






目标检测是计算机视觉领域中的一项重要任务,旨在检测和定位图像或者视频中的目标对象。当人类观看图像或视频时,我们可以在瞬间识别和定位感兴趣的对象。目标检测的目标是使用计算机复制这种智能。
近年来,目标检测网络的发展日益成熟,涌现出多种优秀的模型。其中包括 YOLO 系列和 EfficientDet-D0 等目标检测网络。
YOLO 系列:
YOLO(You Only Look Once)是由 Joseph Redmon 等人在 2016 年提出的一个实时目标检测网络。YOLO 系列的模型包括 :YOLO v2、YOLO v3 、YOLO v4、YOLOX 和 YOLO v8 等。
EfficientDet-D0:
EfficientDet-D0 是 Google 在 2020 年提出的一个高效的目标检测网络。它基于 Transformer 架构,使用了 Bidirectional Encoder Representations from Transformers(BERT)作为 backbone 网络。EfficientDet-D0 的主要贡献在于引入了 Compound Scaling 方法,能够自动调整模型的深度、宽度和分辨率,从而实现高效的目标检测。
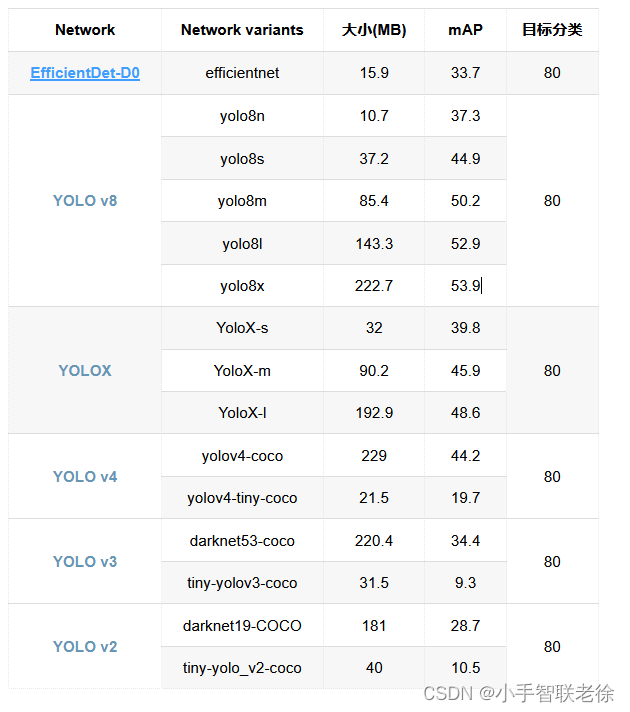
目标检测预训练模型大小及准确度比较:
这些网络已经训练用于检测来自 COCO 数据集的 80 个对象类别,输入是RGB图像,输出是预测的标签、边界框和得分。这些模型适合使用迁移学习来训练自定义目标检测器。
选择模型的建议:
预训练的目标检测器在选择应用于实际问题的网络时具有不同的重要特性。最重要的特性包括平均精度均值(mAP)、速度和大小。选择网络通常是在这些特性之间做出权衡。
在选择模型时,应该考虑以下因素:
-
平均精度均值(mAP):mAP 是目标检测任务中常用的评估指标,它考虑了预测边界框的位置和类别标签的准确性。更高的 mAP 通常意味着模型在检测各种对象时更准确。根据实际的应用需求,选择一个具有足够高 mAP 的模型是很重要的。
-
速度:速度指的是模型处理输入图像并生成预测结果的速度。对于需要实时响应的应用(如自动驾驶、视频流分析等),速度是一个关键因素。选择一个速度较快的模型可以确保系统能够及时响应。
-
大小:模型的大小通常以参数数量或存储空间需求来衡量。较小的模型可以更容易地部署在资源有限的设备上(如移动设备或嵌入式系统)。然而,较小的模型可能牺牲了部分准确性。因此,在选择模型时,您需要在准确性和大小之间找到平衡。
在选择模型时,考虑实际的具体需求,如实时性、准确性要求、硬件资源限制等。可以使用预训练的模型作为起点,并根据需要进行微调或优化。此外,还可以尝试使用迁移学习技术,将预训练模型的知识迁移到自己的数据集上,以加速训练过程并提高性能。
老徐,2024/5/28

















 689
689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









