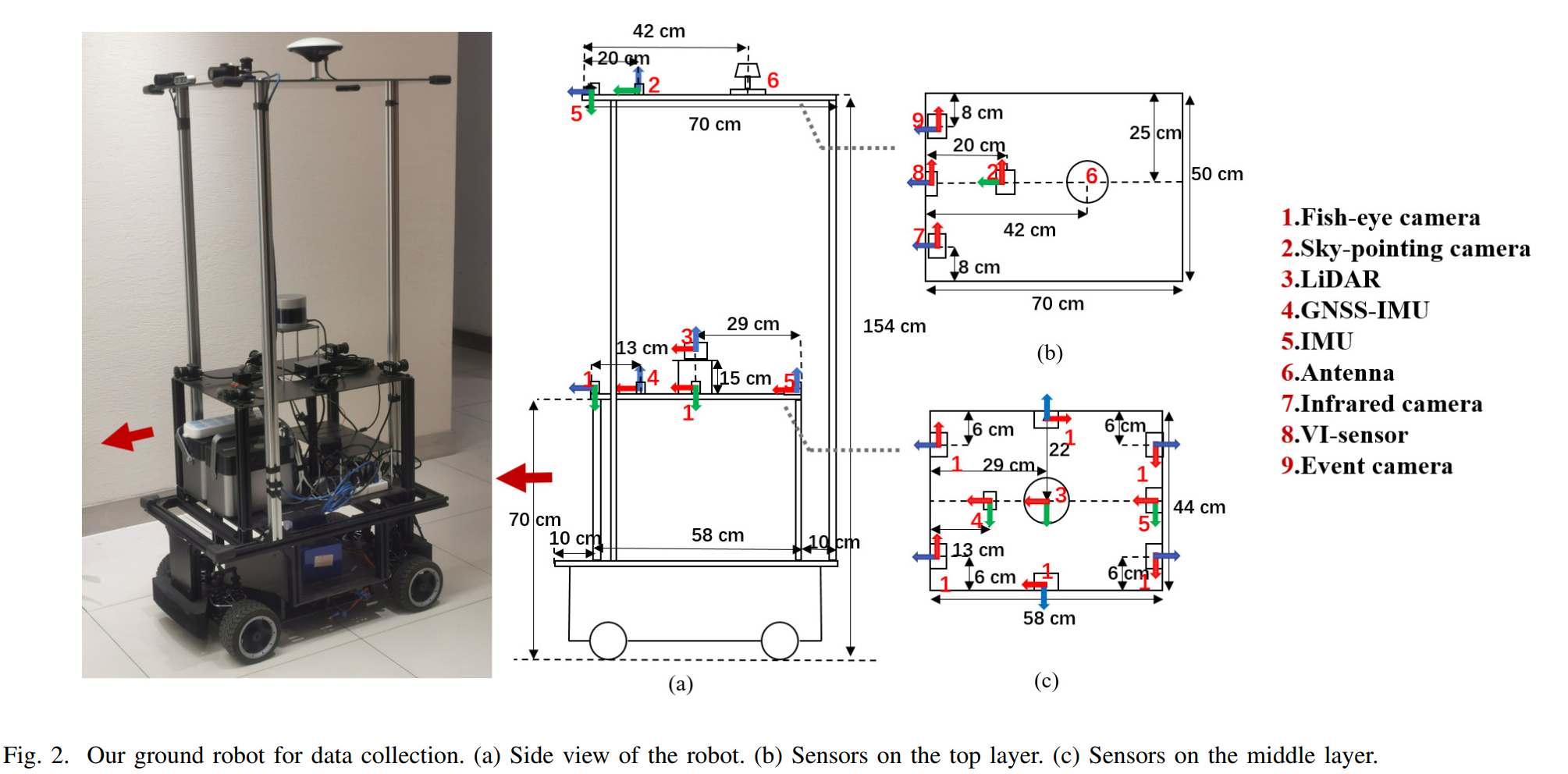
由于其主要针对的是地面机器人,所以创新点也是围绕着这里进行的。文章使用了一个自己搭建的数据采集机器人,配备了六个朝向四周的鱼眼相机、一个朝向天空的普通相机、一个红外相机、一个事件相机、一个32线激光雷达、IMU以及定位设备。
标定与同步方面。文章使用了MATLAB的标定工具箱对相机的内参进行了标定,鱼眼相机使用了Kannala Brandt model畸变模型机型标定。红外相机使用了不同比热容的标定板进行标定,这一标定方法出现在好多红外相机的标定中,这种方法实际上就是用比热容不同的材料来只做标定板的黑白格,这样在加热标定板的时候,黑白格会因为比热容不同呈现出不同的温度,从而就可以在红外相机中表现出差异,利用这种方法人工寻找黑白格的交界处,就能完成标定。外参标定也是使用了各种工具箱,使用Autoware的工具箱可以标定激光雷达和相机,相机和IMU使用了Kalibr工具箱。传感器之间没有使用硬触发,而是选择系统时间来进行软同步。
由于其针对的是地面机器人,所以设计的录制场景同时包含了室内、室外以及室内外交替三类。室外场景选择了RTK定位来获得真值,室内的真值则是使用动捕系统。对于室内外交替的场景,真值是RTK与动补相结合的,个人推测采集机器人上面安装的朝天的相机就是为了判断是在室内还是室外。
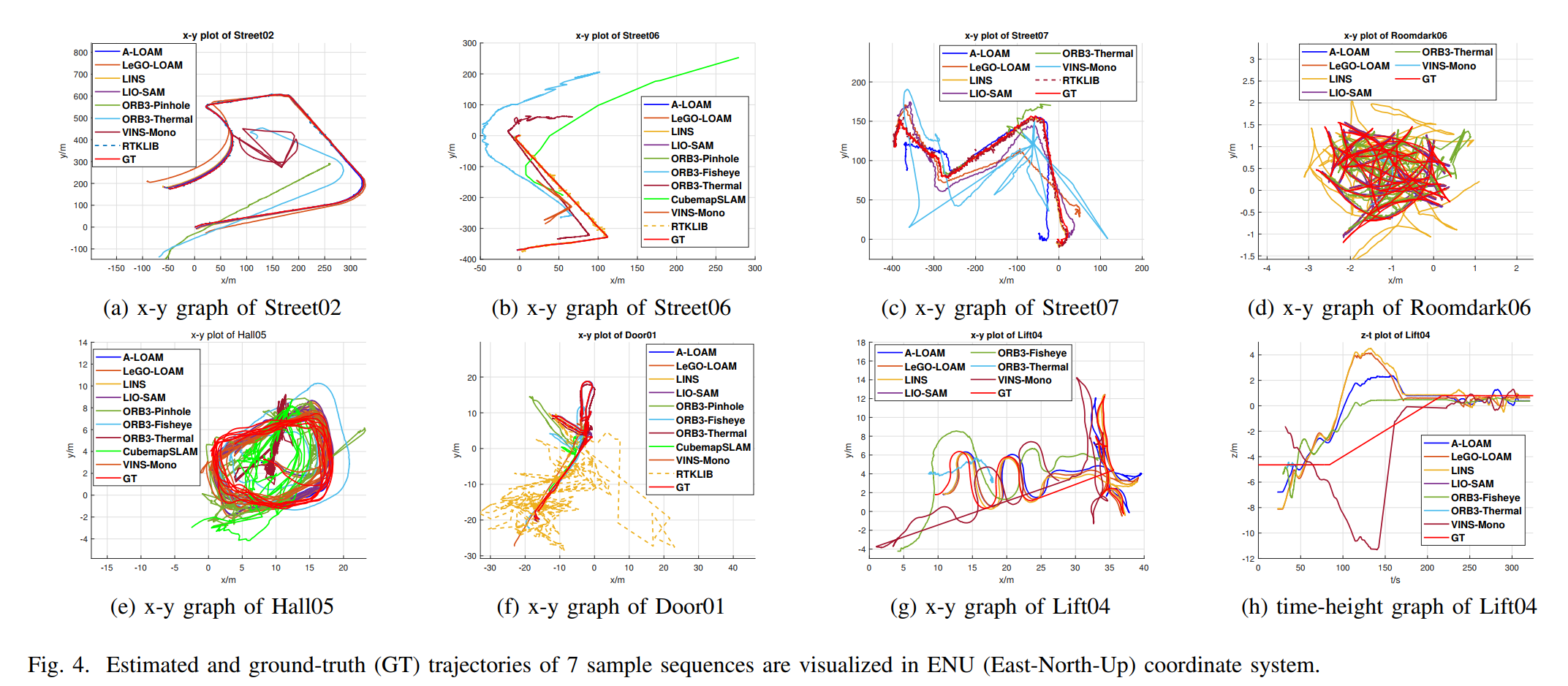
在验证实验部分,文章选择了A-LOAM、LeGo-LOAM、lINS、LIO-SAM、ORBSLAM3、VINS-MONO进行了验证。在一些数据集上表现和真值偏差还是很大的。
二、UrbanLoco
该数据集针对的是无人驾驶数据集缺少人口密集的城市场景这一问题,现有的数据集比如KITTI、Waymo等数据集,并不是在那种大都市场景下进行的录制,在这类场景下高楼大厦会对GNSS信号产生影响,同时诸如汽车、行人等动态物体也会增多,这对于无人驾驶的定位来说是一个较大的挑战。所以作者提出了这样的一个大规模的城市定位数据集,不仅包含了多样的场景以及动态物体,还使用了多传感器进行录制,为了衡量场景的复杂程度,作者还提出了一个城市化比例的概念。
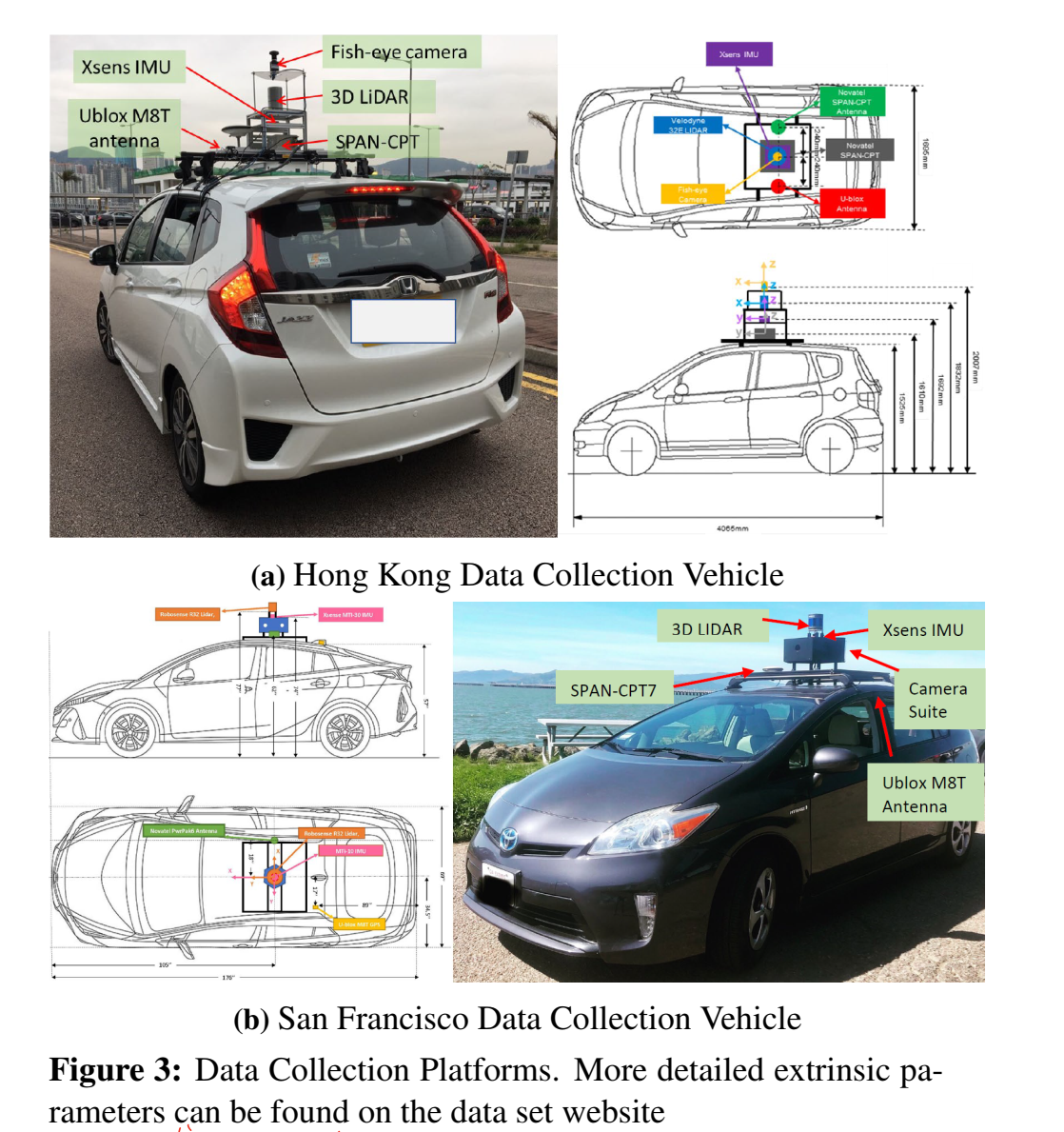
实验采集车使用的是一辆改装过的丰田飞度,在车顶加了一个架子用来放置传感器,使用的传感器包括一个激光雷达、相机、鱼眼相机、IMU以及GNSS设备,录制地点是香港和旧金山的街道。为了获得轨迹真值作者选用的SPAN-CPT来融合IMU和RTK来完成真值。这里作者提到在鱼眼相机仅用在了香港的数据采集,并且这一相机是朝天指向的,这样做是为了去评估卫星的可见程度,从而改善GNSS的定位结果。
标定方面论文没有介绍太多,只写了用Kalibr工具箱来进行相机内参的标定,外参则是使用Autoware工具箱进行的。
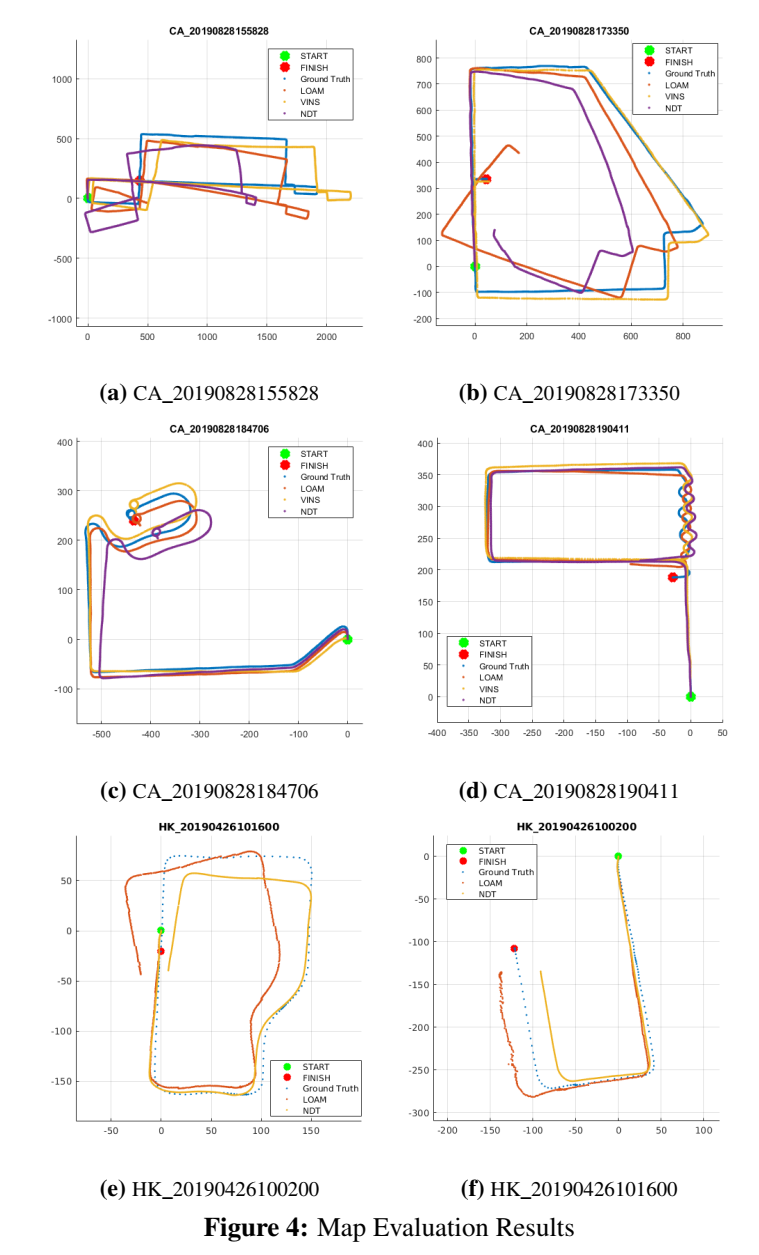
验证实验部分,作者选用了视觉、激光两类SLAM框架进行验证,选择了LOAM、NDT、VINS-MONO进行测试。
三、NCLT
该数据集主要针对的是地面机器人的导航,作者使用了一台类
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 529
529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











