






目录
transductive link predition+ablation
一、summary
为解决大型KG上训练的计算负担,本文提出了一种模型压缩方法NodePiece,该方法基于固定尺寸大小的“锚点”,对每个顶点由其相邻的k个锚点及距离以及m个相邻的关系学习嵌入。企图利用较少的子实体对大型KG进行表示,并增强模型的泛化性。
二、method
对知识图谱,NodePiece定义为
,Nodepiece vocabulary定义为
,为保证可达性及出入度平衡
,每个节点的hash由相邻的k个锚点及距离以及m个相邻的关系表示,
,,再由编码函数
嵌入到向量空间中。
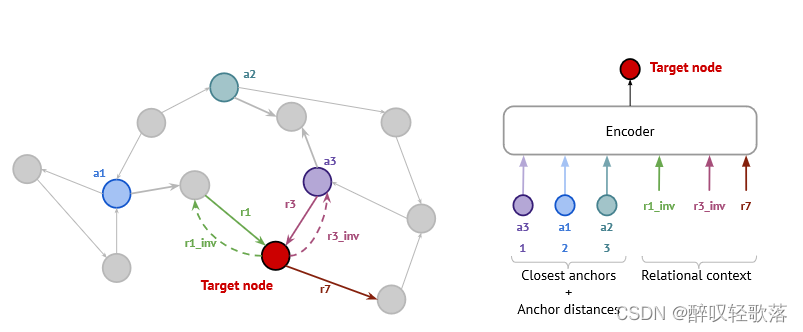
anchor selection
实验发现随机选择与基于确定性的规则选择效果差不多。
node tokenization
提出两种方法确定k个锚点,1.随机策略,均匀从可能组合选取,
和k由节点总数定义的可能组合的下界来选择,2.确定性策略,使用BFS直接对n的邻居进行检索并排序。对于孤立点,将其与标记为DISCONNECTED的锚点相连,或者是直接将其设为锚点,对大多KG影响忽略不计。
anchor distance
利用原图中锚点与目标点的最短距离(整数),后将其映射为d维向量.
relation context
随机采样m个相连的关系,少于m个则用[pad]补全.
encoding:
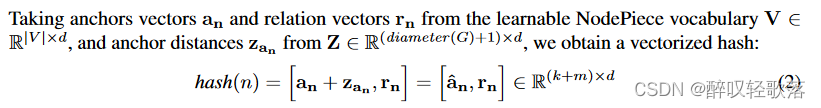
使用MLP和Transformer解码器实现编码函数,其中MLP的速度更快,能够更好地缩放具有更多边缘的图,transformer参数更少。
三、experiment
transductive link predition+ablation


其中FB15k-237比WN18RR的关系更为稠密,在消融实验中获得了不同的效果,且消融分析表明,增加锚的总数和每个实体的锚数量可以将性能提高到饱和点。
在大规模KG中,NodePiece获得了更好的结果。

inductive link predition

node classification

总结
nodepiece能够有效地减少了知识图谱表示的参数,且在大规模,关系稠密的知识图谱中能够得到更好的结果。
















 957
957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









